在深度学习领域,通过以精度、召回率、平均精度均值(Mean Average Precision,mAP)和FPS等指标评价目标检测算法的有效性,在图像分割中则主要采用平均像素准确率、平均交并比等指标评价。
在工业质检领域的评价指标与深度学习领域类似,只是表述方式有所不同,一般使用漏检率、误检率和准确率等。
根据被检测工件的真实情况(OK*和NG*)和检测结果(OK和NG)的不同,可以将缺陷识别的结果分为4种情况,如下表所示。
TP、FP、FN和TN的含义为:
TP(True Positive):被检测工件为OK,检测结果为OK,正确检出。
FP(False Positive):被检测工件为NG,检测结果为OK,漏检。
FN(False Negative):被检测工件为OK,检测结果为NG,误检。
TN(True Negative):被检测工件为NG,检测结果为NG,正确检出。
1. 工业质检中的性能指标
漏检率、误检率、准确率和错误率的含义和计算方式为:
(1)漏检率
漏检率指的是在检测中未发现的不合格品数量占实际不合格品数量的百分比。漏检会直接导致不良产品流向终端客户,因此是工业表面缺陷检测中格外关注的指标。漏检率的计算公式为:
漏检率漏检率=FPTN+FP×100%
(2)误检率
误检率指的是将合格品检测为不合格品的数量占实际合格品数量的百分比。误检会直接对工业企业的良品率造成负面影响,会导致物料的浪费。误检率的计算公式为:
误检率误检率=FNTP+FN×100%
(3)准确率
准确率指的是检测中正确检出的数量占检测总数的百分比。准确率是衡量检测系统性能的重要参数,其计算公式为:
准确率准确率=TN+TPTN+FP+TP+FN×100%
2.目标检测中的性能指标
在目标检测中,通常采用FPS和mAP两个指标来分别评估识别系统的识别速度和精度。前者的计算方式较为简单,通过计算系统每秒内能够处理的图像数量即可求出FPS值。计算mAP值涉及到IoU、精度(Precision)和召回率 (Recall)和平均精度(Average Precision,AP)等内容。
(1)IoU
缺陷识别问题的任务除了要判断出表面是否存在缺陷,还需识别出缺陷的种类,并以矩形框的方式定位缺陷的位置。如图下所示,识别系统预测的矩形框无法与人工贴标的Ground True标定框完全一致。因此在目标识别中引入交并比(Intersection over Union, IoU)的来衡量位置判断是否准确。图中蓝色框表示预测的缺陷位置,绿色框表示Ground True标定的缺陷位置。
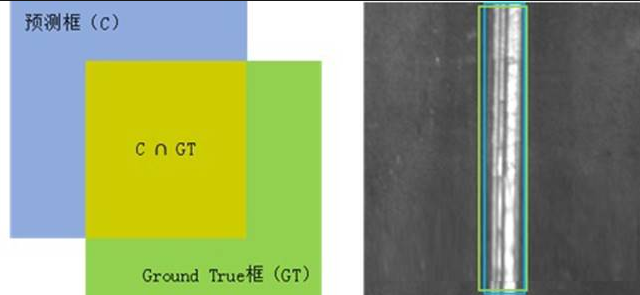
Ground True框
IoU的计算方式如下面的公式所示,即预测框与真实框交集区域和并集区域的比值大小。当IoU=0
时表示两块区域完全不重叠,IoU=1 时表示完全重叠。
IoU=area(C)∩area(GT)area(C)∪area(GT)
在目标检测任务中,如果模型的预测输出矩形框与人工标注的Ground True标定框的IoU值大于某一阈值时,即认为模型的预测是准确的。遵照惯例,IoU通常取值为0.5。
(2)精度和召回率
精度和召回率可由下面两个公式表示,精度用于反映检测结果中命中率的高低,召回率反映了某类目标的检测覆盖率的高低。
Precision=TPTP+FPRecall=TPTP+FN
评估模型有效性时需同时检测精度和召回率两个指标。但这两个指标存在负相关现象,提高精度往往会导致召回率的降低,反之亦然。因此一般引入兼顾精度和召回率的平均精度来评估模型的效果。
(3)平均精度
目标检测任务中使用置信度来评估当前矩形框内为某种物体的概率。置信度的取值为0到1之间。当置信度为1时表示有最大可能性认为矩形框内的物体为某一类别,当置信度为0时表示有最小可能性。
在计算AP的值时,需要绘制Precision-Recall曲线,计算曲线下方的面积即为AP值。首先按照模型给出的置信度由高到低对预测框进行排序,排序后获得一组包含精度、召回率值的有序数组。将该数组绘制成以召回率为横坐标,精度为纵坐标的曲线。随着召回率的增大,精度的值呈振荡减小趋势。为去除振荡的影响,在实际应用中需要对曲线进行平滑处理,曲线中精度值取该点右侧(召回率大于或等于当前点召回率所对应的精度)最大的精度值。经过曲线平滑后,平均精度AP的值由如下公式计算:
AP=∫01p(r)dr
平均精度均值mAP为所有类别的AP的平均值:
mAP=12∑i=1nAPi
式中,n 表示缺陷的类别数, APi 为每一类缺陷的平均精度。当 n=1 时, mAP=APi 。
3.语义分割中的性能指标
图像语义分割的性能主要通过像素准确率(Pixel Accuracy,PA)、平均像素准确率(Mean Pixel Accuracy,MPA)和平均IoU(Mean Intersection over Union,MIoU)三个指标来衡量。
(1)像素准确率(Pixel Accuracy,
PA)
像素准确率指正确分类的像素量占总图片像素量的比值,由如下公式计算:
PA=∑i=0kpii∑i=0k∑j=0kpij
式中,k 表示类别数量, pii 为实际类别为 i 的像素分预测为类别 i 的总数量, pij 为实际类别为 i 的像素被预测为类别 j 的总数量。
(2)平均像素准确率(Mean Pixel Accuracy,MPA)
平均像素准确率是对像素准确率的改进,它是先对每个类计算像素准确率,然后再对所有类的像素准确率求平均,由如下公式计算:
PA=1k+1∑i=0kpii∑j=0kpij
(3)平均IoU(Mean Intersection over Union,MIoU)
平均IoU分别对每个类计算交并比,然后再对所有类别的交并比求均值。平均IoU由如下公式计算:
MIoU=1k+1∑i=0kpii∑j=0kpij+∑j=0kpji−pii
以上就是深度学习与缺陷检测中常用的性能指标及计算方法,目标检测和语义分割的资料比较多,但是对于工业实际应用的漏检率、漏检率和准确率等指标的介绍内容比较少,而且计算方式有时会根据实际情况做细微的调整、因此撰写此文,一方面作为参考,另一方面与深度学习中的常用指标做个对比。
来源:知乎@李是Lyapunov的李










