
稿件:econometrics666@126.com所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软
件都放在社群里.欢迎到计量经济圈社群交流访问.
接着1.实证横截面资产定价最新进展, 2.5万字顶刊最全综述,2.利用机器学习进行实证资产定价, 金融投资的前沿科学技术! 3.诺奖得主五因子定价模型的国际检验, 做金融的得学起来了!4.站稳2900, TOP刊推出“中国金融市场发展及现状系统回顾”万字雄文!等,今天推出实证资产定价的最新进展:因子模型和机器学习。
*本文字数21536,文后有完整版PDF
正文
关于下方文字内容,作者:陈泽州, 浙江工业大学经济学院,通信邮箱:zezhou_chen@163.com
Stefano Giglio, Bryan Kelly, and Dacheng Xiu (2022), Factor Models, Machine Learning, and Asset Pricing, Annual Review of Financial EconomicsWe survey recent methodological contributions in asset pricing using factor models and machine learning. We organize these results based on their primary objectives: estimating expected returns, factors, risk exposures, risk premia, and the stochastic discount factor, as well as model comparison and alpha testing. We also discuss a variety of asymptotic schemes for inference. Our survey is a guide for financial economists interested in harnessing modern tools with rigor, robustness, and power to make new asset pricing discoveries, and it highlights directions for future research and methodological advances.
因子模型,机器学习和资产定价
摘要
本文从因子模型和机器学习方法的角度,对最近实证资产定价的发展进行了综述。本文按如下各研究的主要目标进行归类:对预期回报、因子、风险敞口、风险溢价和随机贴现因子的估计,以及模型比较和alpha检验。本文还探讨了各种用于推断的渐近分析。本综述为有兴趣利用严谨、稳健和有能力的前沿工具的金融经济学家提供了资产定价研究的指南,并强调了未来研究和方法更新的方向。一、 研究内容
本文的主要研究内容分为两部分。(1)对最近实证资产定价领域的方法论贡献进行综述,根据这些方法的主要目的进行分类:对预期回报、因子、资产的因子暴露、风险溢价、随机贴现因子的估计,以及对资产定价模型的比较和alpha检验。(2)本文探讨了相应的渐近理论,主要关注时间序列渐近(大T),横截面渐近(大N),或二维面板渐近(大T和大N),帮助金融经济学家找到最合适其研究需求的方法。在此过程中,本文比较了各种方法,突出其中优点和局限性,并指出未来的改进方向。
二、 模型设定
2.1 静态因子模型(Static Factor Models)
本文首先引入静态因子模型,作为全文的基准模型:

另外一种可以追溯到Connor & Korajczyk(1986)的框架最近重新流行起来,这种框架假设所有因子暴露都是隐式的,这放宽了上述设定中的限制性假设(所有因子已知且可观测)。第三个框架假设因子暴露是可观测的,但这些因子是隐式(Latent)的。这可以说是实务界最普遍的框架,植根于Rosenberg(1974)最初提出的MSCI Barra模型。该模型的流行源于它更方便地刻画了个股回报的随时变的暴露。本文接下来开始探讨随时变的因子暴露。
2.2 条件因子模型(Conditional Factor Models)
式1中的静态模型仅适用于某些资产组合(尽管即使在这种情况下,静态的假设也可能有问题),但对于大多数的单个资产而言是不够的。而重要的是模型能够描述单个资产的情况,而不仅仅是排序后的投资组合,才能更完全的理解资产市场上的异质性。
2.2.1 随时变的风险敞口
个股的风险敞口很有可能会随着公司的成长而变化,具有固定期限和非线性收益结构(例如债券和期权)的资产随着到期日或标的资产价值的变化,其风险敞口也会出现变化(Büchner & Kelly,2022,Kelly et al.,Forthcoming)。因此因子模型需要考虑随时变的条件风险溢价:
2.2.2 IPCA
Berra模型在中包含多个个体层面特征和行业层面的变量,这种特定的变量选择不是公开的,并且证据表明模型的参数是过多的。Kelly et al.(2019)提出了IPCA(Instrumented Principal Components Analysis)方法,通过降维避开了Berra模型的问题:
这与式1的静态因子模型相对应:在特征驱动的风险敞口的范围内,按这些特征进行排序消除了排序后投资组合的风险敞口的时间变化。因此,式1表示的静态投资组合可以直接应用于按相关特征适当排序的投资组合;或者可以将个股用作测试资产,使用IPCA解释其特征相关的随时变风险载荷。
2.2.3 随时变的风险溢价
2.2.4 非线性假设
从本质上讲,IPCA和相关模型采用基于可观测特征的数据来线性近似风险敞口,但线性的假设可能无法满足。基本上,前沿理论资产定价模型都认为是非线性的(Campbell & Cochrane,1999;Santos & Veronesi,2004;Bansal & Yaron,2004;He & Krishnamurthy,2013)。基于此,Connor et al.(2021)和Fan et al.(2016)将因子的beta为特征的线性函数的假设修改为因子的beta是特征的非参数函数(尽管为了理论上的可操作性,这些特征假定为不随时间变化)。Kim et al.(2020)据此构建了套利投资组合。Gu et al.(2021)利用条件自编码器模型(Conditional Autoencoder Model)将Berra模型和IPCA扩展到非线性的条件下,并增加了额外的解释变量。该模型利用更加真实和灵活的beta函数替代了式6中的线性beta设定。自编码器模型是第一个明确解释了股权收益的风险-收益权衡的深度学习模型。然而,深度学习模型经常由于其“黑箱”的性质受到批评,严格的理论证明仍然远远落后于模型构建和训练算法的发展。连续时间因子模型(Continuous-time Factor Models)更适合用于对资产回报的时变动态进行建模,尤其是在可获得高频数据的时候。本文推荐对此有兴趣的读者参考Aït-Sahalia et al.(2021)。
三、 研究方法综述
传统的资产定价模型的统计推断方法是在低维情境下的(如25个资产在几十年的数据)。目前,与权益资产回报相关的解释变量迅速增长(如Harvey et al.,2016),研究者开始使用单个资产进行测试(如Kelly et al.,2019)。随着向大规模因子集和测试资产的过渡,实证资产定价开始越来越需要高维统计方法。本文综述了经典的方法,但着重突出应对高维环境的统计方法。第3.1节本文探讨使用机器学习方法来衡量条件预期回报率而不施加因子定价模型的限制性条件。在第3.2节到第3.5节中,本文讨论了因子模型设定、估计和评价的各个方面。在第3.6节中,本文重点关注预期回报和因子暴露之间的差异来探讨alpha检验。
3.1 衡量预期回报率
资产定价的一个核心目标是了解预期回报,对于更清楚地了解金融市场至关重要。但对预期回报的观测会受到会影响资产价格的不可预测信息噪音的干扰,使得预期回报难以衡量。许多资产定价研究通过因子定价模型的视角来理解资产之间预期回报的差异。然而,越来越多的证据表明,资产的平均回报有时会大大偏离因子定价所隐含的限制。因此,在讨论因子模型之前,本文先概述了不施加资产定价限制性条件的预期回报的简约式模型,并着重关注衡量预期回报率的机器学习方法。本节的主要内容概括如表1所示,具体内容见下或原文。表1 衡量预期回报率的主要方法
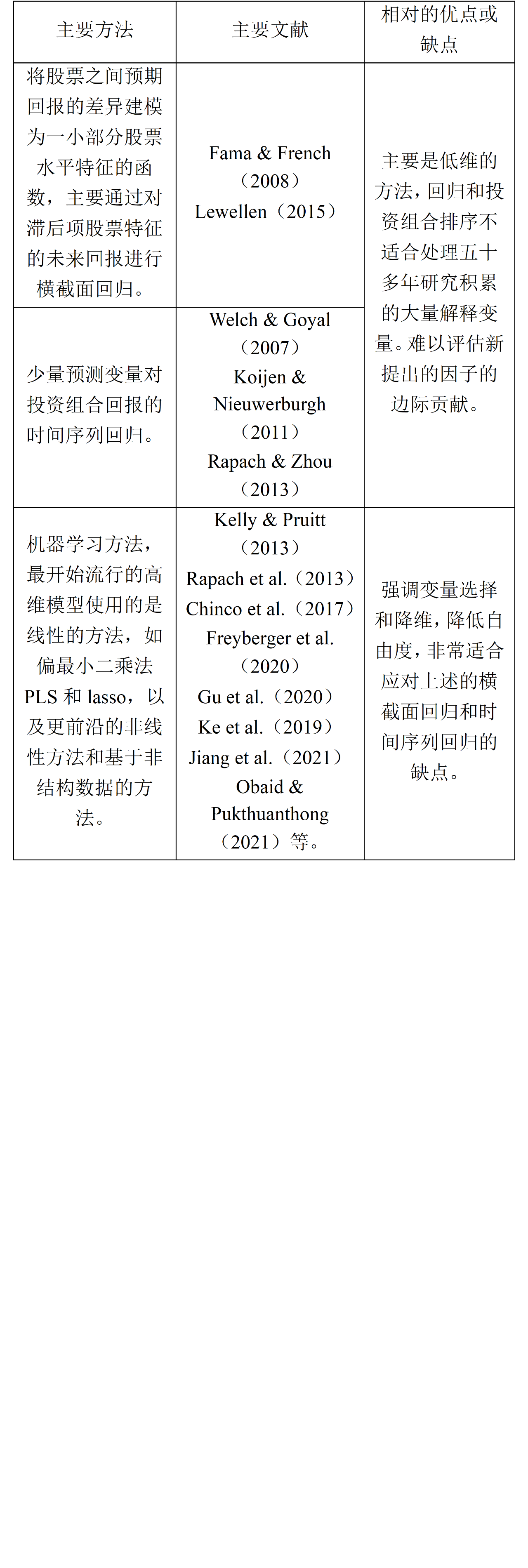
对股票回报率预测的经验研究文献有三个主要的方向,前两个分别为(1)将股票之间预期回报的差异建模为一小部分股票水平特征的函数(Fama & French,2008;Lewellen,2015);主要通过对滞后项股票特征的未来回报进行横截面回归(2)少量预测变量对投资组合回报的时间序列回归(Welch & Goyal,2007;Koijen & Nieuwerburgh,2011;Rapach & Zhou,2013)。这些传统方法具有可能的严重局限性,机器学习中更前沿的统计方法可以帮助克服这些局限性。最重要的是,回归和投资组合排序不适合处理五十多年研究积累的大量解释变量。难点在于如何评估新提出的因子的边际贡献。第三个方向基于机器学习方法,强调变量选择和降维,降低自由度,非常适合应对上述的难点。最开始流行的高维模型使用的是线性的方法,如偏最小二乘法PLS(如Kelly & Pruitt,2013;Rapach et al.,2013)和Lasso(Chinco et al.,2017;Freyberger et al.,2020)。Gu et al.(2020)对用于回报预测的机器学习方法进行了广泛的分析,不仅考虑了正则化线性方法,还考虑了更前沿的非线性方法,包括随机森林、提升回归树和深度学习。该研究表明,在估计预期回报率时,使用机器学习方法对结果有巨大的提升,表现为样本外的提高,以及投资策略的收益提升。经验分析还发掘了信息量最大的解释因子,有助于给出经济学解释。机器学习还可以使用复杂和非结构化数据集中的预测信息来改进预期回报估计。例如,Ke et al.(2019)提出了一种新的有监督的主题模型,从原始新闻文本预测回报率,在样本外预测上有不错的表现。Jiang et al.(2021)和Obaid & Pukthuanthong(2021)使用计算机视觉文献中的机器学习模型来挖掘图像数据。文本和图像数据在数天和数周的短期回报预测中都具较好的贡献,并且可能受到相对快速变化的市场情绪的支撑,而不是在季度或年份的范围内起主导作用的基本面信息。事实上,情绪和相关的行为经济因素正在成为金融市场研究的一个核心方向,为机器学习挖掘丰富的复杂的非线性信息提供了沃土。整体而言,预测回报率的文献少有深入探究预测背后的经济机制(如风险-收益权衡、市场摩擦或行为偏差)。例如,区分风险溢价和错误定价需要更结构化的建模方法,因子模型是在这上面的主要研究方法。
3.2 对因子和暴露的估计
在因子模型中,资产的总方差可分解为系统性风险和资产异质性风险。许多因子模型在因子及因子暴露是否已知,以及模型使用有条件风险分解还是无条件风险分解的假设上存在差异。本节的主要内容概括如表2所示,具体内容见下或原文。表2 对因子及其暴露估计的方法
3.2.1 时间序列回归和横截面回归
若式1中的因子已知,则可以通过逐一资产的时间序列回归(TSR)来估计因子暴露,以矩阵的形式写为
时间序列回归和横截面回归的局限性在于它们依赖于因子或因子暴露完全可观测这一严格的假设。尽管理论研究为常见的风险因子提供了参考,以及公司的情况与因子暴露相关,但数据符合这些假设是不太可能的。
3.2.2 PCA
当因子及其载荷均未知时,可以采用PCA来提取潜因子及其载荷。PCA在资产定价中的应用可以追溯到Chamberlain & Rothschild(1983)和Connor & Korajczyk(1986),并使用得越来越多(如Kozak et al.,2018;Pukthuanthong et al.,2019;Kelly et al.,2019;Giglio & Xiu,2021)。在出现位置的线性变换之前,PCA可以识别静态因子模型(式1)中的因子极其载荷。
虽然考虑潜因子和暴露可以为研究增加更大的灵活性,但这种变换也使得对潜因子模型中因子的解释更为困难。当部分因子可观测,部分因子不可观测时,PCA也可使用。Giglio et al.(2021a)提出,在回报率对可观测因子的时间序列回归后,可对得到的残差项进行PCA,且在未知的线性变换出现之前可观测因子和潜因子的beta估计与真实的beta一致。
3.2.3 风险溢价PCA
PCA的一个缺陷在于其只能从已实现的回报协方差中提取潜因子的信息。
3.2.4 IPCA(Instrumented PCA)

Kelly et al.(2021)使用IPCA的方法来解释权益类回报的动量和长期逆转。IPCA方法同样扩展到了其他资产大类,例如公司债券(Kelly et al.,Forthcoming)和期权(Büchner & Kelly,2022)。
3.2.5 自编码器学习
IPCA假定条件因子载荷是资产特征的线性函数,这一假设可能存在问题。这里本文介绍自编码器(Autoencoder)的深度学习模型。机器学习的研究很早就关注了自编码器与PCA之间的联系(如Baldi & Hornik,1989)。与PCA的线性假设不同,自编码器使用神经网络来估计因子及其载荷,即标准的自编码器仅使用回报数据来估计潜因子模型,因此其没有使用IPCA需要的额外的非回报的条件变量。Gu et al.(2021)提出了自编码器因子模型,既使用了灵活的神经网络方法,同时利用了额外的非回报的条件信息(如IPCA)。在这一条件自编码器模型中,股票特征通过前馈神经网络映射到betas当中,从而用更符合现实的非线性设定下的betas替代IPCA中的betas。原文图1展示了模型的基本结构。该模型的数学表达形式与式4相同。在该模型(如图所示)的左侧,因子载荷是协方差(如公司特征)的非线性函数,而模型右侧则将因子建模为个股回报的投资组合。

式19使用单个资产回报的特征排序的投资组合(式7)对神经网络进行初始化,这一步可以会比个股回报率面板的不完整问题,并对数据进行了初步的缩减。式20是回报数据在隐藏层迭代下不断降维的过程。式21是维因子在输出层的输出。当自编码器只有一个隐藏层和线性的激活函数时,其等价于上述的PCA。神经网络的灵活性也带来了可能的过拟合问题,本文在此介绍了几种通用的算法。训练集,验证集,测试集。将全样本分为三个不相交的子样本,并保留原数据的时间顺序。第一个子样本(训练集)用于估计特定超参数下的模型。第二个子样本(验证集)用于调整超参数,即选择超参数来优化验证目标。验证集并非真正的样本外预测,而同样是模型的输入和训练部分。正则化。防止过拟合的常见方法是在目标函数上增加惩罚项,这种方法降低了模型的样本内表现,以提高样本外表现的稳定性,即要求惩罚项可以降低模型对噪音(noise)的拟合,保留对信号(signal)的拟合。Gu et al.(2021)将估计的目标函数设定为第三种正则化方法是,Gu et al.(2021)在训练神经网络时采用了集成(Ensemble)的方法,即使用多个随机的seed来初始化神经网络,并使用所有神经网络输出的平均来作为模型的预测。这种方法可以增强结果的稳定性。优化算法。神经网络中高度的非线性和非凸性使得暴力计算很难进行。Gu et al.(2021)采用了自适应矩估计算法(Adam),使用梯度的一阶矩和二阶矩估计来计算单个参数的自适应学习率。Gu et al.(2021)还采用了批标准化(Batch Normalization,Ioffe & Szegedy,2015),以控制神经网络中不同区域和不同数据集之间预测因子的变异性。
3.2.6 矩阵补全
金融研究中也需要处理非平衡面板数据。Giglio et al.(2021a)使用了一种矩阵补全算法来处理提取因子和因子载荷时的缺失数据。3.3 对风险溢价的估计
因子的风险溢价是投资者由于面临与该因子相关的风险敞口而获得均衡补偿的信息。资产定价的一个核心预测是风险因子应当有风险溢价,投资者因这些因子的风险敞口获得不错,保持对所有其他风险来源的敞口保持不变。对于可交易因子(例如CAPM中的市场投资组合),估计风险溢价可简化为计算该因子的样本平均超额回报。这一估计简单、可靠,且需要的假设最少。然而,许多理论模型是针对本身不是投资组合的非交易因子(如消费、通货膨胀、流动性等)构建的。为了估计这些因子的风险溢价,需要构建其可交易的“替代”(Tradable Incarnation)。这种可交易因子是一种“对冲投资组合”,它分离出了不可交易因子的风险,同时保持所有其他风险不变。构建不可交易因子的可交易对手有两种标准方法:两步回归(Two-pass Regression)和因子模拟投资组合(Factor Mimicking Portfolio)。
3.3.1 传统的两步回归
3.3.2 因子模拟投资组合
3.3.3 三步回归和遗漏因子偏差

由于该估计不依赖于事先设定的估计风险溢价的资产定价模型,因此可以有效的估计理论文献提出的不可交易因子的风险溢价(而不需考虑其他模型中因子的作用)。而如果真实存在的一些因子被忽略,则MacBeth回归估计是有偏的。与此相关,Gagliardini et al.(2019)提出了一种检验遗漏变量数量的准则。
3.3.4 弱因子
除了遗漏因子偏差外,另一个影响传统两步回归有效性的是弱识别问题。Kan & Zhang(1999)最早发现两步回归中得到的风险溢价会因为模型包含“无用”因子(测试资产中该因子暴露为0)而出现错误。Kleibergen(2009)进一步指出若betas相对较小则统计推断是无效的。在实践中会存在这种问题,因为许多测试资产对宏观经济冲击并不是很敏感。此外,当betas共线时,也可能能出现排序不足(Rank-deficiency)的问题(即使因子有很强的独立性),也就是说,在解释预期回报的变化上,一些因子是多余的。这在实践中也存在问题,研究文献发现了非常多的因子,其中很多都是密切相关的,而没有为横截面增加任何的解释力。当β接近于0时,估计误差会导致变量误差(Error-in-variables)的问题。Kleibergen(2009)提出了几种风险溢价的检验统计量,这些统计量在所有的值上都是一致有效的。当存在弱因子时,这些检验的稳健性是以缺乏模型效果为代价的。这些检验还可用于联合检验所有因子的风险溢价,但通常不能提供任何特定因子风险溢价的信息。Bryzgalova(2015)提出通过有惩罚的两步回归来消除弱因子,以提高检测强因子的能力。然而,消除弱因子可能导致无效的推断,并且带来对其余因子的风险溢价估计较大的偏差。
Giglio et al.(2021b)认为,弱因子问题根本上来讲是测试资产选择的问题。该研究认为,因子的强度不是因子本身的属性,而是由测试资产的选择决定的。弱因子仍然可能需要定价,因此仅仅是消除这些弱因子是不可取的方案。相反,该研究认为应当积极选择测试资产来保证所选资产有足够的对感兴趣因子的暴露。换句话讲,通过适当地资产选择(即选择高度暴露的资产)可以使因子更强。为了同时解决弱因子和省略因子问题,该研究提出一种迭代的有监督的PCA方法,讲相关性筛选(Correlation Screening)和Giglio & Xiu(2021)的三步回归结合起来。这一估计对遗漏变量偏差、弱因子问题和观测因子中的测量误差都具有稳健性。选择那些测试资产?测试资产也是实证资产定价的重要组成部分,但少有人致力于系统严格地对其进行研究。与可交易因子相比,测试资产是研究不可交易因子的核心,因为它们用于构建必要的因子模拟投资组合,而这些投资组合又是大多数资产定价分析的输入。第一种是大多数文献选择的方式,即依Fama & French(1993)的方式,根据一些特征(如规模和价值)对投资组合进行排序。Lewellen et al.(2010)建议在测试资产中加入行业投资组合;Giglio et al.(2021b)认为使用普通的横截面可能会带来弱因子问题,因为这些资产可能没有对感兴趣因子的暴露;Ahn et al.(2009)提出要按单个证券的相关性进行聚类,使得类内相似,类间不同,但这一提议没有明确的理论依据。第二种方法是在测试资产集中纳入按过去几十年间发现的更大的特征集排序的投资组合,在数百个投资组合的数量级上(如Kozak et al.,2020;Bryzgalova et al.,2020b)。顺其思路,IPCA有一个较好的特点,其可以从个股或特征管理的投资组合的角度作为测试资产来看待和评估。Kelly et al.(2019)认为这可以减小研究者在测试资产选择中的主观性。第三种方法是选择针对特定感兴趣因子的测试资产(如Ang et al.,2006)。一个常见的方法是估计给定因子的股票层面的betas,然后根据估计的暴露将资产加入到投资组合中。预计这些分类投资组合的一小部分能够特别给出感兴趣因子的信息,但它受到遗漏因子问题的影响,因为它往往只关注单变量的暴露。Giglio et al.(2021b)以这些方法为基础,从大量测试资产开始,然后仅仅选择可以提供信息的资产进行估计。
3.4 对随机贴现因子(SDF)及其载荷的估计
因子的风险溢价等于其随机贴现因子(SDF)的(负)协方差。在式1中,随机贴现因子可以写为
3.4.1 广义矩估计
3.4.2 基于PCA的方法
Kozak et al.(2018)认为,缺乏近乎套利的机会迫使预期回报(大致上)与共同因子协方差一致,即使在信念扭曲会影响资产定价的世界中也是如此。资产回报的强共同变异(Strong Covariation)表明,随机贴现因子可以表示为几个主要回报变化来源的函数。资产回报的PCA可以恢复主要回报变化的共同组成部分。具体而言,第3.3.3节中三步的前两步产生的随机贴现因子估计量不依赖于对因子身份的认知(Knowledge of Factor Identities):
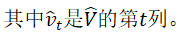
3.4.3 带有惩罚的回归
PCA方法中,随机贴现因子基本上被参数化为少量的线性因子组合(式29)。Kozak et al.(2020)考虑用一组可交易的测试资产回报来表示随机贴现因子:
3.4.4 双重机器学习(DML)
相对于目前研究文献发现的成百上千的因子,如何判断一个新的因子是否增加了资产定价模型的解释力?Feng et al.(2020)试图通过系统地评估单个因子相对于现有因子的贡献以及在这个高维情境中进行适当的统计推断来解决这个问题。虽然上一节中讨论的机器学习方法通过采用正则化来权衡偏差和方差,但正则化和过拟合都会导致偏差,从而影响统计推断。Chernozhukov et al.(2018)引入了一个通用的双重机器学习(DML)框架,以缓解偏差并在存在高维干扰参数的情况下建立对感兴趣的低维参数的有效推断。Feng et al.(2020)根据这一框架测试了新提出因子的随机贴现因子载荷。
3.4.5 参数化投资组合和深度学习随机贴现因子
由于随机贴现因子(当投影到可交易资产上时)是由最有投资组合回报生成的,因此估计随机贴现因子实际上是构建最优投资组合的问题。传统的均值-方差分析的重要阻碍是低信噪比:无法准确地得到大量横截面可投资资产的预期回报和协方差。在前文中,本文讨论了基于因子的方法,这些方法要么是利用了经济学的直觉和理论,要么是通过统计机器学习的方法来“规范化”这一学习问题。对预期回报和协方差的估计越好,投资组合的表现就越好。
Brandt et al.(2009)提出了一种针对投资组合优化问题的新方法:直接将投资组合权重参数化为资产特征的函数,然后通过求解效用优化问题来估计参数:
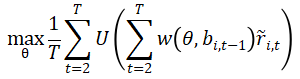
其中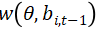 是股票特征的参数函数,
是股票特征的参数函数,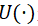 预先设定的效用函数。Demiguel et al.(2020)表明,当仅限于线性参数权重函数和均值-方差效用的特殊情况时,这种方法等价于通常的均值-方差投资组合配置范式,但是以特征排序的投资组合作为基础资产。Cong et al.(2021)将此框架扩展到更灵活的神经网络模型,并通过强化学习优化投资组合的夏普比率(随机贴现因子),其中具有50多个特征及其滞后项。Chen et al.(2019)将测试资产投资组合的随机贴现因子载荷和权重参数化为两个独立的神经网络,并采用对抗最小最大值方法来估计随机贴现因子。两者都采用长短期记忆(LSTM)模型来整合来自宏观变量、公司特征或过去回报的滞后时间序列信息。
预先设定的效用函数。Demiguel et al.(2020)表明,当仅限于线性参数权重函数和均值-方差效用的特殊情况时,这种方法等价于通常的均值-方差投资组合配置范式,但是以特征排序的投资组合作为基础资产。Cong et al.(2021)将此框架扩展到更灵活的神经网络模型,并通过强化学习优化投资组合的夏普比率(随机贴现因子),其中具有50多个特征及其滞后项。Chen et al.(2019)将测试资产投资组合的随机贴现因子载荷和权重参数化为两个独立的神经网络,并采用对抗最小最大值方法来估计随机贴现因子。两者都采用长短期记忆(LSTM)模型来整合来自宏观变量、公司特征或过去回报的滞后时间序列信息。
3.5 模型设定检验和模型比较
金融学研究带来了大量的因子和可选择的模型,一些最近和突出的模型以可观测的投资组合为因子(如Fama & French,2015;Hou et al.,2015;Stambaugh & Yuan,2017;He et al.,2017;Daniel et al.,2020)。另一方面,纯粹的统计检验往往是能力有限,因为样本量太有限,无法梳理出真实的模型。
3.5.1 GRS检验和扩展
具体而言,因子定价模型可以看作是统计学假设检验问题。这类检验通常关注零alpha条件:如果因子模型反映了真实的随机贴现因子,那么其应当为所有测试资产定价时alpha为0。原假设为:

3.5.2 模型比较
“All models are wrong, but some are more useful than others.” 因此,对模型的检验可能不如直接对模型进行比较更能提供有价值的信息。Gibbons et al.(1989)指出,式1给出的因子模型直接表明了GRS检验统计量的以下等价性:

3.5.3 贝叶斯方法
Barillas & Shanken(2018)提出了一种贝叶斯方法,计算有可交易因子的资产定价模型集合的模型概率。该研究根据Harvey & Zhou(1990),采用现有的对betas和残差协方差的Jeffreys先验分布: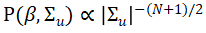
原假设是alpha为0,其中alpha为集中在0上的delta函数。也可以替代为alpha服从下列分布:
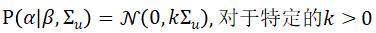
Bryzgalova et al.(2020a)进一步扩展了贝叶斯框架,以便在存在可能的弱因子或不可交易因子的情况下进行因子选择。该研究使用式32重新参数化预期收益,使用spike-and-slab作为的先验分布来进行模型选择并确保贝叶斯因子的有效性。具体做法可见原文。
3.6 Alpha和多重检验
Alpha是预期回报中无法用风险敞口解释的部分。因此,相对于现状模型(Status quo Model,如CAPM或Fama-French三因子模型),具有显著alpha的投资组合是异常(Anomaly)。Harvey et al.(2016)探究了超过300个文献中提出的异常,并认为其中大量异常是由于数据窥探(Data Snooping)和多重检验(Multiple Testing,MT)造成的统计假象(Statistical Artifacts)。资产定价领域的研究很早就意识到了alpha检验中的数据窥探问题和多重检验问题,并采取各种方法来解决(Lo & MacKinlay,1990;Sullivan et al.,1999)。

相关研究中,Chen(2021)认为-hacking需要大量的尝试来解释文献中记录的异常alpha发现。更明确地说,这些异常从广义上讲是可复制的(见Chen & Zimmermann,2021;Jensen et al.,2021)。
四、 渐近理论
文献中主要有三种渐近方式,用来刻画因子模型、风险溢价和alphas的统计性质。传统的推断依赖于大T固定N渐近,这仍然是资产定价中最常见的设定。第二种方式允许N和T趋于∞(有速率限制)。第三种方式是大N固定T。在统计推断中需要考虑每种方式的优缺点,下文使用了一些例子进行说明。4.1 固定N,大T
在传统的方式下,Shanken(1992)推导了两步估计量(式9和式24)的中心极限定理,OLS和GLS的两步风险溢价估计量的渐近方差分别为4.2 大N,大T
上述分析背后的一个关键假设是,所有因子都是普遍存在的(Pervasive)。虽然这一假设由于其简单性和便利性而在目前的因子分析中被广泛采用(如Bai,2003),但它经常与经验证据相冲突。如果违反此假设,PCA可能无法发现因子及其风险敞口。有越来越多的计量经济学文献开始关注弱因子模型。Bai & Ng(2008)认为,在构造主成分时应考虑异质性误差项的性质。删去嘈杂的数据可能可以提高预测的能力。该研究比较了影阈值(hard thresholding),lasso,弹性网络(Elastic Net)和最小角(Least Angle)回归在经验研究上的能力,以选择因子估计的子集(没有理论上的分析)。Huang et al.(2021)提出了缩放主成分分析(Scaled PCA),将来自预测目标的信息纳入到因子提取过程中。Bailey et al.(2020)假设因子暴露的载荷矩阵具有稀疏的结构,并提出了了因子强度的度量。Freyaldenhoven(2019)提出了存在弱因子时因子数量的估计,尽管有时“弱”因子也可能是强的,因为在这种情况下,PCA仍然可以一致的恢复这些“弱”因子。Pesaran & Smith(2019)研究了因子强度和定价误差对风险溢价估计的影响,发现随着因子变弱,传统的两步风险溢价收敛率较低。Lettau & Pelger(2020a)将其提出的风险溢价PCA与普通PCA估计量在所有因子都非常弱的情况下进行了比较,以至于它们无法再同级生与异质噪声区分开来(可见Onatski(2009)和Onatski(2012)在类似的弱因子模型上的理论分析结果)。在此情况下,任何风险溢价或随机贴现因子的估计量都是不一致的。Lettau & Pelger(2020a)表明,风险溢价PCA并不能一致地恢复随机贴现因子,但其与随机贴现因子的相关性高于从普通PCA中获得的随机贴现因子。Giglio et al.(2021b)没有关注这种弱因子的极端情况,而是构建了涵盖各种因子强度的渐近理论,可以带来对因子、风险溢价和随机贴现因子的一致估计,具体形式上,该研究考虑了收益协方差矩阵中因子成分的最小特征值发散而由于异质误差导致的最大特征值有界的情况。在这种一般设定中,当且仅当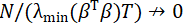 时,才会出现弱因子问题,在这种情况下,Giglio & Xiu (2021)的三步估计量、岭估计量或PLS估计量,以及Lettau & Pelger(2020a)的风险溢价PCA估计都给出了有偏的风险溢价估计,但Giglio et al.(2021b)的有监督的PCA估计仍然有效。
时,才会出现弱因子问题,在这种情况下,Giglio & Xiu (2021)的三步估计量、岭估计量或PLS估计量,以及Lettau & Pelger(2020a)的风险溢价PCA估计都给出了有偏的风险溢价估计,但Giglio et al.(2021b)的有监督的PCA估计仍然有效。
4.3 大N,固定T

Zaffaroni(2019)扩展了这一框架,考虑了潜因子,对基于PCA的时候风险溢价估计量和相关的事后随机贴现因子(Ex-post SDF)提供了新的渐近分析。这种设定的优势在于它能自然地处理随时变的因子模型,其中每个特征都允许随时间变化,包括载荷、异质性风险和风险因子的数量。五、 结论和展望
因子模型是实证资产定价的主要模型框架,本文综述了前沿的因子模型,尤其是在高维情境下的以及相应的机器学习统计工具。机器学习并不是经验研究的“灵丹妙药”,也不能替代经济理论和经验研究,金融领域的只是仍然是资产市场统计学习问题不可缺失的部分。本文作者认为未来实证资产定价研究最有希望的研究是将经济理论与机器学习真正的融合,因为资产定价理论上投资者信念会以细微、复杂的方式参与定价,而机器学习等统计模型可以灵活地适应丰富和复杂信息的情境。机器学习因子模型就是这种融合的一个例子。本文关注的是方法论上的创新和贡献,主要专注于统计框架而不是模型背后的经济学理论基础和设定。文献经常会分为可观测因子模型和潜因子模型两类,本文中讨论的一些方法适用于可观测因子的情境(或是混合的情境),但由于研究中对潜因子方法的日益重视,本文作者也偏向于潜因子方法。本文作者认为,这一领域从基于CAPM的回报因子模型分析之后,研究开始偏向与理论几乎没有关系的纯统计学模型上,而未来研究最重要的方向可能是重新建立资产定价理论与实证回报模型之间的联系。机器学习由于能够挖掘出收益的决定因素,可能会成为这项工作的关键工具。这需要其更直接地将收益与基本经济活动及现金流数据结合起来,并强调其发现的关系的经济学解释。按照这一思路,行为金融学的新的理论研究提供了将收益与更容易获得的非价格数据(如对调查的回复、文本叙述)相结合的机会。机器学习方法会成为推导出价格与这些非标准数据中经济主体信念之间关系的关键。另一个重要的研究方向是金融市场和资产回报的结构性变化。收益模型应该如何适应经济的结构演变、监管和政治制度的变化以及金融技术的进步?如何发现经济反馈机制的微妙的收益动态,例如市场学习和竞争效应带来的alpha衰减(Alpha Decay)?
关于金融学研究,参看:1.
2022年诺贝尔经济学奖: 表彰Bernanke, Diamond和Dybvig对银行和金融危机的研究贡献,2.基于文本大数据分析的会计和金融研究综述, 附24篇相关讲解文章!3.一篇说“可能重新改写经济学基本公式和金融数学推算”的投稿,4.中文顶刊上关于零工经济的研究, 思路和方法借鉴的是这篇金融TOP刊文章?5.从耶鲁到香港, 从金融到历史后, 陈志武教授第一篇TOP刊文章是OLS+IV组合!6.TOP5刊, 我国政府为什么对金融市场进行定期和密集的干预? 7.中国数字普惠金融的测度及其影响研究: 一个文献综述,8.Top金融,经济与会计期刊中的文本分析, 一项长达2万字的综述性调查,9.经济金融学研究中的大数据革命, 将来的实证研究该何去何从?10.合作者把代码弄丢了! 只能撤稿! 发表在最TOP金融期刊上, 但用代码复制不出结果! 11.金融, 管理和会计, 中国人在哪个领域做得最好呢?基于TOP国际期刊的发现,12.前沿: 大数据对经济金融研究的致命影响, 那又该如何推动这些领域的前沿研究呢?13.华人金融学术女神为运用工具变量估计方法做因果推断的学者提供了如下宝贵建议!14.推荐"数字普惠金融指数", 省市县三级面板数据可做很多实证研究,15.利用机器学习进行实证资产定价, 金融投资的前沿科学技术! 16.金融学文本大数据挖掘方法与研究进展, 金融学者看过来!
17.权威前沿: 大数据时代经济学和金融学中的预测方法和实践, 不看就不要提前沿!18.诺奖得主五因子定价模型的国际检验, 做金融的得学起来了!19.神器! 统计和金融计算器, 词云和情感分析器强大到无敌!20.最全: 深度学习在经济金融管理领域的应用现状汇总与前沿瞻望, 中青年学者不能不关注!21.前沿: 机器学习在金融和能源经济领域的应用分类总结,22.疫情期Wind资讯金融终端操作指南,23.疫情期间CSMAR数据库使用指南!金融财务管理必备数据库!24.金融领域三大中文数据库, CSMAR, CCER, Wind和CNRDS,25.Luigi Zingales: 金融有益于社会吗?26.经济金融领域第一位华人当选美国艺术与科学学院院士,27.时间序列数据分析的思维导图一览, 金融经济学者必备工具,28.研究创意的来源在哪里?顶级国际金融期刊主编如是说,29.金融人如何用好统计分析学, 金融视角下的统计分析,30.金融计量模型:误差修正模型(Error Correction Model,ECM)
推荐一份超级大礼包资源, 里面有丰富的Stata学习材料, 写文章作报告找工作的指南,①134篇各种方法的code, 代码和程序文章合集, 必须收藏!②今年最诚意的主流计量方法与Stata操作的视频教程, 一定要收藏学习!③《经济研究》期刊上所有文章按照"计量方法"进行分类汇总,有选择性地学习计量方法,④120篇DID双重差分方法的文章合集, 包括代码,程序及解读, 建议收藏!⑤Stata数据管理,绘图,检验,实证方法操作,结果输出的187篇文章!⑥CFPS 2020, CHFS 2019数据都公布了! 最新数据用起来做研究!
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
4年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
计量经济圈组织了一个计量社群,有如下特征:热情互助最多、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。








