
作者:Anusua Trivedi、Wee Hyong Tok
翻译:付宇帅
校对:卢苗苗
本文5302字,建议阅读10分钟。
本文讲述了现代机器学习的模型,主要由微软数据科学家Anusua Trivedi和数据科学家经理Wee Hyong Tok共同撰写。
动机
现代机器学习模型,尤其是深度神经网络,通常可以从迁移学习中显著受益。在计算机视觉中,在大型图像分类数据集(如ImageNet)上训练的深卷积神经网络已被证明对初始化其他视觉任务(如物体检测)模型非常有用(Zeiler和Fergus,2014)。
但是,我们如何文本上应用迁移学习技术?在这篇博客文章中,我们试图在研究社区中对现有的文本传输学习文献进行综合研究。我们探索八种流行的机器阅读理解(MRC)算法(图1)。我们评估和比较了六篇这样的论文:
BIDAF,DOCQA,ReasoNet,R-NET,SynNet和OpenNMT
我们将模型初始化,对不同的源问题答疑(QA)数据集进行预先训练,并展示标准迁移学习如何在大型目标语料库上实现结果。为了创建一个测试语料库,我们选择了由Harry Shum和Brad Smith编写的Future Computed一书。
我们比较了使用这些预训练的MRC模型为本书创建QA系统的迁移学习方法的性能。对于我们的评估方案,Document-QA模型的性能优于其他迁移学习方法(如BIDAF,ReasoNet和R-NET模型)的性能。您可以在这里使用Jupyter笔记本测试Document-QA模型场景。
我们使用一些预训练的MRC模型比较了用于为本书创建QA语料库的微调学习方法的性能。根据我们的评估方案,OpenNMT模型的性能优于SynNet模型的性能。您可以在这里使用Jupyter笔记本测试OpenNMT模型场景。
介绍
在自然语言处理(NLP)中,域适应一直是语法解析(McClosky等,2010)和命名实体识别(Chiticariu等,2010)等重要课题。随着词向量的普及,像word2vec(Mikolov et al。,2013)和GloVe模型(Pennington等,2014)这样的预先训练的词嵌入模型也被广泛用于自然语言任务。
在自然语言处理中,问题回答中是一个长期存在的挑战,该社区在过去几年中为这项任务引入了几个范例和数据集。这些范例在问题和答案的类型以及培训数据的大小方面各不相同,有几百到几百万不等的例子。
在这篇文章中,我们特别感兴趣的是上下文感知QA范例,其中每个问题的答案可以通过参考其伴随的上下文(即段落或句子列表)来获得。对于人类来说,阅读理解是一项基本任务,每天都要进行。早在小学,我们就可以阅读一篇文章,并回答关于其主要思想和细节的问题。但对于AI来说,完成阅读理解仍然是一个难以捉摸的目标。因此,构建能够执行机器阅读理解的机器是非常有意义的。
机器阅读理解(MRC)
MRC是关于回答有关给定情境段落的查询。 MRC需要对上下文和查询之间的复杂交互进行建模。最近,注意力机制已成功扩展到MRC。通常,这些方法使用注意力集中在上下文的一小部分上,并用固定大小的矢量对其进行总结,暂时关注时间和/或经常形成单向注意力。这些都已表明,这些MRC模型对于新领域的文本转移学习和微调来说表现良好
为什么MRC对企业来说非常重要?
企业内部对聊天机器的使用情况持续增长。研究和行业已经转向会话式AI方法来推进这种聊天机器人场景,特别是在银行,保险和电信等复杂使用案例中。对话式人工智能的一个主要挑战是需要使用人类的方式理解人类所表达的复杂句子。人的交谈从来不是直截了当的 - 它充满了由多字符串单词,缩写,片段,发音错误和其他一系列问题。
MRC是解决我们今天面临的对话式AI问题的必备因素。如今,MRC方法能够精确地回答诸如“什么原因导致下雨?”等客观问题。这些方法可以被运用于真实世界,如客户服务。 MRC可以被用于导航和理解种“给予与获取”这样的交互。 MRC在商业领域的一些常见应用包括:
这种智能会话界面是企业与各地的设备,服务,客户,供应商和员工互动的最简单方式。使用MRC方法构建的智能助理可以每天训练并继续学习。业务影响可以包括通过增加自助服务,提高最终用户体验/满意度,更快地提供相关信息以及提高对内部程序的遵从性来降低成本。
在这篇博文中,我们想要评估不同的MRC方法来解决不同领域的自动问答功能。
MRC迁移学习
最近,一些研究人员已经探索出了各种攻克MRC迁移学习问题的方法。他们的工作对于开发一些可扩展解决方案以将MRC扩展到更广泛领域来讲,至关重要。
目前,大多数最先进的机器阅读系统都建立在监督培训数据的基础上,通过数据实例进行端对端培训,不仅包含文章,还包含人工标记的关于文章和相应答案的问题。通过这些例子,基于深度学习的MRC模型学习理解问题并从文章中推断出答案,其中涉及推理和推理的多个步骤。对于MRC转移学习,我们有6个模型,如图1所示。
MRC微调
尽管使用MRC迁移学习有了很大的进展,但直到最近,人们才开始重视一个被忽视很久的关键问题- 如何为非常小的领域构建MRC系统?
目前,大多数最先进的机器阅读系统都建立在监督式培训数据的基础上,经过数据示例的端对端培训,不仅包含文章,还包含有关文章和相应答案的人工标记问题。通过这些例子,基于深度学习的MRC模型学习理解问题并从文章中推断出答案,其中涉及推理和推理的多个步骤。这种MRC迁移学习对于通用文章非常有效。但是,对于许多利基领域或垂直领域而言,这种监督训练数据不存在。
例如,如果我们需要建立一个新的机器阅读系统来帮助医生找到有关新疾病的有价值信息,那么可能有许多文件可用,但是缺少关于这些文章及其相应答案的手动标记问题。由于需要为每种疾病建立单独的MRC系统以及迅速增加的文献量,这一挑战被放大了。因此,找出如何将MRC系统转移到小众领域很重要,在这个领域中没有手动标记的问题和答案,但有可用的文件体。
在此之前,已经有人研究过生成合成数据以增加不充分的训练数据这样的问题。为了翻译的目标任务,Sennrich 等人在2016提出用给定的真句生成合成翻译以改进现有的机器翻译系统。然而,与机器翻译不同的是,对于像MRC这样的任务,我们需要综合考虑文章的问题和答案。而且,虽然问题是句法流式的自然语言句子,但答案主要是段落中的显著语义概念,如命名实体,动作或数字。由于答案与问题的语言结构不同,因此将答案和问题视为两种不同类型的数据可能更合适。 Golub等人2017年提出了一种称为SynNet的新型模型以解决这一关键需求。
Xinya Du等人在2017年使用了开源神经机器翻译工具包OpenNMT这样的微调方法。
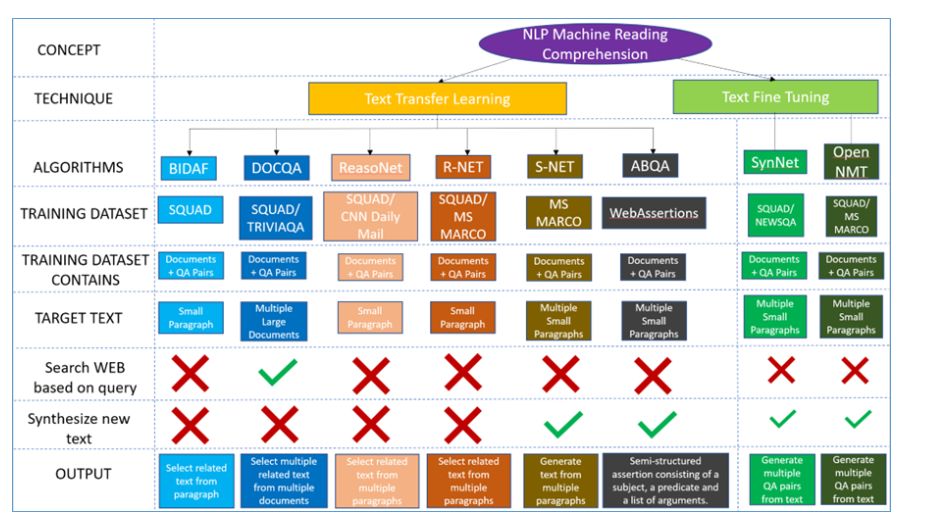 图1
图1
训练MRC模型
我们使用深度学习虚拟机(DLVM)作为具有NVIDIA Tesla K80 GPU,CUDA和cuDNN库的计算环境。 DLVM是数据科学虚拟机(DSVM)的一种特别配置的变体,可以更直接地使用基于GPU的虚拟机实例来训练深度学习模型。它支持Windows 2016和Ubuntu Data Science虚拟机上。它与DSVM共享相同的核心虚拟机映像(以及所有丰富的工具集),但在配置上更适用于深度学习。所有实验均在具有2个GPU的Linux DLVM上运行。我们使用TensorFlow和Keras以及Tensorflow后端来构建模型。我们在DLVM环境中安装了所有依存项。
先决条件
对于每个模型,请按照GitHub中的Instructions.md来下载代码并安装依存关系。
实验步骤
在DLVM中设置代码后:
运行代码来训练模型。
产生训练有素的模型。
然后运行评分代码来测试训练模型的准确性。
有关所有代码和相关详细信息,请参阅我们的GitHub链接。
使用Python Flask API在DLVM上运行训练的MRC模型
操作化是将模型和代码发布为Web服务以及消费这些服务以产生业务结果的过程。 AI模型可以使用Python Flask API部署到本地DLVM。 要使用DLVM操作AI模型,我们可以在DLVM中使用JupyterHub。 您可以按照每个型号的笔记本中列出的类似步骤进行操作。 DLVM模型部署体系结构图如图2所示。
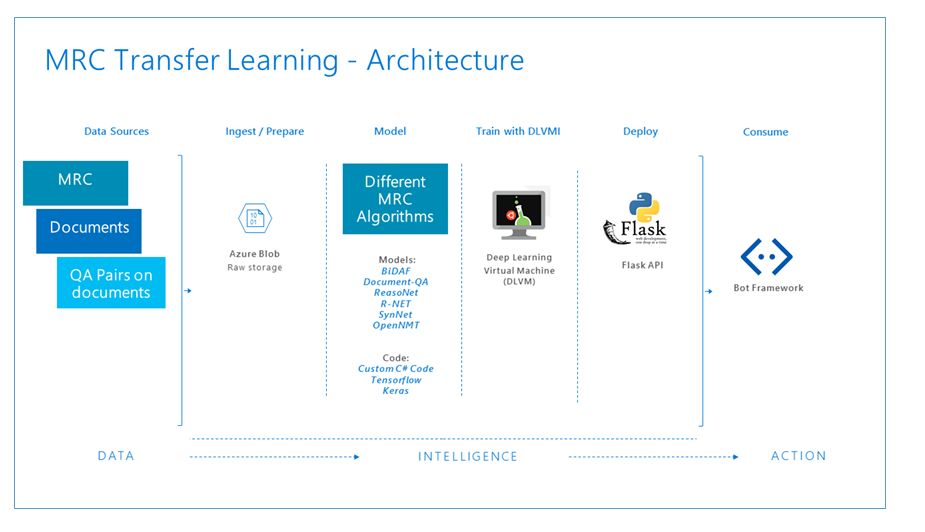 图2
图2
评估方法
为了比较研究,我们想要在不同的数据集上训练不同的MRC模型,并在单个大型语料库上测试它们。为了达到本博文的目的,我们使用六种MRC模型方法 - BIDAF,DOCQA,ReasoNet,R-NET,SynNet和OpenNMT - 使用训练好的MRC模型为大语料库创建QA-Bot,然后比较结果。
如前所述,为了创建我们的测试语料库,我们使用Harry Shum和Brad Smith撰写的Future Computed一书。我们将本书的PDF转换为Word格式,并删除了所有图像和图表,因此我们的测试语料库仅包含文本。
BIDAF,DOCQA,R-NET,SynNet和OpenNMT都有开放的GitHub资源可用来复制纸质结果。我们使用这些开放的GitHub链接来训练模型,并在必要时扩展这些代码以进行比较研究。对于ReasoNet论文,我们与作者取得联系并访问了他们的私人代码以进行评估工作。请参考下面的详细说明,对我们的测试语料库上的每个MRC模型进行评估。
我们的比较工作总结在下面的表1中
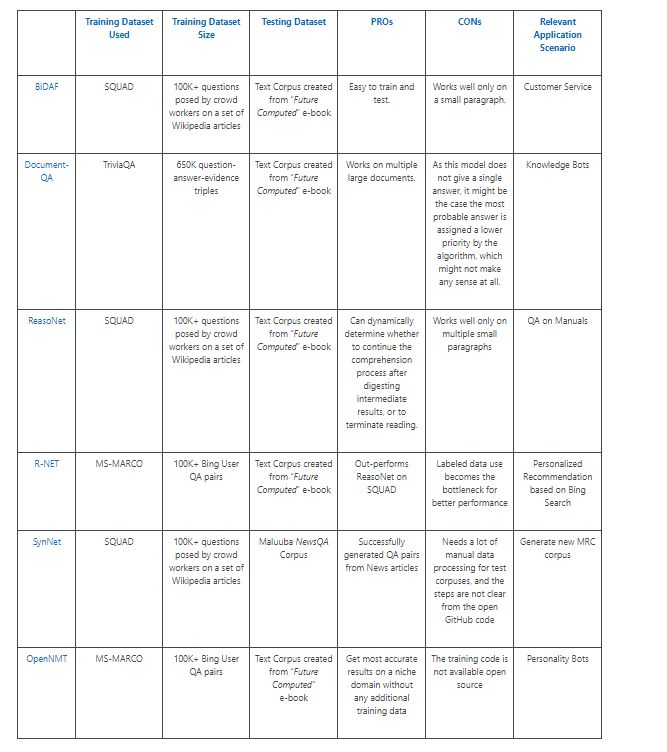
表1
评估工作中的收获
在这篇博客文章中,我们调查了SQUAD和TriviaQA数据集中的四种不同MRC方法的性能。我们比较了使用这些预训练的MRC模型为Future Computed一书创建问答系统的迁移学习方法的性能。请注意,这里的比较仅限于我们的评估方案。其他文档或场景的结果可能会有所不同。
我们的评估方案显示,OpenNMT微调方法的性能优于针对领域特定数据集的简单迁移学习MRC机制。但是,对于通用的大型文章,Document-QA模型优于BIDAF,ReasoNet和R-NET模型。我们将比较下面更详细的性能。
使用BiDAF模型进行转移学习的优点和缺点
BiDAF模型易于培训和测试(感谢AllenAI通过开放的GitHub链接提供所有代码)。
BiDAF模型的使用非常有限。它只适用于一小段。给定一个更大的段落或许多小段落,这个模型通常需要很长时间,并且以可能的跨度作为答案返回,这可能根本没有任何意义。
GitHub中的资源贡献:
https://github.com/antriv/Transfer_Learning_Text/tree/master/Transfer_Learning/bi-att-flow
使用Document-QA模型进行转移学习的优点和缺点
Document-QA模型非常易于培训和测试(感谢AllenAI通过开放的GitHub链接提供所有代码)。与我们之前探讨的BiDAF模型相比,Document-QA模型做得更好。给定多个较大的文档,这个模型通常需要很少的时间来产生多个可能的跨度作为答案。
但是,由于Document-QA没有给出单个答案,因此算法可能会将最可能的答案指定为较低的优先级,这可能根本没有任何意义。我们假设,如果模型只能看到包含答案的段落,那么它可能会对启发式或模式过于自信,这种模型只有在先验知道存在答案时才有效。例如,在下面的表2中(根据论文进行调整),我们观察到,即使问题单词与上下文不匹配,模型也会为与答案类别强烈匹配的跨度分配高信度值。如果有答案,这可能会工作得很好,但在其他情况下可能不会有这么好的效果。
GitHub中的资源贡献:
https://github.com/antriv/Transfer_Learning_Text/tree/master/Transfer_Learning/document-qa

表2
使用ReasoNet模型进行迁移学习的优点和缺点
ReasoNets利用多次轮流有效地利用,然后推理查询文档和答案之间的关系。通过使用强化学习,ReasoNets可以动态确定究竟是在消化中间结果后继续理解过程还是终止阅读。
很难重现本文的结果。没有开放代码可用于此。 ReasoNet模型的使用非常有限。它只适用于一小段。给定一个更大的段落,这个模型通常需要很长时间,并以可能的跨度作为答案回来,这可能根本没有任何意义。
GitHub中的资源贡献,我们为这项工作增加了一些演示代码,但没有公开的GitHub代码可用于此。
使用R-NET模型进行转移学习的优点和缺点
除了在SQUAD上进行培训外,我们还可以在MS-MARCO上训练此模型。在MS-MARCO中,每个问题都有几个相应的段落,所以我们只需按照数据集中给出的顺序连接一个问题的所有段落。其次,MS-MARCO的答案不一定是这些段落的次要代表。在这方面,我们选择评分最高的跨度,参考答案作为训练中的黄金跨度,并预测最高得分跨度作为预测的答案。 MS-MARCO数据集上的R-NET模型优于其他竞争性基线,如ReasoNet。
对于数据驱动的方法,标记数据可能成为更好性能的瓶颈。虽然文本很丰富,但找到符合SQUAD风格的问题片段组合并不容易。为了生成更多的数据,R-NET模型作者使用SQuAD数据集训练了一个序列到序列的问题生成模型,并从英文维基百科生成了大量的伪问题通道组合。但分析表明,生成问题的质量需要改进。 R-NET仅适用于一小段。给定一个更大的段落或许多小段落,这个模型通常需要很长时间,并且以可能的跨度作为答案返回,这可能根本没有任何意义。
使用SynNet模型进行Finetuning的优点和缺点
在NewsQA数据集上使用SynNet模型非常简单。它还在NewsQA数据集上生成了很好的问答组合。
SynNet模型的使用非常有限。很难在自定义段落/文本上运行打开的现有代码。它需要大量的手动数据处理,并且这个打开的GitHub链接的步骤并不清楚。因此,我们无法在我们的测试书语料库上对其进行评估。
使用OpenNMT模型进行微调优的优点和缺点
使用OpenNMT模型,我们能够在没有任何额外训练数据的情况下,获得迄今为止最精确的小众领域结果,以接近完全监督的MRC系统性能。 OpenNMT分两个阶段工作:
一旦我们从一个新领域获得生成的问答组合,我们还可以在这些问答组合上训练一个Seq2Seq模型,用以从MRC中生成更多像人类一样的对话式AI方法。
OpenNMT模型培训代码不可用于开源。它只适用于一小段。给定一个更大的段落或许多小段落,这个模型通常需要很长时间,并且以可能的跨度作为答案返回,这可能根本没有任何意义。
结论
在这篇博文中,我们展示了我们如何使用DLVM来训练和比较不同的MRC模型进行迁移学习。我们评估了四种MRC算法,并通过使用每种模型为语料库创建问答模型来比较它们的性能。在这篇文章中,我们展示了使用迁移学习选择相关数据的重要性。这表明,考虑到任务和特定领域的特征,学习适当的数据选择措施的性能优于现成的指标。 MRC方法给了AI更多的理解力,但是MRC算法仍然不能真正理解内容。例如,它不知道“英国摇滚乐队酷玩乐团”究竟是什么,只知道它是超级碗相关问题的答案。有许多自然语言处理应用程序需要能够将知识迁移到新的任务的模型,并通过人类理解来适应新的领域,我们认为这仅仅是文本迁移学习之旅的开始。
Anusua和Wee Hyong
(您可以通过antrua@microsoft.com向Anusua发送电子邮件,内附与本文相关的问题。)
原文标题:
Transfer Learning for Text using Deep Learning Virtual Machine (DLVM)
原文链接:
https://blogs.technet.microsoft.com/machinelearning/2018/04/25/transfer-learning-for-text-using-deep-learning-virtual-machine-dlvm/
付宇帅,澳大利亚联邦CSIRO Machine Learning Engineer。Dedicate in creating reliable and safe lifestyle via technology。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文
”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。











