近年来,随着深度学习的发展和大规模数据集的出现,深度学习在很多领域也取得了进展,但其中「人脸复原」(Face Restoration)任务仍然缺乏系统性的综述。最近,来自南京大学、澳大利亚国立大学、中山大学、帝国理工学院和腾讯的研究者们全面回顾并总结了基于深度学习的人脸复原技术的研究进展,对人脸复原方法进行了分类,讨论了网络架构、损失函数和基准数据集,并对现有SOTA方法进行了系统性性能评测。

论文链接:https://arxiv.org/abs/2211.02831
仓库链接:https://github.com/TaoWangzj/Awesome-Face-Restoration
这篇文章也是人脸复原领域首篇综述,其主要贡献为:
1. 回顾了人脸复原任务中主要的退化模型、常用的评价指标,并总结了人脸图像显著性的特点;
2. 总结了目前人脸复原面临的挑战,对现有方法进行分类及概述。方法主要包括两大类:基于先验的深度学习复原方法和无先验的深度学习复原方法;
3. 梳理了方法中使用的基本网络架构、基本网络模块、损失函数和标准数据集;
4. 在公共基准数据集上对现有SOTA方法进行了系统性实验评测;
5. 分析了人脸复原任务未来发展前景。
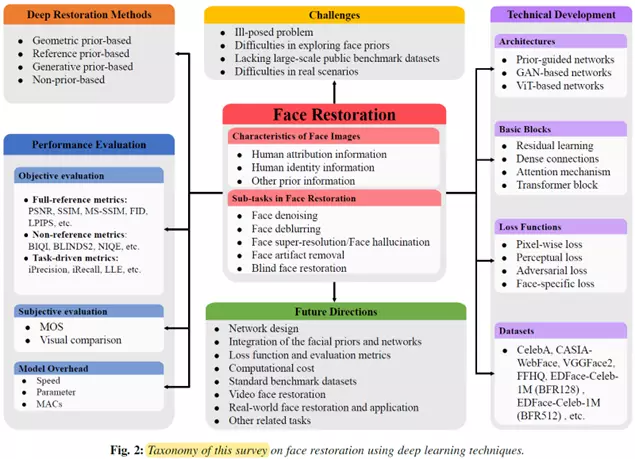
文章的整体架构
人脸复原(Face Restoration, FR)是底层视觉中一个特定的图像复原问题,旨在从低质量的输入人脸图像中恢复出高质量的人脸图像。通常来说,退化模型可以描述为:
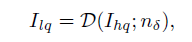
其中I(lq)是低质量人脸图像, D是与噪声不相关的退化函数, n是加性高斯噪声。当退化函数D不同的时候,就对应了不同的退化模型。因此,FR任务可以视为是求解上述退化模型的逆过程,它可以表示为:
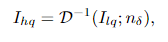
其中根据退化函数不同,人脸复原任务主要可以分为以下五大类,其分别对应着不同的退化模型:
1. 人脸去噪任务(Face Denoising, FDN):去除人脸图像中的噪声,恢复出高质量的人脸;

2. 人脸去模糊任务(Face Deblurring, FDB):去除人脸图像中的模糊,恢复出高质量的人脸;

3. 人脸超分辨率任务(Face Super-Resolution, FSR):从低质量的低分辨率人脸中恢复出高分辨率高质量的人脸;

4. 人脸去伪影任务(Face Artifact Removal, FAR):去除人脸图像压缩过程中出现的伪影,恢复出高质量的人脸;

5. 盲人脸复原任务(Blind Face Restoration, BFR):将未知退化的低质量人脸复原成高质量人脸;

与一般自然图像的复原任务不同,人脸图像具有很强的结构性信息,因此人脸复原任务可以利用人脸图像的先验信息来辅助人脸的复原过程,先验信息主要可以分为以下三部分:
人的属性信息:如性别,年龄,是否佩戴眼镜,如下图所示;

人的身份信息;
其他先验信息:如下图所示,代表性的先验有人脸landmark,人脸热图,人脸解析图和3D人脸先验;

1. 人脸复原本身是一个不适定的问题。
因为低质量人脸图像的退化类型和退化参数是事先未知的,从退化的图像中估计高质量的人脸图像是一个不适定问题。
另一方面,在实际场景中,人脸图像的退化是复杂多样的。因此,如何设计有效并且鲁棒的人脸复原模型来解决这个不适定的问题具有一定的挑战性。
2. 探索未知的人脸先验较为困难。
现有人脸复原算法很难充分利用人脸先验知识,因为人脸先验(例如面部成分和面部标志)通常是从低质量人脸图像中估计的,低质量的人脸可能造成先验估计的不准确,这直接影响人脸复原算法的性能。
另一方面,真实场景拍摄的人脸图像往往包含复杂多样的退化类型,找到合适的人脸先验来辅助人脸复原过程是非常困难的。因此,如何挖掘合理的人脸先验具有一定的挑战性。
3. 缺乏大型公开基准数据集。
随着深度学习技术的发展,基于深度学习的方法在人脸复原方面表现出令人印象深刻的性能。大多数基于深度学习的人脸复原方法强烈依赖于大规模数据集来训练网络。
然而,目前大多数人脸复原方法通常在非公开数据集上训练或测试的。因此,目前很难直接公平地比较现有人脸复原方法。
此外,缺乏高质量和大规模的基准限制了模型的潜力。然而,如何获得大规模的人脸数据依然很困难,因此,为人脸复原任务构建合理的公开基准数据集有一定的挑战性。
4. 人脸复原算法在实际场景下泛化能力有限。
尽管基于深度学习方法在人脸复原方面取得了较好的性能,但大多数方法是依赖监督策略进行训练。
也就是说,这些方法需要成对的(低质量和高质量图像对) 数据集,如果这个条件不满足,它们性能会大幅度降低。
另一方面,很难在现实场景中收集到具有成对样本的大规模数据集。因此,在合成数据集上训练的算法在实际场景下泛化能力很弱,从而限制了模型在实际场景中的适用性。因此,如何提高人脸算法在实际场景下泛化能力具有一定的挑战性。
到目前为止,研究人员提出了许多人脸复原算法来尝试解决上述的挑战。下图显示了基于深度学习的人脸复原方法的一个简明的里程碑。
如图所示,自2015年以来,基于深度学习的人脸复原方法的数量逐年增加。
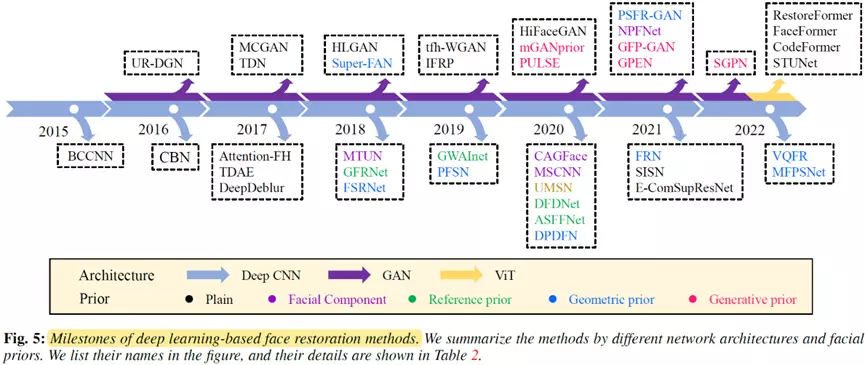
这些人脸复原方法分为两类:基于先验的深度学习复原方法和基于非先验的深度学习复原方法。
而对于基于先验的深度学习复原方法,我们将其分为三类: 基于几何先验的深度学习复原方法,基于参考先验的深度复原方法和基于生成先验的深度复原方法。
下面对具有代表性的人脸复原算法进行简要介绍。
基于几何先验的深度复原方法(Geometric Prior Based Deep Restoration Methods)
该方法主要利用图像中人脸独特的几何形状和空间分布信息来帮助模型逐步恢复高质量的人脸。典型的几何先验有人脸landmark,人脸热图,面部解析图和面部成分。代表性工作有:
SuperFAN:是第一个同时实现人脸超分辨率和人脸landmark定位任务的端到端方法。
这个方法的核心思路是使用联合任务训练策略来引导网络学习更多的人脸几何信息来辅助模型实现高效的人脸超分辨率和人脸landmark定位。
MTUN:是一个包含两个分支网络的人脸复原方法,其中第一个分支网络用来实现人脸图像的超分辨率,第二个分支用于估计面部组成的热力图。
这个方法表明,利用低质量人脸图像中的人脸元素信息可以进一步提高算法人脸复原的性能。
PSFR-GAN:是一种基于多尺度渐进式网络的盲人脸复原方法。这个方法的核心思路是通过使用多尺度低质量人脸图像和人解析图作为输入,通过语义感知风格转换来逐步恢复出人脸的面部细节。
基于参考先验的深度复原方法(Reference Prior Based Deep Restoration Methods
以往人脸复原方法只是依靠退化图像来估计人脸先验,然而人脸图像退化过程通常是高度病态的,仅仅通过退化的图像这些方法无法获得准确的人脸先验。
因此,另外一类方法通过使用额外的高质量人脸图像来获得的面部结构或面部成分字典作为人脸参考先验来指导模型进行高效地人脸复原。代表性工作有:
GFRNet: 该网络模型由一个扭曲网络(WarpNet)和一个重构网络(RecNet)。WarpNet是来提供扭曲引导信息,目的是通过生成流场对参考图像进行扭曲来纠正面部的姿势和表情。RecNet将低质量的图像和扭曲的引导信息同时作为输入来产生高质量的人脸图像。
GWAInet: 这个工作是在GFRNet的基础上提出的,它以对抗生成的方式进行训练,以生成高质量的人脸图像。与GFRNet相比,GWAInet在训练阶段不依赖人脸标记,这个模型更加关注整个人脸区域从而增加了模型的鲁棒性。
DFDNet: 该方法首先利用K-means算法从高质量图像中为感知上显著的面部成分(即左/右眼睛、鼻子和嘴)生成深度字典;然后,从生成的组件字典中选择最相似的组件特征,将细节转移到低质量的人脸图像中,指导模型进行人脸复原。
基于生成先验的深度复原方法(Generative Prior Based Deep Restoration Methods)
随着生成对抗网络(GAN)的快速发展,研究发现,预训练的人脸GAN模型,如StyleGAN、StytleGAN2能够提供更加丰富的人脸先验(如几何和面部纹理)。
因此,研究人员开始利用GAN生成的先验辅助模型进行人脸复原。代表性工作有:
PULSE:
这个工作核心是迭代优化预训练StyleGAN的latent code, 直到输出和输入之间的距离低于阈值,从而实现高效的人脸超分辨率。
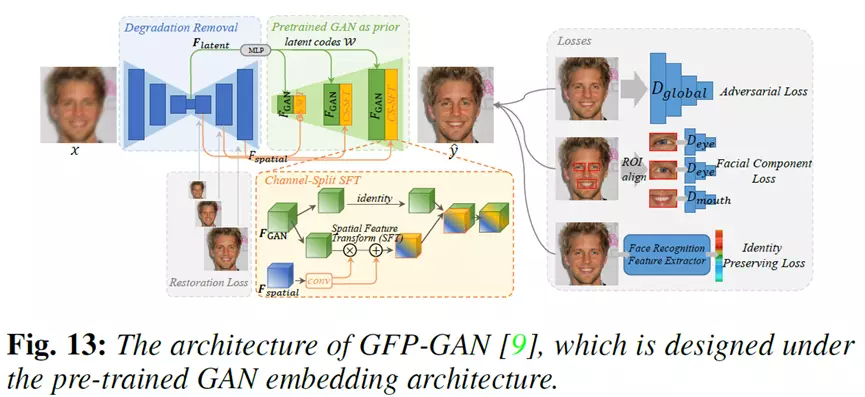
GFP-GAN: 这个工作利用预先训练的GAN模型中丰富多样的先验作为生成先验来指导模型进行盲人脸复原。这个方法主要包含一个降质去除模块和一个基于预训练GAN模型的先验模块,这两个模块通过一个latent code连接和几个通道分割空间特征转换层进行高效信息传递。
GPEN: 这个方法核心思路是有效整合GAN和DNN两中不同的框架优势实现高效的人脸复原。GPEN首先学习一个用于生成高质量人脸图像的GAN模型;然后将这个预先训练好的GAN模型嵌入到一个深度卷积网络中作为先验解码器;最后通过微调这个深度卷积网络实现人脸复原。
基于非先验的深度复原方法:(Non-prior Based Deep Restoration Methods)
虽然大多数基于深度学习的人脸复原方法可以在人脸先验的帮助下恢复满意的人脸,但依赖于人脸先验在一定程度上加剧了生成人脸图像的成本。
为了解决这一问题,另外一类方法旨在设计一个端到端的网络模型来直接学习低质量和高质量人脸图像之间的映射函数,而不需要引入任何额外的人脸先验。代表性工作有:
BCCNN: 一种用于人脸超分辨的双通道卷积神经网络模型。它由一个特征提取器和一个图像生成器组成,其中特征提取器从低分辨率人脸图像中提取鲁棒的人脸表示而图像生成器自适应地将提取的人脸表示与输入的人脸图像进行融合,生成高分辨率图像。
HiFaceGAN: 这个方法将人脸复原问题转化为语义引导的生成问题,并设计了HifaceGAN模型来实现人脸复原。这个网络模型是一个包含多个协作抑制模块和补充模块的多阶段框架,这种结构设计减少了模型对退化先验或训练结构的依赖性。
RestoreFormer: 这是一种基于Transformer的端到端人脸复原方法。它主要探索了对上下文信息建模的全空间注意力机制。
这个方法核心思路主要有两点,第一个是提出了一个多头交叉注意力层来学习损坏查询和高质量键值对之间的全空间交互。第二点是,注意力机制中的key-value 对是从高质量字典中采样获得的,它蕴含高质量的人脸特征。
下图全面地总结了近年来基于深度学习的人脸复原方法的特点。
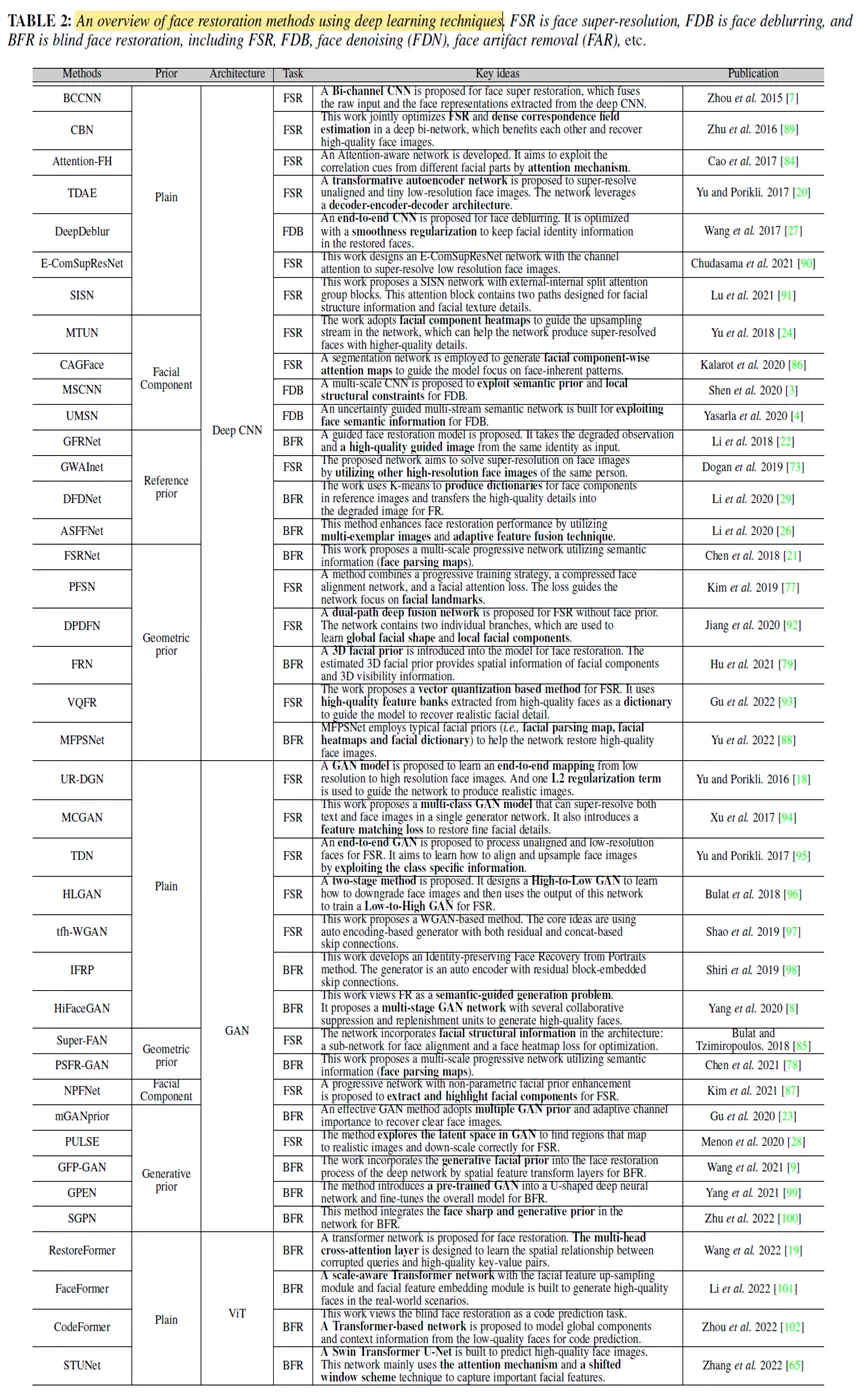
其中Plain表示基于非先验的深度复原方法,Facial component 和Geometric prior 表示基于几何先验的深度复原的两类方法,Reference prior表示基于参考先验的深度复原方法,Generative prior 表示基于非先验的深度复原方法,Deep CNN, GAN, ViT分别表示模型使用深度卷积神经网络,生成对抗网络和Visual Transformer网络结构。
这个部分全面地回顾了基于深度学习的人脸复原方法的技术发展过程,主要从以下几个方面进行总结和分析:网络模型的基本架构、使用的基本模块、模型使用的损失函数和人脸相关的基准数据集。
网络架构
现有基于深度学习的人脸复原方法的网络架构主要分为三类:基于先验引导的方法,基于GAN网络结构的方法和基于ViT网络结构的方法。因此,我们将在本节讨论这些发展。
基于先验引导的方法
这类方法主要可以分为四种,分别为基于前置先验的人脸复原方法(Pre-prior face restoration method),联合先验估计和人脸复原的方法(Joint prior face restoration method),基于中间先验的人脸复原方法(Pre-prior face restoration method),基于参考先验的人脸复原方法(Reference-prior face restoration method)。
以上四种方法的简明结构图如下所示:
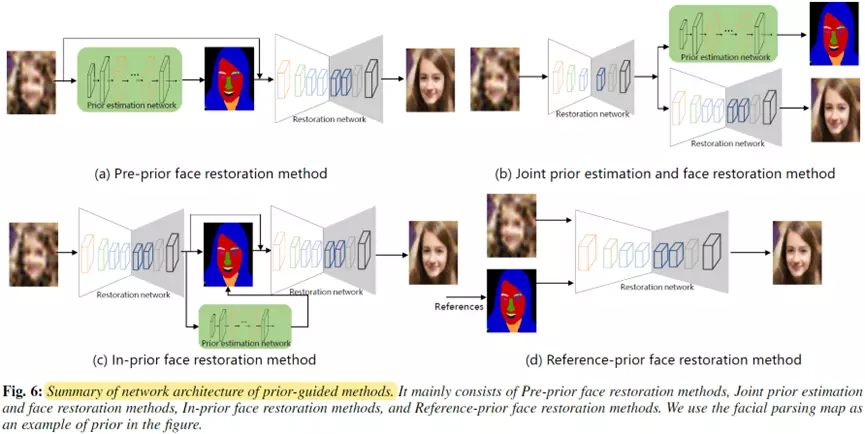
基于前置先验的人脸复原方法通常先使用先验估计网络(如人脸先验估计网络或预训练的人脸GAN模型)从低质量输入图像中估计人脸先验,然后利用一个网络利用人脸先验和人脸图像生成高质量的人脸。
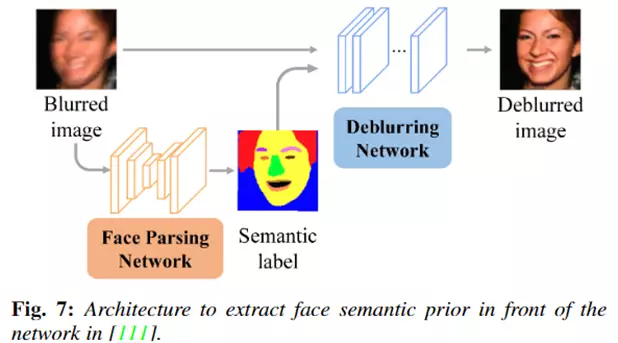
典型的方法如下图所示,研究人员设计了一个人脸解析网络,先从输入模糊人脸图像中提取人脸语义标签,然后将模糊图像和人脸语义标签同时输入一个去模糊网络中来生成清晰的人脸图像。
联合先验估计和人脸复原方法主要是挖掘了人脸先验估计任务和人脸复原任务之间的互补性关系。这类方法通常联合训练人脸复原网络和先验估计网络,因此这类方法同时兼顾了两个子任务的优点,这能直接提高人脸复原任务的性能。
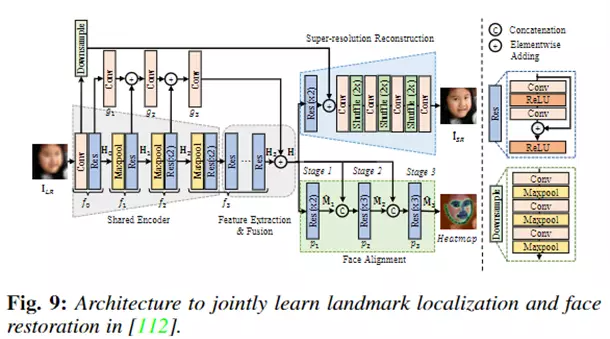
典型的方法如下图所示,研究人员提出了一种联合人脸对齐和人脸超分辨率的网络模型,该方法共同估计人脸的landmark 位置和超分辨率人脸图像。
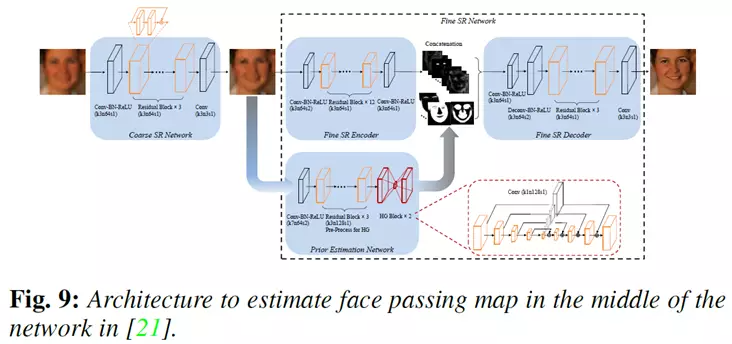
基于中间先验的人脸复原方法的核心思路是首先使用一个复原网络生成粗人脸图像,然后从粗图像中估计人脸先验信息,这样比直接从输入的低质量的图像可以获得更精确的先验信息。
典型的方法如下图所示,研究人员提出了FSRNet网络模型,这个模型在网络中间进行人脸先验估计。
具体的,FSRNet先用一个粗SR网络对图像进行粗恢复;然后分别用一个细SR编码器和一个先验估计网络对粗结果图像进行先验估计和细化;最后将图像细化特征和先验信息同时输入到一个精细SR解码器,恢复出最终的结果。
基于GAN网络结构的方法
这类方法主要分为两种类型:基于朴素GAN架构的方法(Plain GAN method)和基于预训练GAN嵌入式结构的方法(Pre-trained GAN embedding method)。
这两种方法的简明结构图如下所示:
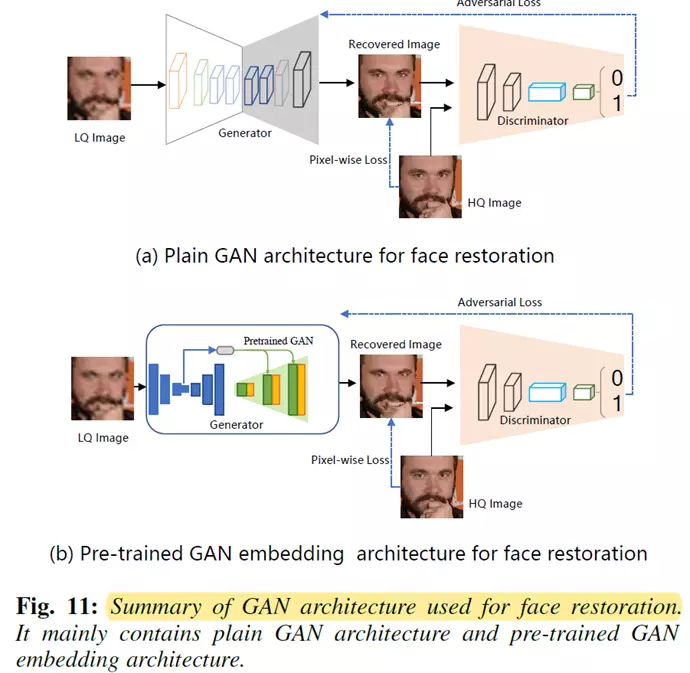
基于普通GAN架构的方法通常是在网络模型中引入对抗性损失,然后使用对抗性学习策略来联合优化判别器和生成器(人脸复原网络),从而生成更加逼真的人脸图像。
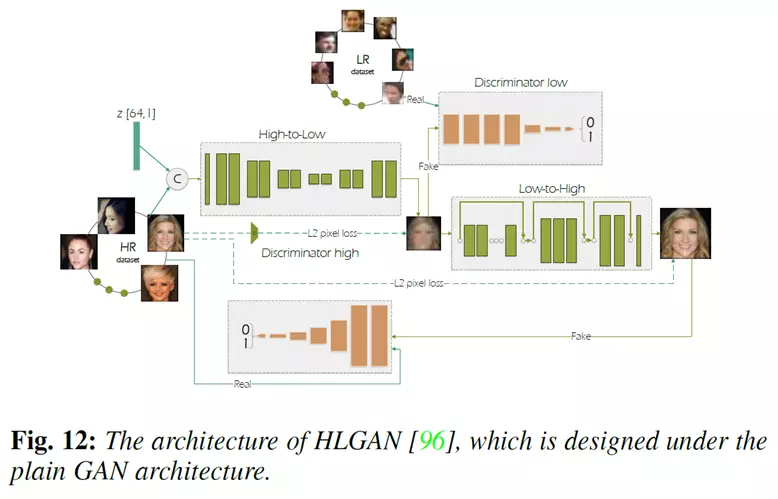
典型的方法如下图所示,研究人员提出了HLGAN网络模型,这个模型由两个生成对抗网络组成。
第一个是 High-to-Low GAN网络,它使用非成对的图像进行训练来学习高分辨率图像的退化过程。第一个网络的输出(即低分辨率人脸图像)被用来训练第二个 Low-to-High GAN网络,从而实现人脸超分辨率。
基于预训练GAN嵌入式结构的方法的核心思路是利用预训练的人脸GAN模型(如 StyleGAN)中的潜在先验,然后将潜在先验融合到人脸复原的过程中,借助于潜在先验和对抗学习策略来实现高效的人脸复原。
典型的方法如下图所示,研究人员设计了一个GFP-GAN 模型,这个模型主要包含一个降质去除模块和一个基于预训练GAN模型的先验模块,这两个模块通过一个latent code连接和几个通道分割空间特征转换层进行高效信息传递。
基于ViT网络结构的方法
最近Visual Transformer (ViT)网络架构在自然语言处理和计算机视觉等领域表现出了卓越的性能,这也启发了Transformer 架构在人脸复原任务的应用。
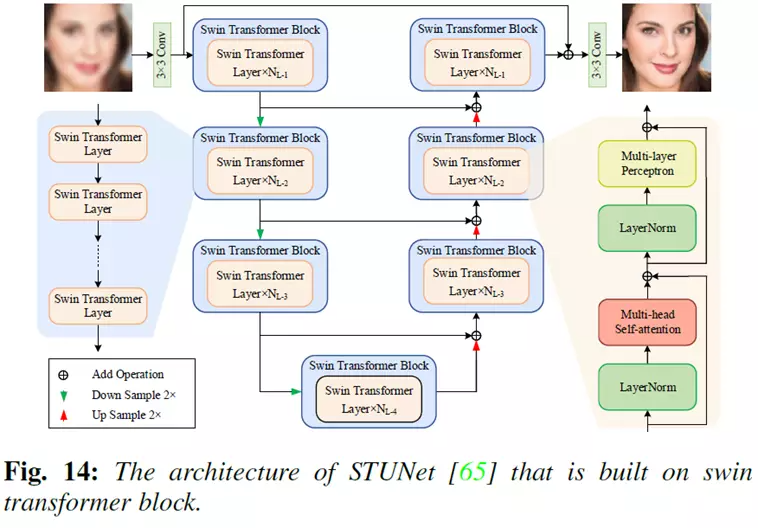
典型的方法如下图所示,基于Swin Transformer,研究人员提出了一种用于人脸复原的端到端Swin Transformer U-Net (STUNet)网络。
在 STUNet 中,transformer模块利用自注意力机制和移位窗口策略来帮助模型关注更多有利于人脸复原的重要特征,这个方法取得了良好的性能。
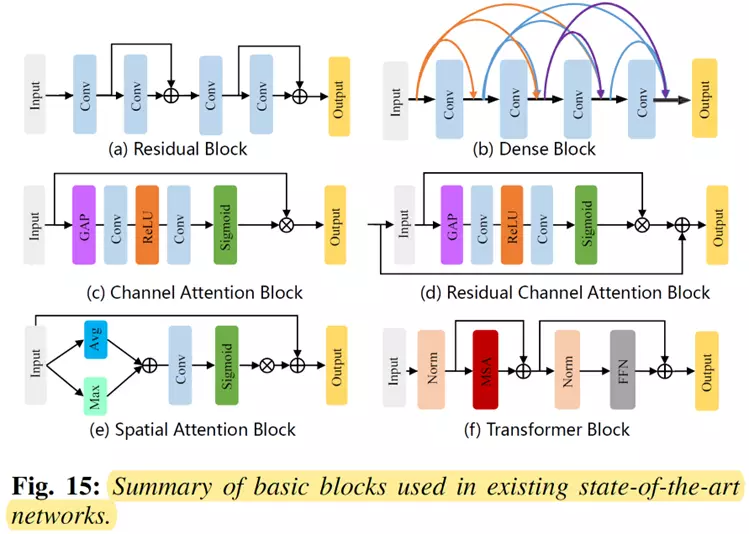
网络模型中常用的模块
在人脸复原领域,研究者们设计了各种类型的基础模块来构建出强大的人脸复原网络。常用的基础模块如下图所示,其中这些基础模块主要有残差模块(Residual Block),Dense模块(Dense Block),注意力模块(Channel attention block, Residual channel attention block, spatial attention block)和Transformer 模块(Transformer block)。
损失函数
人脸复原任务中常见的损失函数主要有以下几类:Pixel-wise loss (主要包括L1和L2损失), Perceptual loss, Adversarial loss, face-specific loss。各项人脸复原方法以及他们使用的损失函数总结在下表中:

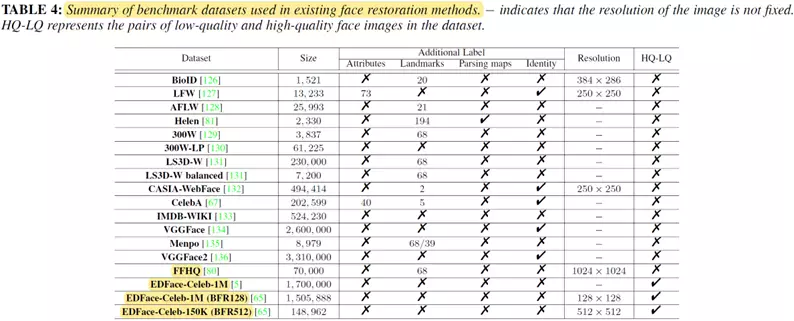
数据集
人脸复原任务相关的公开数据集以及相关统计信息总结如下:
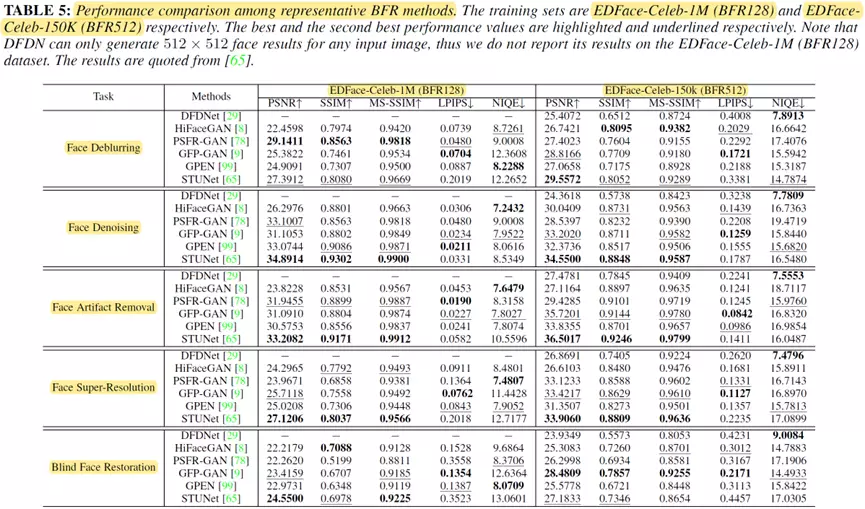
性能比较
本文总结并测试了一些具有代表性的人脸复原方法在PSNR/SSIM/MS-SSIM/LPIPS/NIQE等方面的性能
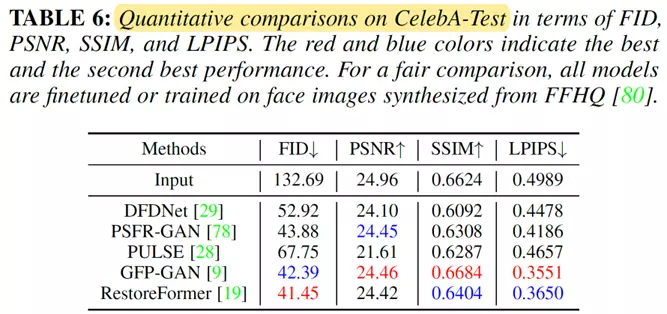
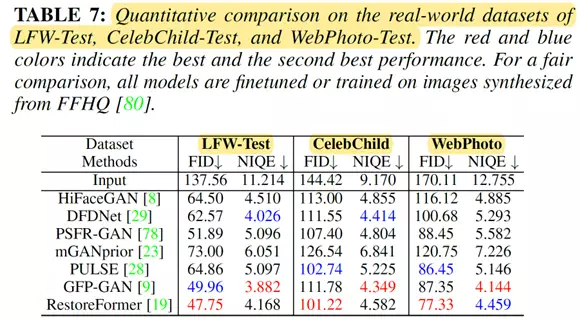
定量结果比较
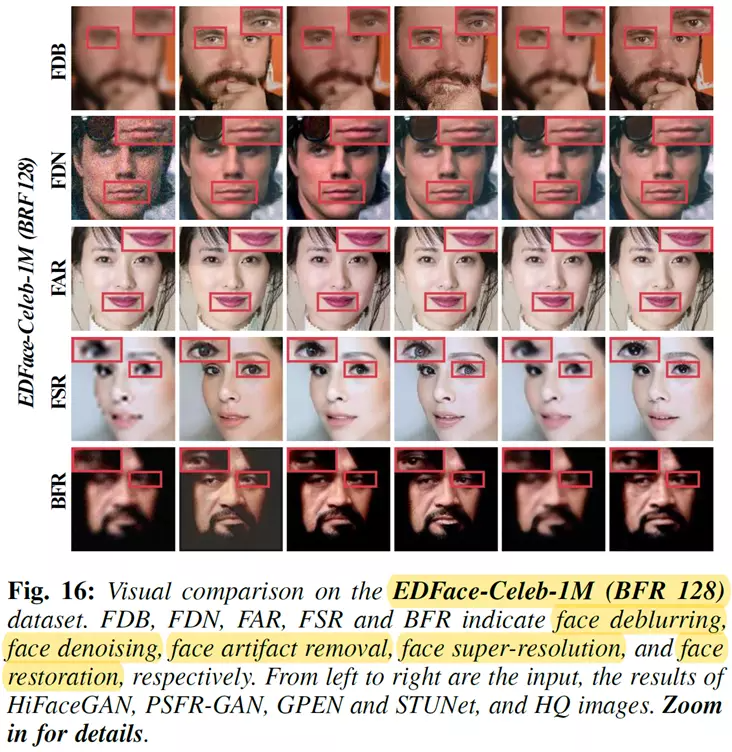
定性结果比较

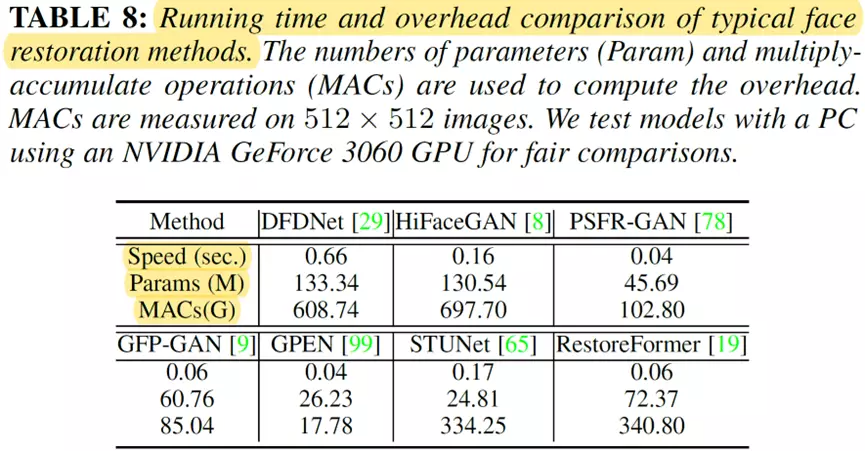
方法复杂性比较
尽管基于深度学习的人脸复原方法已经取得了一定的进展,但是仍然存在许多挑战和未解决的问题。
网络结构设计
对于基于深度学习的人脸复原方法,网络结构可以对方法的性能产生显著的影响。
例如,由于Transformer 架构的强大能力,最近的基于Transformer 的方法通常具有更好的性能。基于GAN的方法可以生成视觉上令人更加愉悦的人脸图像。
因此,在设计网络时,值得从不同的结构如CNN、GAN和ViT中进行学习和研究。
另一方面,最近基于Transformer的模型通常含有更大的参数,并且需要更高的计算成本,这使得它们难以部署在边缘设备中。
因此,如何设计一个性能强大的轻量级网络是未来工作的另一个潜在研究方向。
面部先验与网络的融合
作为特定领域的图像复原任务,人脸特征可以用于人脸复原任务。在设计模型时,许多方法旨在利用人脸先验来恢复真实的人脸细节。
尽管一些方法试图将几何先验、面部组件、生成先验或3D先验引入人脸复原的过程,但如何将先验信息更加合理地集成到网络中仍然是这个任务一个有前途的方向。
此外,进一步挖掘新的与人脸相关的先验,例如来自预训练GAN的先验或网络中的数据统计,也是这个任务的另一个方向。
损失函数和评价指标
对于人脸复原任务,广泛使用的损失函数有 L1 损失、L2 损失、感知损失、对抗性损失和人脸特定损失,如表3所示。
现有方法通常不使用单个损失函数,而是将多个损失函数与相应的权重相结合训练模型。但是,目前还不清楚如何设计更加合理的损失函数来指导模型训练。
因此,在未来,预计会有更多的工作寻求更准确的损失函数(例如,通用或人脸任务驱动的损失函数),以促进人脸复原这个任务的发展。此外,损失函数可以直接影响模型的评估结果。如表 5、6和7所示,L1损失和L2损失在PSNR、SSIM和MS-SSIM 方面往往获得更好的结果。
感知损失和对抗性损失往往会产生更令人愉悦的结果(即产生高 LPIPS、FID和NIQE值)。因此,如何开发能够兼顾人和机器两方面的指标进行模型性能更加合理地评估也是未来一个很重要的方向。
计算开销
现有的人脸复原方法通常是通过显著地增加网络的深度或宽度来提高复原性能,而忽略了模型的计算成本。
繁重的计算成本阻止了这些方法在资源有限的环境中使用,例如移动或嵌入式设备。
例如,如表8所示,最先进的方法RestoreFormer 有72.37M参数量和340.80G MACs的计算量,这在现实世界的应用程序中部署它是非常困难的。因此,开发具有更少计算成本的模型是未来重要的方向。
基准数据集
与图像去模糊、图像去噪和图像去雾等其他底层视觉任务不同,人脸复原的标准评估基准很少。
例如,大多数人脸复原方法通常在私有数据集上进行实验(从FFHQ合成训练集)。
研究人员可能倾向于使用偏向于他们提出的方法的数据。另一方面,为了进行公平比较,后续工作需要花费大量时间来合成私有数据集并重新训练其他比较方法。此外,最近广泛使用的数据集规模通常较小,不适合深度学习方法。
因此,开发标准的基准数据集是人脸复原任务的一个方向。未来,我们期望社区的研究人员能够构建更多标准和高质量的基准数据集。
视频人脸复原
随着手机和相机等移动设备的普及,视频人脸复原任务变得越来越重要。然而,现有的工作主要集中在图像人脸复原任务上,而视频相关的人脸复原工作较少。
另一方面,视频去模糊、视频超分辨率和视频去噪等其他底层视觉任务近年来发展迅速。
因此,视频人脸复原是社区的一个潜在方向。视频人脸复原任务可以从以下两个方面来考虑。
首先,对于基准数据集,我们可以考虑为此任务构建高质量的视频数据集,这可以快速促进视频相关算法的设计和评估,这有利于人脸复原社区的发展;
其次,对于视频复原方法,我们应该通过充分考虑连续视频帧之间的空间和时间信息来开发基于视频的人脸复原方法。
真实世界的人脸复原和应用
现有方法依靠合成数据来训练网络模型。然而,经过训练的网络不一定在现实世界的场景中表现出良好的泛化能力。
如图19所示,大多数人脸复原方法在面对真实世界的人脸图像时效果不佳。因为合成数据和现实世界数据之间存在很大的数据域差距。
尽管一些方法引入了一些解决方案来解决这个问题,例如无监督技术或学习真实图像退化技术。然而,他们仍然依赖于一些特定的假设,即所有图像都有类似的退化。
因此,现实世界的应用仍然是人脸复原任务的一个具有挑战性的方向。
此外,一些方法表明,人脸恢复可以提高人脸验证和人脸识别等后续任务的性能。然而,如何在一个框架中将人脸复原任务与这些任务结合起来也是未来的研究方向。
其他相关任务
除了上面讨论的人脸复原任务,还有很多与人脸复原相关的任务,包括人脸修饰、照片素描合成、人脸到人脸翻译、人脸修复、颜色增强和旧照片恢复。
例如,面部修复旨在通过匹配或学习来恢复面部图像的缺失区域。它不仅需要在语义上为缺失的面部组件生成新的像素,而且还应该保持面部结构和外观的一致性。老照片修复是修复老照片的任务,老照片的退化是相当多样和复杂的(例如,噪点、模糊和褪色)。
此外,一些任务侧重于面部风格迁移,例如人脸到人脸翻译和面部表情分析,这与人脸复原任务不同。
因此,将现有的人脸复原的方法应用到这些相关任务中,也是一个很有前景的方向,这可以触发更多的应用落地。








