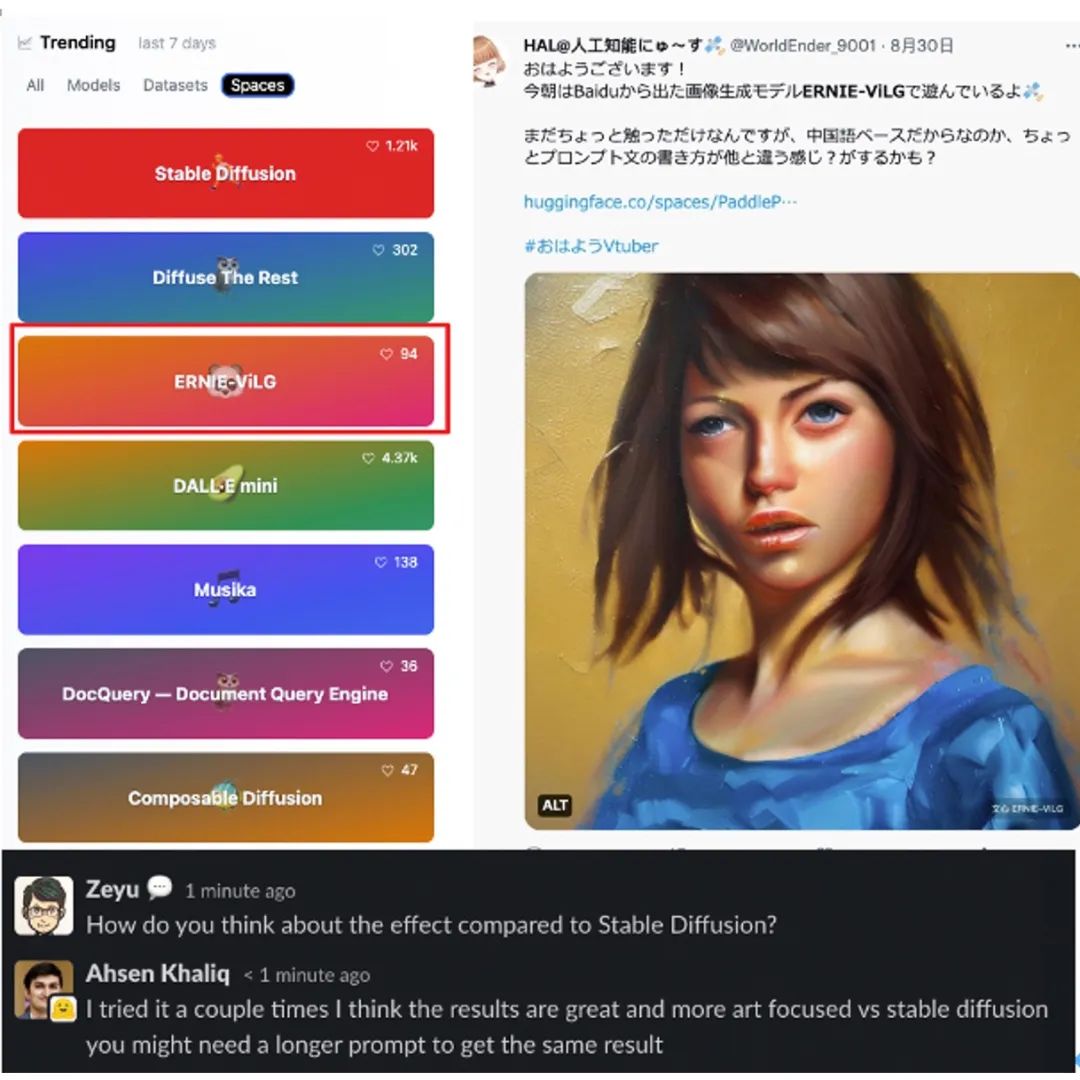
当前star 8.6k,大胆预判,这个项目肯定要火,在Hugging Face Space上已经登录Trending TOP3,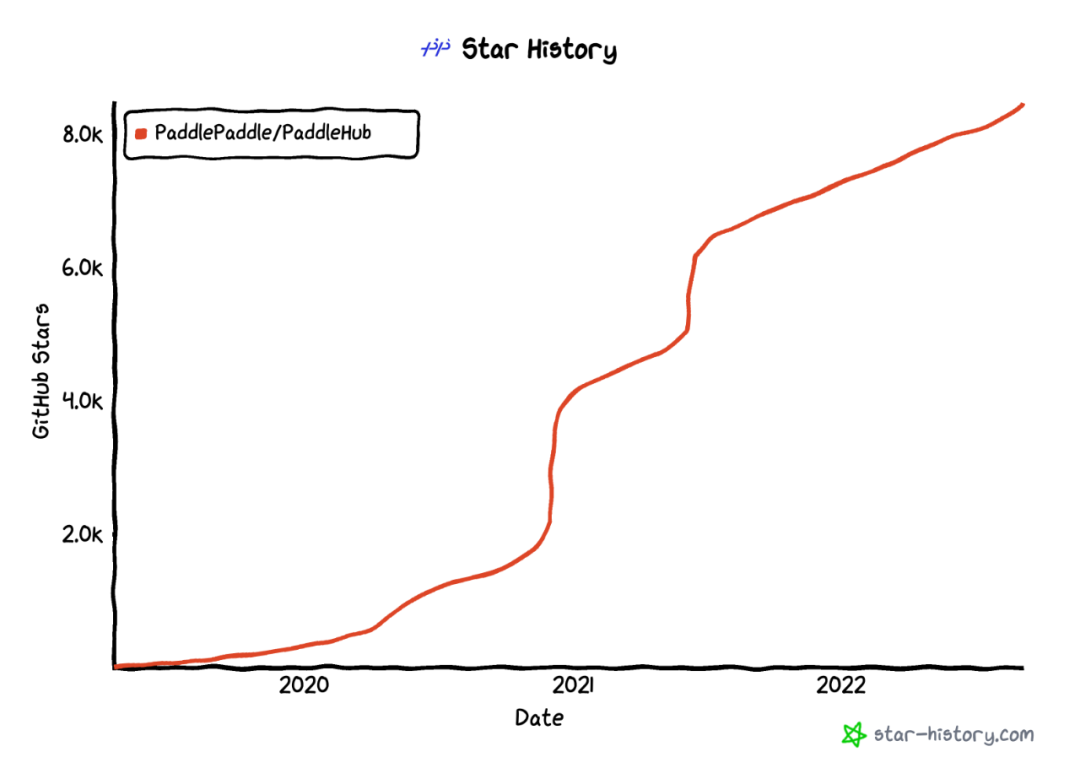
传送门:
https://github.com/PaddlePaddle/PaddleHub
话不多说,直接看效果:

prompt:古风华服少女,唯美,俏皮,火凤凰

prompt:日落时的城市天际线,秋天风格

prompt:巨大的纯白色城堡

prompt:a beautiful landscape photography of snow covered Rocky mountains,a dead intricate tree in the foreground,sunset,dramatic lighting,by Marc Adamus

prompt:close-up maximalist illustration of panther, by makoto shinkai, akihiko yoshida, yoshitaka amano, super detailed, hd wallpaper, digital art

prompt:clouds surround the mountains and Chinese palaces,sunshine,lake,overlook,overlook,unreal engine,light effect,Dream,Greg Rutkowski,James Gurney,artstation

prompt:在 artstation 上的一幅美丽的画,一个独特的灯塔,照耀着它的光穿过喧嚣的血海;由 greg rutkowski 和 thomas Kinkade 所做

prompt:孤舟蓑笠翁,独钓寒江雪, 水粉画

prompt:在宁静的风景中画一幅美丽的建筑画,由Arthur Adams在artstation上所做
以上惊艳的文图生成效果,是通过 PaddleHub 三行 Python 代码实现的作品:import paddlehub as hub
module = hub.Module(name="ernie_vilg")
results = module.generate_image(text_prompts=["巨大的白色城堡"])
本次PaddleHub v2.3.0开源ERNIE-ViLG、Stable-Diffusion(SD)、Disco-Diffusion的文生图大模型能力,将以上ernie_vilg替换为stable_diffusion或disco_diffusion_ernievil_base即可轻松体验不同的文图生成模型,用户也可自定义修改text_prompts来获得不同的效果体验。三行代码虽然简单,但是代码背后的文图生成模型可不简单,分别来源于现在文图生成领域最顶尖的开源成果:ERNIE-ViLG、Stable-Diffusion 以及 Disco Diffusion+ERNIE-ViL。
以 DD+ERNIE-ViL 为例,DD 扩散模型负责从初始噪声或者指定初始图像中来生成目标图像,ERNIE-ViL 负责引导生成图像的语义和输入的文本的语义尽可能接近,随着扩散模型在 ERNIE-ViL 的引导下不断的迭代生成新图像,最终能够生成文本所描述内容的图像。这种惊艳的效果,在 PaddleHub 这里只需要三行代码即可体验。也可以通过 huggingface 的 ERNIE-ViLG 空间体验,如图:








