Pix2Text (https://github.com/breezedeus/pix2text) 期望成为 Mathpix 的免费开源 Python 替代工具,完成与 Mathpix 类似的功能。当前 Pix2Text 可识别截屏图片中的数学公式、英文、或者中文文字。它的流程如下:
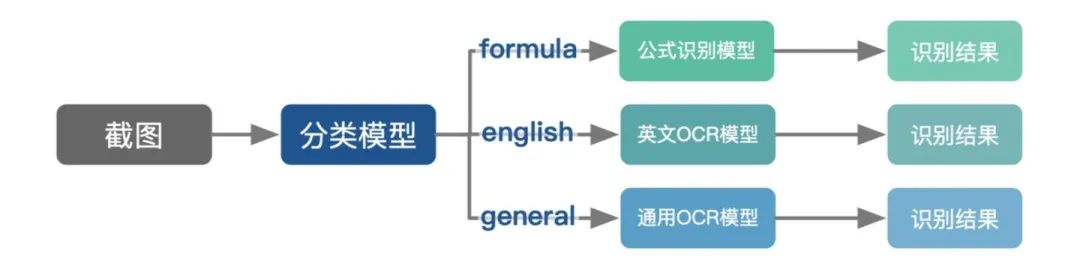
Pix2Text 首先利用图片分类模型来判断图片类型,然后基于不同的图片类型,把图片交由不同的识别系统进行文字识别:
如果图片类型为 formula ,表示图片为数学公式,此时调用 LaTeX-OCR 识别图片中的数学公式,返回其 Latex 表示;
如果图片类型为 english,表示图片中包含的是英文文字,此时使用 CnOCR (https://github.com/breezedeus/cnocr) 中的英文模型识别其中的英文文字;英文模型对于纯英文的文字截图,识别效果比通用模型好;
如果图片类型为 general,表示图片中包含的是常见文字,此时使用 CnOCR 中的通用模型识别其中的中或英文文字。
后续图片类型会依据应用需要做进一步的细分。
欢迎扫码加小助手为好友,备注 p2t,小助手会定期统一邀请大家入群:

作者也维护 知识星球 P2T/CnOCR/CnSTD 私享群 (https://wx.zsxq.com/dweb2/index/group/28858522821151),这里面的提问会较快得到作者的回复,欢迎加入。知识星球私享群也会陆续发布一些 P2T/CnOCR/CnSTD 相关的私有资料,包括更详细的训练教程,未公开的模型,不同应用场景的调用代码,使用过程中遇到的难题解答等。本群也会发布 OCR/STD 相关的最新研究资料。
使用说明
调用很简单,以下是示例:
from pix2text import Pix2Text
img_fp = './docs/examples/formula.jpg'
p2t = Pix2Text()
out_text = p2t(img_fp) # 也可以使用 `p2t.recognize(img_fp)` 获得相同的结果
print(out_text)
返回结果 out_text 是个 dict,其中 key image_type 表示图片分类类别,而 key text 表示识别的结果。
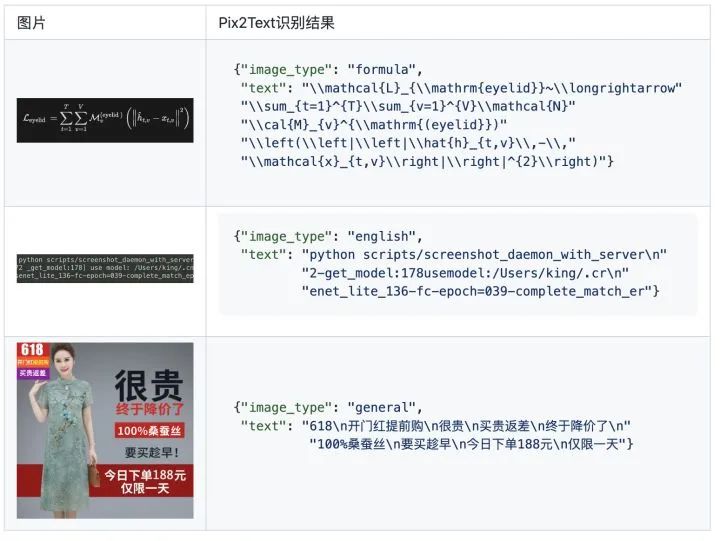
以下是一些示例图片的识别结果:
模型下载
安装好 Pix2Text 后,首次使用时系统会自动下载 模型文件,并存于 ~/.pix2text 目录(Windows 下默认路径为 C:\Users\\AppData\Roaming\pix2text)。
Note如果已成功运行上面的示例,说明模型已完成自动下载,可忽略本节后续内容。
对于分类模型,系统会自动下载模型 zip 文件并对其解压,然后把解压后的模型相关目录放于 ~/.pix2text 目录中。如果系统无法自动成功下载 zip 文件,则需要手动从 cnstd-cnocr-models/pix2text 下载此 zip 文件并把它放于 ~/.pix2text 目录。如果下载太慢,也可以从 百度云盘 下载, 提取码为 p2t0。
对于 LaTeX-OCR ,系统同样会自动下载模型文件并把它们存放于 ~/.pix2text/formula 目录中。如果系统无法自动成功下载这些模型文件,则需从 百度云盘 下载文件 weights.pth 和 image_resizer.pth, 并把它们存放于 ~/.pix2text/formula 目录中;提取码为 p2t0。
安装
嗯,顺利的话一行命令即可。
pip install pix2text
安装速度慢的话,可以指定国内的安装源,如使用豆瓣源:
pip install pix2text -i https://pypi.doubanio.com/simple
如果是初次使用 OpenCV,那估计安装都不会很顺利,bless。
Pix2Text 主要依赖 CnOCR>=2.2.2 ,以及 LaTeX-OCR 。如果安装过程遇到问题,也可参考它们的安装说明文档。
Warning如果电脑中从未安装过 PyTorch,OpenCV python 包,初次安装可能会遇到不少问题,但一般都是常见问题,可以自行百度 / Google 解决。
接口说明
类初始化
主类为 Pix2Text ,其初始化函数如下:
class Pix2Text(
object):
def __init__(
self,
*,
clf_config: Dict[str, Any] = None,
general_config: Dict[str, Any] = None,
english_config: Dict[str, Any] = None,
formula_config: Dict[str, Any] = None,
thresholds: Dict[str, Any] = None,
device: str = 'cpu', # ['cpu', 'cuda', 'gpu']
**kwargs,
):
其中的各参数说明如下:
clf_config (dict): 分类模型对应的配置信息;
general_config (dict): 通用模型对应的配置信息;
english_config (dict): 英文模型对应的配置信息;
formula_config (dict): 公式识别模型对应的配置信息;
thresholds (dict): 识别阈值对应的配置信息;
device (str): 使用什么资源进行计算,支持 ['cpu', 'cuda', 'gpu'];默认为 cpu
**kwargs (): 预留的其他参数;目前未被使用。
识别类函数
通过调用类 Pix2Text 的类函数 .recognize() 完成对指定图片的文字或 Latex 识别。类函数 .recognize() 说明如下:
def recognize(self, img: Union[str, Path, Image.Image]) -> Dict[str, Any]:
"""
Args:
img (str or Image.Image): an image path, or `Image.Image` loaded by `Image.open()`
Returns: a dict, with keys:
`image_type`: 图像类别;
`text`: 识别出的文字或Latex公式
"""
其中的输入参数说明如下:
返回结果说明如下:
如前面给出的一个示例结果:
{"image_type": "general",
"text": "618\n开门红提前购\n很贵\n买贵返差\n终于降价了\n"
"100%桑蚕丝\n要买趁早\n今日下单188元\n仅限一天"}
Pix2Text 类也实现了 __call__() 函数,其功能与 .recognize() 函数完全相同。所以才会有以下的调用方式:
from pix2text import Pix2Text
img_fp = './docs/examples/formula.jpg'
p2t = Pix2Text()
out_text = p2t(img_fp) # 也可以使用 `p2t.recognize(img_fp)` 获得相同的结果
print(out_text)
HTTP 服务
Pix2Text 加入了基于 FastAPI 的 HTTP 服务。开启服务需要安装几个额外的包,可以使用以下命令安装:
pip install pix2text[serve]
安装完成后,可以通过以下命令启动 HTTP 服务(-p 后面的数字是端口,可以根据需要自行调整):
p2t serve -p 8503
服务开启后,可以使用以下方式调用服务。
命令行
比如待识别文件为 docs/examples/english.jpg,如下使用 curl 调用服务:
> curl -F image=@docs/examples/english.jpg http://0.0.0.0:8503/pix2text
Python
使用如下方式调用服务:
import requests
image_fp = 'docs/examples/english.jpg'
r = requests.post(
'http://0.0.0.0:8503/pix2text', files={'image': (image_fp, open(image_fp, 'rb'), 'image/png')},
)
out = r.json()['results']
print(out)
其他语言
请参照 curl 的调用方式自行实现。
脚本运行
脚本 scripts/screenshot_daemon.py 实现了自动对截屏图片调用 Pixe2Text 进行公式或者文字识别。这个功能是如何实现的呢?
以下是具体的运行流程(请先安装好 Pix2Text):
找一个喜欢的截屏软件,这个软件只要支持把截屏图片存储在指定文件夹即可。比如 Mac 下免费的 Xnip 就很好用。
除了安装 Pix2Text 外,还需要额外安装一个 Python 包 pyperclip,利用它把识别结果复制进系统的剪切板:
下载脚本文件 https://github.com/breezedeus/pix2text/blob/main/scripts/screenshot_daemon.py 到本地,编辑此文件 "SCREENSHOT_DIR" 所在行(第 17 行),把路径改为你的截屏图片所存储的目录。
运行此脚本:
$ python scripts/screenshot_daemon.py
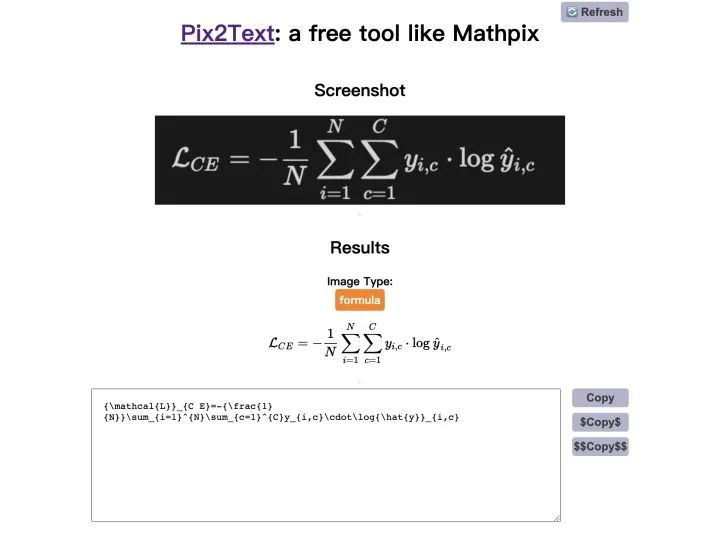
好了,现在就用你的截屏软件试试效果吧。截屏后的识别结果会写入当前文件夹的 out-text.html 文件,只要在浏览器中打开此文件即可看到效果。
Note
感谢我的同事帮忙完成了此页面的大部分工作。这个页面还有很大改进空间,欢迎对前端熟悉的朋友帮忙提 PR 优化此页面。
更详细使用介绍可参考视频:
官方代码库:https://github.com/breezedeus/pix2text 。
更多信息:









