易侕软件新增全自动机器学习预测模块,可根据结果变量类型自动选择各种适用的算法,包括深度学习-全连接神经网络、随机森林包括分布式随机森林和极度随机树、梯度提升机、广义线性模型等。deeplearning (fully connected deep neural network), random forest 包括 DRF (distributed random forest) 和 XRT (extremely random trees), GBM (gradient boosting machine), GLM (generalized linear model)。
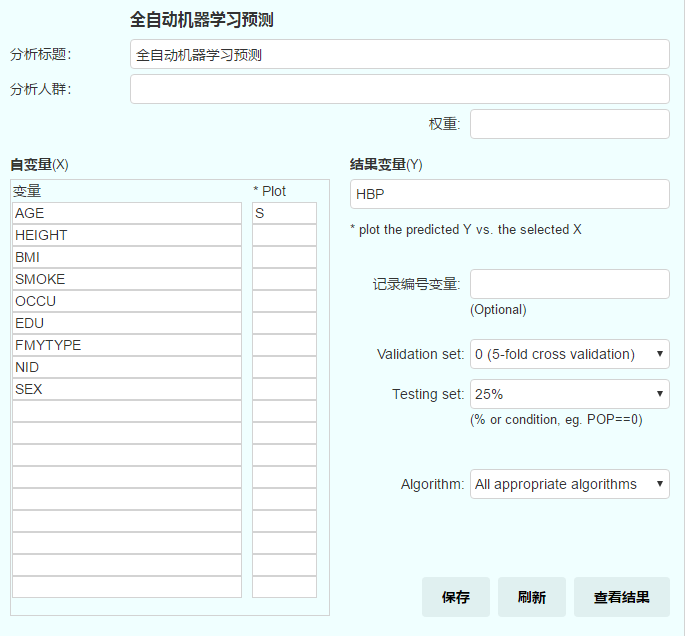
极简的操作设置界面,给出XY:
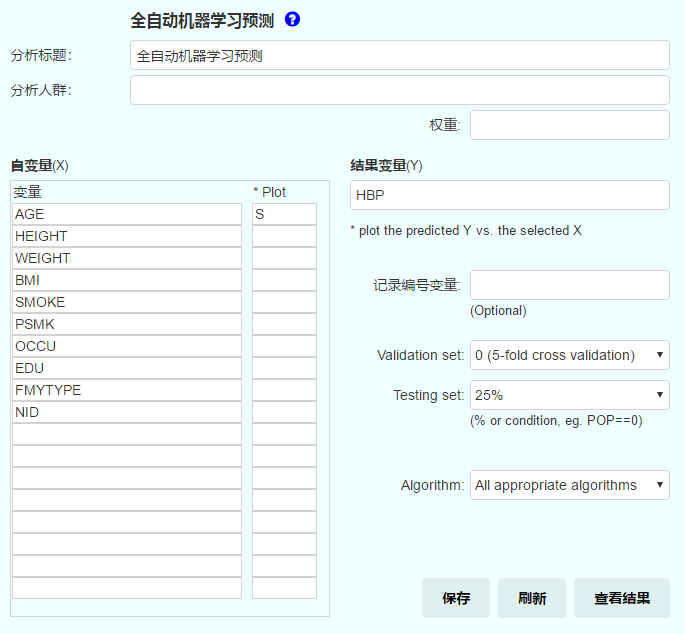
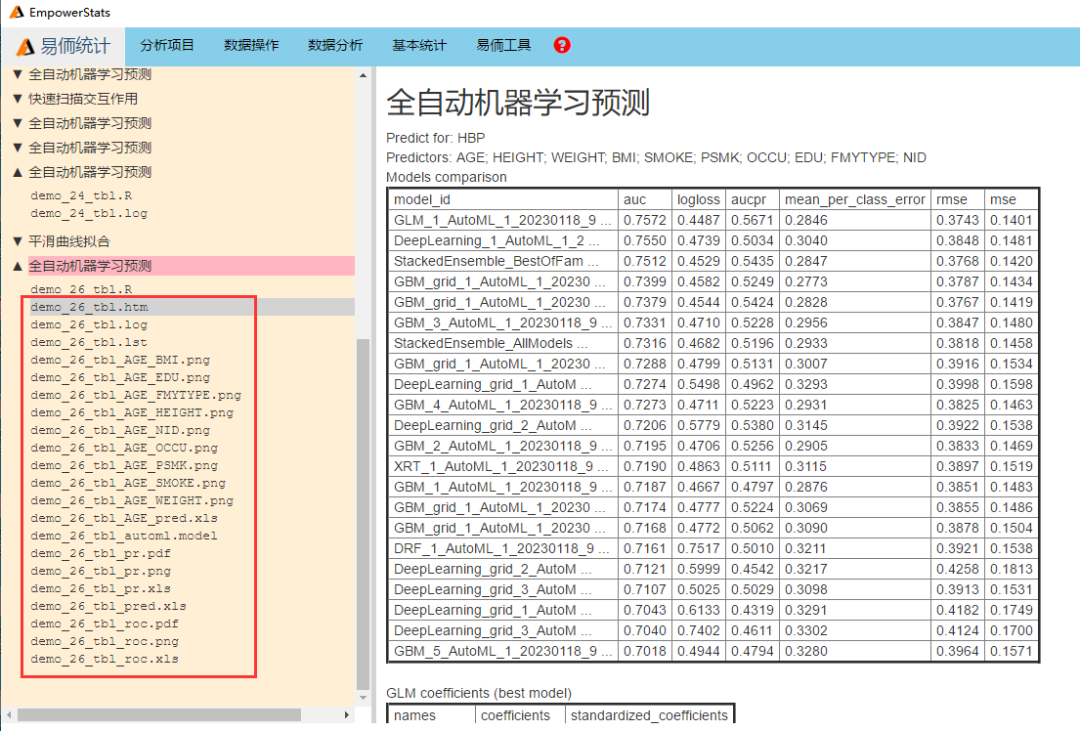
查看结果得出批量图表结果:
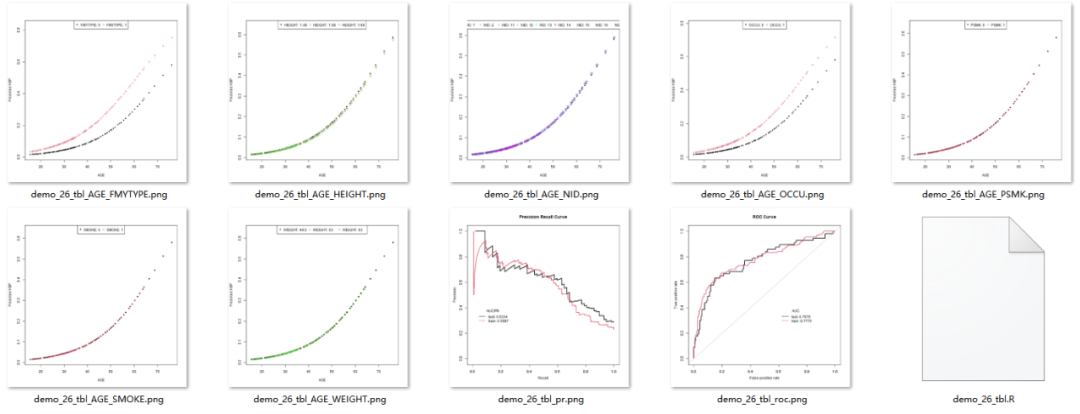
(部分截图)
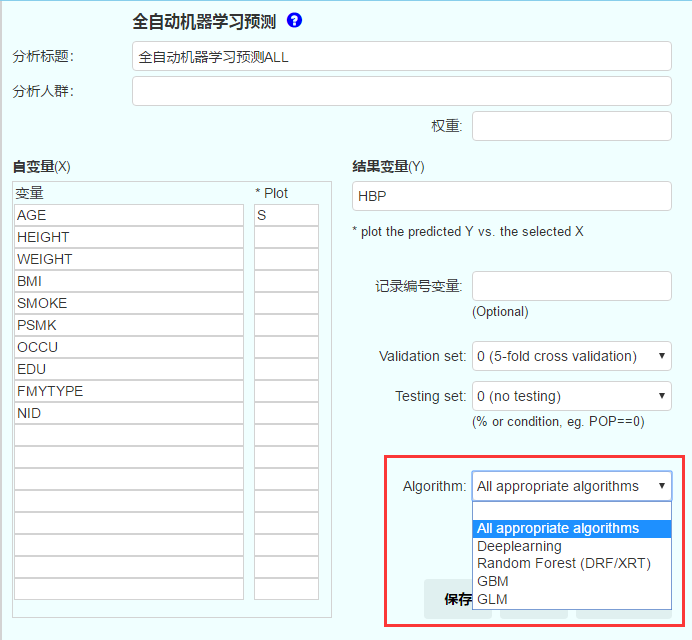
可以在模型选择这里选择所有合适的算法(all appropriate algorithms),或者单选某个模型。如果选所有合适的算法,则自动输出模型比较的ROC曲线(当Y是二分类时):
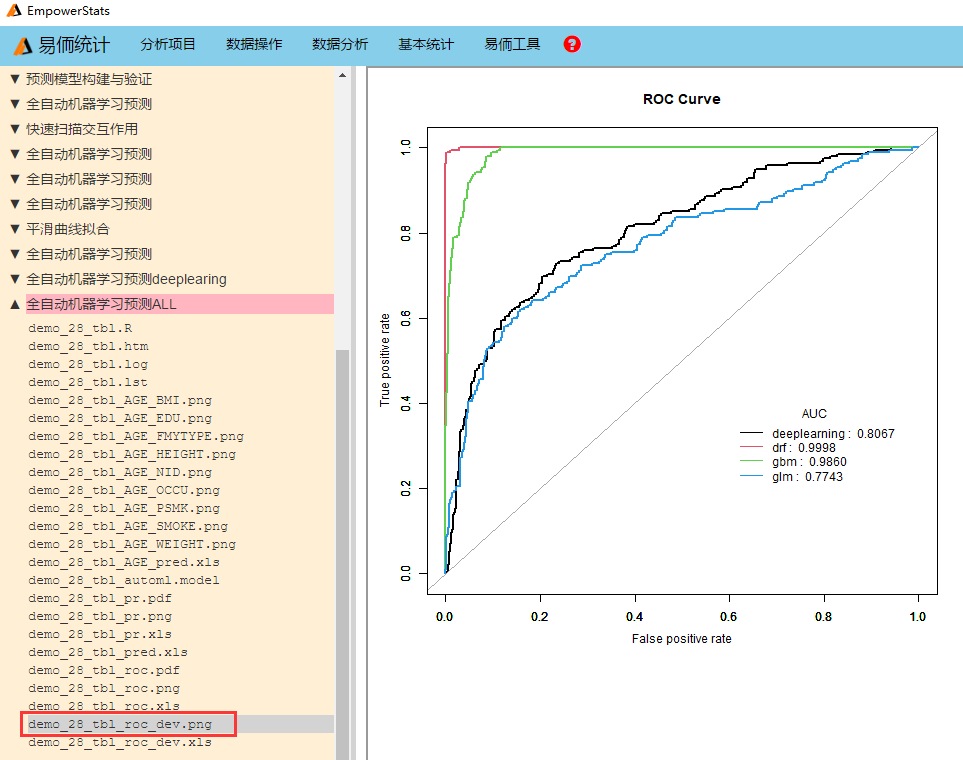
本模块使用R package h2o automl (Automate Machine Learning) 功能。
1 使用要求
1. 结果变量为两分类(编码成0/1)或多分类或连续性。
2. 自变量可以是两分类或多分类变量或连续性变量。输入变量要求是数字型变量,如为字符型需重新编码成数字(可用易侕的分类变量取值重组功能)。
2 主要参数设置
内部验证集(validation set):validation 的目的是防止过度拟合。可以:
1. 采用5分组内部交叉验证(默认选项 0)
2. 或随机分出一组做验证集,选择或输入百分数,如25%,15%。手动输入可只输入数字(不带“%”号,如20)。
3. 或定义一组作为验证集,如手动输入 POP = 1。(输入 POP==1 与 POP=1 效果相同)。
模型检验集 (testing set):testing 的目的是对模型进行外部检验。可以:
1. 随机分出一组做验证集,选择或输入百分数,如25%,15%。手动输入可只输入数字(不带“%”号,如20)。
2. 或定义一组作为验证集,如手动输入 POP = 2。(输入 POP==2 与 POP=2 效果相同)。
算法选择(algorithms):默认根据结果变量类型选择各种适用的算法,也可以选择如 deeplearning (fully connected deep neural network), random forest 包括 DRF (distributed random forest) 和 XRT (extremely random trees), GBM (gradient boosting machine), GLM (generalized linear model)
3 模型自动比较与选择标准
对两分类的结果变量,比较 "AUC", "AUCPR", "logloss", "mean_per_class_error", "RMSE", "MSE"。默认最大 AUC 模型被选为最佳模型。
对连续性结果变量,比较 "mean_residual_deviance", "RMSE", "MSE", "MAE", and "RMSLE"。默认最小 mean_residual_deviance 模型被选为最佳模型。
对多分类结果变量,比较 "mean_per_class_error", "logloss", "RMSE", "MSE"。默认最小 mean_per_class_error 模型被选为最佳模型。
4 输出结果
Automated machine learning 自动运行多个模型,如选择各种适用的算法,运行20个模型,如选择单项算法,运行10个模型,通过模型比较自动选出最佳模型。然后对选出的最佳模型的模型表现与预测结果进行分析,输出结果包括:
Models comparison :下面的结果都是建立在自动选出的最佳模型上:
Model performance
Prediction performance
结果变量如为0/1编码的两分类变量,输出 ROC,Precision Recall 图及其数据文件;如为连续性变量,输出 EGA (Exploratory Graph Analysis) 图及其数据文件。
对连续性的自变量,如在 * Plot 列输入“S”,表示选择该变量,将绘制该变量(S)与结果变量预测值的关系曲线图,所有其它变量将作为分组变量(如为分类变量按原分类分组,如为连续性变量将取值 10%,50%,90% 百分位数分成低、中、高三组)分别绘制S与Y的曲线图,以便观察其与S的交互作用。
详见易典通帮助文件
http://www.empowerstats.net/article?aid=9401
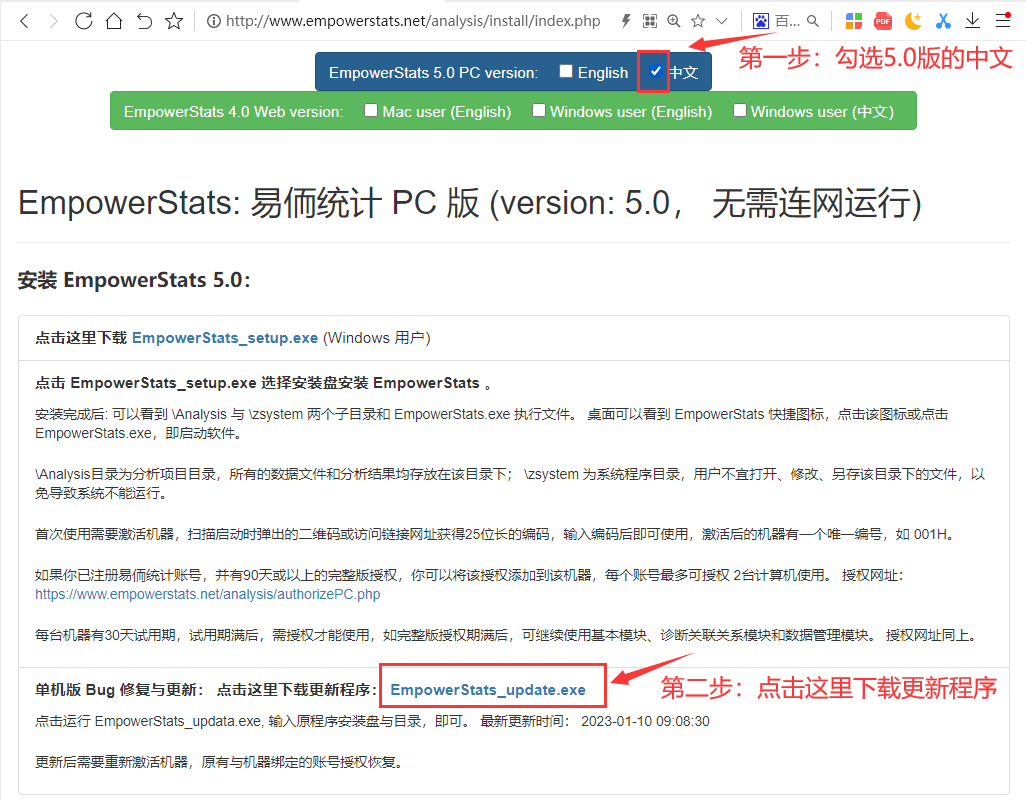
5.0单机版和4.1版可以操作本模块,需要更新软件,操作如下:
第一步:下载更新程序,登录
http://www.empowerstats.net/cn/download.html

(或在官网下载界面点击“易侕统计4.1版”也可以跳转到上述页面)
第二步,安装完更新包后操作软件自带的demo数据,点击数据分析-诊断试验与预测方程-全自动机器学习预测模:
如果首次操作出现如下图报错提示,首先确认本机是64位机器,然后按错误提示,重新安装Java:
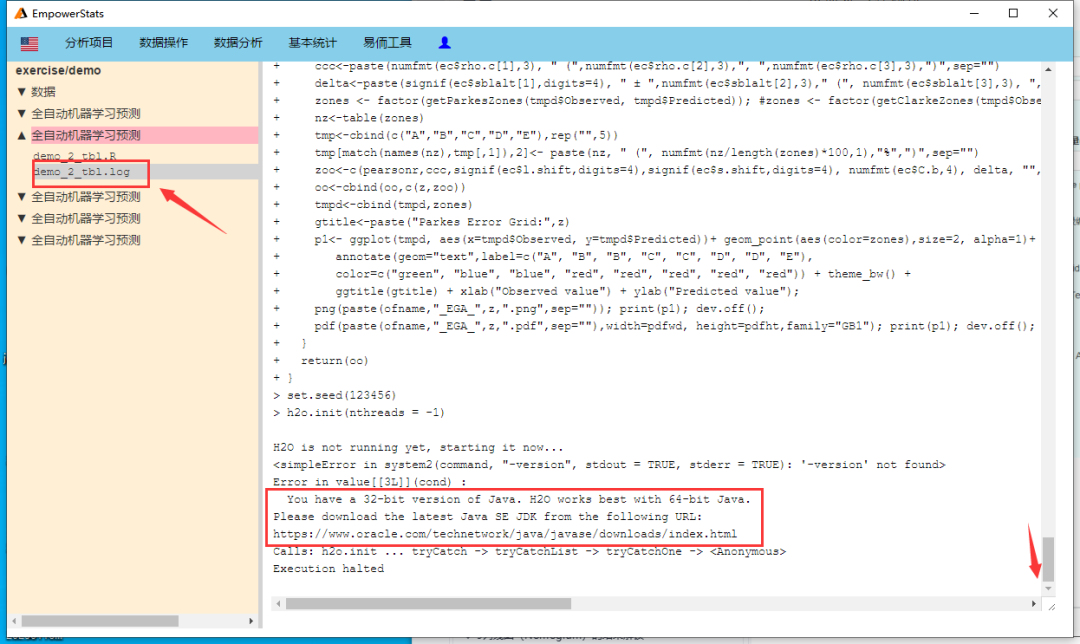
上图红框中下载Java的网址为
https://www.oracle.com/technetwork/java/javase/downloads/index.html
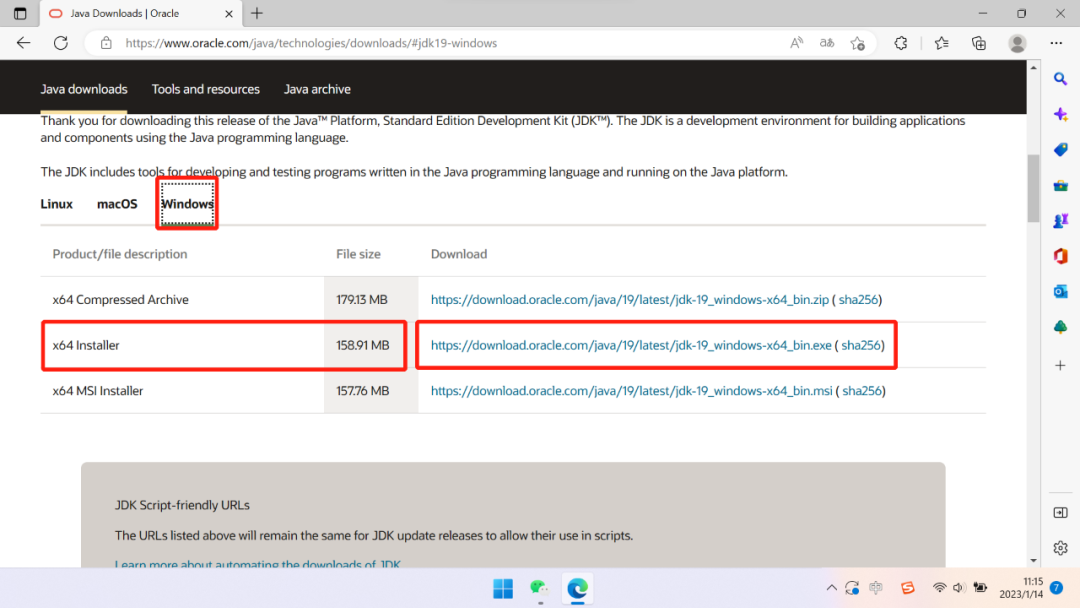
选择适合本机的安装程序,如下图所示:
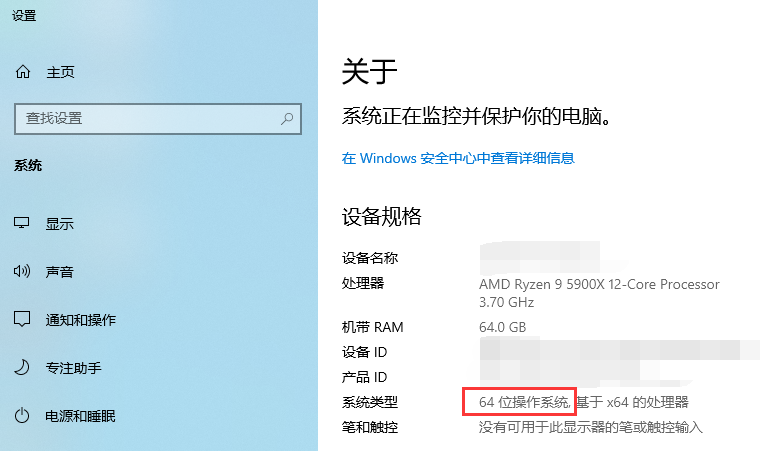
例如,在“我的电脑”点右键-属性-系统类型可以查看到是64位操作系统:
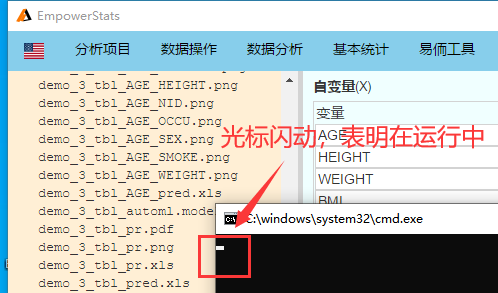
安装完Java后重新运行,通常要运行10分钟以上,黑框左上角光标闪动表明仍在运行。如果有的电脑等待20分钟左右黑框没有自行关闭,可以手动关闭黑框,即可查看结果。
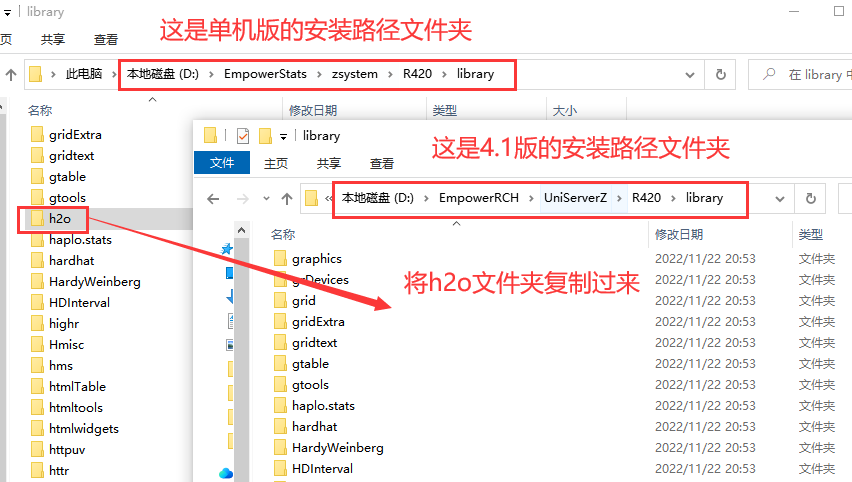
可以从单机版上复制 zsystem/R420/library/h2o 目录到4.1版的 uniserverz/R420/library 下。
如果本机没有安装单机版,也可以在百度网盘下载h2o文件到本机解压缩后放在相应路径文件夹,下载地址:
https://pan.baidu.com/s/1MimcD_hoM0p0Bxww61mTCg
提取码:ilxk
操作设置同上,如果有的电脑等待20分钟左右黑框没有自行关闭,可以手动关闭黑框,即可查看结果。











