导读:Flink ML 是一个基于 DataStream 的迭代引擎和机器学习算法库。本文将对 Flink ML 库进行介绍,主要包括以下几部分内容:
Flink ML 迭代执行引擎
Flink ML 高效算法库
分享嘉宾|高赟/赵伟波 阿里巴巴 技术专家/算法专家
编辑整理|刘浩平 东北大学
出品平台|DataFunTalk
Flink ML 是 Flink 生态的子项目,目标是为用户提供高效的离线和在线算法库。Flink ML 实现了端到端的性能测试框架,是保障整个算法性能的基础。它提供了完整的 Python 支持,用户可以通过 Python 提交任务。并且提供了完善的帮助文档和网站,在 Flink 官网的左侧导航栏可以查看对应文档。它也在补充更多的离线和在线算法。图1 Flink Table Store v0.2 的架构
Alink 是最早基于 Flink 的机器学习生态项目,始于 2017 年(阿里巴巴),开源于 2019 年,包含丰富的机器学习算法,并且已经在服务大量云上的客户。现在希望将 Alink 的设计思路、代码贡献回 Flink 社区。Flink 是基于 DAG 描述流批一体的处理引擎,但在许多场景下,如机器学习或图计算场景,以及线上预测希望根据预测结果实时调整参数,这些场景下需要用到数据迭代处理的能力。比如某些算法,在机器学习中进行离线或在线的训练,这种情况下需要对训练数据和模型不断的迭代更新直到模型收敛,此时需要在 Flink 中支持后续节点将结果返回给前面节点,即支持带环的数据处理能力。默认 Flink 是基于 DAG 的处理引擎,因此就需要在 Flink 之上提供数据迭代处理的执行引擎,同时希望可以支持离线和在线场景(如图 2 所示)。图2 支持场景
接下来以逻辑回归为例了解一下算法如何在这几种场景下执行。前面提到了离线训练、在线训练、线上动态调整模型参数三个场景(如图 3 所示)。这三种场景之间既有共性又有区别。首先看离线训练场景。以逻辑回归为例,在逻辑回归当中需要一个初始的模型参数将结果发送到迭代中的节点,比如用来做模型缓存的节点。简单起见假设该节点的并发度为 1,保存了当前最新的模型。另外有一个并发为 N 的训练节点。由于是离线训练,因此训练节点在迭代开始之前可以预先把所有数据读取到训练节点当中。然后在每一轮迭代中,当训练节点收到从模型节点发送的最新的模型之后,就会从预先缓存的全量训练数据中选择一小部分数据(Mini-batch)。基于当前最新的模型计算一个模型更新,模型更新通过某种方式发挥到模型缓存的节点。模型缓存节点把这个模型更新应用到之前保存的最新模型上就可以完成一轮迭代,最后得到下一轮迭代开始的模型,模型缓存节点再把模型发送到训练节点并开始下一轮迭代。
对于在线训练,训练数据就无法进行预先缓存,训练数据是实时的。在这种情况下,每次从模型缓存收到下一个模型之后,从训练数据源读取下一个 Mini-batch 数据,也就是读取下一部分固定条数的数据。基于这部分数据和获取的最新模型计算一个模型更新,然后把模型更新发回到训练节点实现模型的实际更新。在这个过程中训练节点要能够在读取模型和读取下一个 Mini-batch 之间进行动态切换。对于离线和在线训练,有同步和异步两种实现方式。如果是同步,模型缓存节点需要收齐所有训练节点的更新,模型缓存节点应用全部更新之后再发送给训练节点进行下轮迭代。相当于每个训练节点的更新次数都是同步的。另一种是异步更新,对于模型缓存节点,它从一部分或者一个训练节点收到模型更新之后,会立即应用模型的更新,然后向所有节点广播模型最新的结果。还有一种是在线上进行预测的时候,有可能需要根据预测结果实时调整参数。比如某些算法当中,根据预测的结果动态的在延迟和精度之间选择。可见这几种场景中都需要下游节点把结果发送给上游节点,通过这种方式实现数据循环处理。图3 迭代执行引擎场景
基于前面提到的三个场景,对迭代的需求作个总结,如图 4 所示。首先,统一的迭代结构图。这三个场景都需要在 Flink 的作业中引入统一的有环迭代结构支持数据的循环处理。其次,统一的迭代终止判断。这三种场景都需要在某种条件下能够终止迭代,也就是迭代执行引擎要为用户提供判断迭代终止的逻辑。由于迭代就是在整个作业中引入了环,因此它的终止逻辑和普通的 DAG 执行逻辑是有区别的。最后,提供整个数据集处理完一轮的通知。在迭代中需要为用户提供每处理完一轮迭代,对算子进行通知的能力。比如之前提到的模型缓存的算子,例如在同步情况下,当从所有训练节点收到模型更新数据之后,就需要进行一次模型的更新。这时候就需要有消息通知训练节点所有模型的更新已经收齐。而训练节点从模型缓存节点收到最新的模型之后,也需要通知缓存节点整个模型已经收到了,可以开始计算下一轮模型更新。因此就需要当处理完整个数据集之后通知的能力。无论在线训练还是离线训练中,都需要对数据做 Mini-batch 切分。这里有两个选择,一个是,在整个迭代层提供 Mini-batch 的语义。然后迭代算法可以直接看到一个 Mini-batch,同时也提供 Mini-batch 处理完成之后通知的能力。另一种可能是将 Mini-batch 交给上层,最后我们选择了在迭代层提供整个数据集处理完成之后进行通知的能力。而把 Mini-batch 处理就是交给了算法层进行处理。主要有三个原因,第一点,Mini-batch 可能有两种处理逻辑:一是,串行顺序处理 Mini-batch;另一种是,多个 Mini-batch 并行处理。如果要在迭代层同时支持这两种语义的话,就必须在迭代层引入一套非常复杂的关于 Mini-batch 数据流的描述。这样就需要提供一套完全独立于 Flink DataStream API 的 API,如果引入 Mini-batch 就需要引入一套复杂的基于 Mini-batch 的 DataStream API,并且所有算子需要进行重写来支持 Mini-batch 的语义。第二点,对于图 3 中的第三种情况,可能每处理完一条数据都需要向上游节点发送一部分数据。这种情况下把它归结为 Per-record 的 Mini-batch,否则就要提供一个无限大的 Mini-batch,或者每个 Record 切分一次 Mini-batch,这些操作都有较大的额外开销。考虑到上述情况,在迭代层提供了整个数据集处理完成之后通知的能力。而划分 Mini-batch 可以由实现算法的算子来 Mini-batch 处理。后续也会实现在迭代之上提供整个 Mini-batch 的处理的逻辑。图4 迭代执行引擎:需求
迭代的设计如图 5 所示,主要由四个部分组成。第一,指定一个有回边的输入,比如图 5 中的初始输入就是模型的初始参数,每一轮迭代都会对模型进行更新,因此模型的输入就会有一个和它对应的回边,回边传递的是模型更新;第二是,没有回边的输入,比如训练数据集,这个数据集是只读的不需要更新;第三个是回边;第四个是模型迭代终止之后的输出。前面提到在迭代过程中需要具备进度追踪能力,即每处理完一轮,都需要通知算子本轮迭代处理完了,此时算子可以做一些特定的操作,比如更新模型或者计算下一个模型更新。对于迭代中无回边的输入,Flink ML 提供了两种语义,一种是重放,即每一轮迭代都会从边上读取相同的输入;另一种是不重放,即数据集只传输一次。对于算子的生命周期也提供了两种,一种是每轮重建,即每轮创建新的算子实例来处理收到的数据;第二种是每轮不重建,即用一个算子实例处理每一轮迭代。无论是初始输入还是回边收上的输入,模型的更新都交给一个算子实例处理。针对这两种生命周期用户有两种使用方法:第一,如果不重建算子,只创建一个模型缓存算子实例,既处理模型的初始输入,也处理每一轮的模型更新。这样可以在本地缓存最新的模型,避免在迭代中传输整个模型;第二,选择每轮重建算子,并选择重放算子使用的无回边输入。这样在迭代中可以复用迭代外的算子。比如迭代的算子既有无回边输入,也包含有回边输入,每轮重建算子就可以方便地使用比如 Join 或 Reduce 算子等迭代外的实现。最后,迭代提供了两种终止逻辑。其一,当迭代的所有输入都迭代处理完成,这种情况就认为迭代终止。在这种终止逻辑中,会发送一个特殊消息,当迭代一轮也没发现有新的数据输入,就会终止迭代;其二,对于有限数据流的迭代,允许用户指定一个特定的节点,当该节点某一轮没有输出的时候,就认为迭代终止。比如运行最短路径的图算法,如果某个节点负责输出下一轮需要的更新。当该节点不再有更新就认为迭代已经终止。图5 迭代执行引擎:设计
基于上述 API 实现一个迭代的例子,如图 6 所示,获取 initParameters 和 Dataset 两个 DataStream 之后,调用 Iterations.iterate 方法。iterate 方法需要传入四个参数:有回边输入、无回边输入、算子每轮是否重建、迭代体处理逻辑。迭代体处理逻辑基于有回边和无回边的输入列表构建迭代体。迭代体将返回两个输出列表,一个是与有回边输入数据一一对应的有回边列表,并将执行 Union 操作后,再交给迭代体处理;第二个是迭代完成后的最终输出。由于 Flink 需要预先构建 DAG 图,因此要根据用户指定的执行逻辑构建包含回边的 DAG 图,这一点会在后续做详细的介绍。
图6 迭代执行引擎:API
迭代内的算子可以实现 IterationListener 接口,如图 7 所示,实现该接口后会得到两个通知,一是每轮数据输入完成的通知,另一个是迭代终止的通知。图7 迭代执行引擎:API
以模型缓存算子为例,图 7 中左上角橙色的模型缓存算子,当收到模型更新后,就将更新加到当前的模型上。缓存算子收齐模型更新便将最新的模型发送给下游的训练节点。当迭代终止就得到最终的输出,这里使用了 Flink 的 Sideoutput 机制。接下来看一下迭代引擎的具体实现,如图 8 所示。对于图 8 左侧的迭代体结构,其中有回边和输入边是一一对应的。如图 8 右侧的结构,在图中引入一些特殊算子,包括 Input、Output、Head、Tail 等算子。另外会对迭代体中的算子做 Wrap,它负责管理其中算子的生命周期,比如每轮是否重建。Head 和 Tail 算子通过 Colocation 机制被调度到同一个 TM 进程中。这样可以实现基于内存的回边消息队列,由于 Tail 和 Head 节点在同一个进程中,当数据到达 Tail 节点后可以基于内存直接传输数据。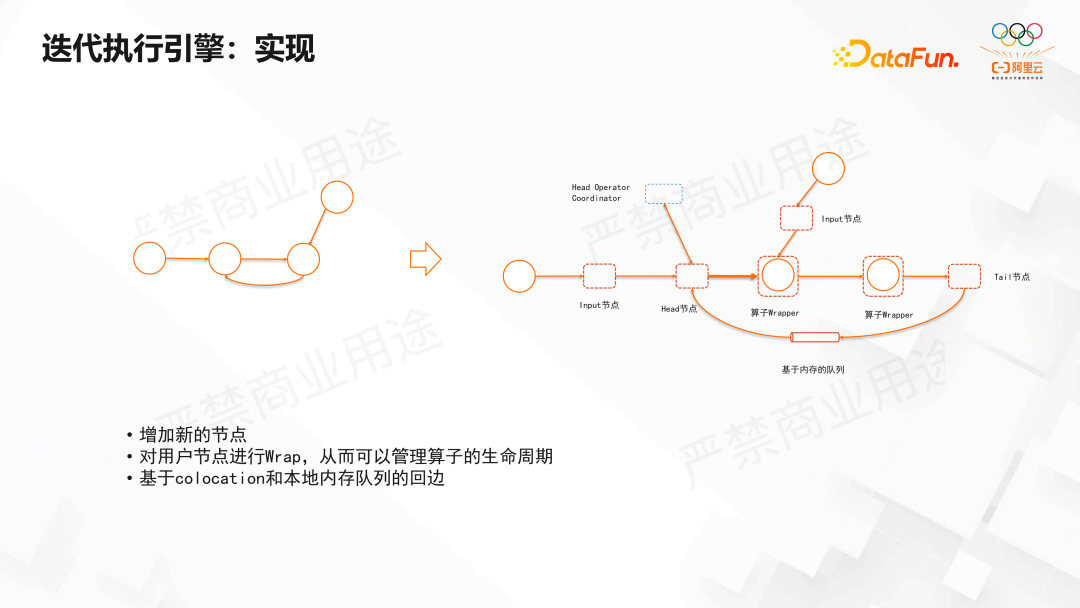
图8迭代执行引擎:实现
迭代中当数据通过 Input 算子输入迭代体时,会对每条记录做 Wrap 操作并添加迭代头,迭代头上记录了该记录所属的迭代的轮次。Wrap 后的数据输入到 Wrapper 算子时,Wrapper 算子去掉迭代头后,再交给用户编写的算子处理。当所有元素输入完后,将插入一个 Barrier 节点标记本轮输入结束。此外当迭代执行完成,如果中间算子通过 Output 算子输出,Output 算子将去掉迭代头。在迭代中 Head 节点会判断迭代是否终止以及每轮迭代是否结束。当 Input 算子读取完输入数据,如果数据是有限的将在其后插入一个特殊的 Barrier,Barrier 将跟随数据进入循环。当 Head 节点读取完每一轮输入,将通过 Head Operator Coordinator 和所有的 Head Task 并发通信,Head Operator Coordinator 是 JM 中的全局组件。Head Task 会通知 Head Operator Coordinator 已经读取完输入,然后 Head Operator Coordinator 会通知所有 Head 节点本轮输入结束。这种情况下,Head 节点首先拿到本轮输入完成的通知,然后 Head 节点将数据和这个特殊的消息(图 9 中蓝色块)广播发送给下游节点。然后下游节点从所有的输入读到这个特殊的消息之后,就代表这一轮的输入已完成,然后他所 Wrapper 的算子这一轮输入完成。通过这种方式实现了进度追踪。这个逻辑与 Flink 中 Watermark 管理逻辑是类似的。当数据经过 Tail 节点时,就会把头的数据和特殊消息上所记录的迭代轮次都做加 1 的操作。图9迭代执行引擎:实现
因为 Flink 默认的容错机制不支持环,因此引入环后就必须对 Checkpoint 机制做扩展。扩展主要包括两部分:一部分是在正常 Checkpoint 时,当 Head 节点收到Barrier之后,除了做 Snapshot 之外,Head 节点还会记录回边上收到的数据,并往下发送Barrier。当Barrier经过Tail节点通过环回到 Head 节点后,此时就记录了 Checkpoint 当中回边上的所有数据。这样就实现了带环的 Chandy-Lamport 算法,最后保存的 Checkpoint 就是这些算子的 Snapshot 以及回边的数据列表。除此之外,Head 节点在每一轮 Checkpoint 时,Head 节点即要等待输入边上的Barrier 对齐,还要等待 OperatorCoordinator 的虚拟 Barrier。这个 Barrier 保证它与 OperatorCoordinator 本轮消息收集的通知不会交叉,保证在迭代中,所有 Task 都在同一轮。这样在算子扩并发和缩并发时,可以很容易地合并同一个算子不同实例的状态。最后还有一个正在做的优化,在某一轮结束之后立即发送缓存的虚拟 Barrier 数据。这样如果迭代中有些节点是通过缓存所有的数据,等到某一轮结束时发送,这种情况下保证它保存的数据量最小。图10迭代执行引擎:实现
以上是关于迭代执行引擎的介绍,下面对迭代执行引擎做一个总结,如图 11 所示。首先迭代执行引擎实现了统一支持离线和在线算法训练。其次提供了 Exactly-Once 容错机制。当输入是有限集合时,将进支持 Batch 执行模式。并且未来将提供统一的上层算法开发工具,如前面提到的 Mini-batch 工具或者模型缓存的统一实现。迭代执行引擎在 Flink ML 库中实现了一些依赖迭代算法的基础,比如逻辑回归或 Kmeans。下面是关于 Flink ML 中离线和在线算法的介绍。图11迭代执行引擎:总结
03
下面介绍基于迭代的 Flink ML 高效的算法库。基于 Flink 的 ML 算法库 Alink 开始于 2017 年,到目前为止已经做了 5 年,内置了丰富的算子,如图 12 所示,包括:
① 分类算法,包括逻辑回归、Softmax、树相关的 GBDT、随机森林相关的分类算法⑤ 关联分析相关的FPGrowth 、PrefixSpan和ALS经过多年发展,Alink 内置了一套比较完备的算法库,基于 Alink 可以很方便地搭建业务流程,解决实际业务中遇到的问题。 图12高效的离线/在线学习算法库
在做的 Flink ML 目的是将 Alink 算法回馈到 Flink 社区,如图 13 所示,即通过流的方式在 Flink ML 的 1.15 版本中重新实现这些算法并做相关的优化。图13 高效的离线/在线学习算法库
将 Flink ML 与 Spark ML 的部分算法做了一个对比,如图 14 所示,其中包括Kmeans、String Indexer、MinMaxScaler 以及 OneHotEncoder 这几个算法。通过图 14 中的结果可知 Flink ML 的性能不弱于 Spark,个别算法明显优于Spark 的性能。这也给我们基于 Flink 开发 ML 增加了很大的信心,基于Flink也可以做出高性能的 ML 算法库。图14 Flink ML 与 Spark ML 部分算法性能对比基于前一小节的迭代引擎实现 Online LR 算法的应用。前一小节是基于迭代引擎来讲 Online LR。而这里是从应用的角度,或者从在线逻辑回归算法的角度来讲迭代引擎在实际算法中的应用。如图 15 是 Online LR 算法的流程图。其中左边是实时数据,右边是初始模型。实时数据切分成 Mini-batch 然后分布到各个 Work 上计算梯度。计算梯度的时候需要用到模型队列,它包含两部分:一部分是初始模型;另一部分是计算完之后的更新模型,更新模型会广播分发到 Worker 上。各个 Worker 节点使用更新模型以及数据来计算梯度。最后再通过 Reduce 操作计算得到最终的梯度,并用这个梯度更新模型。输出模型一方面输出为预测使用;另一方面它会反馈(Feedback)给模型队列,作为下一步 Mini-batch 迭代提供 Base 模型。图15 迭代引擎在 Online LR 的应用
以上是 Online LR 的基本流程。下面来看基于迭代引擎如何实现 Online LR,如图16 所示。首先,图 16 中 IterationBodyResult 是核心的迭代体,其中第一个参数DataStreamList 传入 Model 队列,第二个参数DataStreamList把实时数据传进来。可以看到参数并不是单独的 DataStream 而是一个 List,List 说明可以支持复杂的多组数据的模型。另外实时训练数据也可以是数组,示例的 Online LR 算法中只有一个训练数据。实际在设计迭代引擎时,需要考虑更复杂的场景。 图16迭代引擎在 Online LR 的应用
接下来看图 17 中第一个绿色背景的代码是计算本地梯度。当拿到 Mini-batch 后,将本地计算梯度。计算完梯度之后,图 17 中第二个绿色背景的代码执行行 Reduce 操作并得到整体的梯度值。之后,在图 17 中的 Update Model 部分用该梯度对模型进行更新。图17迭代引擎在 Online LR 的应用
更新之后,在图 18 中通过迭代框架的机制将模型数据 Feedback 再重新广播做循环计算。在回流迭代的同时将模型输出,为下一个流程做准备。以上就是 Online LR 在迭代引擎中实现的基本流程。在整个过程中,计算梯度以及更新模型都封装成了独立的函数。如果不是 Online LR 而是 Online SVM 只要调整梯度计算以及模型更新就可以了。所以这套机制不光适用于 Online LR 只要是基于梯度更新的模型都可以实现 Online 版本的,基于迭代更新实现一个在线算法。图18迭代引擎在 Online LR 的应用
如图 19 中的示例代码,第一步,算法需要一个初始的 LR 模型,示例中调用的是offlineTrainDenseTable 的逻辑回归,训练得到逻辑回归的初始模型。第二部,基于初始模型构造 Online 逻辑回归。从 Online 逻辑回归的 Fit 得到实时的模型流,相当于 Fit 完之后,Online 逻辑回归模型是一个不断地有模型流出来的 DataStream。图19 Online LR 算法使用
第三步,是使用在线 LR 模型推理并写出结果如图 20 所示。最后,写出在线 LR模型。以上是 Online LR 算法的使用。图20 Online LR 算法使用
下面再展示一个 KMeans Demo。这个 Demo 是对 KMeans 算法做的在线实时学习的例子。如图 21 所示,首先是参数设置,Demo 设置了本地接收数据的端口为 9999,并行度是 1,输入数据的维度是 2,聚类个数是 2,GlobalBatchSize 是 1 (GlobalBatchSize 设置为 1 主要是为了演示,实现来一条数据,就迭代更新一次模型),DecayFactor 参数值为 0.5。图21 KMeans Demo
如图 22 所示,启动 9999 端口并写数据。如图写入(1,2)。这里是初始模型,可以看到输入数据是 1 和 2,这两个数据更接近于图中 Model version-0 中的 1-th center 这个点([0.509, 0.400], 1.0),所以模型会更新这个聚类点。从图 22 中 Model version-1 可以看到 0-th center 这个点没有变化,而下面的 1-th center 点根据输入数据更新了一次。图22 KMeans Demo
如图 23 所示,再输入几组数据再观察一下模型的输出,从图中可以看到第一个聚类点做了两次更新,可以看到每发送一条数据,就会实时的迭代更新模型。图23 KMeansDemo
接下来再输入一组其他数据(-1,-2),这组数据离上一个聚类点(0-th Center)比较近。当输入(-1,-2)时 0 号聚类就不断迭代更新。而 1 号聚类点就不受影响。以上示例演示了实时在线学习的 Demo。图24 KMeans Demo
最后介绍一下 Flink ML 未来的发展,如图 25 所示。Flink ML 在 2022 年 1 月份的时候发布了 Flink ML API,其中结合 Alink 的 API 设计,考虑到流处理算法的开发,对 API 做了重新的架构设计。在 2022 年 7 月份的时候发布了一个版本,主要是开发了高效的 Flink ML 的基础设施。未来,预计在 2022 年 11 月份的下一个发布版本中,侧重于特征工程算法,并考虑一些业务场景进行落地。最终希望将 Flink ML 做成我们传统实时机器学习实施标准。图25 Flink ML 发展路线
大家如果对 Flink ML 感兴趣,可以看一下项目的 GitHub 和文档,链接地址如图26 所示。
图26 参考资料
Q1:Flink ML 与 Alink 是什么关系?A1:Alink 是 Flink 生态之外的一块项目,我们希望把 Alink 的所有能力都赋能给 Flink ML。A2:对于是元数据或者模型这部分的存储,是 Flink ML 内置的功能。如果是一些偏表格的数据,可以考虑用传统的方式来统计。A3:当前支持二分类评估。将来会逐步完善评估模块,比如回归的评估。A4:现在主要是推荐和广告业务中用得比较多,因为它们对实时性要求比较高,所以这些领域比较多一些。A5:主要是因为学习率太大,或者数据里边有坏数据把整个模型拉坏了。要避免这种情况主要考虑使用 Rebase 的方式,隔段时间把模型往后拉一下。不要一直基于一个模型持续训练很长时间。A6:这实际上就是数据过滤,对于数据质量比如填充或者是数据过滤,这个应该是在训练之前就应该做的,数据清洗这块不应该在训练过程支持,这需要单独的操作或组件来完成。A7:这是一个模型管理的问题。Online 算法只输出模型,之后会有一个对模型进行评估的机制。这个机制需要在算法之外实现。

高赟博士
阿里巴巴 技术专家
阿里巴巴技术专家,Apache Flink PMC。高赟博士毕业于中国科学院大学,加入阿里巴巴实时计算团队,主要从事 Flink Runtime / DataStream API / 迭代引擎方向的开发与改进。

赵伟波
阿里巴巴 算法专家
2010毕业于北京大学数学系,2017年进入阿里巴巴从事算法研发相关的工作。
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。











