以下文章来源于微信公众号:小白学视觉
本文仅用于学术分享,如有侵权,请联系后台作删文处理
显存占用和GPU利用率是两个不一样的东西,显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。显存可以看成是空间,类似于内存。GPU计算单元类似于CPU中的核,用来进行数值计算。

深度学习最吃硬件,耗资源,在本文,我将来科普一下在深度学习中:何为“资源”
不同操作都耗费什么资源
如何充分的利用有限的资源
如何合理选择显卡
nvidia-smi是Nvidia显卡命令行管理套件,基于NVML库,旨在管理和监控Nvidia GPU设备。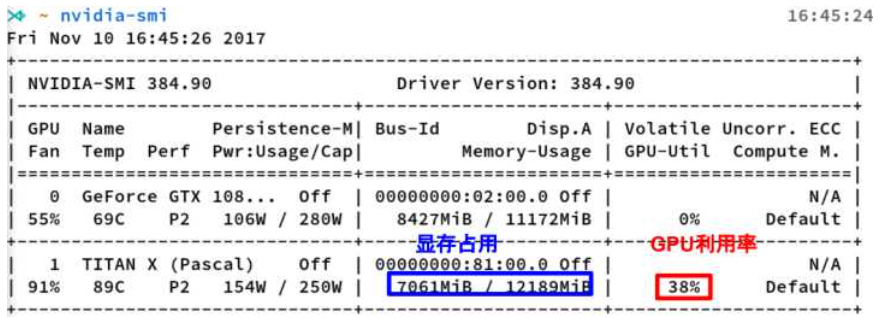
这是nvidia-smi命令的输出,其中最重要的两个指标:显存占用和GPU利用率是两个不一样的东西,显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。这里推荐一个好用的小工具:gpustat,直接pip install gpustat即可安装,gpustat基于nvidia-smi,可以提供更美观简洁的展示,结合watch命令,可以动态实时监控GPU的使用情况。
watch --color -n1 gpustat -cpu

显存用于存放模型,数据
显存越大,所能运行的网络也就越大
GPU计算单元类似于CPU中的核,用来进行数值计算。衡量计算量的单位是flop: the number of floating-point multiplication-adds,浮点数先乘后加算一个flop。计算能力越强大,速度越快。衡量计算能力的单位是flops:每秒能执行的flop数量
1.1 存储指标

K、M,G,T是以1024为底,而KB
、MB,GB,TB以1000为底。不过一般来说,在估算显存大小的时候,我们不需要严格的区分这二者。在深度学习中会用到各种各样的数值类型,数值类型命名规范一般为TypeNum,比如Int64、Float32、Double64。
其中Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。举例来说:有一个1000x1000的 矩阵,float32,那么占用的显存差不多就是
2x3x256x256的四维数组(BxCxHxW)占用显存为:24M举例来说,对于如下图所示的一个全连接网络(不考虑偏置项b)

输入X可以看成是上一层的输出,因此把它的显存占用归于上一层。只有有参数的层,才会有显存占用。这部份的显存占用和输入无关,模型加载完成之后就会占用。卷积
全连接
BatchNorm
Embedding层
... ...
多数的激活层(Sigmoid/ReLU)
池化层
-
Dropout
... ...
更具体的来说,模型的参数数目(这里均不考虑偏置项b)为:Linear(M->N): 参数数目:M×N
Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
BatchNorm(N): 参数数目:2N
Embedding(N,W): 参数数目:N × W
在PyTorch中,当你执行完model=MyGreatModel().cuda()之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。1.2.2 梯度与动量的显存占用

如果是Adam优化器,动量占用的显存更多,显存x41.2.3 输入输出的显存占用
这部份的显存主要看输出的feature map 的形状。


据此可以计算出每一层输出的Tensor的形状,然后就能计算出相应的显存占用。需要计算每一层的feature map的形状(多维数组的形状)
模型输出的显存占用与 batch size 成正比
需要保存输出对应的梯度用以反向传播(链式法则)
模型输出不需要存储相应的动量信息(因为不需要执行优化)
深度学习中神经网络的显存占用,我们可以得到如下公式:显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
可以看出显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大
1.3 节省显存的方法
在深度学习中,一般占用显存最多的是卷积等层的输出,模型参数占用的显存相对较少,而且不太好优化。降低batch-size
下采样(NCHW -> (1/4)*NCHW)
减少全连接层(一般只留最后一层分类用的全连接层)
计算量的定义,之前已经讲过了,计算量越大,操作越费时,运行神经网络花费的时间越多。

2.2 AlexNet 分析
AlexNet的分析如下图,左边是每一层的参数数目(不是显存占用),右边是消耗的计算资源
2.3 减少卷积层的计算量
今年谷歌提出的MobileNet,利用了一种被称为DepthWise Convolution的技术,将神经网络运行速度提升许多,它的核心思想就是把一个卷积操作拆分成两个相对简单的操作的组合。如图所示, 左边是原始卷积操作,右边是两个特殊而又简单的卷积操作的组合(上面类似于池化的操作,但是有权重,下面类似于全连接操作)。


2.4 常用模型 显存/计算复杂度/准确率
去年一篇论文(http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1605.07678)总结了当时常用模型的各项指标,横座标是计算复杂度(越往右越慢,越耗时),纵座标是准确率(越高越好),圆的面积是参数数量(不是显存占用)。左上角我画了一个红色小圆,那是最理想的模型的的特点:快,效果好,占用显存小。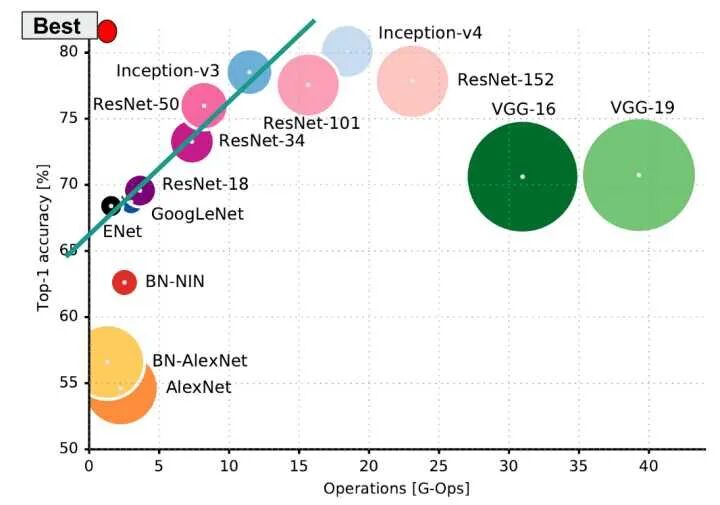
3.1 建议
尤其是batch-size,假定GPU处理单元已经充分利用的情况下:增大batch size能增大速度,但是很有限(主要是并行计算的优化)
增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但是每次迭代耗时更长。
增大batch size使得一个epoch所能进行的优化次数变少,收敛可能变慢,从而需要更多时间才能收敛(比如batch_size 变成全部样本数目)。
3.2 关于显卡购买
一般显卡购买渠道就是京东自营、淘宝等电商平台,线下实体店也可以购买。 正常时期,同款显卡,京东自营的价格会略高于淘宝,主要是京东自营的售后比淘宝更好,更放心,而特殊时期,比如现在部分型号淘宝和京东自营的价格比较悬殊,我建议是淘宝购买,如果价格相差不大,优先京东自营购买。像微星不支持个人送保,我不建议在淘宝和拼多多等渠道购买,售后不方便,建议天猫旗舰店及京东自营等有售后保障的渠道购买,支持个人送保的品牌在哪里买都可以。
本文都是针对单机单卡的分析,分布式的情况会和这个有所区别。在分析计算量的时候,只分析了前向传播,反向传播计算量一般会与前向传播有细微的差别。 AIHIA | AI人才创新发展联盟2023年盟友招募
AI同学会 | AI同学会开启试运营,快来Pick你的AI同学
AI融资 | 智能物联网公司阿加犀获得高通5000W融资
注意:大白梳理对接AI行业的一些中高端岗位,年薪在50W~120W之间,图像算法、搜索推荐等热门岗位,欢迎感兴趣的小伙伴联系大白,提供全流程交流跟踪,各岗位详情如下:《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!

人工智能行业,研究方向很多,大大小小有几十个方向。
为了便于大家学习交流,大白创建了一些不同方向的行业交流群。每个领域,都有各方向的行业实战高手,和大家一起沟通交流。目前主要开设:Opencv项目方面、目标检测方面、模型部署方面,后期根据不同领域高手的加入,建立新的方向群!大家可以根据自己的兴趣爱好,加入对应的微信群,一起交流学习!
大家一起加油!