点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转载自夕小瑶的卖萌屋
最近几天在知乎上有个问题火了:
你是什么时候对深度学习失去信心的?
在此推荐一下知乎大V@霍华德的回答,以下为原回答。
对于深度学习的现状,工业界还是很清楚的。如果没有变革性的突破,弱人工智能时代的范式应该基本就要确定了。
 大模型 + 拖拖乐
大模型 + 拖拖乐
基本范式就是 大模型 + 拖拖乐,下游少量数据微调,在前端表现为拖拖乐形成DAG,自动生产模型。拖拖乐平台,各大云厂商都有提供,如阿里的PAI,腾讯的Ti平台、华为的ModelArts,亚马逊的SageMaker等等
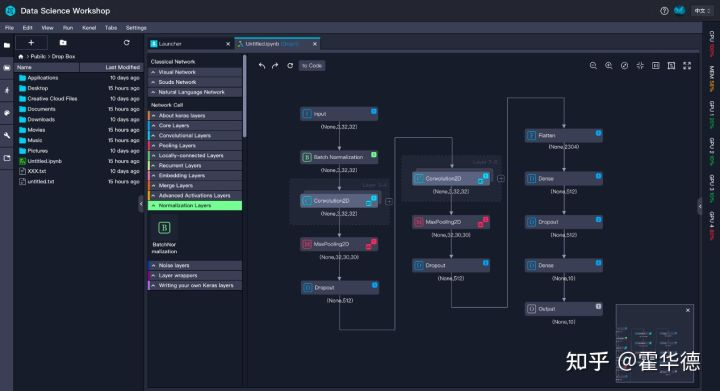
对于大模型,各种网络魔改价值很有限,因为数据上去后,假设越少越好,偏置归纳越少越好,这就使得模型越朴素越好。
大模型也会成为各大公司的核心资产,所有数据向大模型汇聚,试图记下互联网上的一切数据。然后,一键蒸馏小模型,一键剪枝,一键压缩,一键部署,一键一条龙。
深度学习规则化
越来越觉得,深度学习变成一种数据驱动的规则,一个模型就是一个规则。传统规则引擎里各种if-else,全靠程序员启发式完成。
深度学习规则引擎,每个规则就是个小模型。全靠算法工程师,使用数据驱动的方式训练完成。
之前大家觉得,一个强力模型包打天下。现在看来,更务实的方式的,无数小模型,组合冲击,往往效果更佳。
这就使得,原本深度学习被诟病可解释性问题,其实不再是问题。因为从业务顶层已经被拆分,拆分成一个个可以被人理解的因子,无法被合理解释的因子,项目启动的评审都无法通过。
就我熟悉的视频理解来说吧,原本以为一个强大模型,学习所有数据,出一个强力分数,然后用这个分数搞定一切。但这样的模型背后的黑箱,无法被接受。
现在,视频被从非常多个维度切分,视频清晰度、视频美观度、视频有没有log,视频有没有涉黄,视频有没有涉政,是不是ppt视频,有没有被剪裁过,有没有黑边。所有这些子任务都不需要多强的模型,更重要的是数据。
显著的 > 隐含的
另外一个感悟是,显著的优于隐含的,字幕就是优于打标签,OCR识别优于各种分类、检索、生成。因为字幕就是最显著的,其他信息都是隐含的,通过模型推测出来的。
这就产生了一个固有矛盾。在学术界,隐含的才是有难度的,才是有研究价值的,例如视频动作识别,一定要从连续的动作中理解出到底在干啥。但在工业界,这样的任务就非常难用。工业界喜欢显著的,因为问题最少。
这样的分野,会使得工业界和学术界关心的问题,慢慢发生分歧,不知道是好是坏。
刀耕火种的时代过去了
过去,算法工程师们耕作着一亩三分地,或经营着一个个手工作坊,面向业务营业。但显然刀耕火种和手工作坊时代要过去了。大型收割机已经进入农田,制造业工厂已经拔地而起,里面是一条条模型流水线。这就是生产力的发展,势不可挡。
但就像失去土地的农民,失去作坊的工匠,下步又该何去何从?
技能闭环,还是深耕?
我能想到的大概两个方向。
一个是往大模型深耕,成为大模型专家,在公司内守住一个领域的大模型。或者带着自己大模型的技能,到其他地方去用大模型降维打击。但其实能用起的大模型的地方,可能不会很多,训练的成本就很高。
一个是技能闭环,或者说就是全栈化,补充后台、前端、大数据、产品的知识,争取获得独立打造产品的能力。这样能降低被螺丝钉化的风险。
独家重磅课程官网:cvlife.net

全国最大的机器人SLAM开发者社区

技术交流群

— 版权声明 —
本公众号原创内容版权属计算机视觉life所有;从公开渠道收集、整理及授权转载的非原创文字、图片和音视频资料,版权属原作者。如果侵权,请联系我们,会及时删除。










