点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
北京时间2022年7月8日晚上22:30,鄂维南院士在2022年的国际数学家大会上作一小时大会报告(plenary talk)。今天我们带来鄂老师演讲内容的分享。鄂老师首先分享了他对机器学习数学本质的理解(函数逼近、概率分布的逼近与采样、Bellman方程的求解);然后介绍了机器学习模型的逼近误差、泛化性质以及训练等方面的数学理论;最后介绍如何利用机器学习来求解困难的科学计算和科学问题,即AI for science。文章作者Hertz。

众所周知,机器学习的发展,已经彻底改变了人们对人工智能的认识。机器学习有很多令人叹为观止的成就,例如:
· 比人类更准确地识别图片:利用一组有标记的图片,机器学习算法可以准确地识别图片的类别:

Cifar-10 问题:把图片分成十个类别
来源:https://www.cs.toronto.edu/~kriz/cifar.html
· Alphago下围棋打败人类:完全由机器学习实现下围棋的算法:
参考:https://www.bbc.com/news/technology-35761246
参考:https://arxiv.org/pdf/1710.10196v3.pdf
机器学习还有很多其他的应用。在日常生活中,人们甚至常常使用了机器学习所提供的服务而不自知,例如:我们的邮件系统里的垃圾邮件过滤、我们的车和手机里的语音识别、我们手机里的指纹解锁……
所有这些了不起的成就,本质上,却是成功求解了一些经典的数学问题。
对于图像分类问题,我们感兴趣的其实是函数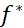 :
:
: 图像→类别
一般而言,监督学习(supervised learning)问题,本质都是想基于一个有限的训练集S,给出目标函数的一个高效逼近。
对于人脸生成问题,其本质是逼近并采样一个未知的概率分布。在这一问题中,“人脸”是随机变量,而我们不知道它的概率分布。然而,我们有“人脸”的样本:数量巨大的人脸照片。我们便利用这些样本,近似得到“人脸”的概率分布,并由此产生新的样本(即生成人脸)。
一般而言,无监督学习本质就是利用有限样本,逼近并采样问题背后未知的概率分布。
对于下围棋的Alphago来说,如果给定了对手的策略,围棋的动力学是一个动态规划问题的解。其最优策略满足Bellman方程。因而Alphago的本质便是求解Bellman方程。
一般而言,强化学习本质上就是求解马尔可夫过程的最优策略。
然而,这些问题都是计算数学领域的经典问题!!毕竟,函数逼近、概率分布的逼近与采样,以及微分方程和差分方程的数值求解,都是计算数学领域极其经典的问题。那么,这些问题在机器学习的语境下,到底和在经典的计算数学里有什么区别呢?答案便是:
维度灾难(curse of dimensionality)
所有的经典算法,例如多项式逼近、小波逼近,都饱受维度灾难之害。很明显,机器学习的成功告诉我们,在高维问题中,深度神经网络的表现比经典算法好很多。然而,这种“成功”是怎么做到的呢?为什么在高维问题中,其他方法都不行,但深度神经网络取得了前所未有的成功呢?
从数学出发,理解机器学习的“黑魔法”:监督学习的数学理论
· 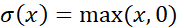 ,ReLU函数;·
,ReLU函数;· 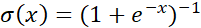 ,Sigmoid函数。而神经网络的基本组成部分即为:线性变换与一维非线性变换。深度神经网络,一般就是如下结构的复合:
,Sigmoid函数。而神经网络的基本组成部分即为:线性变换与一维非线性变换。深度神经网络,一般就是如下结构的复合:
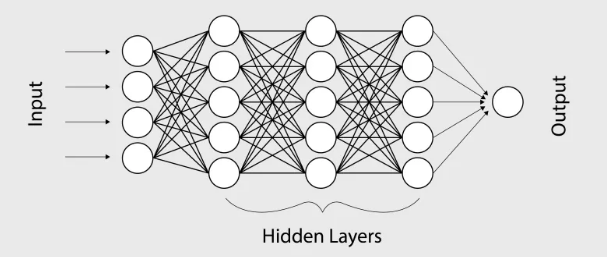
我们将要在训练集S上逼近目标函数
第一步:选取一个假设空间(测试函数的一个集合) (m正比于测试空间的维数);
(m正比于测试空间的维数);
第二步:选取一个损失函数进行优化。通常,我们会选择经验误差(empirical risk)来拟合数据:

如果把机器学习输出的结果记 ,那么总误差便是
,那么总误差便是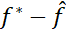 。我们再定义:
。我们再定义:
 是在假设空间里最好的逼近;
是在假设空间里最好的逼近;
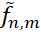 是在假设空间里,基于数据集S最好的逼近。
是在假设空间里,基于数据集S最好的逼近。
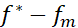 是逼近误差(approximation error):完全由假设空间的选取所决定;
是逼近误差(approximation error):完全由假设空间的选取所决定;
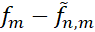 是估计误差(estimation error):由于数据集大小有限而带来的额外的误差;
是估计误差(estimation error):由于数据集大小有限而带来的额外的误差;
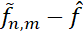 是优化误差(optimization error):由训练(优化)带来的额外的误差。
是优化误差(optimization error):由训练(优化)带来的额外的误差。
我们下面集中讨论逼近误差(approximation error)。
其误差便是正比于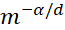 ,毫无疑问地受到维度灾难的影响。令
,毫无疑问地受到维度灾难的影响。令
 是测度
是测度 的独立同分布样本,我们有:如果让激活函数为
的独立同分布样本,我们有:如果让激活函数为 ,那么
,那么 就是以
就是以 为激活函数的两层神经网络。此结果意味着:这一类(可以表示成期望)的函数,都可以由两层神经网络逼近,且逼近误差的速率与维数无关!对于一般的双层神经网络,我们可以得到一系列类似的逼近结果。其中关键的问题是:到底什么样的函数可以被双层神经网络逼近?为此,我们引入Barron空间的定义:
参考:E, Chao Ma, Lei Wu (2019)对于任意的Barron函数,存在一个两层神经网络
为激活函数的两层神经网络。此结果意味着:这一类(可以表示成期望)的函数,都可以由两层神经网络逼近,且逼近误差的速率与维数无关!对于一般的双层神经网络,我们可以得到一系列类似的逼近结果。其中关键的问题是:到底什么样的函数可以被双层神经网络逼近?为此,我们引入Barron空间的定义:
参考:E, Chao Ma, Lei Wu (2019)对于任意的Barron函数,存在一个两层神经网络 ,其逼近误差满足:可以看到这一逼近误差与维数无关!(关于这部分理论的细节,可以参考:E, Ma and Wu (2018, 2019), E and Wojtowytsch (2020)。其他的关于Barron space的分类理论,可以参考Kurkova (2001), Bach (2017),类似的理论可以推广到残差神经网络(residual neural network)。在残差神经网络中,我们可以用流-诱导函数空间(flow-induced function space)替代Barron空间。人们一般会期待,训练误差与测试误差的差别会正比于
,其逼近误差满足:可以看到这一逼近误差与维数无关!(关于这部分理论的细节,可以参考:E, Ma and Wu (2018, 2019), E and Wojtowytsch (2020)。其他的关于Barron space的分类理论,可以参考Kurkova (2001), Bach (2017),类似的理论可以推广到残差神经网络(residual neural network)。在残差神经网络中,我们可以用流-诱导函数空间(flow-induced function space)替代Barron空间。人们一般会期待,训练误差与测试误差的差别会正比于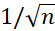 (n是样本数量)。然而,我们训练好的机器学习模型和训练数据是强相关的,这导致这样子的Monte-Carlo速率不一定成立。为此,我们给出了如下的泛化性理论:简言之,我们用Rademacher复杂度来刻画一个空间在数据集上拟合随机噪声的能力。Rademacher复杂度的定义为:其中
(n是样本数量)。然而,我们训练好的机器学习模型和训练数据是强相关的,这导致这样子的Monte-Carlo速率不一定成立。为此,我们给出了如下的泛化性理论:简言之,我们用Rademacher复杂度来刻画一个空间在数据集上拟合随机噪声的能力。Rademacher复杂度的定义为:其中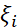 是取值为1或-1的独立同分布的随机变量。当
是取值为1或-1的独立同分布的随机变量。当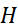 是李朴西斯空间中的单位球时,其Rademacher复杂度正比于
是李朴西斯空间中的单位球时,其Rademacher复杂度正比于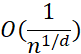 。当d增加时,可以看到拟合需要的样本大小指数上升。这其实是另一种形式的维度灾难。对于第一个问题,答案恐怕是悲观的。Shamir(2018)中的引理告诉我们,基于梯度的训练方法,其收敛速率也受维度灾难的影响。而前文提到的Barron space,虽然是建立逼近理论的好手段,但对于理解神经网络的训练却是一个过大的空间。特别地,这样子的负面结果可以在高度超参数(highly over-parameterized regime)的情形(即m>>n)下得到具体刻画。在此情形下,参数的动力学出现了尺度分离的现象:对于如下的两层神经网络:在训练过程中,
。当d增加时,可以看到拟合需要的样本大小指数上升。这其实是另一种形式的维度灾难。对于第一个问题,答案恐怕是悲观的。Shamir(2018)中的引理告诉我们,基于梯度的训练方法,其收敛速率也受维度灾难的影响。而前文提到的Barron space,虽然是建立逼近理论的好手段,但对于理解神经网络的训练却是一个过大的空间。特别地,这样子的负面结果可以在高度超参数(highly over-parameterized regime)的情形(即m>>n)下得到具体刻画。在此情形下,参数的动力学出现了尺度分离的现象:对于如下的两层神经网络:在训练过程中,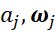 的动力学分别为:由此可以看到尺度分离的现象:当m很大的时候,
的动力学分别为:由此可以看到尺度分离的现象:当m很大的时候,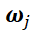 的动力学几乎被冻结住。这种情形下,好消息是我们有了指数收敛(Du et al, 2018);坏消息却是这时候,神经网络表现得并不比从random feature model模型好。我们也可以从平均场的角度理解梯度下降方法。令:
的动力学几乎被冻结住。这种情形下,好消息是我们有了指数收敛(Du et al, 2018);坏消息却是这时候,神经网络表现得并不比从random feature model模型好。我们也可以从平均场的角度理解梯度下降方法。令: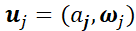 ,并令:
则
,并令:
则 是下列梯度下降问题的解:当且仅当
是下列梯度下降问题的解:当且仅当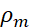 是下面方程的解(参考:Chizat and Bach (2018), Mei, Montanari and Nguyen (2018), Rotsko and Vanden-Eijnden (2018), Sirignano and Spiliopoulos (2018)):这一平均场动力学,实际上是在Wassenstein度量意义下的梯度动力学。人们证明了:如果其初始值
是下面方程的解(参考:Chizat and Bach (2018), Mei, Montanari and Nguyen (2018), Rotsko and Vanden-Eijnden (2018), Sirignano and Spiliopoulos (2018)):这一平均场动力学,实际上是在Wassenstein度量意义下的梯度动力学。人们证明了:如果其初始值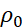 的支集为全空间,且梯度下降的确收敛,那么其收敛结果必然是全局最优(参考:Chizat and Bach (2018,2020), Wojtowytsch (2020))。既然机器学习是处理高维问题的有效工具,我们便可运用机器学习解决传统计算数学方法难以处理的问题。第一个例子便是随机控制问题。传统方法求解随机控制问题需要求解一个极其高维的Bellman方程。运用机器学习方法,可以有效求解随机控制问题。其思路与残差神经网络颇为类似(参考Jiequn Han and E (2016)):第二个例子便是求解非线性抛物方程。非线性抛物方程可以被改写成一个随机控制问题,其极小点是唯一的,对应着非线性抛物方程的解。利用机器学习处理高维问题的能力,我们可以解决更多科学上的难题。这里我们举两个例子。第一个例子是Alphafold。参考:J. Jumper et al. (2021)第二个例子,便是我们自己的工作:深度势能分子动力学(DeePMD)。这是能达到从头计算精度的分子动力学。我们所使用的新的模拟“范式”便是:
的支集为全空间,且梯度下降的确收敛,那么其收敛结果必然是全局最优(参考:Chizat and Bach (2018,2020), Wojtowytsch (2020))。既然机器学习是处理高维问题的有效工具,我们便可运用机器学习解决传统计算数学方法难以处理的问题。第一个例子便是随机控制问题。传统方法求解随机控制问题需要求解一个极其高维的Bellman方程。运用机器学习方法,可以有效求解随机控制问题。其思路与残差神经网络颇为类似(参考Jiequn Han and E (2016)):第二个例子便是求解非线性抛物方程。非线性抛物方程可以被改写成一个随机控制问题,其极小点是唯一的,对应着非线性抛物方程的解。利用机器学习处理高维问题的能力,我们可以解决更多科学上的难题。这里我们举两个例子。第一个例子是Alphafold。参考:J. Jumper et al. (2021)第二个例子,便是我们自己的工作:深度势能分子动力学(DeePMD)。这是能达到从头计算精度的分子动力学。我们所使用的新的模拟“范式”便是:利用神经网络,给出势能面准确的拟合(参考:Behler and Parrinello (2007), Jiequn Han et al (2017), Linfeng Zhang et al (2018))。
运用DeePMD,我们能够模拟一系列材料和分子,可以达到第一性层面的计算精度:我们还实现了一亿原子的第一性原理精度的模拟
,获得了2020年的戈登贝尔奖:参考:Weile Jia, et al, SC20, 2020 ACM Gordon Bell Prize参考:Linfeng Zhang, Han Wang, et al. (2021)而事实上,物理建模横跨多个尺度:宏观、介观、微观,而机器学习恰好提供了跨尺度建模的工具。AI for science,即用机器学习解决科学问题,已经有了一系列重要的突破,如:
量子多体问题:RBM (2017), DeePWF (2018), FermiNet (2019),PauliNet (2019),…;
密度泛函理论: DeePKS (2020), NeuralXC (2020), DM21 (2021), …;
分子动力学: DeePMD (2018), DeePCG (2019), …;
动理学方程: 机器学习矩封闭 (Han et al. 2019);
连续介质动力学: 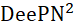 (2020)
(2020)
在未来五到十年,我们有可能做到:跨越所有物理尺度进行建模和计算。这将彻底改变我们如何解决现实问题:如药物设计、材料、燃烧发动机、催化……
机器学习根本上是高维中的数学问题。神经网络是高维函数逼近的有效手段;这便为人工智能领域、科学以及技术领域提供了众多新的可能性。这也开创了数学领域的一个新主题:高维的分析学。简而言之,可以总结如下:
北京科学智能研究院(AI for Science Institute, 以下简称AISI)成立于2021年9月,由鄂维南院士领衔,致力于将人工智能技术与科学研究相结合,加速不同科学领域的发展和突破,推动科学研究范式的革新,建设引领世界的「AI for Science」基础设施体系。
AISI的研究人员来自国内外顶尖高校、科研机构和科技企业,共同聚焦物理建模、数值算法、人工智能、高性能计算等交叉领域的核心问题。
AISI致力于创造思想碰撞的学术环境,鼓励自由探索和跨界合作,共同探索人工智能与科学研究结合的新可能。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:
扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~












