分享嘉宾:熊昊一&李徐泓 百度
编辑整理:宋迪 安徽大学
出品平台:DataFunTalk
导读:深度学习在物体识别、医学影像检测、自动驾驶、语音助手、机器翻译和广告营销等方面广泛应用,但也存在一些亟待解决的问题。本文将分享百度研究院大数据实验室在自动化与可解释深度学习方面做的一些工作,包括一些原创性的科研突破和开源的应用实例。
今天的介绍会围绕下面四点展开:
首先分享一下深度学习的应用场景以及存在的问题。
1. 深度学习的应用场景

深度学习在业界内应用场景十分广泛,包括物体识别、医学影像检测、自动驾驶等等。
2. 深度学习的发展与挑战
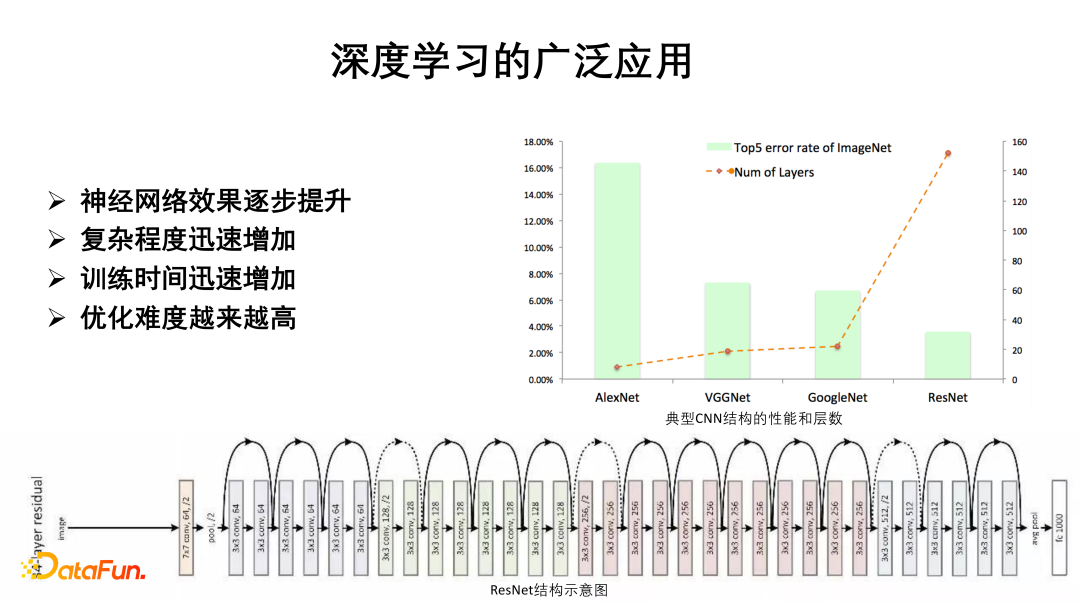
Resnet、Googlenet等经典的深度学习网络其参数量增长非常迅速,但在ImageNet上进行监督训练,模型性能的提升随着过参数化的深入反而只是呈现缓慢的增长。
3. AutoDL的目标
① 端到端深度学习模型自动化设计
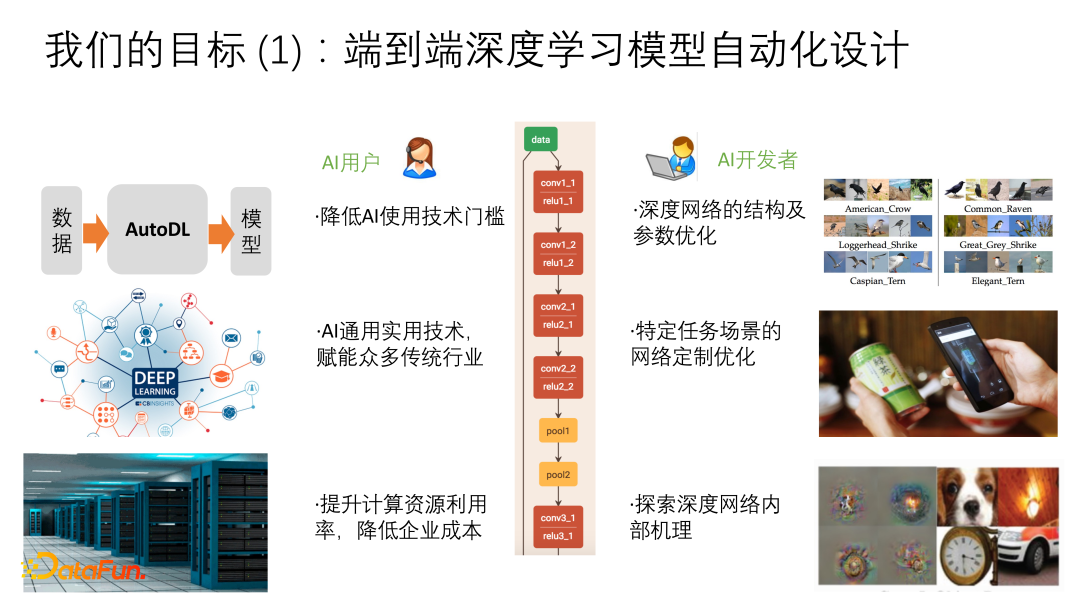
深度学习的过于复杂造成了AI的使用门槛较高。首先是对算力有较高要求。过去的统计学习在CPU即可进行,但深度学习则需要使用更多的计算资源,比如GPU。
其次深度学习涉及到模型选择和训练时的配置。DataScience年代中使用SVM做任务时不会设计模型结构,仅需一行代码就可以配置一个很好的SVM,但deep learning包含太多内容,如网络架构、参数初始化、normalization,以及batch size、learning rate或者其它超参的调优选择等。因此很难简单地进行配置描述,使得AI开发者之间造成割裂,提升开发成本。
② 提高机器学习的可解释性与安全性
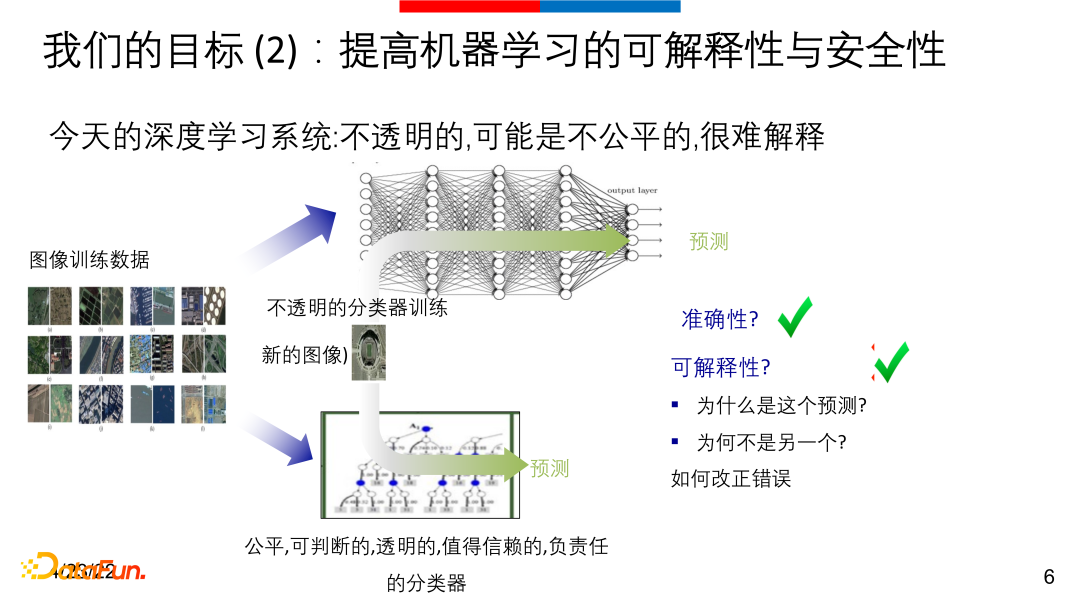
深度学习的另一个问题在于深度学习系统预测较准确,但其实是一个非常不透明的分类器,其预测结果不可解释。传统的XGboost、KNN等经典方法总有方法可以从逻辑、特征、重要性和哪些样本影响最后的决策上可以解释这些分类器。
因此在我们看来,自动化和可解释性是深度学习最重要的两个问题。
02
AutoDL在PaddlePaddle与PaddleHub上的重要角色
今天主要介绍上图中关于AutoDL的3个内容。
1. AutoDL Design
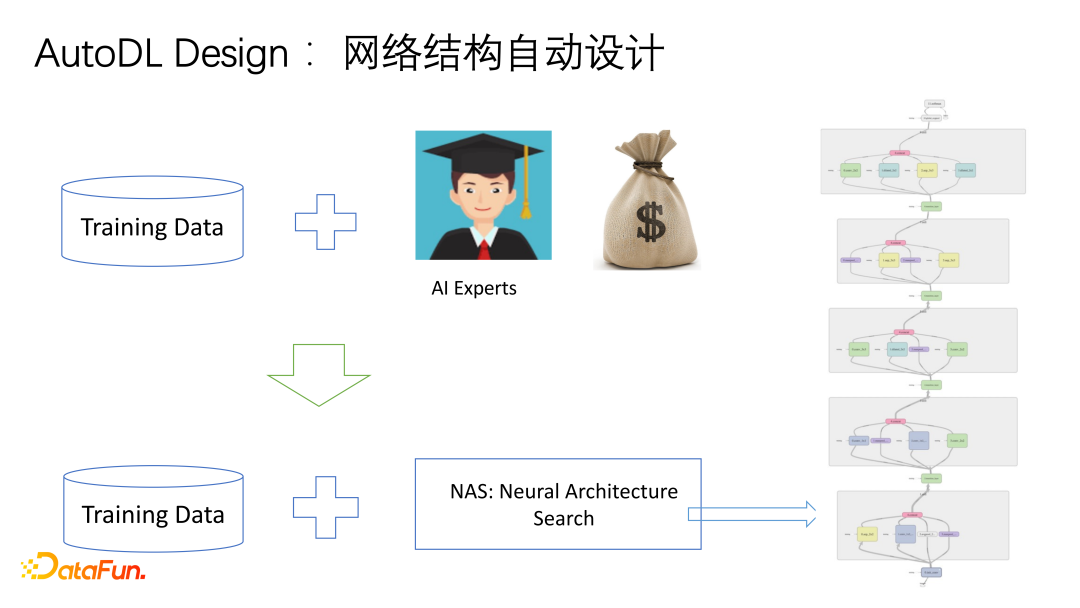
AutoDL Design即自动化设计,当有足够多的training data和很好的网络结构搜索空间与搜索算法时,就可以找到很好的模型,但我们的目标是想要找出一种方法自动化地设计出模型并调优调参。
① 现有技术

贝叶斯优化、多臂赌博机、RNN强化学习以及遗传算法等都是很好的深度学习算法。
② 阶段性成果

2019年AutoDL Design的分类网络在cifar、imagenet数据集上取得了预料中的好效果。
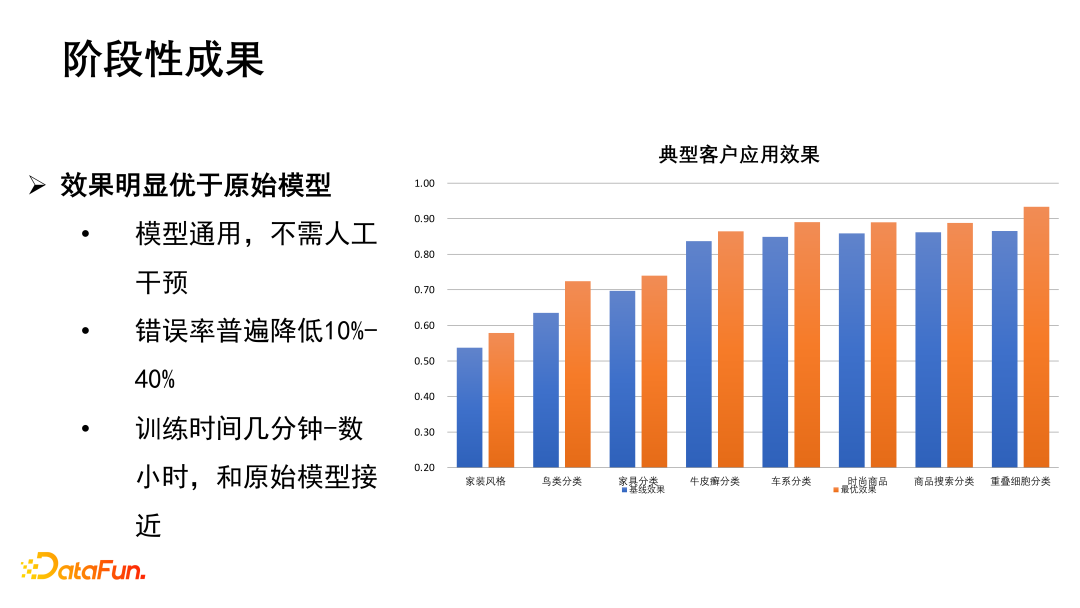
此外AutoDL Design可以解决一些客户的需求,如客户的数据量不足,根据客户提供的数据将错误率降低10%-40%等。
③ 视觉风格迁移网络
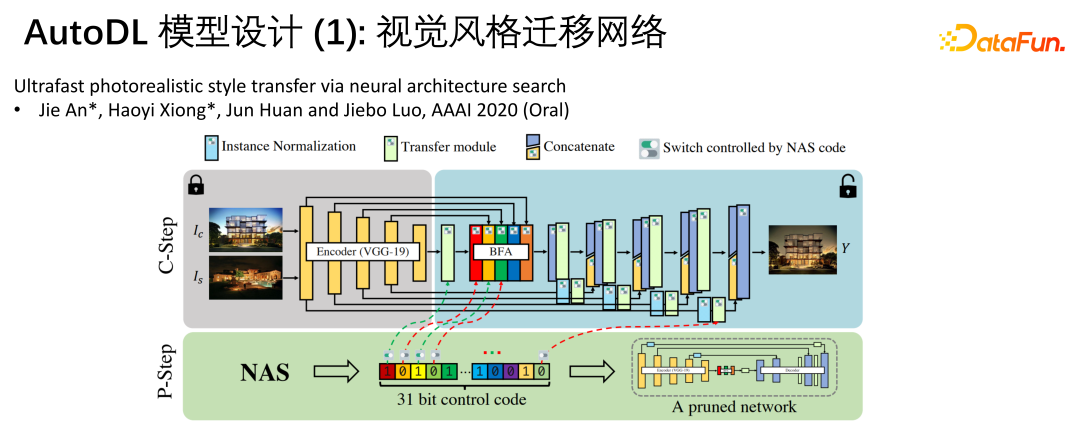
我们最早开始做生成模型自动化设计,如视觉风格迁移模型。视觉迁移,也就是将风格(style)图片上的风格迁移到内容(content)图片上,如将一张照片渲染成梵高的绘画风格。
生成模型网络最大的问题是模型太大了,很难实时地做rendering。如果给定的不是图片,而是一段video,想要对每一帧的图片进行风格迁移,在当时是很难实现的。
我们提出了使用NAS(neural architecture search)的方法来搜索合适的网络解决问题,但首先需要有一个搜索空间,即这个网络是哪个空间的子集。这个搜索空间要足够大,在风格迁移这个问题上,搜索空间有2^31大,有很多option和connection,connection有些可以打断,有些继续参与连接。基本上Auto Encoder有很多一层层的stack encoder和stack decoder,中间还有许多控制参数。
这里的架构搜索其实是pruning,搜索的是子网络或者是切割后的网络。搜索目标这里定义的是生成出的图片的清晰度、质量(feature score、inception score)、图片的丰富程度等。使用一些搜索算法在2^31的搜索空间中计算出一个小网络。比如搜索目标是图片质量可以加上正则,这个正则可以是计算出来的小网络的复杂度或小网络的推理运行时间,然后将这两个目标加权在一起,这样就可以得到一个很好的平衡图像质量和网络复杂度的object,从而搜索到较好的网络。

上图左上角第一张小图是曼哈顿白天的照片,第二张小图是香港夜晚的照片,我们希望将香港夜晚的风格迁移到曼哈顿白天的照片上。传统的方法如DPST、WCT2等都需要给定一个mask。而我们的算法比如PhotoNet、PhotoNet-Auto等使用搜索空间搜索到的网络不需要给定mask也可以很好地对图片进行处理。
又比如上图中自行车需要从较艳丽的风格迁移成昏暗的风格,搜索出来的网络capacity非常高,可以看到PhotoNet-Auto中,车轮这种以往需要抠图处理的现在可以自动处理了。
对于风格迁移所诟病的速度问题,传统的PhotoWCT等处理一张256x128的图片需耗时4.38秒,而搜索出来的styleNAS-5opt仅需0.05秒。也就是说styleNAS-5opt 1秒可以处理20帧,达到了准实时处理视频。对于1024x512的图片,PhotoWCT甚至需要153.25秒才能处理一张图片,而styleNAS-5opt仅需0.23秒,虽然时间仍较长,但可以通过多张GPU并行计算,也可以达到准实时渲染的程度。
总之通过搜索空间搜索到的小网络还是可以达到很好的低延时渲染的效果。
④ 人像pose生成网络
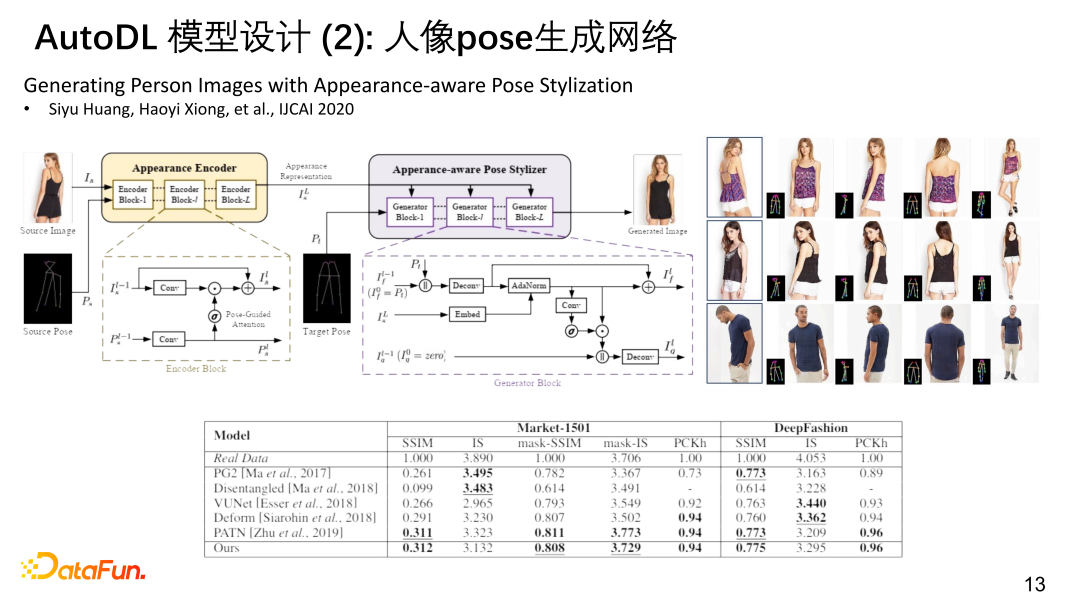
基于相似的逻辑,我们又设计了人像生成网络,当然也会有大规模的架构搜索过程获取一些基本的架构,encoder是人的照片和骨架,decoder是目标骨架。而这需要在大规模的数据集上训练,然后去rendering目标骨架上的形象。搜索也可以做Auto encoder 这么复杂的图像生成的网络。
⑤ 推荐系统网络推理优化
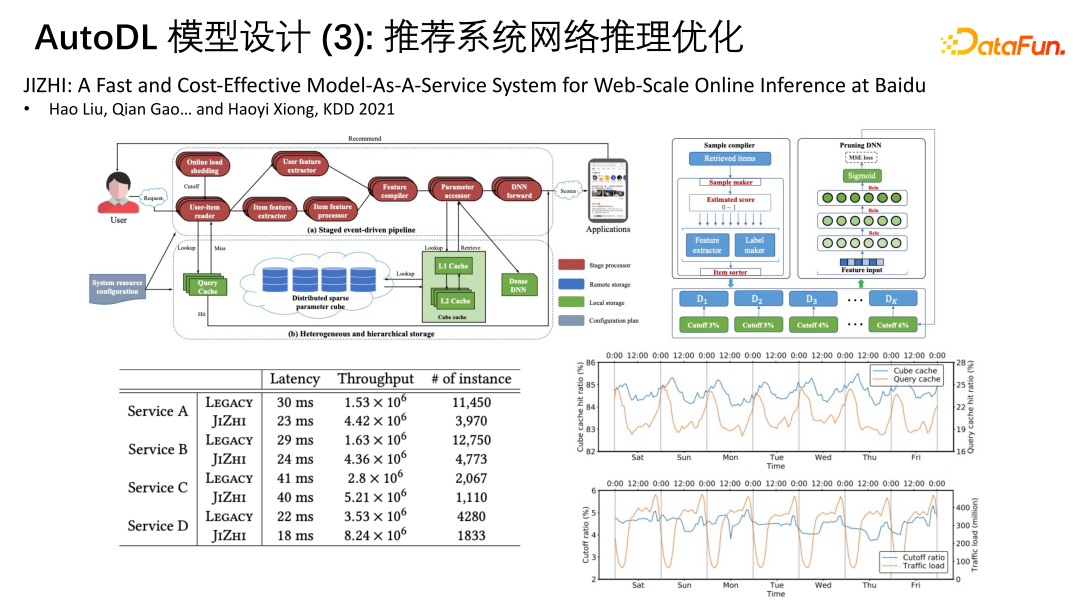
众所周知,百度也是一家搜索推荐公司,我们有很大的web-scale online inference 系统针对recommender system。推荐系统其实是一个online的对延时性有一定要求的DNN。以百度的流量来看,做到低延时的推荐在计算资源方面是受限的,不能持续性的投入新的计算资源来服务。受限于 inference time 的要求,有时候需要些dynamic pruning。对于一些大规模稀疏特征的网络的参数很多时候是以 key value 的形式存在于database中,features也是一些signatures等,在做动态推理时就会有一些dynamic pruning,对于一些长尾特征或其对应的权重,在一些非常急迫的情况下需要cut off,动态的proving掉,可能还会涉及到catch超参数的设计。此外,pipeline上有许多节点,每个节点每一次做inference时是按batch进行的,batchsize的设定需要根据服务的节点、流量特征进行动态调整,对每个pipeline的服务节点打包成microservice,微服务的虚拟机是不知道的,decode量与算力在微服务上,占总池子资源多少也是不清楚的。
所以AutoDL除了设计网络架构,还可以动态设计异构推理的流水线,动态调配计算资源在每个节点的投入。另外也可以动态调整catch的策略和一些超参数,以及在算力紧张时对一些长尾稀疏特征的cut off或key value损失掉,但并不导致精度下降。因此,我们的系统叫作“JIZHI“,急中生智,在有限的系统条件下快速找到合适的模型网络。
上图左下角可以看到百度的LEGACY和JIZHI在性能上的区别,比如Latency、吞吐量和instance。
JIZHI的原理是摄取整个pipeline的配置,有时无法在线摄取,就需要先有一个simulator,对资源投入、参数配置、端到端性能进行模拟,先把模拟器搭起来,暴露足够多的超参数,然后再去search。这个模拟器可以根据超参数、web traffic的情况模拟出大概的资源消耗、throughput和延时情况,据此寻找出新的最优流水线配置,使其性能达到最好。
JIZHI这个项目中的throughput基本都有提高,latency基本都下降,instance物理级的个数也都下降了,符合互联网行业的特点,即流量是有上限的,不可能一直增加。JIZHI就是AutoDL在工业界最大规模的应用。
⑥ 如何使用这些模型
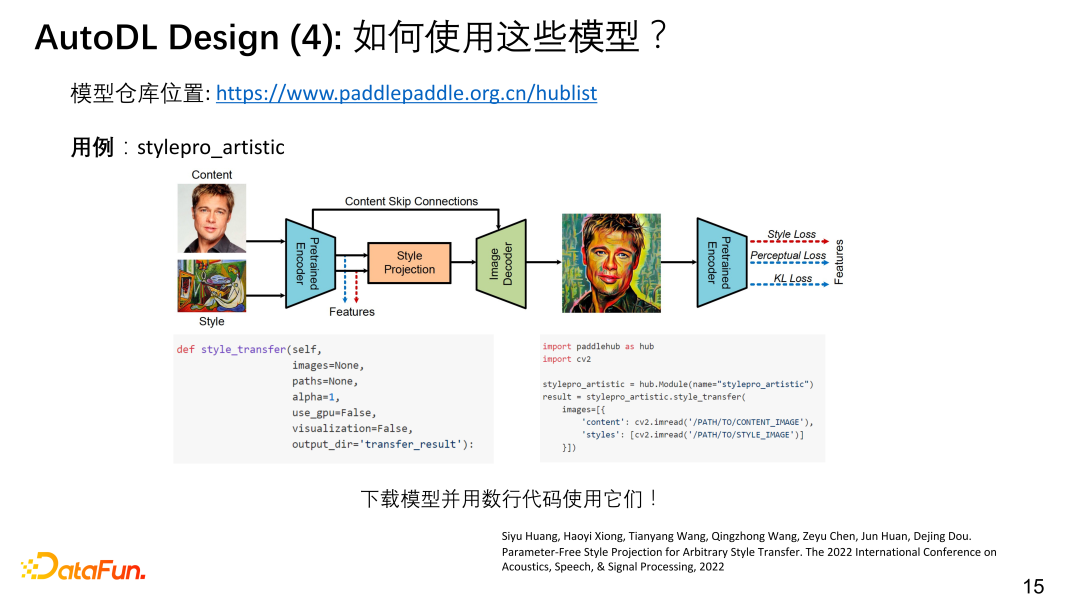
大家都知道“PPT” (PaddlePaddle、PyTorch、TensorFlow)中的PaddlePaddle飞桨,如果大家想用我们搜索出来的一些不错的模型,可以去我们的模型仓库中寻找,比如风格迁移的模型,几行代码就可以嵌入到自己的软件中。
2. AutoDL Transfer
下面介绍AutoDL Transfer 迁移学习。
大部分迁移学习都要基于预训练模型,比如传统的基于imagenet做训练的模型等。现在有很多新的数据集,比如BERT、RoBERTa或百度的ERNIE这种NLP大规模模型,特别是NLP领域非常依赖大模型的使用,一个好的大模型非常节省开发人员的精力、时间还有资源投入。
另外一些视觉模型,比如vison transform 、MME等都有新的features。
① AutoDL迁移学习的基本概念算法与创新算法
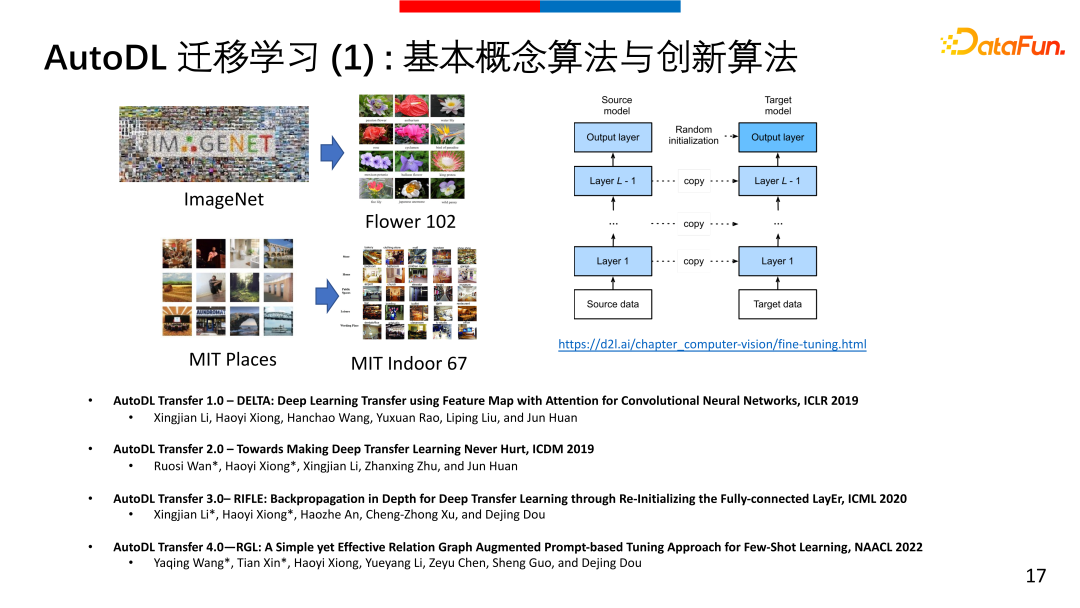
关于AutoDL 迁移学习我们已经迭代了3个版本,基本的想法是用ImageNet或其他数据训练一个模型,比如CNN模型或者Transform模型,我们把它训练好,这个模型可以adapt到大数据的任务上,也可以对给定的如MIT Place365、flower102等小问题的数据使用。对传统的统计学习上来说,迁移学习非常的复杂,但对深度学习来说,可以是很简单的问题。本质上是用大数据集训练得到一个模型,然后将模型backbone到小数据上,将最后一层或head换成所需要的head,再进行一些精调,以这个模型为起点,再在小数据集上去训练,结果要比自己从随机初始化做起得到的模型效果要好很多。
我们的创新就在于提供了3种新的正则:
第一种叫DELTA,Deep learning transfer using feature maps with attention for convolutional neural network,提供了一种知识蒸馏,不光使用预训练的模型的权重进行初始化,还使用feature map用来蒸馏teacher network或者feature map,不仅如此,还要对哪些有用的feature map 进行判断。我们找到了一种新的feature selection 的方法:先把teacher network中的 feature map 进行甄别能否帮助分类新的任务,如果可以就将这些feature map 放入积极蒸馏的正则中,否则就drop out,这样得到AutoDL Transfer 1.0。
AutoDL Transfer 2.0 版本解决的是Negative Transfer。使用预训练模型在下游任务上进行迁移,有时会产生越迁移越坏的情况,叫做负面迁移(negative transfer)。即使使用weight decay,或者用 L2-SP,即以原始的预训练模型的backbone的权重为weight decay的中心点,又或者DELTA,这种负面迁移的现象都无法缓解。我们发现negative transfer 的原因是正则梯度方向和真正的目标的梯度方向超过了90°,正则结果与训练数据集的目标方向夹角过大的时,约束力就会产生negative transfer,我们采用了一些几何方法,使用decompose将与loss相抵触的部分的分量drop out从而避免negative transfer的发生。
AutoDL Transfer 3.0版本提出的是RIFLE,我们发现迁移学习有时很难改变深层次的特征,back propagation不太能改变原始的权重,这时可以将FC层重置,重新初始化变为random再进行propagation,这样周期性的BP和随机初始化,可以提升性能。75%的epoch是周期性的进行重置,最后25%的epoch完全的Finetune,这样最后可以达到一个很好的效果。
② AutoDL迁移学习提供PaddleHub精调API

AutoDL这3个版本现已集成到PaddleHub平台上,并且提供两种使用方法。一是无需编程的脚本方案,我们有预训练好的模型、codes,只要知道需要的预训练模型、所需的精调、适配情况,只需要一行命令行就可以Finetune。二是以编程为基础的方案,PaddleHub提供的API,主要是3个部分,Load pre-trained models、Load datasets以及Set models and run,调整一下learning rate、batch size等,只需不超过20行代码就可以加载好预训练模型、数据集。
③ AutoDL迁移学习:通过EasyDL实现基于云的线上专业
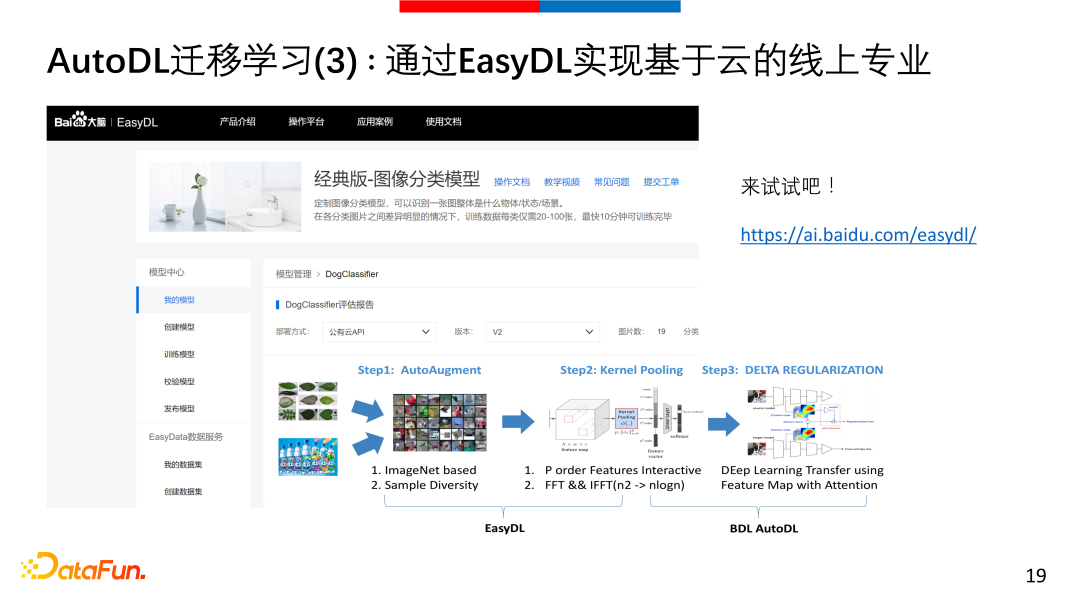
此外我们还提供了EasyDL平台,无需编程,节省算力,直接实现云上的AutoDL。并且EasyDL还提供了许多针对不同行业的预训练模型,可以很快的适配小数据,解决大问题。
3. AutoDL Interpretability
最后介绍一下Interpretability,训练过程和深度学习表现的分析架构太过复杂,有时结果并不可信。
① AutoDL可以解释模型
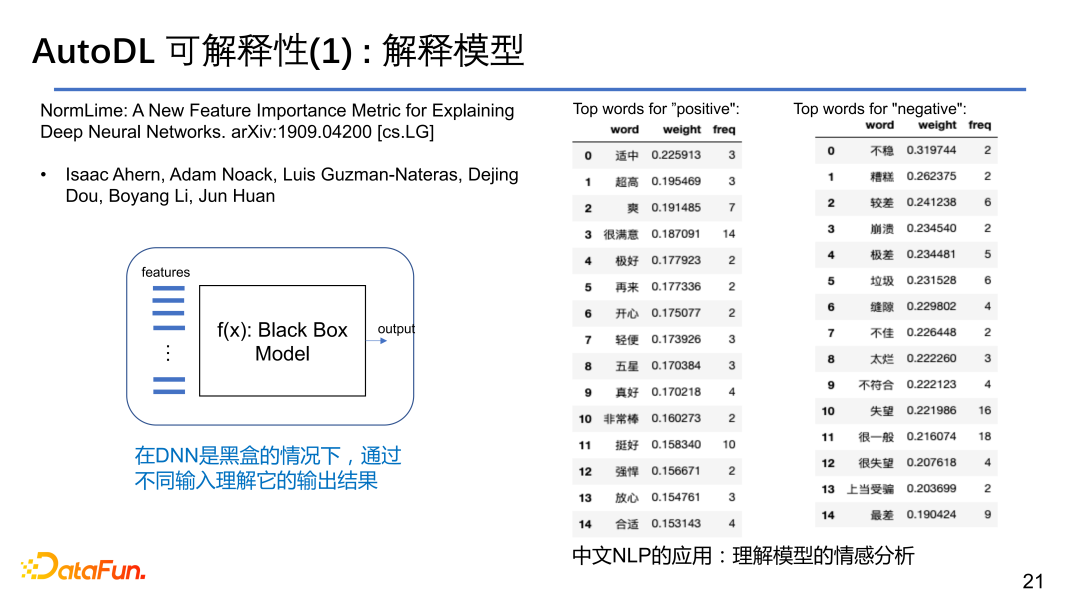
以NLP的任务为例,给定一个sentence评定其正面情绪还是负面情绪,需要知道是根据哪个字或词导致评定结果的。我们有一套新的NormLIME的方法来评定。
LIME指的是经过稍微扰动feature space的输入,对应地分析输出的变化,以此来探究是哪些feature 改变了模型的输出结果,这样就能解释 feature 对于模型的重要度。LIME的思想是深度学习在某一数据点上是可以用线性模型来进行解释的,在该数据点上进行展开并进行线性的拟合,然后比较各个特征对输出结果的贡献情况,从而解释在模型做决策时首先使用了哪些特征,如果不使用这个特征的结果是什么,比如对于logit的输出变化是正的还是负的。
② AutoDL可以解释训练过程
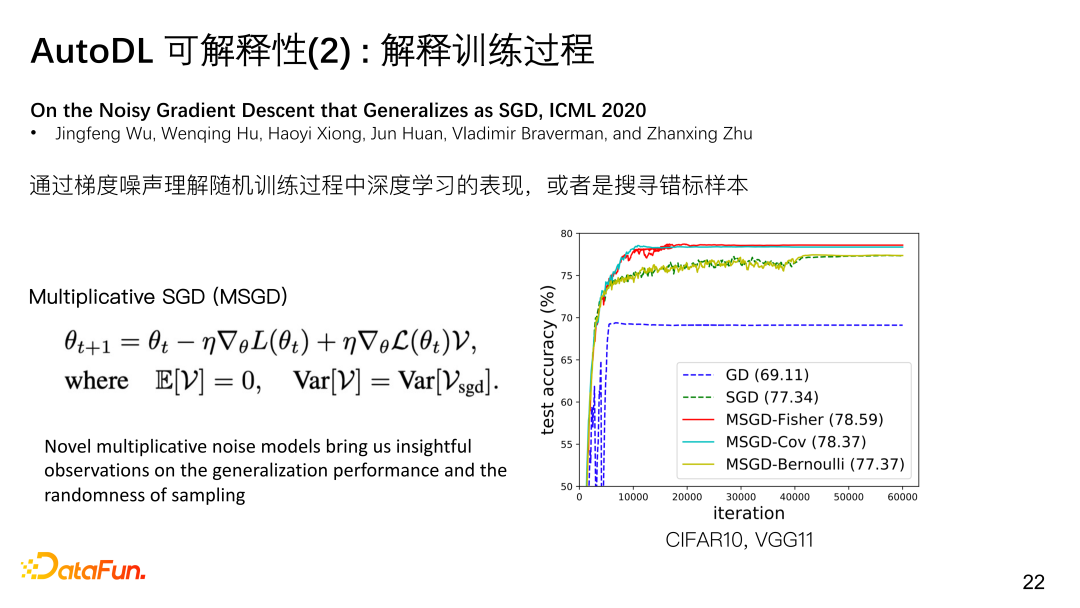
此外对于解释训练过程,训练过程中整个loss、accuracy是一个向上的振动曲线,我们想要从曲线中知晓模型泛化性如何;样本的loss曲线抖动异常可能是因为样本错标,对此我们在ICML上发表了一篇文章,探讨了其可能性。
③ AutoDL可以通过PaddleX解释模型
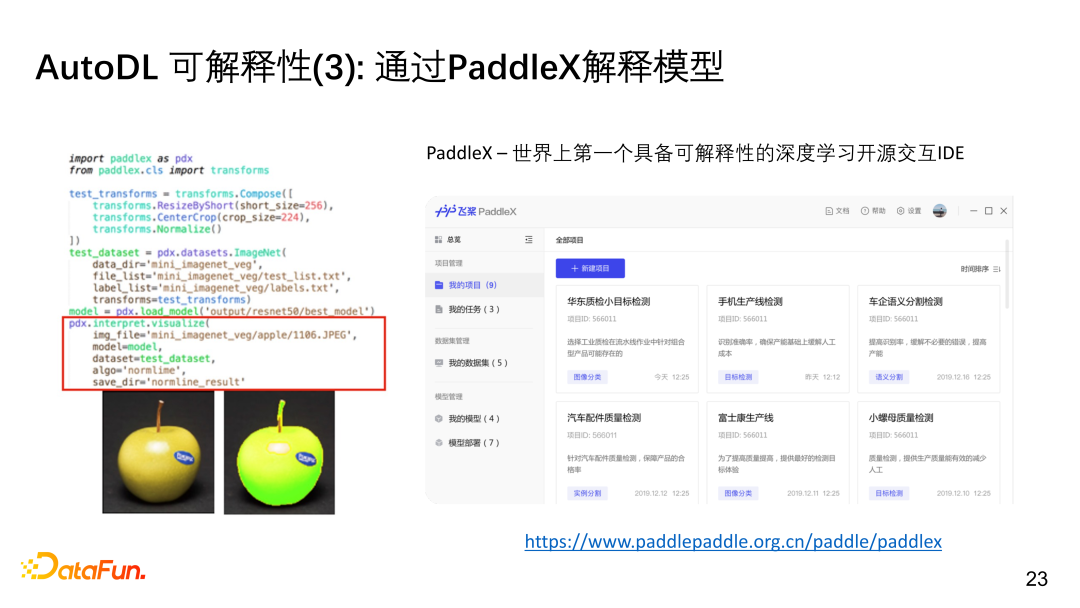
对于开源上如何获得解释,我们集成了PaddleX,可以增加几行代码,帮助判读模型是如何做出决策的。比如上图中,分类图片为苹果的过程中,是哪些pixel支持的分类结果,PaddleX会高亮显示feature pixels。
03
1. EasyDL & BML平台
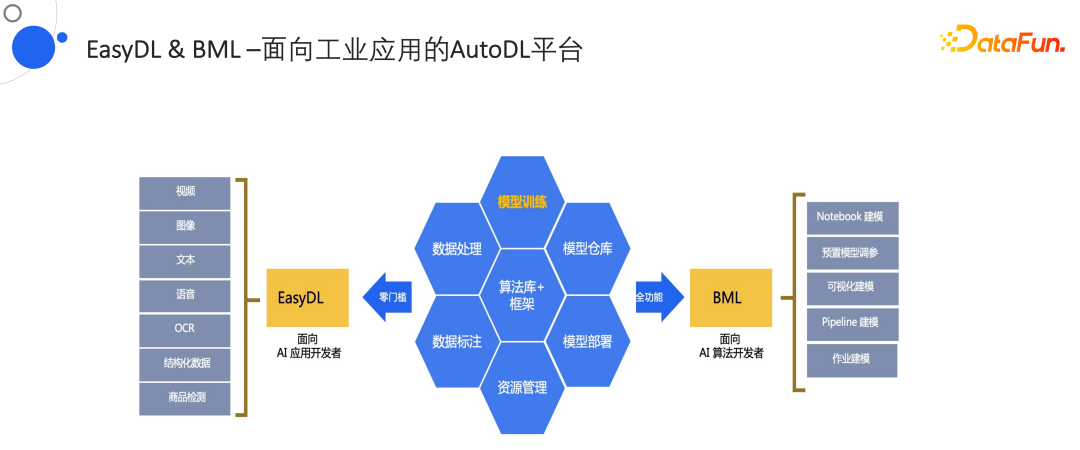
下面介绍商业化的应用,主要是EasyDL和BML。EasyDL是面向AI应用开发者,BML面向AI算法开发者。EasyDL在算法库、框架库、模型的训练、数据处理、数据标注、资源管理、模型部署、资源仓库甚至嵌入式上都有很好的表现,不光是在server中部署,也可以在嵌入式中部署,EasyDL也提供了一套完整的方案。
2. EasyDL 零门槛AI开发平台
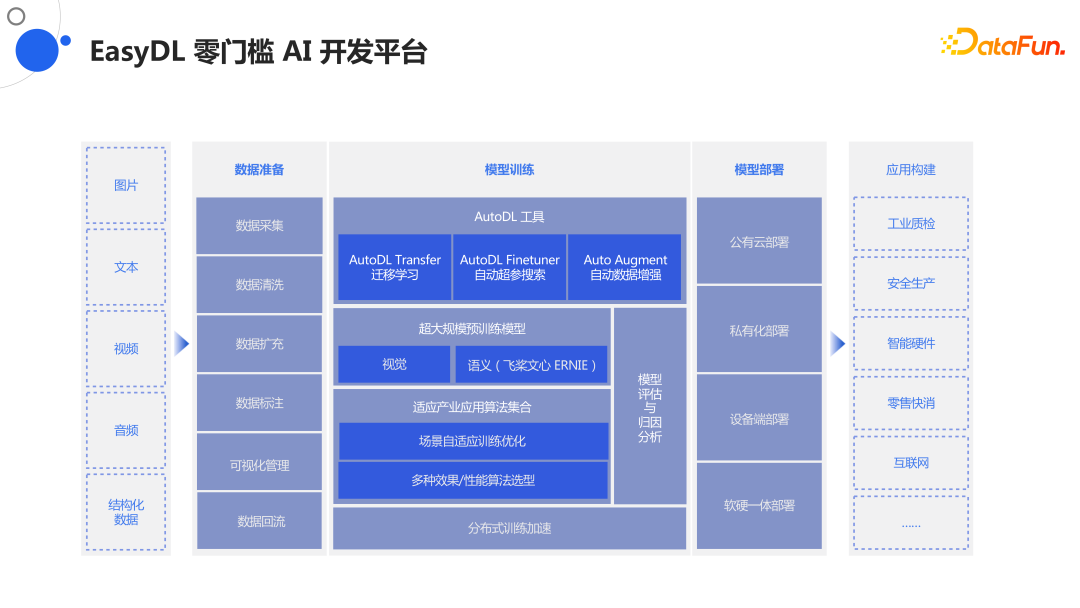
EasyDL包括最顶层的AutoDL Transfer如何做迁移学习、AutoDL Firetuner如何做自动化超参搜索,以及AutoDL Augment数据增强。NAS没被放在最顶层,是因为我们提供了大量的模型在下面一层,包括视觉、NLP,甚至还有生物计算如genetics、RNA、protein蛋白质解析这种复杂数据结构上的模型,我们现在都有底层的知识。
下面一层是一些适应场景的优化、多种效果的选型,我们提供了一系列fullstack的能力。
总之无论是视频、文本还是音频任务,EasyDL对数据准备上给了一系列的准备方案;模型训练上提供AutoDL工具集、超大规模模型库、适应产业应用算法集合以及分布式训练加速等,还有模型可解释性部分的模型评估和归因分析;模型部署上提供多项选择,包括公有云部署、私有云部署、设备端部署、软硬一体部署等;EasyDL给国内许多硬件厂商或生态用户提供了各种各样的端侧或准系统使用,最后根据应用垂类进行应用构建。
3. EasyDL的自动化建模机制
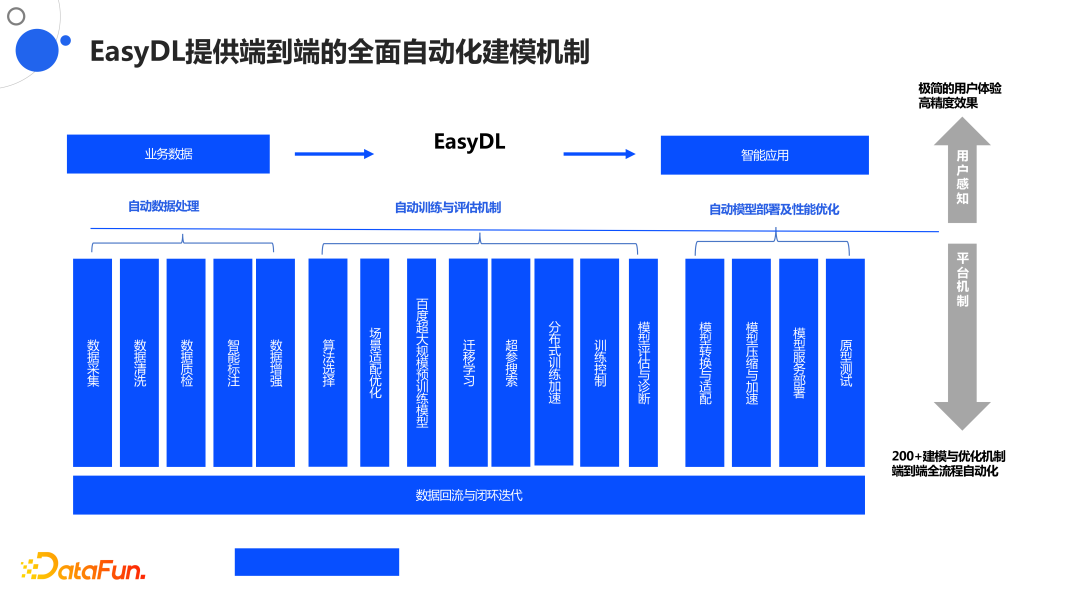
上图是EasyDL的使用图,分为业务数据到EasyDL到智能应用三个过程。具体来说就是自动化数据处理、自动训练与评估机制以及自动模型部署及性能优化。之前提及的论文和技术创造就是为了帮助用户解决自动化迁移、自动化评估、自动化适配等方面的问题。
4. EasyDL预置领先预训练模型

比如一些领先的预训练模型,我们深入了很多行业,做了许多大量的预训练模型,解决了很多问题。如LED的裂痕工业质检,我们有对应的塑料等材质的预训练;又比如水果之类的预训练等。基于海量的互联网数据,我们有非常好的预训练模型,帮助解决许多问题。同时也有很丰富的视觉模型、面向工业界各个垂类的模型。
百度本就是非常强的搜索公司,我们在NLP方面的模型更强,如文心ERNIE,最大的优势在于我们有很强的知识图谱和海量的语料。
5. EasyDL自动场景适配优化

EasyDL可以自动根据场景进行适配,如图像分类、物体检测、文本分析、表数据预测等。以绝缘子故障检测为例,检测目标非常小,但仍可以进行识别;对于气象云状态也可以做识别。
针对适配产生新的问题,EasyDL提供了大量的解决方案,使用上不需要编程,只需通过菜单勾选。
6. EasyDL智能归因助力模型调优
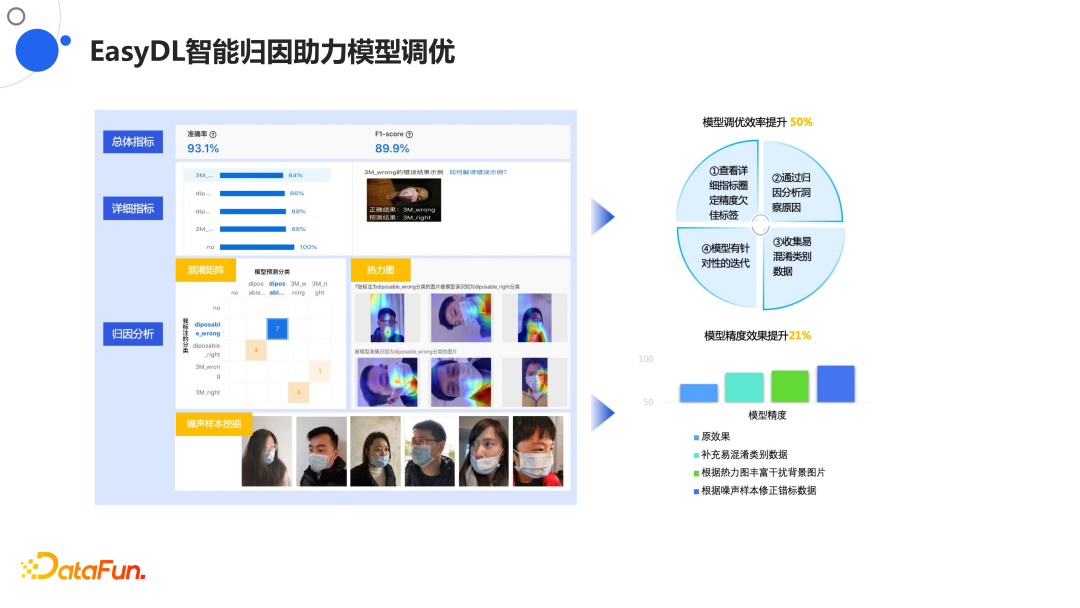
对于归因分析,将模型部署到用户使用端后,我们需要知道模型预测结果为何是这样的。
上图显示的是疫情期间判断人是否戴口罩,我们需要判断哪些pixel决定对图片的理解,否则就算模型蒙对了结果,但哪些特征像素不在口罩上,这样也是不可以的。通过这样的归因分析判断模型的预测结果是否正确,毕竟模型除了预测accuracy外还有correctness。
7. EasyDL丰富任务场景-7大方向、18种任务类型
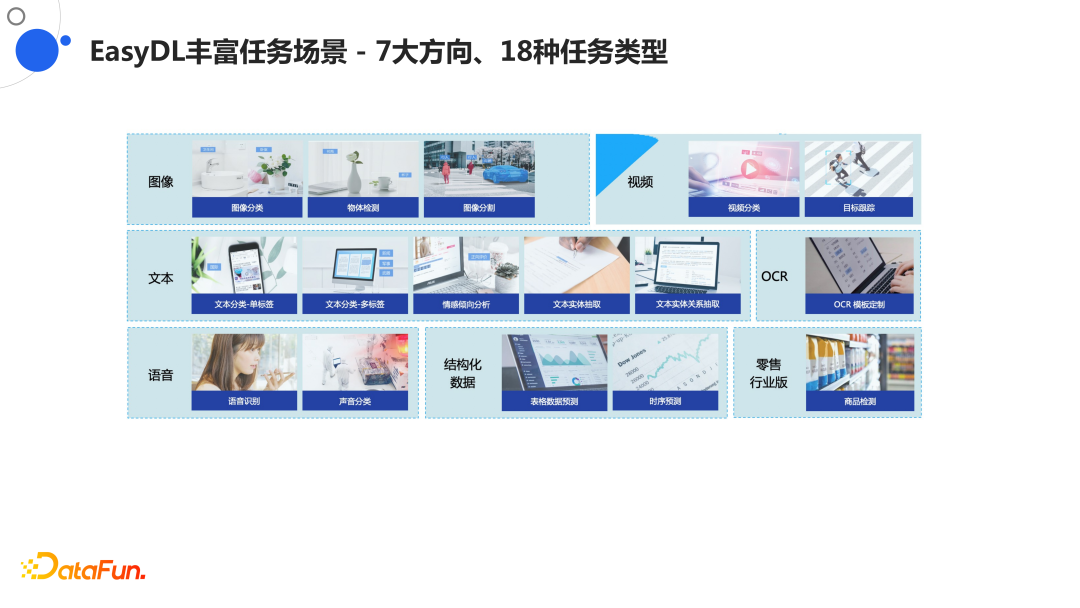
EasyDL对7大方向,18种任务类型,进行了全覆盖,其中OCR做到了业界最好,而且可以根据各种工单、表单、发票等一些垂类的任务进行支持,这一点是非常难得的。
百度作为一家大公司,积累了许多knowhow,这些knowhow全部在这些预训练模型、自动化调优的tricks、以及模型检验中。
百度的语音也是非常厉害的产品,拥有大量的support。
04
关于AutoDL的未来目标与展望

最后分享下我们的vision,我觉得AutoDL是AI时代的creation of Adam,只是开始而已,绝非结束,以后的AI或多或少都是Auto的,机器学习已经做出来了,为何还要人参与机器学习呢。如果有大量算力、预训练模型以及大量的调参的tricks以后,机器学习就是一个pipeline,类似于八股文的存在,自然有办法进行排列组合,在所有可能性中挑出最适合自己的。因此我们认为这可能是未来主要的机器学习的方向。
05
提问环节
Q1:知识图谱如何做可解释?
A1:知识图谱是我的盲区,我个人没有做过知识图谱的东西。但是图神经网络有很多可解释性的工作,你可以看下前年LIME,还有一篇宾西法尼亚州立大学和NEC他们合作做了一篇关于图神经网络的graph explainer,他们有一些解释关于路径搜寻或解释推理过程的方法,如果可以解释图神经网络,那么也可以解释知识图谱的推理,这是我的看法。
Q2:推荐模型的推理pipeline特征处理部分是怎么加速处理的?
A2:以我的理解,工业上一般用的推理,特征首先是0、1特征,会有些1判断有这个特征,0就是没有。一般很少用数字型特征,而是用binary特征。特征传入后,第一步是embedding,将特征拍成一个vector,特征向量从binary特征到分向量,不管权重如何,肯定要做矩阵乘法,我们真正加速是在矩阵乘法上,0、1这种特征和一个矩阵相乘会变成一个key value问题,需要去找1对应的列是什么东西,然后把它们加起来过一个activation,所以这个加速其实是一个database的问题。大规模矩阵乘法后变成一个数据库问题。怎么加速呢?比如说,有些特征不在cache里,但现在整个系统很busy,预估这个特征可能贡献不大,就可以drop out,等到不再catch时,再去数据库中找出它,这是一种加速方法。此外,既然特征变成kv后,其实有很多方法去加速,如分布式数据库之类,基于哈希去调用不同的value或者权重等。这是我的看法。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾
02/电子书免费下载


DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。










