最近基于DEDetection-TRansformer(DETR)的模型已经获得了显著的性能。如果不在编码器中重新引入多尺度特征融合,它的成功就无法实现。然而,多尺度特征中过度增加的标记,特别是对于大约75%的低级别特征,在计算上效率很低,这阻碍了DETR模型的实际应用。本文提出了Lite DETR,这是一种简单而高效的端到端目标检测框架,可以有效地将检测头的GFLOPs减少60%,同时保持99%的原始性能。具体而言,论文设计了一个高效的编码器块,以交错的方式更新高级特征(对应于小分辨率特征图)和低级特征(对应于大分辨率特征图)。此外,为了更好地融合多尺度特征,论文开发了一种key-aware的可变形注意力来预测更可靠的注意力权重。综合实验验证了所提出的Lite DETR的有效性和效率,并且高效的编码器策略可以很好地推广到现有的基于DETR的模型中。
论文链接:https://arxiv.org/abs/2303.07335
代码链接:https://github.com/IDEA-Research/Lite-DETR
简介
目标检测旨在通过定位图像中的边界框并预测相应的分类分数来检测图像中感兴趣的目标。在过去的十年里,许多基于卷积网络的经典检测模型[23,24]取得了显著进展。最近,DEtection TRansformer[1](DETR)将Transformers引入到目标检测中,类似DETR的模型在许多基本视觉任务上都取得了很好的性能,如目标检测[13,36,37]、实例分割[5,6,14]和姿态估计[26,28]。
从概念上讲,DETR[1]由三部分组成:主干、Transformer编码器和Transformer解码器。许多研究工作一直在改进主干和解码器部分。例如,DETR中的主干通常是继承的,并且可以在很大程度上受益于预训练的分类模型[10,20]。DETR中的解码器部分是主要的研究重点,许多研究工作试图为DETR查询引入适当的结构,并提高其训练效率[11,13,18,21,36,37]。相比之下,在改进编码器部分方面所做的工作要少得多。朴素DETR中的编码器包括六个Transformer编码器层,它们堆叠在主干的顶部,以改进其特征表示。与经典的检测模型相比,它缺乏多尺度特征,这些特征对物体检测至关重要,尤其是对小目标的检测[9,16,19,22,29]。简单地在多尺度特征上应用Transformer编码器层是不可行的,因为计算成本是特征token数量的二次方。例如,DETR使用C5特征图来应用Transformer编码器,C5特征图是输入图像分辨率的1/32。如果C3特征(1/8比例)包括在多尺度特征中,则仅来自该比例的标记的数量将是来自C5特征图的标记的16倍。Transformer中自注意力的计算成本将高出256倍。
为了解决这个问题,Deformable DETR[37]开发了一种可变形注意力算法,通过将每个查询令牌与固定数量的采样点进行比较,将自注意力复杂度从二次降低到线性。基于这种高效的自注意计算,可变形DETR将多尺度特征引入到DETR中,可变形编码器已被广泛应用于后续类似DETR的模型[11,13,18,36]。
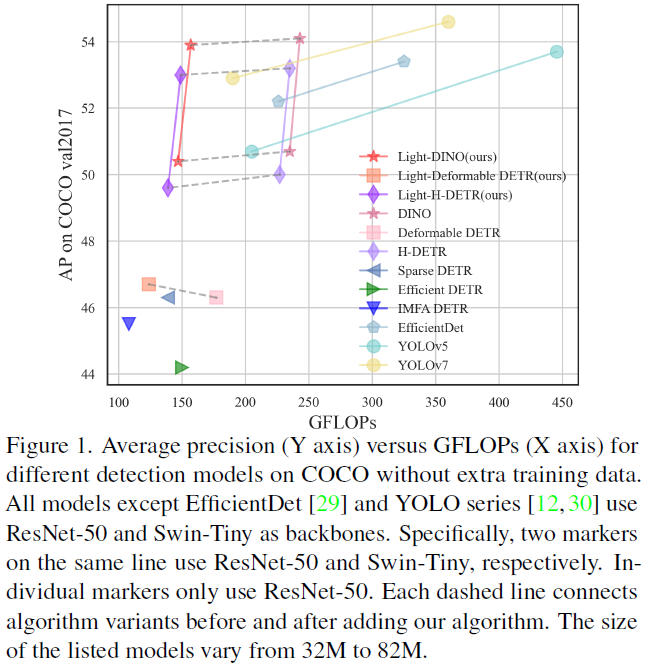
然而,由于多尺度特征引入了大量的查询令牌,可变形编码器仍然存在较高的计算成本。为了揭示这个问题,论文使用基于DETR的模型DINO[36]进行了一些分析实验,如表1和表2所示,以分析多尺度特征的性能瓶颈。可以观察到一些有趣的结果。首先低级别(高分辨率地图)特征占所有token的75%以上。其次,直接丢弃一些低级别特征(DINO-3scale)主要影响小目标(AP_S)的检测性能下降10%,但对大目标(AP_L)的影响很小。


受上述观察结果的启发,本文热衷于解决一个问题:我们能否使用更少的特征尺度,但保持重要的局部细节?利用结构化的多尺度特征,论文提出了一个高效的DETR框架,命名为Lite DETR。具体来说,设计了一个简单而有效的编码器块,包括几个可变形的自注意层,可以在任何多尺度DETR基础模型中即插即用,以减少62%~78%的编码器GFLOPs,并保持有竞争力的性能。编码器块将多尺度特征划分为高级特征(例如C6、C5、C4)和低级特征(例如C3)。高级和低级特征将以交错的方式更新,以改进多尺度特征金字塔。也就是说,在最初的几层中,我们让高级特征查询所有特征图并改进它们的表示,但保持低级token不变。这样的策略可以有效地将查询令牌的数量减少到原始令牌的5%~25%,并节省大量的计算成本。在编码器块的末尾,我们让低级标记查询所有特征图以更新其表示,从而保持多尺度特征。以这种交错的方式,我们更新不同频率的高级和低级特征,以实现高效计算。
此外,为了增强滞后的低级特征更新,论文提出了一种关键感知可变形注意力(KDA)方法来替换所有注意力层。当执行可变形注意力时,对于每个查询,它从特征图中的相同采样位置对关键点和值进行采样。然后,它可以通过将查询与采样的关键字进行比较来计算更可靠的注意力权重。这种方法也可以被视为扩展的可变形注意力或密集注意力的稀疏版本。论文发现KDA非常有效地利用论文提出的高效编码器块来恢复性能。
总结来说,本文的主要贡献如下:
- 论文提出了一种高效的编码器块,以交错的方式更新高级别和低级别特征,这可以显著减少用于高效检测的特征标记。这种编码器可以很容易地插入到现有的基于DETR的模型中;
- 为了增强滞后特征更新,论文引入了一种key-aware的可变形注意力,用于更可靠的注意力权重预测;
- 综合实验表明,Lite DETR可以将检测头GFLOPs降低60%,并保持99%的检测性能。具体来说,论文的Lite-DINO SwinT实现了53.9的AP和159GFLOPs。
方法
动机与分析
在这一部分中,论文首先分析了为什么现有的基于DETR的模型仍然效率低下,然后展示了一些有趣的观察结果。多尺度特征对于检测不同尺度的物体至关重要。它们由多个特征尺度组成,范围从高级别(低分辨率)到低级别(高分辨率)特征。每个较低级别的特征图包含的令牌比其上一个特征级别多4倍。从表2中可以观察到,低级别特征中的令牌数量呈二次增长,而三个高级别尺度仅占约25%。
此外以DETR变体DINO[36]为初步例子。如果简单地将低级特征(表2中的S4)丢弃在其可变形编码器中以降低计算成本,会发生什么?在表1中,缩减的DINO-3尺度模型以4.9%的平均精度(AP)和10.2%的小目标检测恶化为代价,在GFLOP方面获得了48%的效率增益。然而,大目标上的AP是有竞争力的。也就是说,高级令牌包含紧凑的信息和丰富的语义来检测大目标。相比之下,大量的低级别令牌主要负责检测小目标的局部细节。同时,多尺度特征包含许多冗余标记,尤其是低级特征。因此,我们想探索如何通过主要关注构建更好的高级别特征来有效地更新多尺度特征。
通过这种方式,论文可以在大多数层中优先考虑高级特征更新,这可以显著减少查询令牌,从而实现更高效的多尺度编码器。总之,这项工作旨在为高效的基于DETR的检测器设计一种通用解决方案,并保持有竞争力的性能。
模型概览
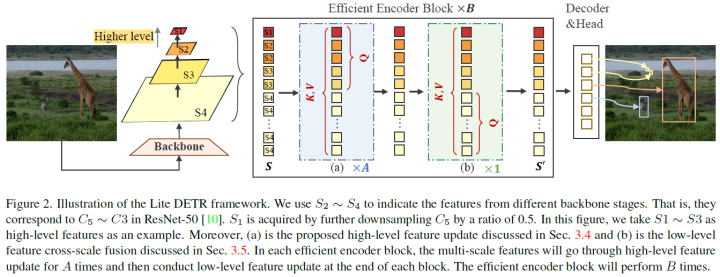
继多尺度可变形DETR[37]之后,Lite DETR由主干、多层编码器和带预测头的多层解码器组成。整体模型框架如图2所示。具体来说,将主干中的多尺度特征分为高级特征和低级特征。在所提出的高效编码器块中,这些特征将以交错的方式以不同的更新频率进行更新,以实现精度和效率的权衡。为了增强低级别特征的滞后更新,论文进一步引入了一种关键感知可变形注意力(KDA)方法。
交错更新
从论文的动机来看,高效编码器的瓶颈是过度的低级特征,其中大多数特征不是信息性的,而是包含小目标的局部细节。此外,多尺度特征S本质上是结构化的,其中少量的高级特征编码丰富的语义,但对于一些小目标缺乏重要的局部特征。因此,论文建议以交错的方式对不同尺度的特征进行优先级排序,以实现精度和效率的权衡。论文将S分为低级特征和高级特征,和是相应的token数量。可以在不同的设置中包含前三个或两个尺度,为了清晰起见,将设置为S1、S2、S3,默认为S4。被视为主要特征,更新频率较高,而更新频率较低。由于可变形注意力与特征查询具有线性复杂性,因此少量频繁更新的高级特征在很大程度上降低了计算成本。如图2所示,将高效编码器块堆叠B次,其中每个块更新高级特征A次,但仅在块结束时更新低级特征一次。通过这种方式,可以以低得多的计算成本来维持全尺寸的特征金字塔。通过这种交错更新,论文为和设计了两种有效的更新机制。
迭代高级特征跨尺度融合
在该模块中,高级特征FH将作为查询(Q),从所有尺度提取特征,包括低级和高级特征标记。该操作通过高级语义和高分辨率细节增强了的表示。详细的更新过程如图2所示。这种操作效率很高。例如,在前两个尺度或前三个尺度中使用多尺度特征查询将分别显著减少94.1%和75.3%的查询,如表2所示。论文还使用所提出的key-aware注意力模块KDA来执行注意力和更新令牌。从形式上讲,更新过程可以描述为:
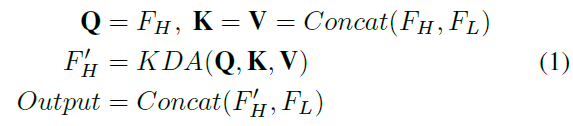
高级特征更新层将被堆叠用于多个(例如,A次)层,用于迭代特征提取。注意,更新后的还将迭代更新多尺度特征金字塔中的Q和相应的高级特征,这使得下一层中的K和V中的特征更新。有趣的是,这个高级特征更新模块类似于Transformer解码器,论文使用少量高级令牌来查询其类似于自注意力的特征,并查询大量类似于交叉注意的低级特征。
高效的低层次特征跨尺度融合
如表2所示,低级特征包含过多的令牌,这是低效计算的关键因素。因此,高效编码器在高级特征融合序列之后以较低的频率更新这些低级特征。具体来说,利用初始的低级特征作为查询来与更新的高级令牌交互,以及利用原始的低级特征来更新它们的表示。与高级功能更新类似,使用了与KDA注意力层的交互。从形式上讲如下:
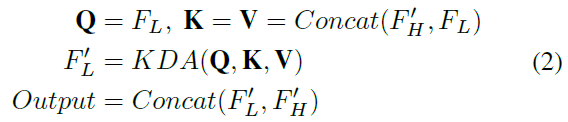
Key-aware Deformable Attention
在普通可变形注意力层中,查询Q将被划分为M个Head,并且每个头部将从L个特征尺度中的每一个特征尺度采样K个点作为值V。因此,为查询采样的值的总数是。采样偏移p及其相应的注意力权重是使用表示为和的两个线性投影从查询中直接预测的。可变形注意力可以公式化为:
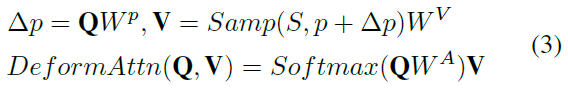
请注意,没有key参与原始可变形注意力层,这表明查询可以仅通过其特征来决定每个采样值的重要性,而无需将其与key进行比较。由于所有的多尺度特征都是对采样位置和注意力权重的查询,因此原始模型可以快速学习如何在给定查询的情况下评估每个采样位置的重要性。然而,论文编码器中的交错更新使查询难以决定其他异步特征图中的注意力权重和采样位置,如图5所示。

为了更好地适应高效的编码器设计,论文提出了一种key-aware可变形注意力(KDA)方法来对查询的密钥和值进行采样,如图3所示。
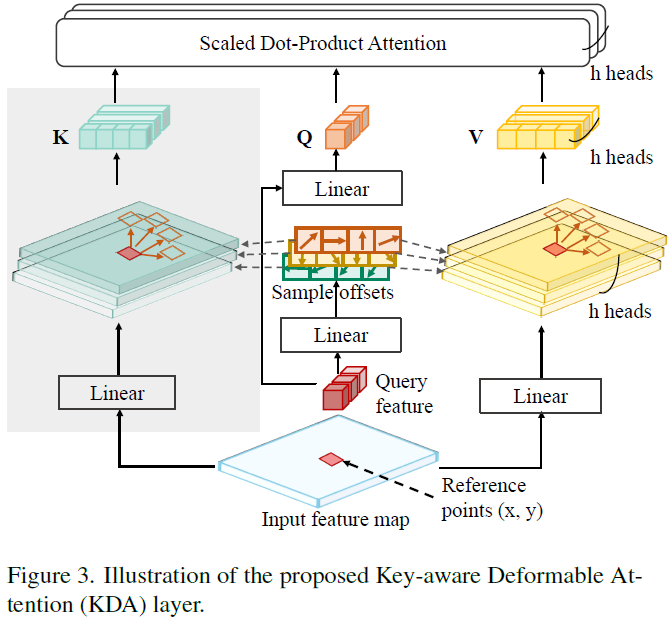
采样的键和值以及查询将执行标准缩放的点积注意力。从形式上讲如下:
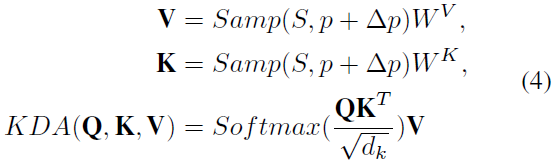
与稀疏DETR和其他有效变体的讨论
另一种有效的方法是通过在多尺度特征中选择显著的标记来减少编码器标记,如Sparse DETR[25]。然而,这种方法有三个缺点。首先,很难在其他基于DETR的模型中进行推广,因为它打破了结构化的特征组织。其次,由于有限的和隐式的监督,通过评分网络选择的令牌可能不是最优的。第三,它引入了其他组件,如多个辅助编码器检测损耗,以增强其稀疏编码器表示。由于编码器负责特征提取,添加检测监督使其难以应用于现有模型。
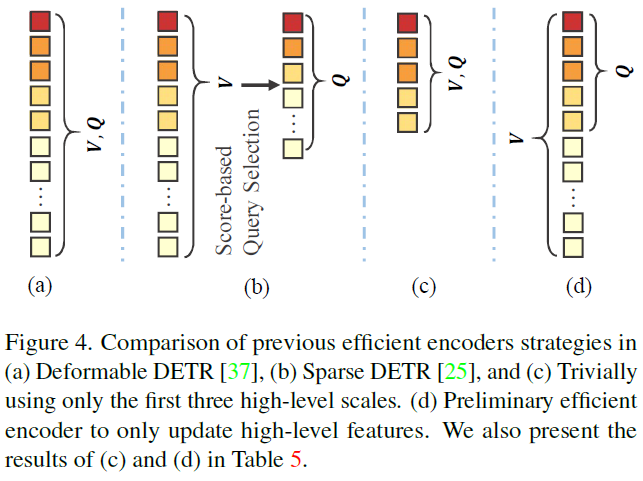
此外,为了进行清楚的比较,论文在图4中说明了以前的高效编码器和初步的高效设计。
实验
论文在COCO数据集上展开实验。
可变形DETR的效率改进
在表3中,论文使用我们提出的lite编码器来取代可变形DETR中的可变形编码器,并构建lite-可变形DETR。使用大约40%的原始编码器GFLOPs实现了与可变形DETR相当的性能。还可以观察到,具有单个尺度的较大特征图的基于DETR的模型在计算上效率低下,并且不如多尺度模型。在迭代的高级跨尺度融合中,可以有效地采用只有两个或三个高级特征图,这可以将编码器层中的查询减少到原始令牌的5%~25%。与其他基于可变形DETR的高效变体相比,论文在相同的计算成本下实现了更好的性能。例如在GFLOPs较少的情况下以0.7 AP的优势超过Sparse DETR-rho-0.3。此外,稀疏DETR基于改进的基线,该基线结合了高效DETR和可变形DETR。相比之下,论文的Lite可变形DETR简单有效。
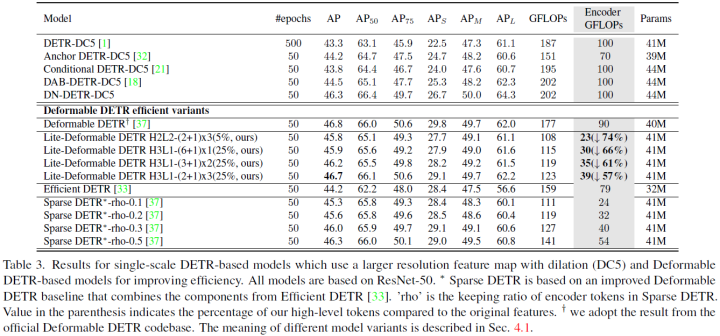
其他基于DETR的模型的效率改进
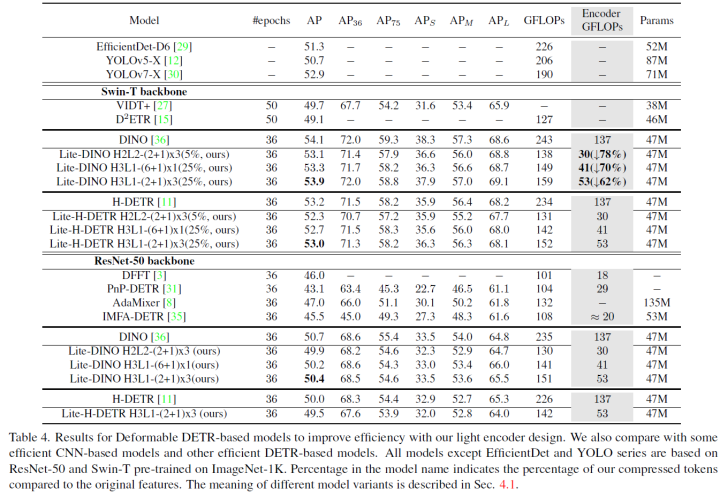
与其他高效变体相比,论文的高效设计不受特定检测框架的限制,并且可以很容易地插入到其他基于DETR的模型中。论文以DINO[36]和H-DETR[11]为例来展示高效编码器的有效性。结果如表4所示。与最近提出的其他类似高效DETR的模型[8,35]相比,本文的模型在计算成本相当的情况下实现了显著更好的性能。此外,插入高效的编码器后,编码器的GFLOPs与原始编码器相比可以减少78%~62%,同时保持99%的原始性能。具体而言,基于Swin Tiny,Lite DINO仅用159 GFLOPs实现了53.9 AP,在相同的GFLOP下也优于YOLO系列[12,30]。
KDA可视化
论文还在图5中的交错编码器中提供了KDA注意力的可视化。与可变形注意力相比,当引入keys,时,KDA注意力可以预测更可靠的权重,尤其是在低级别特征图上。例如,在图5(a)中,S4中可变形注意力的采样位置(用三角形表示)与KDA相比不太可靠。在图6中,在图5(b)和(c)中,观察到在交错编码器中,可变形注意力很难集中在最大比例图S4上的有意义区域上。KDA有效地缓解了这种现象,这有助于提取更好的局部特征,从而恢复小目标的性能。
消融实验
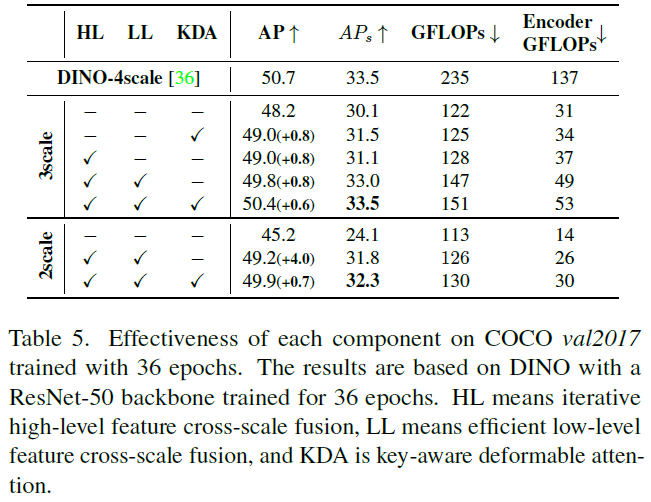
每个模块的有效性:在表5中展示了组件的有效性。选择DINO-3scale和DINO-2scale作为基线,它只使用前三个和两个高级特征图。结果表明,每个组件都需要较小的计算成本,同时以相当大的幅度提高了模型性能。具体来说,这些组件有效地恢复了小目标的性能,例如,论文高效的DINO-3scale的AP与原始的DINO-4scale模型相当。
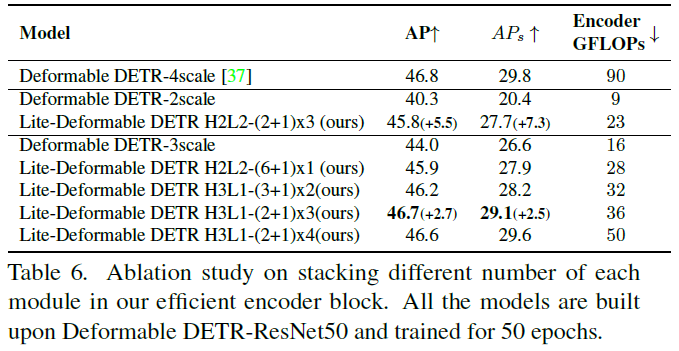
堆叠不同数量模块的影响:在表6中探索了有效块中堆叠每个模块的最佳选择。基于具有ResNet-50骨干的可变形DETR[37],论文改变了影响计算复杂性和检测性能的三个参数,包括用作高级特征的高级尺度H的数量、高效编码器块B和迭代高级特征跨尺度融合A。当使用更多的高级特征尺度和更多的编码器块来更新低级特征时,性能会提高。然而,进一步增加模块数量并不能提高性能。
结论
本文分析了Transformer编码器中具有过多低级别特征的多尺度特征是导致基于DETR的模型计算效率低下的主要原因。论文为Lite DETR提供了一个高效的编码器块,它将编码器令牌分为高级和低级特征。这些特征将通过跨尺度融合在不同频率下进行更新,以实现精度和效率的权衡。为了减轻异步特征的影响,进一步提出了一种key-aware的可变形注意力,它有效地恢复了小目标的检测性能。因此提出的高效编码器可以将计算成本降低60%,同时保持99%的原始性能。此外,这种高效的设计可以很容易地插入到许多基于DETR的检测模型中。本文希望Lite DETR能够为基于DETR的模型中的有效检测提供一个简单的基线,以使其他资源受限的应用程序受益。
限制:本文主要关注降低计算复杂度,而不是优化基于DETR的模型的耗时。论文把这件事留给未来的工作。
参考
[1] Lite DETR : An Interleaved Multi-Scale Encoder for Efficient DETR








