Abstract
做完了感知机(并没有完全做完,感知机的实现不是只有我们的这一种,并且我们的感知机并没有一个很好的优化),下一步我们尝试着搭建一个神经网络吧
Introdution
思考一下我们的感知机是否存在一个非常严重的问题,线性可分是感知机运行的大前提,如果一个数据集是非线性可分的,那么我们在优化损失函数的时候就会出现死循环,感知机怎么都做不到找到这条可以分割数据的直线,这就是常说的XOR问题,即感知机解决不了异或函数,图示如下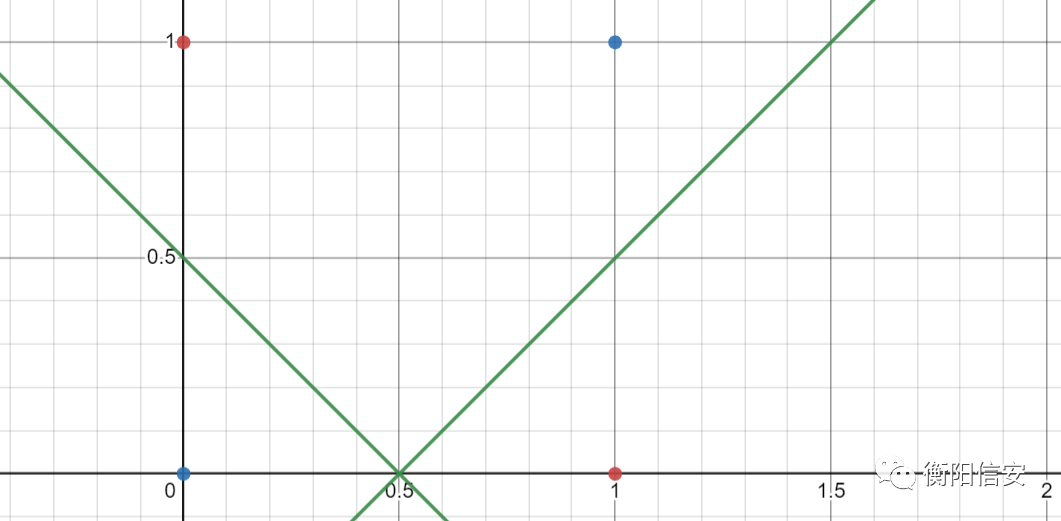
红色和蓝色的点,我们找不到一条合适的直线进行分割,这个就是异或问题,因为蓝色为异或结果为0的,红色为异或结果为1的
要想解决这个问题,就需要多个感知机配合,也就是所谓的神经网络,我们思考一下,既然XOR是非线性可分的,那么我们这么算(下面都是位运算)
H11=A×B
H12=A+B
下面是这两个的真值表
|
|
|
|
|
|---|
| A | 0 | 1 | 0 | 1 |
| B | 0 | 0 | 1 | 1 |
| H11 | 0 | 0 | 0 | 1 |
| H12 | 0 | 1 | 1 | 1 |
| !H12 | 1 | 0 | 0 | 0 |
接着我们顺着这个真值表深入,来处理异或情况,是不是异或就等价于
XOR(A,B)=!(!H12+H11)
像这样,我们就使用两个感知机实现了非线性分类的情况,这个其实就是神经网络,通过多个感知机实现的神经网络
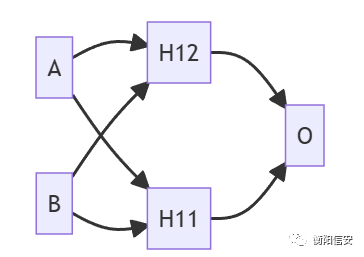
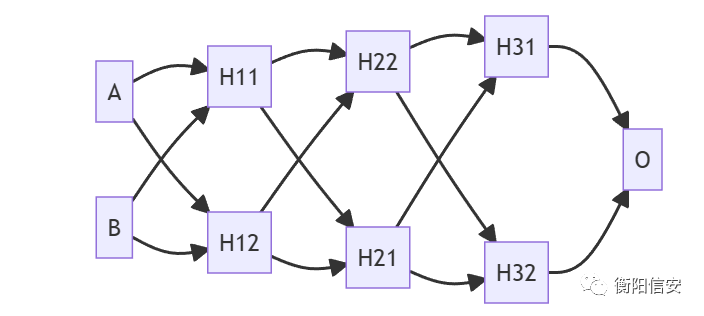
其中H12 H11都是感知机,都有对应的W和b,这个昨天讲过了,而事实上O也是一个感知机,它接受来自H12 H11的数据,然后对他们进行分类,不过往往神经网络长这样子(就是很多层,每一层都影响着它前面几层)
Mathematics Infer Of Function Fitting
了解完了神经网络是个什么玩意,接下来我们开始推导神经网络的实现,在上面的神经网络里,每一个神经元都是一个感知机,那么就意味着有多少层神经元就需要多少个W\b对(假设同一层感知机所使用的W\b是一样的),所以我们这次面临的是大量的W\b训练
现在考虑一个两层的神经网络
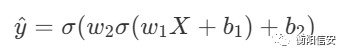
在得到 yhat以后,我们要思考,这个yhat和我们的训练集的联系,即计算损失函数
现在回忆一下每个感知机的输出,由于我们做了一点骚操作,即令sign函数为一个若输入小于0就输出-1,否则+1的函数,所以做到了数据的分类,就使用1和-1判断,现在我们更换sign函数为sigmoid函数
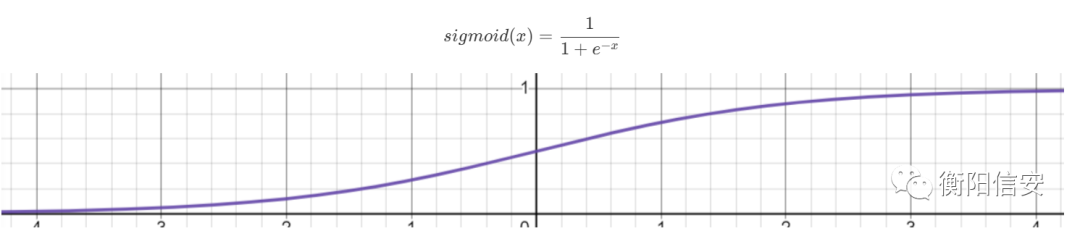
目的很简单,现在我们不再想让每个感知机就输出个离散的数据,而是希望它输出一个连续函数上的值,这样方便我们后续的计算,先不展开,后面会理解的
ok,我们将分类问题转化到函数拟合问题上来,分类问题是简单得使用一个函数去分割数据,使用多个感知机可以做到非线性的分割,那本质上不就是在拟合一条曲线来满足条件吗?而最终输出的结果,通过sigmoid函数,我们可以把其转化为一个值,计算损失函数就可以很方便了,如下
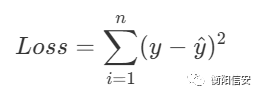
我们可以用这个来表达损失函数,然后目标就是令Loss最小,即对Loss求对W和b的偏导,但是请注意,我们这里的x是相对于一层神经元的前一次神经元的输出
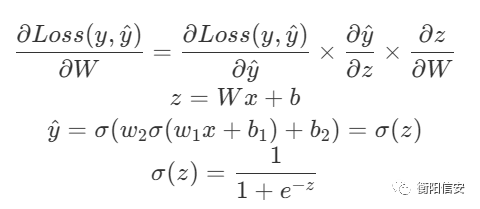
通过上面的表达式,我们计算这个偏导的实际值
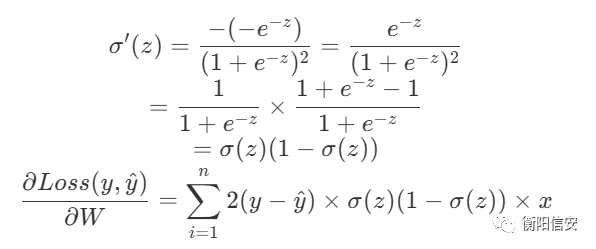
ok,现在,我们得到了这一层的结果,然后我们做一个共识:将W和b看做是同一个系数,即我们之前说的数学家喜欢偷懒,我们也偷个懒
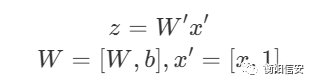
这样,我们就把W和b结合到一起去了,接下来我们看Loss函数,在最后一层,它受哪几个参数的影响?是不是它需要接收来自上一层的输出作为这一层的输入,然后在本层计算出结果,那也就是说,这一层的结果还受到上一层的影响,那么如果我们想要最好的结果,还需要调整上一层,那么理所当然地,我们会思考这个式子(使用x表示上一层的输入
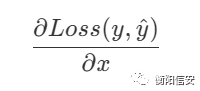
但是我们做得到调整x吗?我们做不到,但是我们可以调整上一层,通过调整上一层的W,就可以调整上一层的输出这一层的输入x,我们记为上一层的W为W',求这一层的Loss函数对上一层W的偏导,用一张图来描述它吧,干文字还是不好看
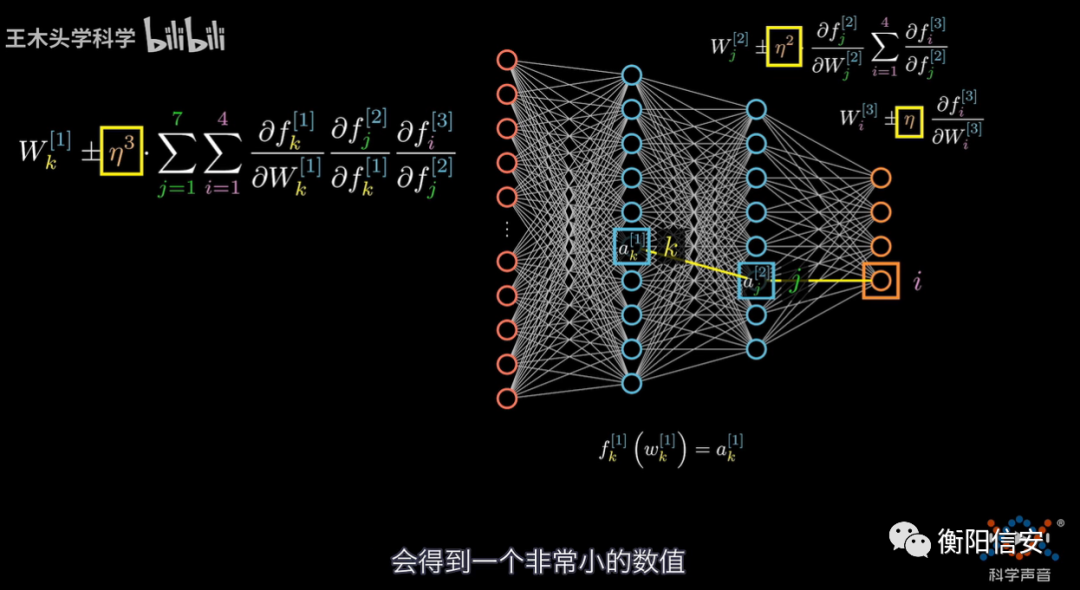
橙色的是输出层,我们可以很清晰得看到,输出层受到蓝色的那一层的影响,然后蓝色的那一层又受到更前面那一层的影响
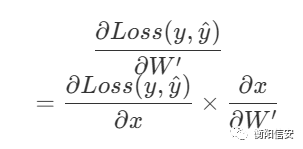
然后如果还有更多层,那就继续往前传
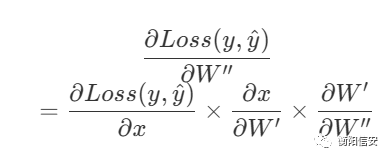
这个过程其实就是链式求导法则,今天的内容就比较少了就只有这些,之后有时间我们就实现一下
Reference
https://towardsdatascience.com/how-to-build-your-own-neural-network-from-scratch-in-python-68998a08e4f6
https://www.bilibili.com/video/BV1FP411j7oW
来自团队学习笔记


\sigma'(z) = \frac{-(-e^{-z})}{(1+e^{-z})^2} = \frac{e^{-z}}{(1+e^{-z})^2}\\ = \frac{1}{1+e^{-z}} \times \frac{1+e^{-z}-1}{1+e^{-z}} \\ = \sigma(z)(1-\sigma(z)) \\ \frac{\partial Loss(y, \hat{y})}{\partial W} = \sum_{i=1}^{n}2(y-\hat{y})\times \sigma(z)(1-\sigma(z)) \timex










