「原驼」大模型输出的内容和 ChatGPT 比,人类也无法区分谁好谁坏。
用微调的方法,现在羊驼模型也可以打 ChatGPT 了,这不是随便说说,有测试结果为证。
最近,来自华盛顿大学的 QLoRA 成为了 AI 领域的热门,很多人把它形容为里程碑级、改变规则的技术。
新方法训练出的模型在评测基准上可以做到 ChatGPT 99% 的能力,而且 33B 的版本只需要在单块 24GB GPU 上进行微调,65B 的版本只需要 46GB 的 GPU。
现在用一块 RTX 4090,就能做 ChatGPT 一样的事,这样的结果让人高呼不敢相信:
具体来说,QLoRA 使用 4 位量化来压缩预训练的语言模型。然后冻结 LM 参数,并将相对少量的可训练参数以 Low-Rank Adapters 的形式添加到模型中。模型体量大幅压缩,推理效果几乎没有受到影响。
对于大型语言模型(LLM)来说,微调(Finetuning)是提高性能、减少错误输出的有效方式。但众所周知,微调大模型是一个成本比较高的工作,举例来说,LLaMA 65B 参数模型的常规 16 位微调需要超过 780 GB 的 GPU 内存。
来自华盛顿大学的研究者首次证明,我们也可以在不降低任何性能的情况下微调量化的 4 位模型,其新方法 QLoRA 使用一种新的高精度技术将预训练模型量化为 4 位,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行调整。
论文《QLORA: Efficient Finetuning of Quantized LLMs》:
论文链接:https://arxiv.org/abs/2305.14314
GitHub:https://github.com/artidoro/qlora
作者开源了代码库和 CUDA 内核,并已将新方法集成到了 Hugging Face transformer 堆栈中。QLoRA 发布了一系列适用于 7/13/33/65B 的版本,在 8 种不同的指令跟随数据集上进行了训练,总共有 32 种不同的开源微调模型。
与 16 位完全微调的基准相比,QLoRA 将微调 65B 参数模型的平均内存需求从大于 780GB 的 GPU 降低到小于 48GB,同时也不降低运行时或预测性能。这标志着 LLM 微调的可访问性发生了重大转变:现在最大的公开可用模型也可以在单块 GPU 上进行微调了。
使用 QLORA,研究人员训练了 Guanaco(原驼)系列模型,第二好的模型在 Vicuna 基准测试中达到了 ChatGPT 性能水平的 97.8%,同时在单个消费级 GPU 上训练时间不到 12 小时,如果在 24 小时内使用单块专业 GPU,最大的模型能达到 99.3%,基本上可以说缩小了在 Vicuna 基准测试上与 ChatGPT 的差距。
另外在部署时,最小的 Guanaco 模型(7B 参数)仅需要 5 GB 内存,并且在 Vicuna 基准测试中比 26 GB Alpaca 模型性能高出 20 个百分点以上。
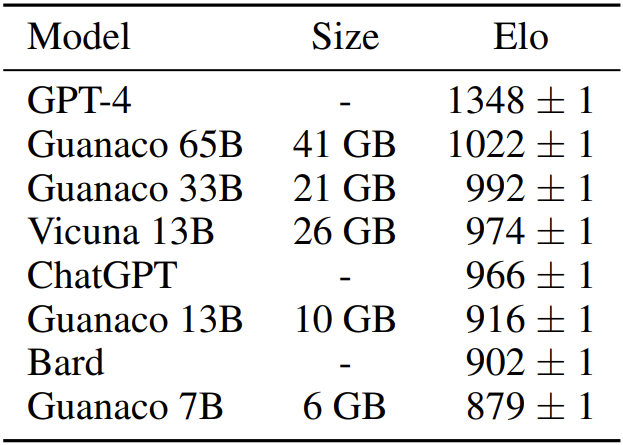
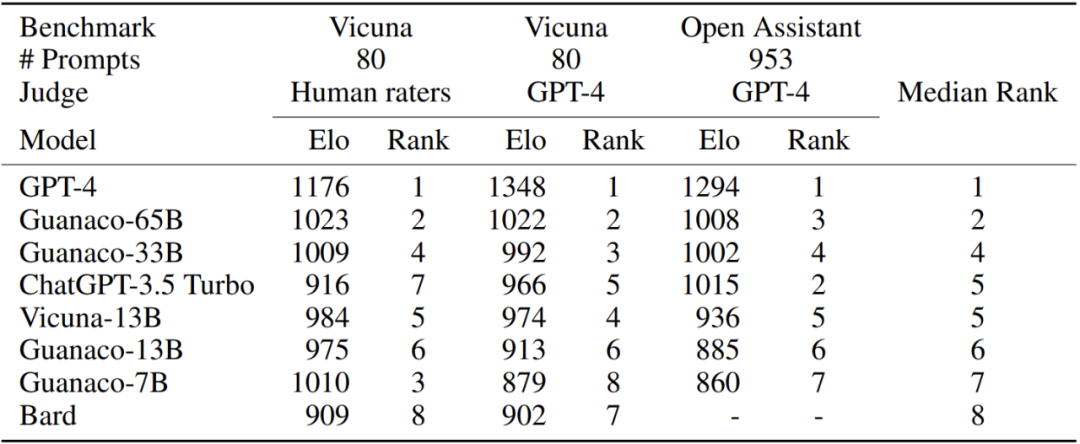
表 1. 模型之间竞争的 Elo 评级,以 GPT-4 为标杆,GPT4 之后 Guanaco 33B 和 65B 获胜次数最多,而 Guanaco 13B 的得分比 Bard 好。
QLoRA 引入了多项创新,目标是在不牺牲性能的情况下减少内存使用,其中包括:
4 位的 NormalFloat,这是一种信息理论上最优的正态分布数据量化数据类型,可产生比 4 位整数和 4 位浮点数更好的经验结果。
Double Quantization,一种对量化常数进行量化的方法,每个参数平均节省约 0.37 位(65B 型号约 3GB)。
Paged Optimizers,使用英伟达统一内存来避免在处理具有较长序列长度的 mini-batch 时出现的梯度 check point 内存尖峰。
这些贡献被结合到了一个更好调整的 LoRA 方法中,该方法在每个网络层都包含适配器,从而避免了之前工作中出现的几乎所有准确性权衡。
QLoRA 的效率让我们能够在模型规模上对指令微调和聊天机器人性能进行深入研究,此前由于内存开销的限制,使用常规微调是不可能的。
因此,作者在多个指令调优数据集、模型架构和 80M 到 65B 参数大小之间训练了 1000 多个模型。
除了展示 QLoRA 恢复 16 位性能和训练最先进的聊天机器人 Guanaco 的能力之外,该研究还分析了训练模型的趋势。首先,作者发现数据质量远比数据集大小重要。例如 9k 样本数据集 (OASST1) 在聊天机器人性能方面优于 450k 样本数据集(FLAN v2,二次采样),即使两者都旨在支持泛化后的指令。
其次,强大的大规模多任务语言理解 (MMLU) 基准性能并不意味着强大的 Vicuna 聊天机器人基准性能,反之亦然 —— 换句话说,数据集适用性比给定任务的大小更重要。
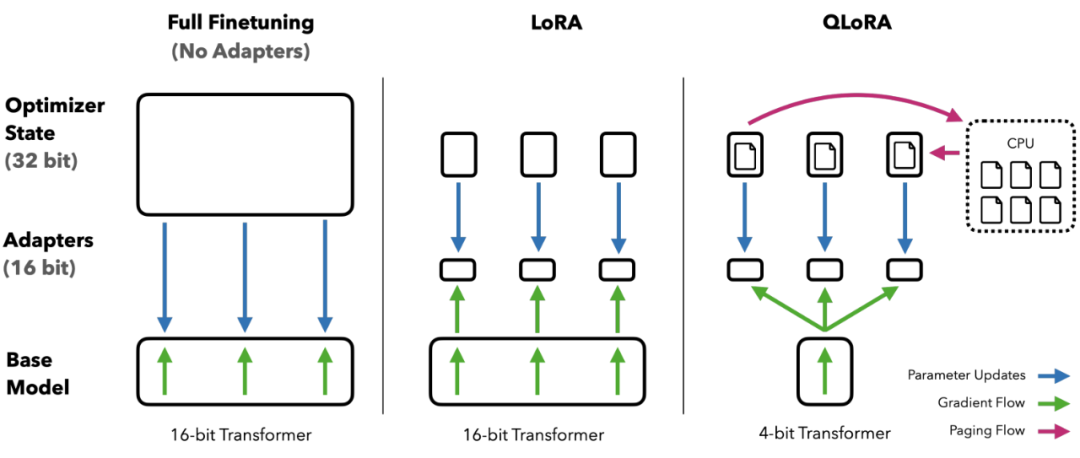
图 1:不同的微调方法及其内存要求。QLoRA 通过将 transformer 模型量化为 4 位精度并使用分页优化器来处理内存峰值提升了性能。
QLoRA 与标准微调
QLoRA 是否可以像全模型微调一样执行呢?默认 LoRA 超参数与 16 位性能不匹配,当使用将 LoRA 应用于查询及值注意投影矩阵的标准做法时,我们无法复制大型基础模型的完整微调性能。如图 2 所示,在 Alpaca 上进行 LLaMA 7B 微调,最关键的 LoRA 超参数是总共使用了多少个 LoRA adapter,并且所有线性 transformer 块层上的 LoRA 都需要匹配完整的微调性能。其他 LoRA 超参数,例如投影维度 r 则不影响性能。
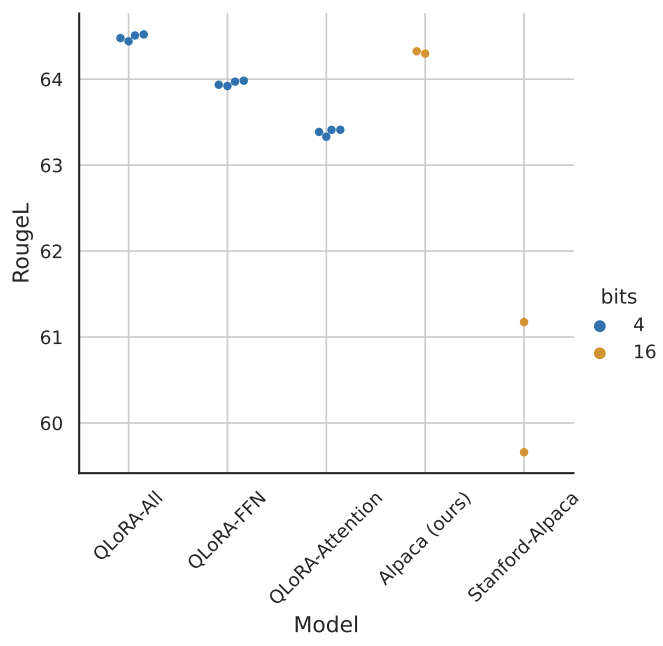
图 2. LLaMA 数据集上 LLaMA 7B 模型的 RougeL,每个点代表使用不同随机种子的运行。
4 位 NormalFloat 产生了比 4 位浮点更好的性能。虽然 4 位 NormalFloat (NF4) 数据类型在信息理论上是最优的,但这里仍需要确定此属性是否转化成为了经验优势。在图 3 和表 2 中,我们看到 NF4 比 FP4 和 Int4 显着提高了性能,并且双量化在不降低性能的情况下减少了内存占用。
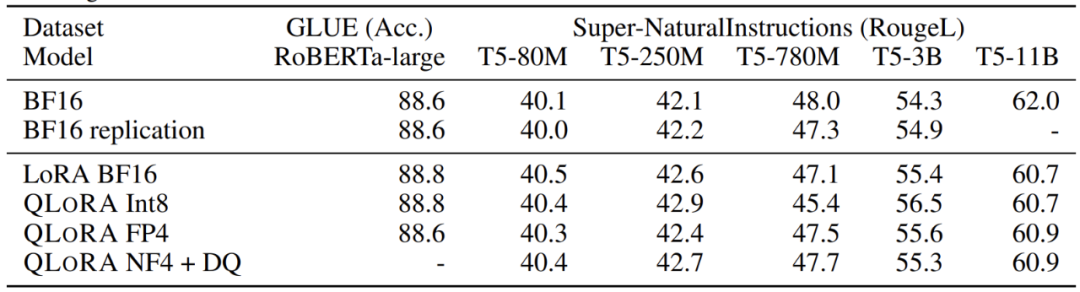
表 3:在 GLUE 和 Super-NaturalInstructions 上比较 16 位 BrainFloat (BF16)、8 位整数 (Int8)、4 位浮点数 (FP4) 和 4 位 NormalFloat (NF4) 的实验。QLoRA 复制 16 位 LoRA 和 fullfinetuning。
该研究的实验结果一致表明,具有 NF4 数据类型的 4 位 QLoRA 在具有完善的评估设置的学术基准上与 16 位完全微调和 16 位 LoRA 微调性能相匹配,而且 NF4 比 FP4 更有效,并且双量化不会降低性能。综合起来,这形成了令人信服的证据,证明 4 位 QLoRA 调整可靠地产生与 16 位方法匹配的结果。
与之前关于量化的工作 [13] 一致,QLoRA 的 MMLU 和 Elo 结果表明,在给定的微调和推理资源预算下,增加基本模型中的参数数量同时降低其精度是有益的。这凸显了 QLoRA 带来的效率优势。该研究在实验中发现,相比于全参数微调(full-finetuning),使用 4 位微调的方法性能并没有下降,这就引出了 QLoRA 调优中性能 - 精度的权衡问题,这将是未来的研究方向。
用 QLoRA 改进对话机器人模型
在该研究发现 4 位 QLoRA 在规模、任务和数据集方面与 16 位性能相当以后,该研究对指令微调进行了深入研究,并评估了指令微调开源模型的性能。
具体来说,该研究在具有挑战性的自然语言理解基准 MMLU 上进行了评估,并开发了用于真实世界聊天机器人性能评估的新方法。在 MMLU 上评估的结果如下表 4 所示

基于 Chiang et al. [10] 提出的评估协议,该研究使用 GPT-4 来评估不同系统相比于 ChatGPT (GPT-3.5 Turbo) 的 Vicuna 基准测试结果。这被该研究称为自动化评估方法。
Guanaco:GPT-4 之后性能最好的模型
通过自动化评估和人工评估,该研究发现在 OASST1 的变体上微调的顶级 QLORA 调优模型 Guanaco 65B 是性能最佳的开源聊天机器人模型,其性能可与 ChatGPT 媲美。与 GPT-4 相比,Guanaco 65B 和 33B 的预期获胜概率为 30%,该结果基于人类注释者系统级成对比较得出的 Elo 等级分(Elo rating),这也是迄今为止报告的最高水平。
该研究还进行了与 ChatGPT 对比的 Vicuna 基准测试,结果如下表 6 所示:
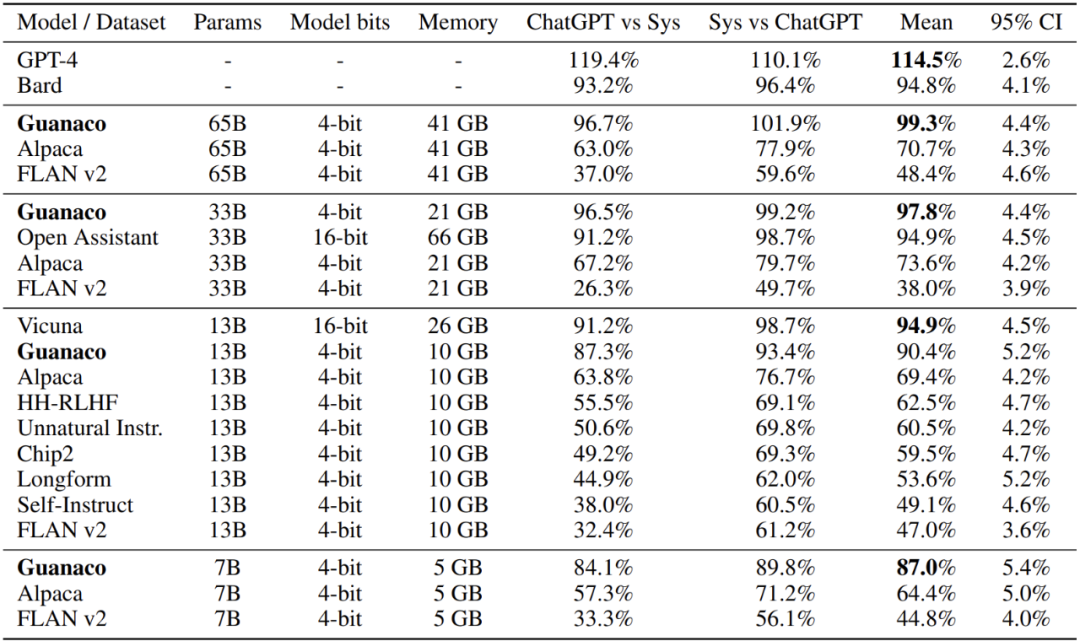
该研究发现 Guanaco 65B 是 GPT-4 之后性能最好的模型,可以实现 ChatGPT 99.3% 的性能水平。Guanaco 33B 的参数比 Vicuna 13B 模型要多,但其权重仅使用 4 位精度,因此内存使用效率更高,内存占用更少(21 GB VS 26 GB)。此外,Guanaco 7B 可轻松安装在 5 GB 内存的智能手机上。
总体而言,GPT-4 和人工注释者的系统级判断是适度一致的,因此基于模型的评估是人类评估的一种可靠替代方案。
在定性分析方面,如下表 7 所示,该研究发现与人类评分相比,GPT-4 为其自己的输出给出了更高的分数(Elo 为 1348 vs 1176)。未来该研究会进一步检查自动评估系统中是否存在潜在偏差,并提出可能的缓解策略。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com







