 来源:内容由半导体行业观察(ID:icbank)转载自公众号软硬件融合,谢谢。
来源:内容由半导体行业观察(ID:icbank)转载自公众号软硬件融合,谢谢。
ChatGPT的火爆,直接引爆了大模型的繁荣,也使得NVIDIA GPU供不应求。
从发展的角度看,GPU并不是大模型最高效的计算平台。
GPT等大模型为什么没有突破万亿参数?核心原因在于在现在的GPU平台上,性能和成本都达到了一个极限。想持续支撑万亿以上参数的更大的模型,需要让性能数量级提升,以及单位算力成本数量级的下降。这必然需要全新架构的AI计算平台。
本文抛砖引玉,期待行业更多的探讨。
大模型为什么“不约而同”的停留在上千亿的参数规模,没有突破万亿参数?原因主要在于,在目前的架构体系下:
单个GPU性能增长(Scale up)有限,想要增加性能,只有通过增加计算集群规模(Scale out)的方式;
上万GPU的计算集群,其东西向的流量交互指数级提升,受限于集群的网络带宽,约束了集群节点计算性能的发挥;
受阿姆达尔定律的约束,并行度无法无限扩展,增加集群规模的方式也到了瓶颈;
并且,如此大的集群规模,成本也变得不可承受。
总的来说,为了数量级的突破算力上限,需要从如下几个方面入手:
首先,性能提升不单单是单个芯片的事情,而是一个系统工程。因此,需要从芯片软硬件到整机再到数据中心全体系进行协同优化。
其次,扩大集群规模,也即大家熟知的Scale Out。要想Scale out,就需要增强集群的内联交互,也就是要更高的带宽,更高效的高性能网络。同时,还需要降低单个计算节点的成本。
最后,最本质的,Scale Up,增加单个节点的性能。这个是最本质的能够提升算力的方法。在功耗、工艺、成本等因素的约束下,要想提升性能,只能从软硬件架构和微架构实现方面去挖潜。
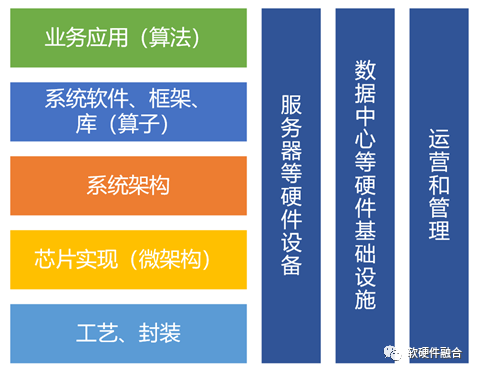
算力,不仅仅是微观芯片性能的事情,而是宏观上复杂而庞大的系统工程。整个体系中,从工艺到软件,从芯片到数据中心,整个算力体系中的各个领域的发展都已经达到一个相对稳定而成熟的阶段。而AI大模型的发展,仍然需要算力大踏步的提升,这不仅仅需要各领域按部就班的持续优化,更需要各个领域间的跨域协同优化创新:
半导体工艺和封装:更先进的工艺、3D集成,以及Chiplet封装等。
芯片实现(微架构):通过一些创新的设计实现,如存算一体、DSA架构设计以及各类新型存储等。
系统架构:比如开放精简的RISC-v,异构计算逐渐走向超异构计算,以及驾驭复杂计算的软硬件融合等。
系统软件、框架、库:基础的如OS、Hypervisor、容器,以及需要持续优化和开源开放的各类计算框架和库等。
业务应用(算法):业务场景算法优化、算法的并行性优化等;以及系统的灵活性和可编程性设计;系统的控制和管理、系统的扩展性等。
硬件,包括服务器、交换机等:多个功能芯片的板卡集成,定制板卡和服务器,服务器电源和散热优化;
数据中心基础设施:如绿色数据中心,液冷、PUE优化等;
数据中心运营和管理:如超大规模数据中心运营管理,跨数据中心运营和管理调度等。
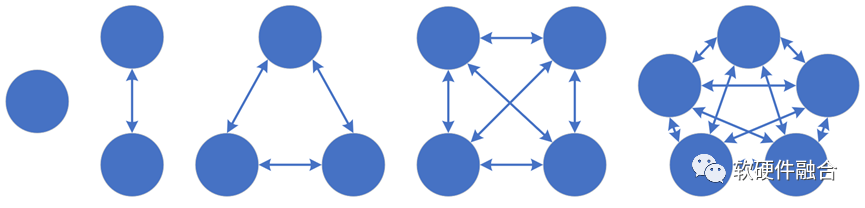
N个节点通过连线两两相连,总共的连线数据需要N*(N-1)/2。据此公式,集群如果只有一个节点,那就没有东西向的内部流量;随着集群中节点数量的增多,内部交互数量会飞速的增长,随之而来的,也就是集群内部的交互流量猛增。
据统计,目前在大型数据中心中的东西向网络流量占比超过85%;AI大模型训练集群,其节点数量基本上超过1000,其东西向流量估计超过90%。理论上,在各个连接流量均等的情况下,目前主流网卡200Gbps的带宽,即使所有都是东西向流量,每两个节点之间的流量也仅仅只能有200/1000 = 0.2 Gbps。一方面,南北向的流量被极限压缩,单个连接的东西向流量又随着集群数量的增长反而持续下降,这进一步凸显了网络带宽瓶颈的问题。
与此同时,受阿姆达尔定律的影响,整体算力并不是跟节点数量呈理想的线性关系,而是随着集群规模的增加,整体算力的增加会逐渐趋缓。
要想通过Scale Out方式提升集群的算力:

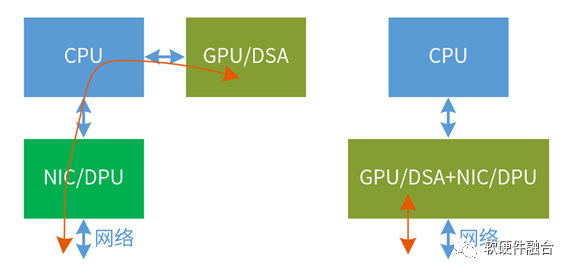
东西向流量本质上属于内部“损耗”,通过Scale Out的方式提升性能对网络的压力巨大,并且有性能上限,属于“治标不治本”的方式。
要想真正的大规模的提升算力,最本质最有效的办法,还是要通过提升单个计算节点、单个计算芯片性能的方式。
要想提升单芯片性能:
首先,是提升芯片规模。通过工艺进步、3D和Chiplet封装,提升单个芯片的设计规模。目前,主流的大芯片晶体管数量在500亿。Intel计划到2030年,会将单芯片晶体管数量提高到1万亿(提升20倍)。
第二,提升单位晶体管资源的性能效率。6个主要的处理器类型:CPU、协处理器、GPU、FPGA、DSA和ASIC,CPU最通用,但性能效率最低,而ASIC最专用,性能效率最高。在计算处理器方面,要尽可能选择ASIC或接近ASIC的计算引擎,尽可能的提升此类处理器在整个系统中的计算量占比。
第三,提升通用灵活性。性能和灵活性是一对矛盾,为什么不能在一个芯片里,完全100%的采用ASIC级别的计算引擎?原因在于,纯粹的ASIC没有意义。芯片需要得到大范围的使用,才能摊薄研发成本。这就需要考虑芯片的通用灵活性。
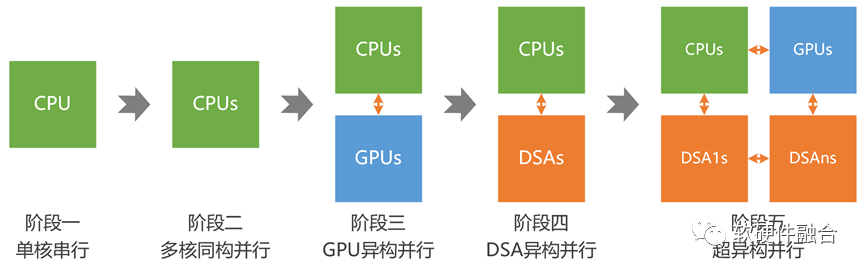
目前,受AI等各类大算力场景的驱动,异构计算已经成为计算架构的主流。未来,随着大模型等更高算力需求场景的进一步发展,计算架构需要从异构计算进一步走向超异构计算:
第一阶段,单CPU的串行计算;
第二阶段,多CPU的同构并行计算;
第三阶段,CPU+GPU的异构并行计算;
第四阶段,CPU+DSA的异构并行计算;
第五阶段,多种异构融合的超异构并行计算。
到目前为止,谷歌TPU都难言成功:虽然TPU可以做到,从芯片到框架,甚至到AI应用,谷歌可以做到全栈优化,但TPU仍然无法做到更大规模的落地,并且拖累了上层AI业务的发展。原因其实很简单:
当上层的业务逻辑和算法一直处于快速迭代的时候,是很难把它固化成电路来进行加速的。
虽然谷歌发明了Transformer,但受限于其底层芯片TPU,使得上层业务需要考虑跟底层芯片的兼容,无法全身心投入到模型开发;
AI模型的发展,目前仍在“炼丹”的发展阶段,谁能快速试错快速迭代,谁就最有可能成功。
也因此,在AI大模型的发展进程中,谷歌落后了。而OpenAI没有包袱,可以选择最优的计算平台(通用的GPU+CUDA平台),全身心专注到自己模型的研发,率先实现了ChatGPT及GPT4这样的高质量AI大模型,从而引领了AGI的大爆发时代。
结论:在目前AI算法快速演进的今天,通用性比性能重要。也因此,NVIDIA GPU通过在GPU中集成CUDA core和Tensor Core,既兼顾了通用性,又兼顾了灵活性,成为目前最佳的AI计算平台。
6.1 Intel Hawana GAUDI

Gaudi是一个典型的Tensor加速器。从第一代Gaudi的16nm工艺提升到第二代的7nm工艺,Gaudi2将训练和推理性能提升到一个全新的水平。它将AI定制Tensor处理器核心的数量从8个增加到24个,增加了对FP8的支持,并集成了一个媒体处理引擎,用于处理压缩媒体,以卸载主机子系统。Gaudi2的封装内存在每秒2.45 Tbps的带宽下增加了三倍,达到96GB的HBM2e。
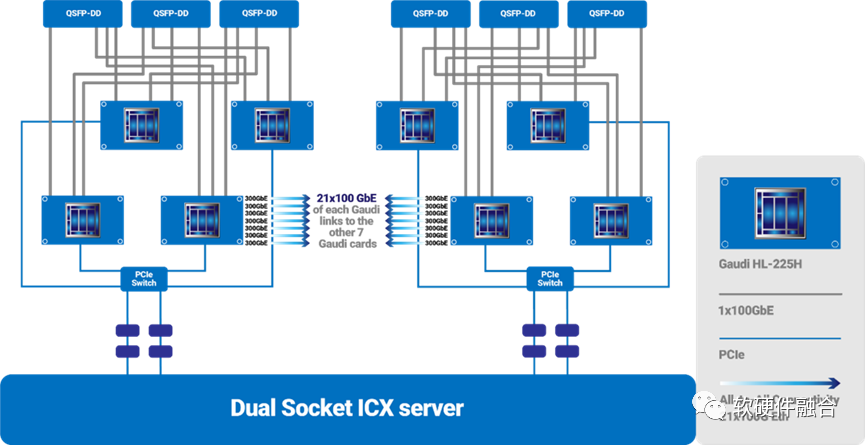
Gaudi可以通过24个100Gbps的RDMA高性能网卡实现非常高的集群扩展能力。实际的集群架构设计,可以根据具体的需求灵活设计。
相比传统的GPU、TPU等加速器,Gaudi的最大亮点在于集成了超高带宽的高性能网络。从而提升了集群节点间的东西向流量交互效率,也使得更大规模的集群设计成为可能。
6.2 Graphcore IPU
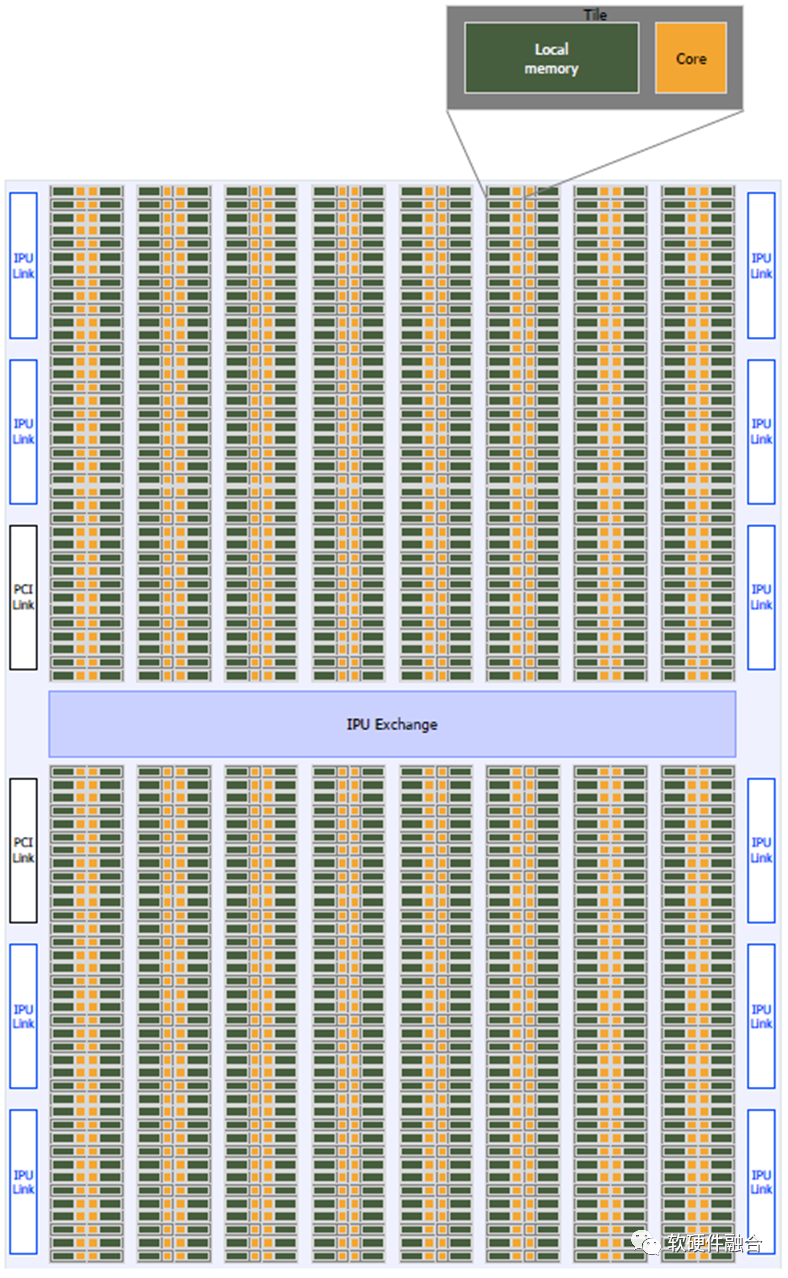
上图为Graphcore的IPU处理器,IPU处理器具有1216个Tile(每个Tile包含一个Core和它的本地内存),交换结构(一个片内互连),IPU链路接口用于连接到其他IPU,PCIe接口用于与主机连接。
Graphcore在架构上是类似NVIDIA GPU的产品,是相对通用的计算架构,比较符合AI计算的要求。但受限于没有类似Tensor core这样的协处理优化,在性能上存在劣势;以及还没有形成类似NVIDIA CUDA这样强大的开发框架和丰富生态。
6.3 Tesla DOJO
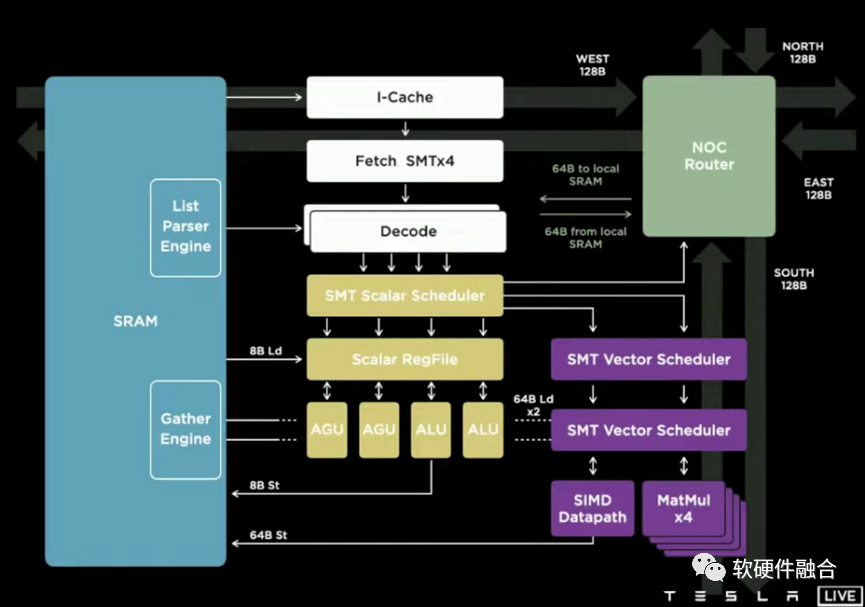
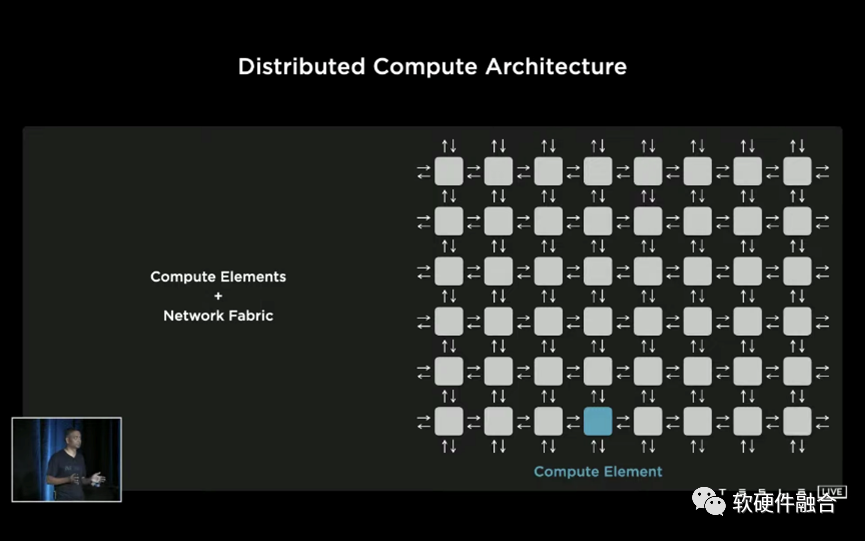
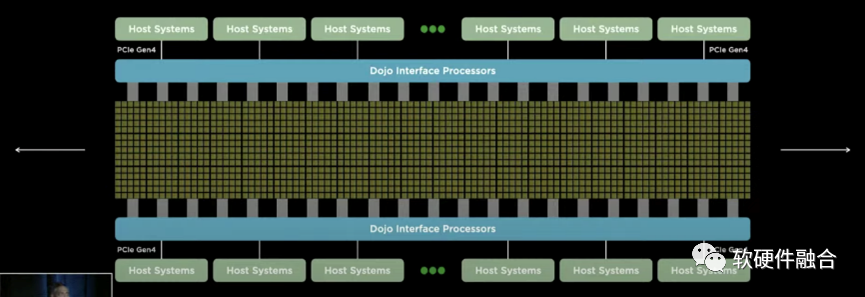
Tesla Dojo芯片和相应的整个集群系统,跟传统的设计理念有很大的不同。其基于整个POD级的超强的扩展性和全系统栈协同设计能力。Dojo系统的每个Node都是完全对称的,是一个POD级完全UMA的架构。或者说,Dojo的扩展性,跨过了芯片、Tile、Cabinet,达到了POD级别。
DOJO是Tesla专用于数据中心AI训练的芯片、集群和解决方案。DOJO的可扩展性能力,使得AI工程师可以专注在模型开发和训练本身,而较少考虑模型的分割和交互等跟硬件特性相关的细节。
DOJO也是比较通用的计算架构:内核是一个CPU+AI协处理器的做法,然后多核心组成芯片,芯片再组织成POD。宏观上,跟NVIDIA GPU的整体思路接近。
6.4 Tenstorrent Grayskull & Wormhole
Tesla Dojo和Tenstorrent的AI系列芯片都是Jim Keller主导的项目,架构设计理念有很多相似之处。
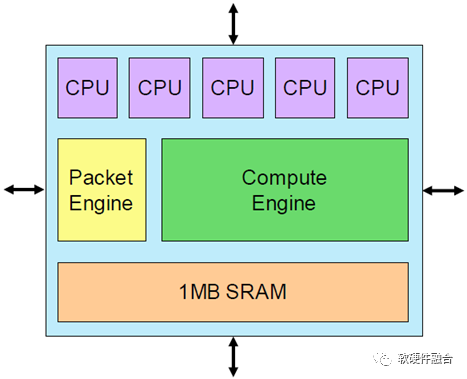
基本架构单元是Tensix核心,它围绕一个大型计算引擎构建,该引擎从单个密集数学单元承担3 TOPS计算的绝大部分。
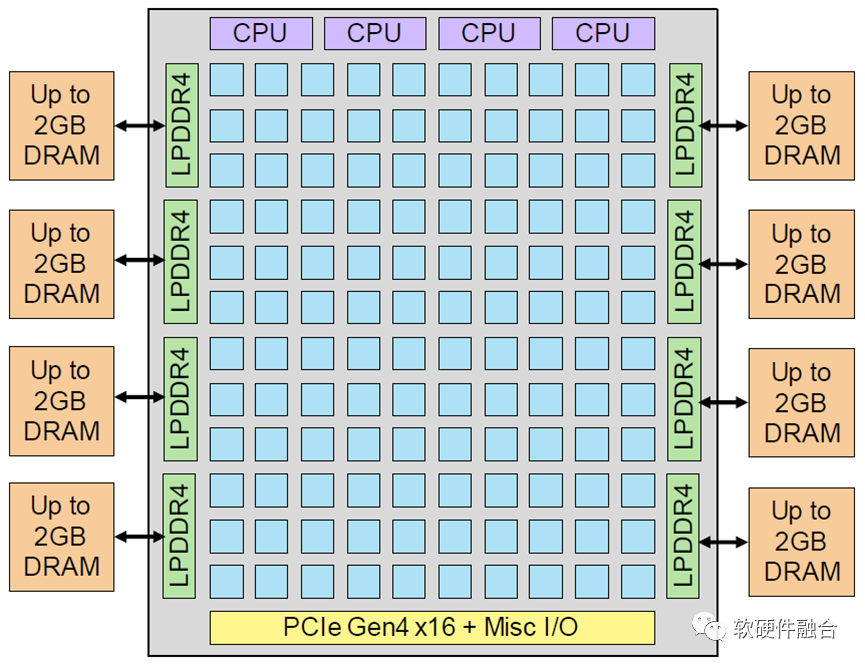
Tenstorrent的Grayskull加速器芯片实现了一个由Tensix内核组成12x10阵列,峰值性能为368 INT8 TOPS。
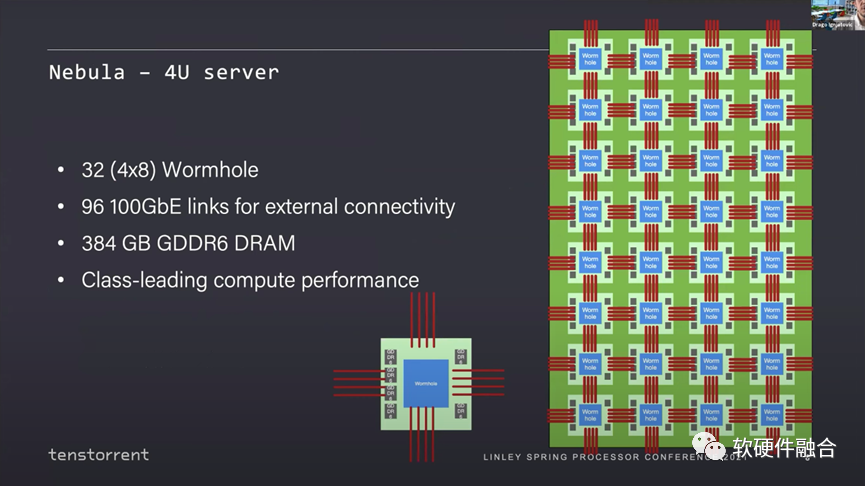
Tenstorrent的第一代芯片代号是Grayskull,第二代芯片代号是Wormhole,两者宏观架构接近。使用Wormhole模块,Tenstorrent设计了nebula(星云),一个4U服务器包含32个Wormhole芯片。
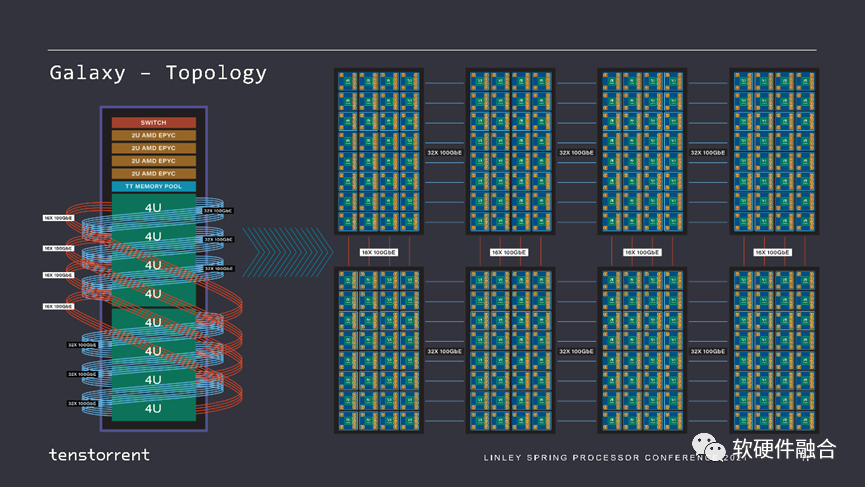
这是一个完整的48U的机架,它像一个2D网格一样,每个Wormhole服务器连接在另一个服务器的对等端,就像一个大而均匀的Mesh网络。
Tenstorrent通过这种多网络连接的方式,实现了集群的极致扩展性。其整体思路和Tesla DOJO类似。
(正文完)
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3416期内容,欢迎关注。
『半导体第一垂直媒体』
实时 专业 原创 深度
识别二维码,回复下方关键词,阅读更多
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装
回复 投稿,看《如何成为“半导体行业观察”的一员 》
回复 搜索,还能轻松找到其他你感兴趣的文章!









