点赞相信大家都不陌生,在B站,点赞是UP主们跟粉丝之间的特殊羁绊。B 站的点赞系统提供了对视频、动态、专栏、评论、弹幕等多种实体维度的点赞、点踩以及其余配套的数据查询的能力。
业务能力:
以 “稿件” 为例,点赞服务需要提供:
平台能力:
点赞作为一个与社区实体共存的服务,中台化、平台化也是点赞服务需要具备的能力
容灾能力:
作为被用户强感知的站内功能,需要考虑到各种情况下的系统容灾。例如当:
当然还有其他比如下游依赖宕机、点赞消息堆积以及其他未知问题。
(1)流量压力
全局流量压力:
全站点赞状态查询、点赞数查询等【读流量】超过300k,点赞、点踩等【写流量】超过15K
单点流量(热点)压力:
热门事件、稿件等带来的系统热点问题,包括DB热点、缓存热点
(2)数据存储压力
(3)面对未知灾难
针对前言中提到的点赞的平台能力、系统压力与容灾,我会在下文中作出更加详细的介绍。
为了在提供上述能力的前提下经受住流量、存储、容灾三大压力,点赞目前的系统实现方式如下:
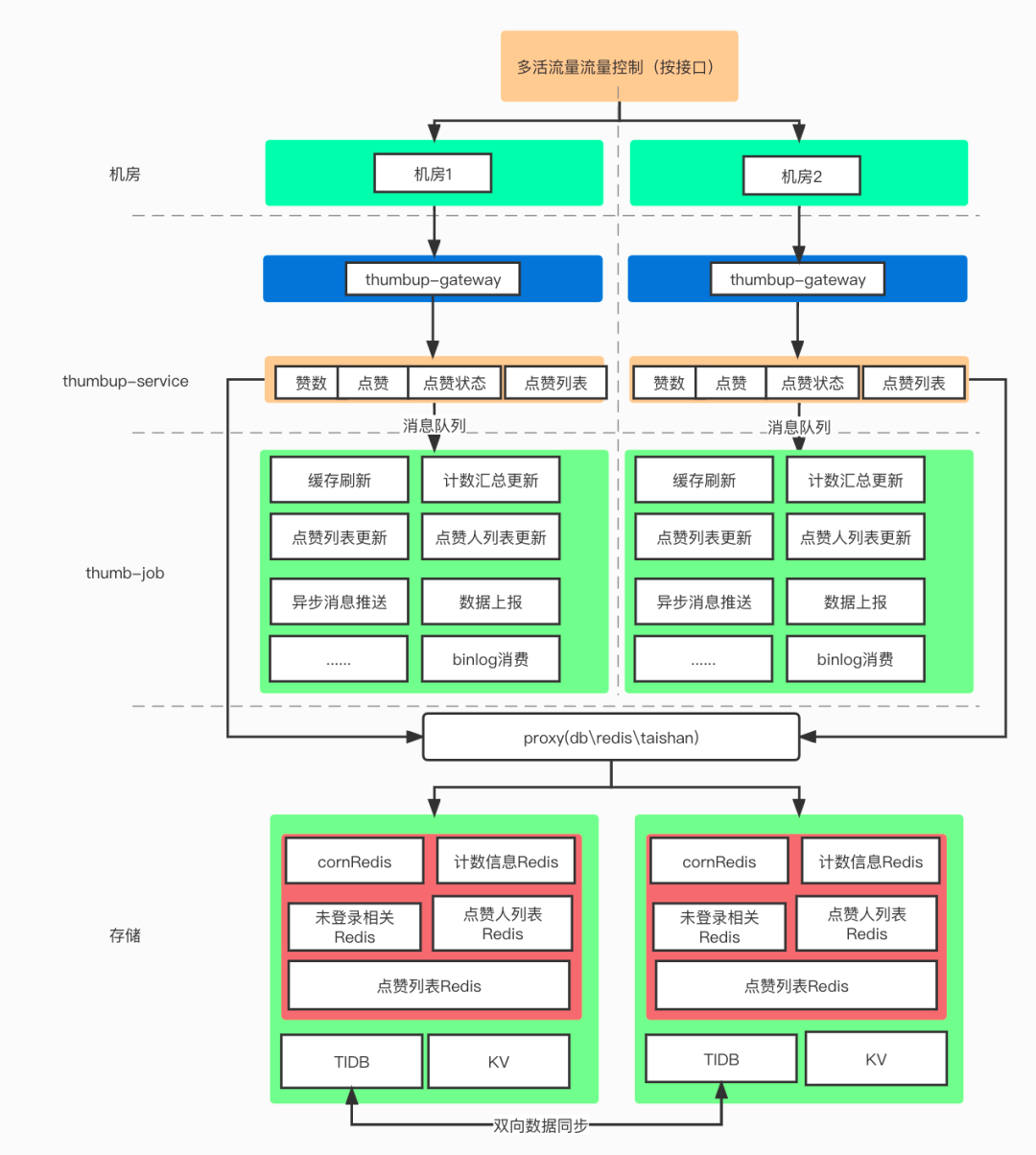
整个点赞服务的系统可以分为五个部分
下文将重点分享下数据存储层、点赞服务层(thumbup-service)与 异步任务层(thumbup-job)的系统设计
基本数据模型:
(1)第一层存储:DB层 - (TiDB)
点赞系统中最为重要的就是点赞记录表(likes)和点赞计数表(counts),负责整体数据的持久化保存,以及提供缓存失效时的回源查询能力。
点赞记录表 - likes : 每一次的点赞记录(用户Mid、被点赞的实体ID(messageID)、点赞来源、时间)等信息,并且在Mid、messageID两个维度上建立了满足业务求的联合索引。
点赞数表 - counts : 以业务ID(BusinessID)+实体ID(messageID)为主键,聚合了该实体的点赞数、点踩数等信息。并且按照messageID维度建立满足业务查询的索引。
由于DB采用的是分布式数据库TiDB,所以对业务上无需考虑分库分表的操作
(2)第二层存储
缓存层Cache:点赞作为一个高流量的服务,缓存的设立肯定是必不可少的。点赞系统主要使用的是CacheAside模式。这一层缓存主要基于Redis缓存:以点赞数和用户点赞列表为例
①点赞数
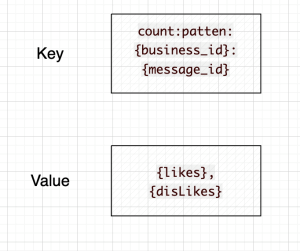
key-value = count:patten:{business_id}:{message_id} - {likes},{disLikes}用业务ID和该业务下的实体ID作为缓存的Key,并将点赞数与点踩数拼接起来存储以及更新
②用户点赞列表
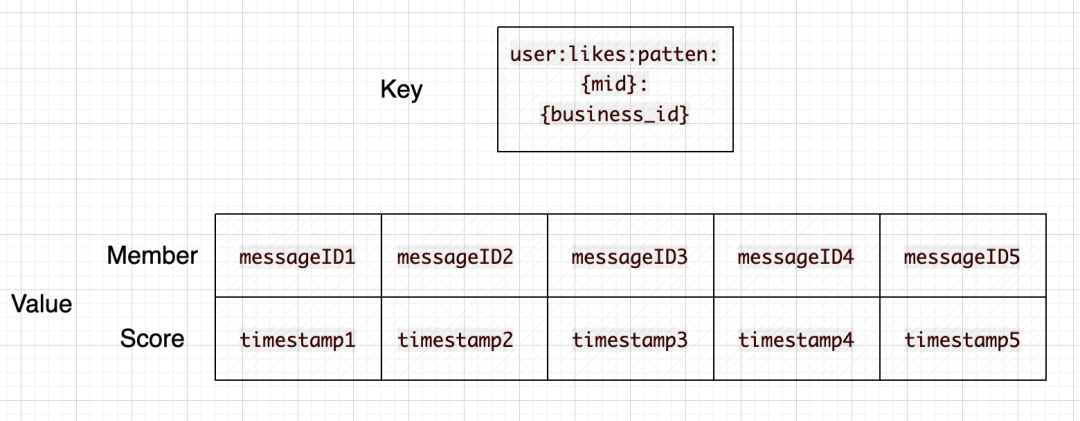
key-value = user:likes:patten:{mid}:{business_id} - member(messageID)-score(likeTimestamp)* 用mid与业务ID作为key,value则是一个ZSet,member为被点赞的实体ID,score为点赞的时间。当改业务下某用户有新的点赞操作的时候,被点赞的实体则会通过 zadd的方式把最新的点赞记录加入到该ZSet里面来为了维持用户点赞列表的长度(不至于无限扩张),需要在每一次加入新的点赞记录的时候,按照固定长度裁剪用户的点赞记录缓存。该设计也就代表用户的点赞记录在缓存中是有限制长度的,超过该长度的数据请求需要回源DB查询
(3)第三层存储
LocalCache - 本地缓存
本地缓存的建立,目的是为了应对缓存热点问题。
利用最小堆算法,在可配置的时间窗口范围内,统计出访问最频繁的缓存Key,并将热Key(Value)按照业务可接受的TTL存储在本地内存中。
其中热点的发现之前也有同步过:https://mp.weixin.qq.com/s/C8CI-1DDiQ4BC_LaMaeDBg
(4)针对TIDB海量历史数据的迁移归档
迁移归档的原因(初衷),是为了减少TIDB的存储容量,节约成本的同时也多了一层存储,可以作为灾备数据。
以下是在KV数据库(taishan)中点赞的数据与索引的组织形式:
①点赞记录
1_{mid}_${business_id}_${type}_${message_id} => {origin_id}_{mtime}
②用户点赞列表索引
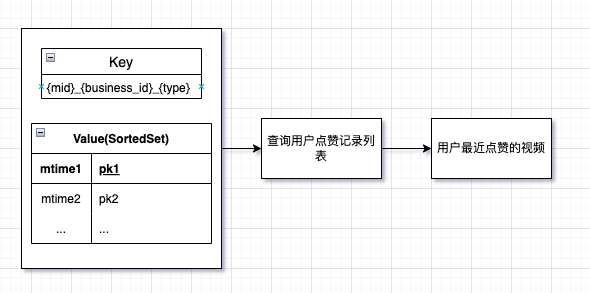
2_{mid}_${business_id}_${type}_${mtime}_{message_id} => {origin_id}
③实体维度点赞记录索引
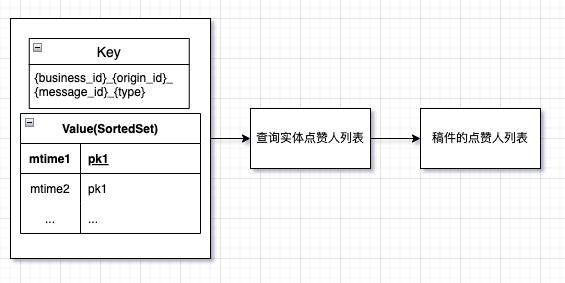
3_
{message_id}_${business_id}_${type}_${mtime}_${mid}=>{origin_id}
作为一个典型的大流量基础服务,点赞的存储架构需要最大程度上满足两个点:
(1)满足业务读写需求的同时具备最大的可靠性
(2)选择合适的存储介质与数据存储形态,最小化存储成本
从以上两点触发,考虑到KV数据在业务查询以及性能上都更契合点赞的业务形态,且TaiShan可以水平扩容来满足业务的增长。点赞服务从当前的关系型数据库(TiDB)+ 缓存(Redis)逐渐过渡至KV型数据库(Taishan)+ 缓存(Redis),以具备更强的可靠性。
同时TaiShan作为公司自研的KV数据库,在成本上也能更优于使用TiDB存储。
作为面对C端流量的直接接口,在提供服务的同时,需要思考在面对各种未知或者可预知的灾难时,如何尽可能提供服务
在DB的设计上,点赞服务有两地机房互为灾备,正常情况下,机房1承载所有写流量与部分读流量,机房2承载部分读流量。当DB发生故障时,通过db-proxy(sidercar)的切换可以将读写流量切换至备份机房继续提供服务。
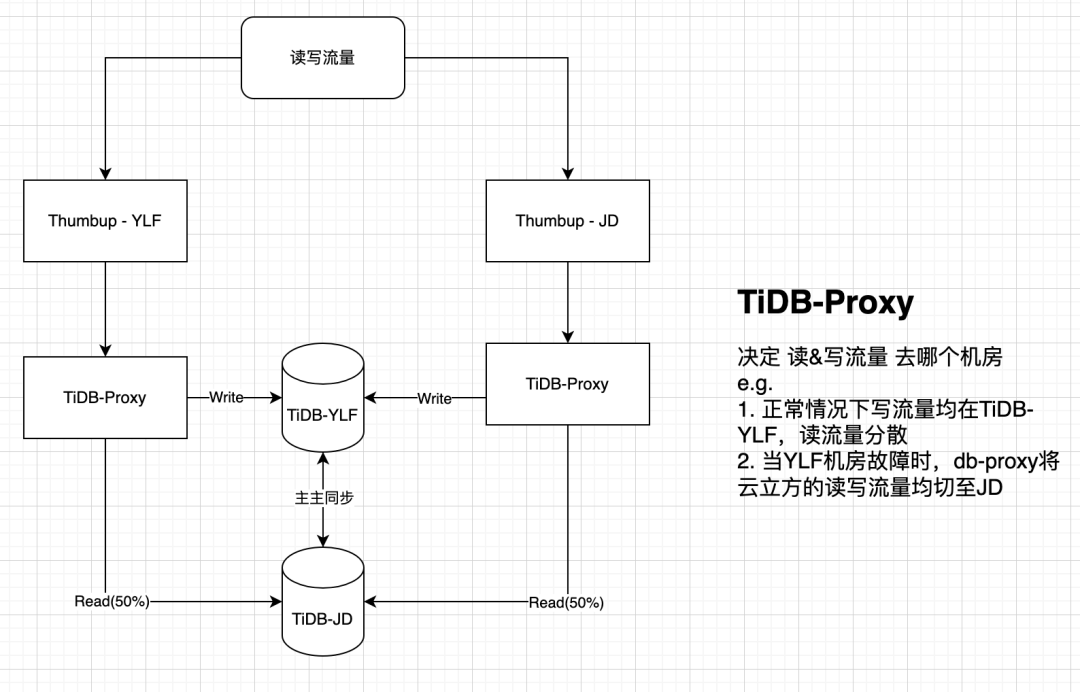
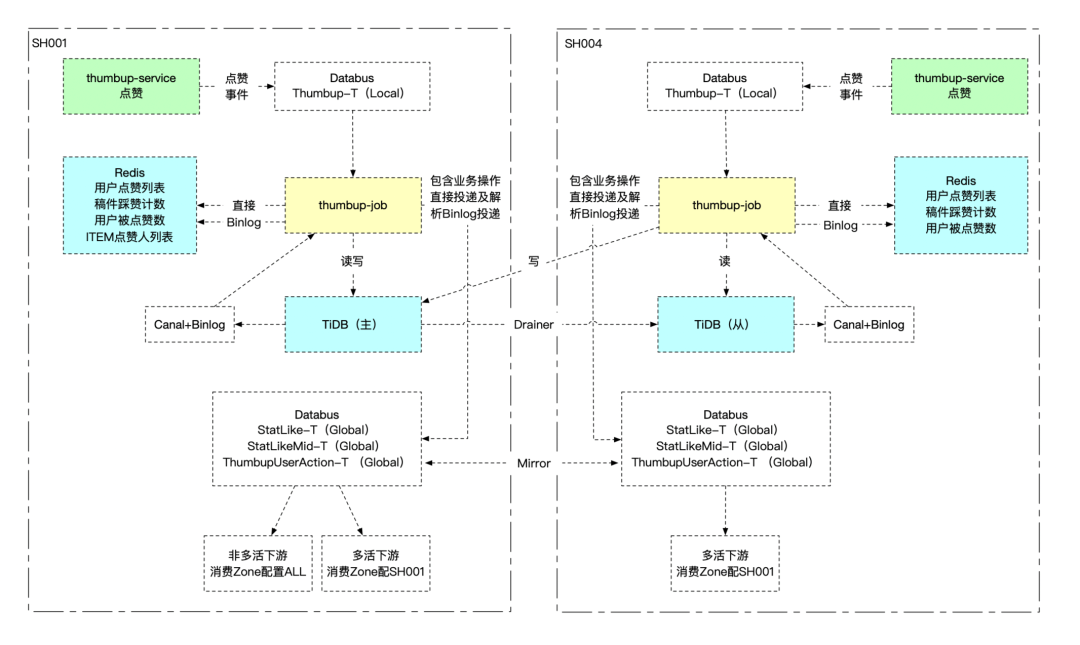
在缓存(Redis)上,点赞服务也拥有两套处于不同机房的集群,并且通过异步任务消费TiDB的binLog维护两地缓存的一致性。可以在需要时切换机房来保证服务的提供,而不会导致大量的冷数据回源数据库。
服务的容灾与降级
(以点赞数、点赞状态、点赞列表为例),点赞作为一个用户强交互的社区功能服务,对于灾难发生时用户体验的保证是放在第一位的。所以针对重点接口,我们都会有兜底的数据作为返回。
多层数据存储互为灾备
点赞的热数据在redis缓存中存有一份。
kv数据库中存有全量的用户数据,当缓存不可用时,KV数据库会扛起用户的所有流量来提供服务。
TIDB目前也存储有全量的用户数据,当缓存、KV均不可用时,tidb会依托于限流,最大程度提供用户数据的读写服务。
因为存在多重存储,所以一致性也是业务需要衡量的点。
首先是最重要的用户行为数据(点赞、点踩、取消等)的写入。搭配对数据库的限流组件以及消费速度监控,保证数据的写入不超过数据库的负荷的同时也不会出现数据堆积造成的C数据端查询延迟问题。
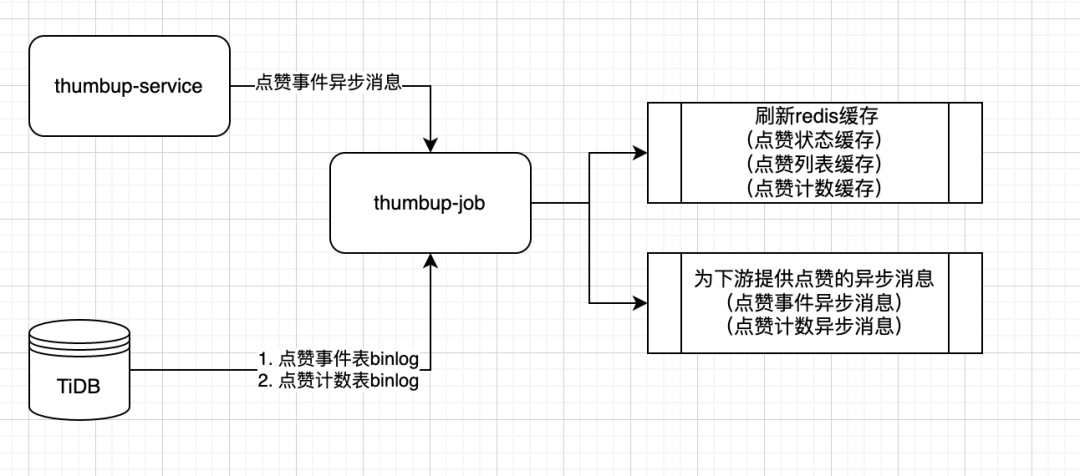
点赞job对binLog的容灾设计
由于点赞的存储为TiDB,且数据量较大。在实际生产情况中,binLog会偶遇数据延迟甚至是断流的问题。为了减少binLog数据延迟对服务数据的影响。服务做了以下改造。
首先在运维层面、代码层面都对binLog的实时性、是否断流做了监控
脱离binlog,由业务层(thumb-service)发送重要的数据信息(点赞数变更、点赞状态事件)等。当发生数据延迟时,程序会自动同时消费由thumbup-service发送的容灾消息,继续向下游发送。









