蛋白水解靶向嵌合体 (PROTACs) 已成为通过使用泛素-蛋白酶体系统选择性降解疾病相关蛋白的有效工具。开发 PROTAC 涉及广泛的测试和试验,以探索广阔的化学空间。
为了加速这一过程,中山大学的研究团队提出了一种新的深度生成模型,用于在低资源环境中合理设计 PROTAC,然后通过深度强化学习引导对具有最佳药代动力学的 PROTAC 进行采样。
将这种方法应用于含溴结构域的蛋白质 4 靶蛋白,该团队生成了 5,000 种化合物,这些化合物通过基于机器学习的分类器和物理驱动的模拟进一步过滤。作为概念验证,研究人员鉴定、合成和实验测试了六种候选的含溴结构域的蛋白质 4 降解 PROTAC,其中三种通过基于细胞的测定和蛋白质印迹分析进行了验证。进一步测试了一种主要候选药物,并在小鼠中证明了良好的药代动力学。这种深度学习和分子模拟的结合可以促进合理的 PROTAC 设计和优化。
该研究以「Accelerated rational PROTAC design via deep learning and molecular simulations」为题,于 2022 年 9 月 15 日发布在《Nature Machine Intelligence》。

自 2001 年首次对蛋白水解靶向嵌合体(PROTACs)进行概念验证研究以来,PROTACs 已成为使用泛素-蛋白酶体系统选择性降解疾病相关蛋白的有效工具。
PROTAC 包含三部分:靶向目标蛋白 (POI) 的配体(弹头)、募集 E3 泛素连接酶的配体和连接两个配体的化学接头。由于这种异双功能结构,PROTACs 能够同时结合 POI 和 E3 连接酶,形成三元复合物并促进 POI 的多泛素化和降解。因此,PROTACs 只需要与靶蛋白瞬时结合即可诱导泛素化和降解,这与传统的占用驱动抑制剂不同,后者需要与靶蛋白的可药化位点具有足够的结合亲和力。
此外,PROTAC 不限于占据可成药的活性位点,因此有可能利用靶蛋白的所有表面结合位点来调节「不可成药」的靶点。因此,PROTAC 的合理设计比传统的小分子发现更具挑战性。
PROTACs的合理设计可以分为三个组件的设计。虽然弹头和 E3 配体的发现与常规小分子发现过程没有根本区别,但接头的设计在实验上具有挑战性,因为 POI 和 E3 连接酶在没有有效 PROTAC 的情况下不会相互作用。传统方法必须通过大量的测试和试验来设计新的 PROTAC,效率极低。最近的许多努力通过生成接头将目标转移到从头 PROTAC 设计,因为越来越多地知道接头对 PROTAC 的物理化学性质和降解活性至关重要。
不幸的是,由于三元结构的结构复杂性和动力学,连接器设计仍然是一项艰巨的挑战。阻止 PROTAC 实现其治疗潜力的另一个主要挑战是设计的分子不符合与口服药物相关的公认药物特性。由于 PROTAC 的大而灵活的性质,增强药代动力学(PK)的工程已被证明具有挑战性。因此,需要新的方法来提高新功能 PROTAC 的发现率。
在对化学空间进行智能探索的基础上,深度生成模型的最新突破使从头分子设计得到了极大的推进。各种生成神经网络,例如循环神经网络、变换神经网络、自动编码器和生成对抗网络,已被证明可有效生成所需的小分子、肽和抗体。
这些策略也已用于生成 PROTAC 的链接器。例如,之前 Imrie 团队开发了一种基于图形的深度生成器 (DeLinker),将三维 (3D) 结构信息直接整合到设计过程中;同时,Yang团队将链接器设计转化为句子完成任务,并引入语言模型(SyntaLinker)来生成新的链接器,给定命中片段的简化分子输入行输入系统(SMILES)。这两种方法都演示了为从头 PROTAC 设计生成各种链接器。
然而,这些方法仅限于对小分子的训练,没有考虑小分子和 PROTAC 在设计策略和化学空间上的差异。此外,他们没有考虑生成分子的药物代谢和 PK 特性。
这部分是因为 PROTAC 公开可用的数据量极少。例如,目前最大的开源 PROTAC 数据库仅包含 2,300 个样本,只涵盖了化学空间的一小部分。考虑到如此小的样本量,训练一个能够同时生成具有所需属性和多样性的新型 PROTAC 的模型具有挑战性。更重要的是,这些先前的生成模型都没有实现涉及合成用于体外或体内测试的新型 PROTAC 的实验验证。
在新的研究工作中,中山大学的研究团队开发了 PROTAC-RL,这是一种新颖的深度生成模型,它结合了增强型 transformer 架构和记忆辅助强化学习(RL),用于合理的 PROTAC 设计。该模型将一对 E3 配体和弹头作为输入和输出设计的接头,以生成具有良好性能的化学可行 PROTAC。
为了克服训练数据量少的问题,研究人员首先使用具有类似于 PROTAC 的化学空间的大量准 PROTAC 小分子集合,使用 transformer 神经网络预训练片段链接模型,通过使用带有随机 SMILES 片段的实际 PROTAC 进行微调。
然后将这个经过训练的 Proformer 模型输入到具有经验奖励函数的记忆辅助 RL 中,以生成具有更好 PK 属性的 PROTAC。作为概念验证,研究人员选择了含溴结构域的蛋白 4 (BRD4) 靶蛋白,并生成了 5,000 个 PROTAC,通过分层机器学习分类器和物理驱动的分子模拟进一步聚类和筛选。
根据合成的可及性,研究人员合成并实验测试了六种 BRD4 降解 PROTAC,其中三种显示出对 BRD4 的抑制活性。一个主要候选者同时表现出对 Molt4 细胞系的高抗增殖效力和对小鼠的有利 PK。这一快速发现(在 49 天内)凸显了深度学习和分子动力学相结合对促进高效 PROTAC 设计和优化所产生的重大影响。
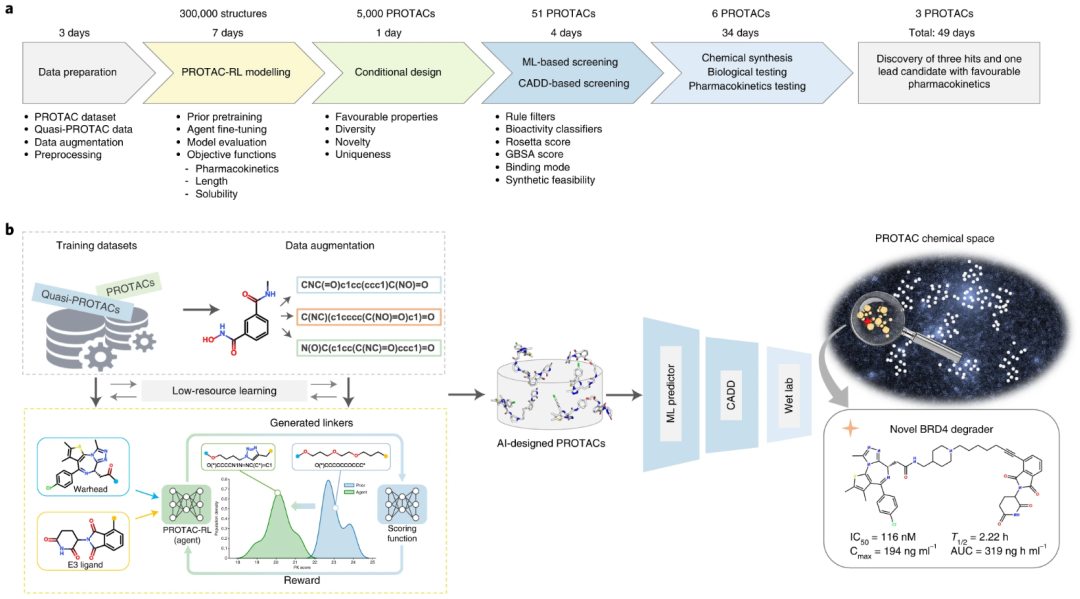
这项概念验证研究中的设计方法产生了 50% 的成功率和 49 天的快速周转时间,突出了将人工智能驱动的计算策略与实验相结合以实现更有效的候选药物的重要性。
由于提出的模型 PROTAC-RL 是一种通用方法,它适用于广泛的条件生成任务,并且可以同时处理多个目标函数。因此,本研究的未来方向将探索其他相关约束条件(例如细胞渗透能力或口服生物利用度)对使用本文介绍的方法设计的 PROTAC 的影响。
在当前框架下,PROTAC-RL 也有几个潜在的限制。首先,作为 RL 方法,奖励函数的设计对输出至关重要。然而,由于 PROTAC 属性预测的实验数据不足,鲁棒预测器的选择将受到限制。一种选择是使用一些半经验的评分函数,如本研究所示。另一种选择是应用对接评分函数来指导模型生成潜在的候选者。其次,当前的三元复数建模仍然依赖于物理驱动的模拟。
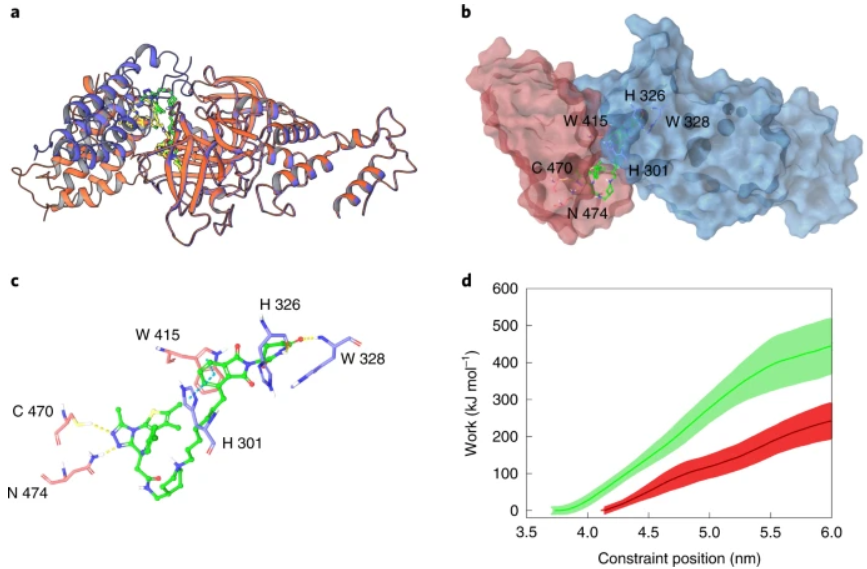
图示:结合模式分析和原子模拟。(来源:论文)
正如结果显示的那样,通过对接获得的最佳结果不一定是活跃的,并且已证明可控的分子动力学是有帮助的。超级计算机的快速发展可能会促进对广泛建模模拟的需求。另一个值得尝试的替代方法是使用最近的基于深度学习的绑定预测方法。第三,附着位点从根本上影响降解和选择性。PROTAC-RL 目前遵循先前方法的设置,这些方法根据先前的生物活性数据预定义附着位点。
当晶体结构可用时,从这些高分辨率共晶结构中识别出的溶剂暴露位置可以确定为附着位点。否则,可以通过发现结构-活性关系的数据并结合可解释的人工智能和分子动力学模拟的检查来确定合适的附着点。最后,蛋白质结构预测和蛋白质-蛋白质相互作用预测方面的进展可能使三元复杂结构的建模更加准确。
总体而言,该团队的结果表明,将现代深度学习方法应用于 PROTAC 发现的时机已经成熟。这些努力可以提高发现新分子实体的速度,减少识别这些分子所需的资源并降低相关成本。相信该工作中描述的策略将激发未来的 PROTAC 设计工作。
论文链接:https://www.nature.com/articles/s42256-022-00527-y
人工智能 ×
[ 生物 神经科学 数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。






