1、表设计
1.1、数据库表最大程度遵守三范式
第一范式:数据库表中的字段都是单一属性的,不可再分;
第二范式:在第一范式基础上,除了主键以外的其它列都依赖于该主键;
第三范式:如果满足第二范式,并且除了主键以外的其它列都不传递依赖于主键列。
1.2、数据表和字段设计的原则
字段的命名要有意义;
字段选择的一般原则是保小不保大,能占用字节少的字段就不用大字段;
尽可能的使用 varchar/nvarchar 代替 char/nchar
尽量不使用 blob,还有将图片以二进制存到数据库
不用使用无法加索引的类型作为关键字段,比如text;
表中组合主键的字段个数越少越好,适当情况使用代理主键。
没有冗余的数据库未必是最好的数据库,适当的时候需降低范式标准;
1.3、根据应用场合选择表的存储引擎
数据表选择合适的引擎
MyISAM 特点
数据存储方式简单,使用 B+ Tree 进行索引使用三个文件定义一个表:.MYI、.MYD、.frm;
少碎片、支持大文件、能够进行索引压缩;
访问速度飞快,是所有MySQL文件引擎中速度最快的;
不支持一些数据库特性,比如 事务、外键约束等;
表级锁,性能稍差,更适合读取多的操作(查询和更新操作并行时,查询操作需等待更新操作结束);
表数据容量有限,一般建议单表数据量介于50w–200w;
增删查改以后要使用 myisamchk 检查优化表
InnoDB 特点
使用 Table Space 的方式来进行数据存储 (ibdata1, ib_logfile0);
支持事务、外键约束等数据库特性;
行级锁, 读写性能都非常优秀。(在默认“可重复读”事务隔离下,查询和更新操作并行时,查询操作不需等待) ;
能够承载大数据量的存储和访问;
拥有自己独立的缓冲池,能够缓存数据和索引;
在关闭自动提交的情况下,与MyISAM引擎速度差异不大
1.4、数据表的反范式化设计
降低范式标准至第二范式
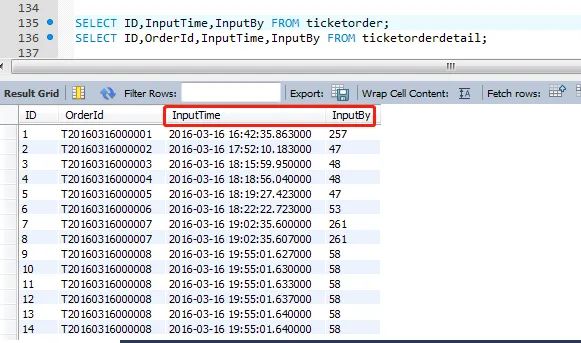
ticketorderdetail 中字段inputTime、inputBy等完全可以通过orderId外键关联 ticketorder表来获取到相应信息。这么设计:存在一定的冗余,主要目的是部分场景时,可以提前筛选或直接取值,而不用join链接。
2、常用优化方法
1、查询语句中不要使用 *
2、尽量减少子查询,使用关联查询(left join,right join,inner join)替代
3、减少使用IN或者NOT IN ,使用exists,not exists或者关联查询语句替代
4、or 的查询尽量用 union或者union all 代替 (在确认没有重复数据或者不用剔除重复数据时,union all会更好)
5、表关联时,关联前尽量过滤数据量,可以减少关联后的集合量级,提高查询速度
6、空间换取时间。增加中间表进行优化(这个主要是在统计报表的场景,后台开定时任务将数据先统计好,尽量不要在查询的时候去统计)
7、那些可以过滤掉最大数量记录的条件必须写在WHERE子句的最前面,(oracle则是末尾)
8、大量数据的更新操作,要尽量使用批量处理,而不能foreach一条一条处理。
9、分页查询优化。不需要查询全部数据时,用分页查询返回。
10、分页查询优化的优化。在数据量非常大的情况下,分页查询时,limit的效率将会非常低。此时应该考虑优化查询条件。(在Mongodb特别明显)
11、结合执行计划explain。
3、索引的创建和使用
3.1、什么是索引?

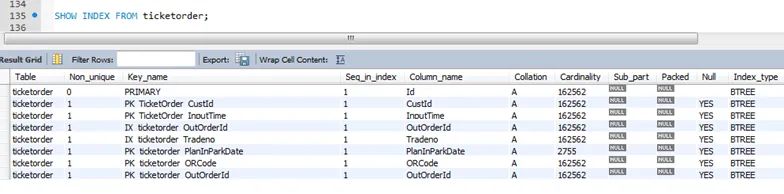
3.2、创建索引的好处
帮助用户提高查询速度;
利用索引的唯一性来控制记录的唯一性;
可以加速表与表之间的连接 ;
降低查询中分组和排序的时间
3.3、创建索引的坏处
存储索引占用磁盘空间;
执行数据修改操作(INSERT、UPDATE、DELETE)产生索引维护
索引创建的总体原则
在了解表的具体应用场景基础上建立索引;
为所有主键和外键列建立索引;
对出现在WHERE子句、JOIN子句、ORDER BY或GROUP BY子句中的列考虑建立索引;
对需要确保唯一性的列考虑建立索引;
对于WHERE子句中用AND连接并频繁使用的列使用组合索引,最频繁的列放在最左边;
数据更新频繁的列不宜建立索引;
数据量较小的表也不宜建立索引
3.4、Explain中type类型

3.5.1、索引的正确使用(一)
去除查询条件左端的任何标量函数或计算
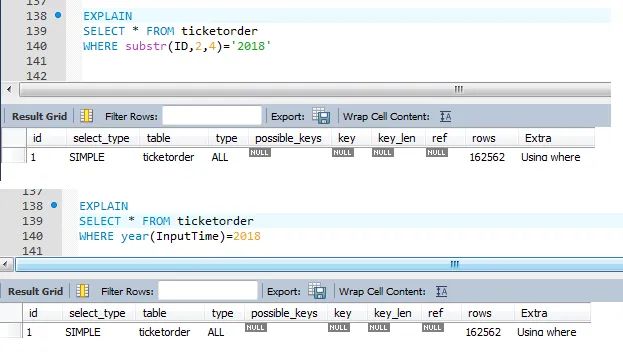
3.5.2、索引的正确使用(二)
确保宿主变量定义与列数据类型匹配
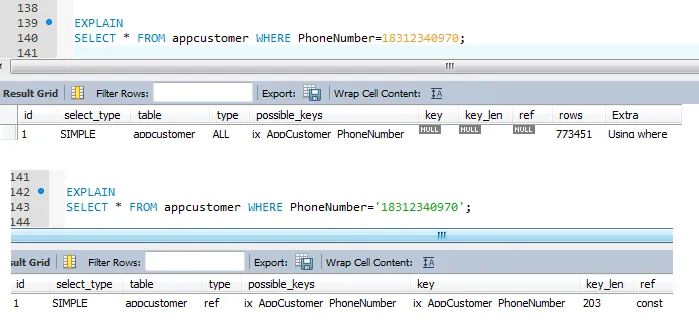
3.5.3、索引的正确使用(三)
查询条件中使用like时避免宿主变量以‘%’开头
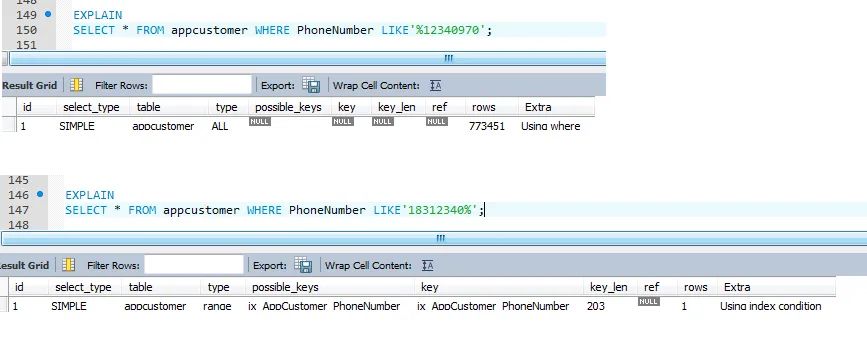
3.5.4、索引的正确使用(四)
避免使用“or” ,采用其它方式重写
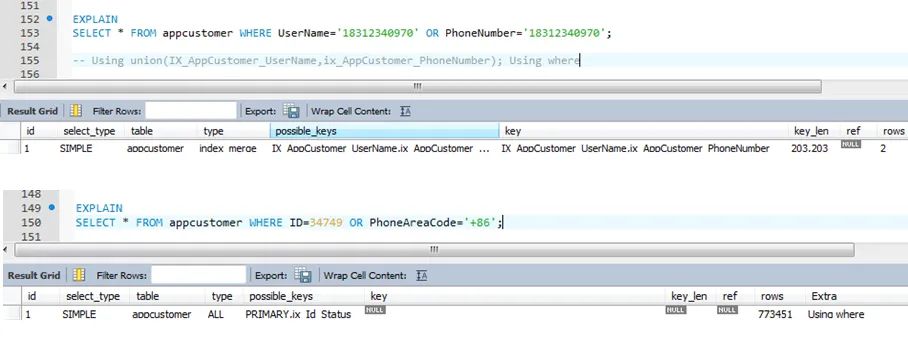
3.5.5、索引的正确使用(五)
使用组合索引时,应注意“最左前缀”基本原则
最左前缀:就是最左优先,我们创建了lname、fname和age的多列索引,相当于创建了lname单列索引,(lname,fname)的组合索引以及(lname,fname,age)组合索引;
SELECT `uid` FROM people WHERE `fname`=‘Zhiqun’ AND `age`=26上述查询语句因违法“最左前缀”原则,系统通常会扫描整表以匹配数据!
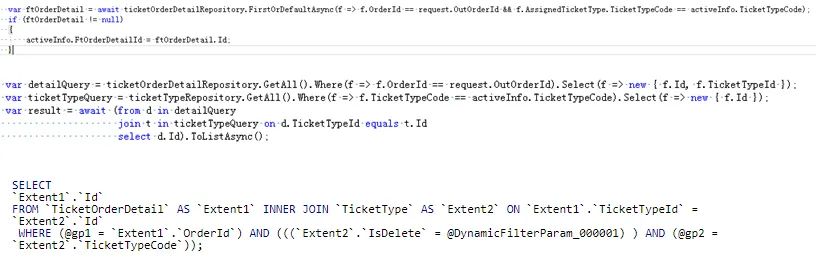
4、EF框架查询优化
4.1、避免使用Select *
一些必填的字符串,应该在实体类上加上[Required]
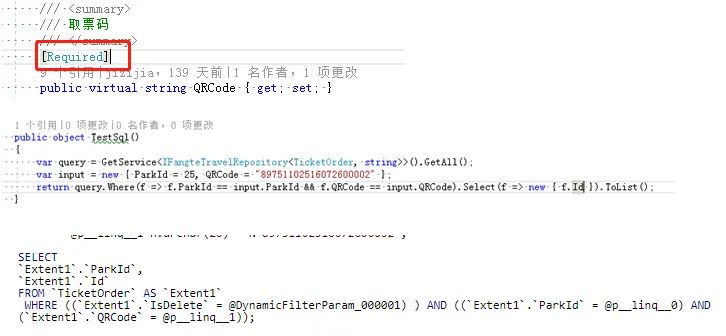
4.2、表关联优化