ES 的集群模式和 kafka 很像,kafka 又和 redis 的集群模式很像。总之就是相互借鉴!
不管你用没用过 ES,今天我们一起聊聊它。就当扩展大家的知识广度了!
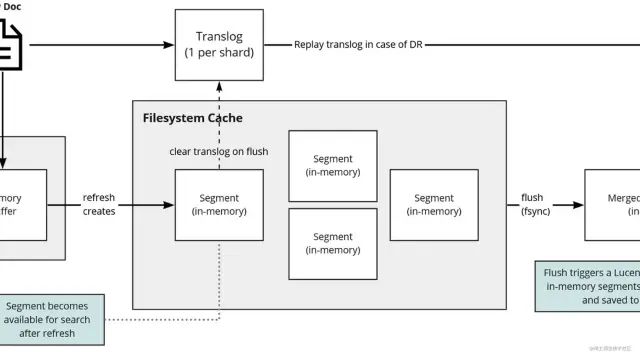
「正排索引 VS 倒排索引:」
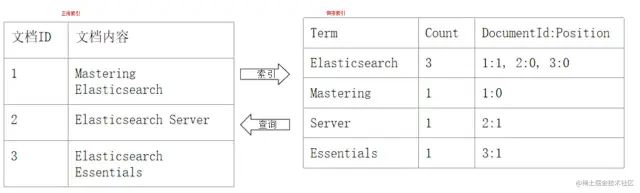
正排索引 VS 倒排索引「倒排索引包括两个部分:」
单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系
❝单词词典一般比较大,可以通过 B+ 树 或 哈希拉链法实现,以满足高性能的插入与查询
❞
-
倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项(Posting)组成:
- 词频
TF:该单词在文档中出现的次数,用于相关性评分 - 位置(
Position):单词在文档中分词的位置。用于语句搜索(Phrase Query) - 偏移(
Offset):记录单词的开始结束位置,实现高亮显示
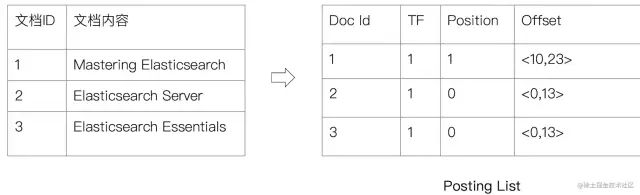
倒排索引「ElasticSearch 的倒排索引:」
ElasticSearch 的 JSON 文档中的每个字段,都有自己的倒排索引
「分片 shard:一个索引可以拆分成多个 shard 分片。」
- 主分片
primary shard:每个分片都有一个主分片。 - 备份分片
replica shard:主分片写入数据后,会将数据同步给其他备份分片。
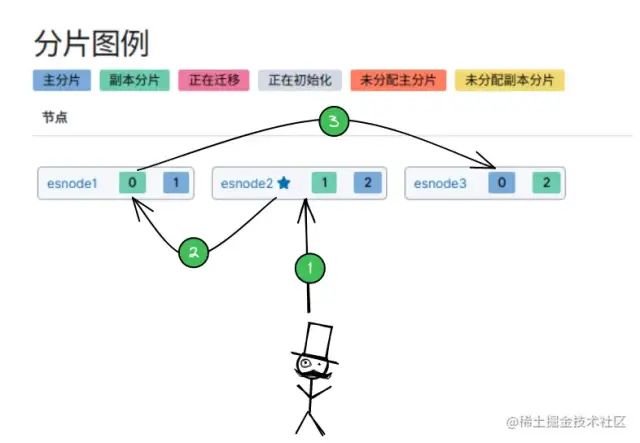
将 ES 集群部署在 3个 机器上(esnode1、esnode2、esnode3):
「创建个索引,分片为 3 个,副本数设置为 1:」
PUT /sku_index/_settings
{
"settings": {
"number_of_shards" : 3,
"number_of_replicas": 1
}
}
响应:
{
"acknowledged" : true
}

分布式架构原理「ES 集群中有多个节点,会自动选举一个节点为 master 节点,如上图的 esnode2节点:」
- 主节点(
master):管理工作,维护索引元数据、负责切换主分片和备份分片身份等。
「集群中某节点宕机:」
- 从节点宕机:由 主节点,将宕机节点上的 主分片身份转移到其他机器上的 备份分片上。
「写单个文档所需的步骤:」
客户端选择一个 Node 发送请求,那么这个 Node 就称为 「协调节点(Coorinating Node)」。
Node 使用文档 ID 来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片0 的主分片在 Node1 上,因此将请求转发到 Node1 上。
Node1 上的主分片执行写操作。如果写入成功,则将请求并行转发到 Node3 的副分片上,等待返回结果。
当所有的副分片都报告成功,Node1 将向 Node (协调节点)报告成功。
写入数据的工作原理「Tips:客户端收到成功响应时,意味着写操作已经在主分片和所有副分片都执行完成。」
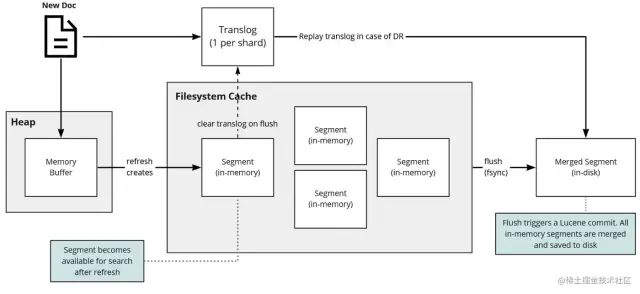
写数据底层原理「写操作可分为 3 个主要操作:」
**refresh 操作:**默认每隔 1s ,将内存中的文档写入文件系统缓存(filesystem cache)构成一个 segment
❝这时候搜索,可以搜索到数据。
❞
- 「
1s 时间:ES 是近实时搜索,即数据写入 1s后可以搜索到。」
**flush 操作:**默认每隔 30 分钟 或者 translog 文件 512MB ,将文件系统缓存中的 segment 写入磁盘,并将 translog 删除。
「translog 文件:」来记录两次 flush(fsync) 之间所有的操作,当机器从故障中恢复或者重启,可以根据此还原
-
translog 是文件,存在于内存中,如果掉电一样会丢失。
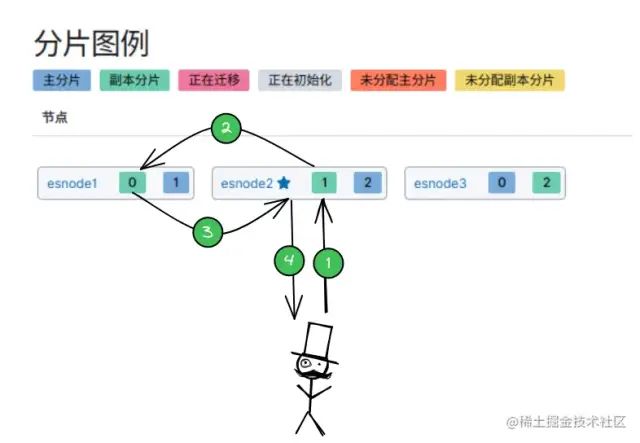
- 客户端选择一个
Node 发送请求,那么这个 Node 就称为 「协调节点(Coorinating Node)」。 Node 使用文档 ID 来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片0 有 2 个副本数据(一主一副),会使用随机轮询算法选择出一个分片,这里将请求转发到 Node1Node1 将文档返回给 Node,Node 将文档返回给客户端。
读取数据的工作原理「在读取时,文档可能已经存在于主分片上,但还没有复制到副分片,这种情况下:」
- 客户端选择一个
Node 发送请求,那么这个 Node 就称为 「协调节点(Coorinating Node)」。 Node 协调节点将搜索请求转发到所有的 分片(shard):主分片 或 副分片,都可以。- 「
query 阶段」:每个分片 shard 将自己的搜索结果(文档 ID)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - 「
fetch 阶段」:由协调节点根据 文档 ID 去各个节点上拉取实际的文档数据。
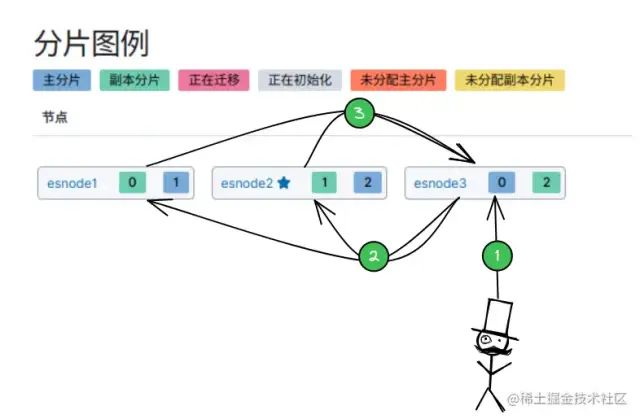
搜索工作原理**举个栗子:**有 3 个分片,查询返回前 10 个匹配度最高的文档- 「协调节点」 将
3 * 10 = 30 的结果再次排序,返回最终 TOP 10 的结果。
Index Buffer 每次 refresh 操作,就会产生一个 segment file。(默认情况:1秒1次)- 定制执行
merge 操作:将多个 segment file 合并成一个,同时将标识为 deleted 的 doc 「物理删除」,将新的 segment file 写入磁盘,最后打上 commit point 标识所有新的 segment file。
如喜欢本文,请点击右上角,把文章分享到朋友圈
如有想了解学习的技术点,请留言给若飞安排分享
因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享
·END·
相关阅读:
作者:格格步入
来源:juejin.cn/post/7110610301669605383
版权申明:内容来源网络,仅供分享学习,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
我们都是架构师!

关注架构师(JiaGouX),添加“星标”
获取每天技术干货,一起成为牛逼架构师
技术群请加若飞:1321113940 进架构师群
投稿、合作、版权等邮箱:admin@137x.com











