近年来,大数据、人工智能等热门关键字多次被写入中央文件与国务院政府工作报告,目前已上升为国家战略,并将深刻地改变现有行业的游戏规则。金融行业是当今大数据、人工智能应用最广、最深的领域之一。随着数据仓库和数据科学的发展,金融行业中的企业(如银行、基金公司、保险公司、互联网电商企业等)拥有了海量数据,应运而生了金融领域的大数据分析、智能风控等大数据和人工智能的应用。而信用评分则是大数据分析在金融领域最早、最成功的应用。当银行等信贷机构面对着海量客户时,如果没有准确而且自动化的风险评估工具,信贷机构就不可能放出那么多贷款并进行有效的管理,我们的生活也不可能像今天这么便利。信用评分是在信贷场景中辅助银行等信贷机构发放贷款的一整套决策支持技术,这些技术将决定谁或哪些公司将会获得贷款、贷款的多少、利息的高低,以及设定哪些合适的经营策略来提高业务利润率。去商场购物刷信用卡、京东白条、蚂蚁花呗日常消费等等,这些背后都是涉及到信贷机构对我们的信用评分,可以说信用评分影响着我们每个人的生活,与我们息息相关,无处不在。Python作为一种科学语言,随着人工智能的兴起其流行程度急剧上升。它最早是由荷兰人Guido van Rossum于1989年在圣诞节期间设计的,其设计理念是“优雅”、“明确”、“简 单”。正是基于这一理念,Python语言具有结构简单、语法清晰、易于学习、可移植性和可扩展性强等特点。目前,Python拥有丰富的数据分析库和机器学习(即人工智能算法)库,成为数据科学领域的不二之选。本案例是基于Python语言开发的信用评分卡,向读者展示了这些前沿技术在金融领域中的应用。 信贷业务,又称贷款业务,是商业银行等信贷机构最重要的资产业务和主要赢利手段。
机构通过放款收回本金和利息,扣除成本后获得利润。对有贷款需求的用户,信贷机构首先要对其未来的还款表现进行预测,然后将本金借贷给还款概率大的用户。但这种借贷关系,可能发生信贷机构(通常是银行)无法收回所欠本金和利息而导致现金流中断和回款成本增加的可能性风险,这就是信用风险,它是金融风险的主要类型。 在信贷管理领域,关于客户信用风险的预测,目前使用最普遍的工具为信用评分卡,它源于20世纪的银行与信用卡中心。在最开始的审批过程中,用户的信用等级由银行聘用的专家进行主观评判。而随着数据分析工具的发展、量化手段的进步,各大银行机构逐渐使用统计模型将专家的评判标准转化为评分卡模型。如今,风险量化手段早已不局限于银行等传统借贷机构,持牌互联网公司的金融部门、持牌消费金融公司等均有成体系的风险量化手段。其应用的范围包括进件、贷后管理及催收等。信用评分不但可以筛选高风险客户,减少损失发生,也可以找出相对优质的客户群,发掘潜在商机。 顾名思义,评分卡是一张有分数刻度和相应阈值的表。对于任何一个用户,总能根据其信息找到对应的分数。将不同类别的分数进行汇总,就可以得到用户的总分数。信用评分卡,即专门用来评估用户信用的一张刻度表,这里我们举一个简单的例子:假设我们有一个评分卡,包含四个变量(特征),即居住条件、年龄、贷款目的和现址居住时长(见表2- 1)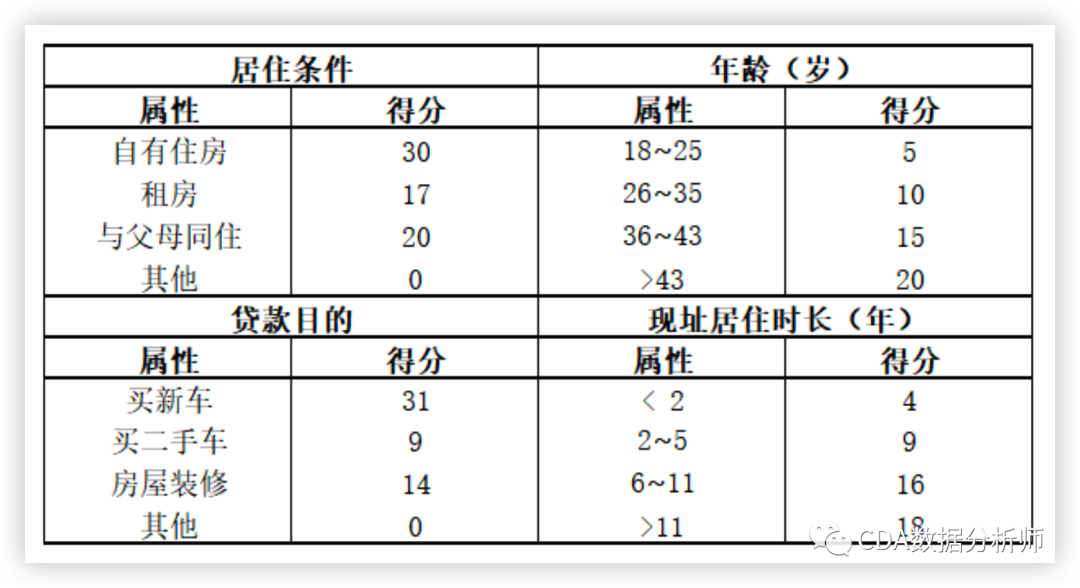
表2-1 简单评分卡
用表2-1这张简单的评分卡,我们能轻而易举地计算得分。一个47岁、租房、在当前住址住了10年、想借钱度假的申请者得到53分(20+17+16+0=53),另一个25岁、有自己的房产、在当前住址住了2年、想借钱买二手车的人也同样得到53分(5+30+9+9=53)。同样地,一个38岁、与父母同住、在当前住址住了18个月、想借钱装修的人也得到53分 (15+20+4+14=53)。事实上,我们一共有七个组合可以得到53分,他们虽然各自情况都不一样,但对贷款机构来说代表了同样的风险水平。该评分系统采用了补偿机制,即借款人的缺点可以用优点去弥补。 总的来说,信用评分卡就是通过用数据对客户还款能力和还款意愿进行定量评估的系统。从20世纪发展至今,其种类已非常多,目前应用最广泛最多的主要分为以下四种:申请评分卡(ApplicationCard):申请评分卡通常用于贷前客户的进件审批。在没有历史平台表现的客群中,外部征信数据及用户的资产质量数据通常是影响客户申请评分的主要因素。行为评分卡(BehaviorCard):行为评分卡用于贷中客户的升降额度管理,主要目的是预测客户的动态风险。由于客户在平台上已有历史数据,通常客户在该平台的历史表现对行为评分卡的影响最大。催收评分卡(CollectionCard):催收评分卡一般用于贷后管理,主要使用催收记录作为数据进行建模。通过催收评分对用户制定不同的贷后管理策略,从而实现催收人员的合理配置。反欺诈评分卡(Anti-fraudCard):反欺诈评分卡通常用于贷前新客户可能存在的欺诈行为的预测管理,适用于个人和机构融资主体。 其中前三种就是我们俗称的“ABC”卡。A卡一般可做贷款0-1年的信用分析;B卡则是在申请人一定行为后,有了较大消费行为数据后的分析,一般为3-5年;C卡则对数据要求更大,需加入催收后客户反应等属性数据。 四种评分卡中,最重要的就是申请评分卡,目的是把风险控制在贷前的状态;也就是减少交易对手未能履行约定契约中的义务而造成经济损失的风险。违约风险包括了个人违约、公司违约、主权违约,本案例只讲个人违约。账龄(Month Of Book,MOB):资产放款月份。MOB0表示放款日至当月月底,MOB1表示放款后第一个完整的月份,MOB2表示放款后第二个完整的月份。其最大值取决于当前产品的周期,如12期产品最多存在MOB12,24期产品最多存在MOB24。逾期天数 (Days Past Due, DPD):已逾契约书约定缴款日的延滞天数。贷放型产品自到期当天开始计算,如DPD0为到期当日,DPD1为逾期一日,DPD7为逾期一周。逾期期数(Bucket)
:逾期的月份数。逾期1个月记为M1,逾期2个月为M2,逾期3个月以上可以记作M3+。逾期阶段(Stage):分为前期、中期、后期和转呆账。一般将M1(1~29)列为前期,M2~M3(30~89)列为中期,M4(90+)以上列为后期,已转呆账者则列入转呆账。呆账:是指已过偿付期限,经催讨尚不能收回,长期处于呆滞状态。2. 时间窗口设计
时间窗口分为表现窗口和观测窗口,表现窗口中的时间称为表现期,观察窗口中的时间称为观察期。如图2-1所示。
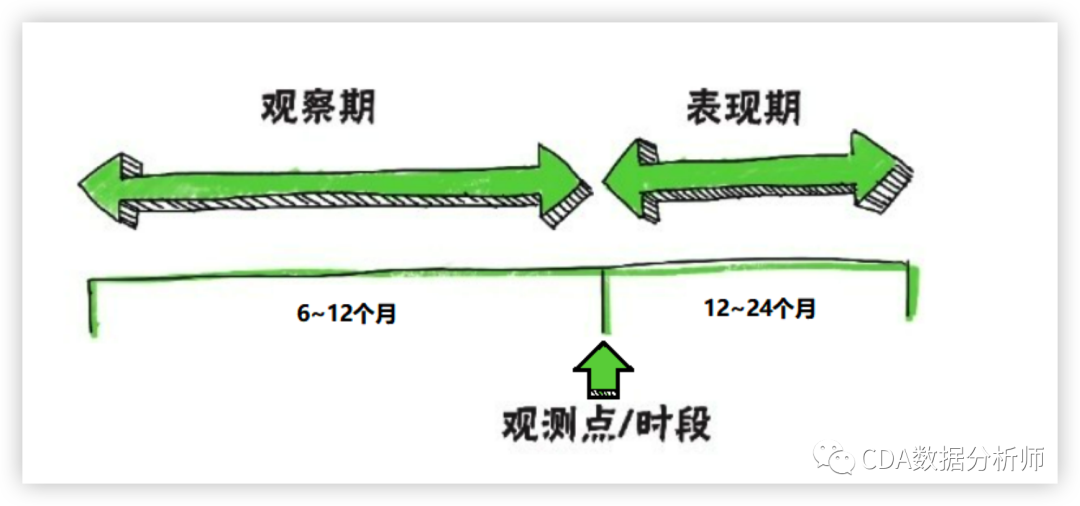
图2-1 观察期与表现期
其中,观察期,即为变量计算的历史期间,比如,有一变量为“近6个月延滞一期以上的次数”,其观察期即等于6个月。观察期设定太长,可能无法反映近期状况,设定太短则稳定性不高,因此多半为6~24个月。表现期则是准备预测的时间长度。例如,若欲预测客户未来12个月内出现违约的概率,则表现期等于12个月。依各种产品特性不同,表现期也可能不同,通常设定为12~24个月。评分模型的任务在于区隔好坏客户(Good/Bad Account),因此,必须定义违约(Bad)的条件,这些条件并不限定为逾期,只要银行认定此情况为“非目标客户”。例如,未来一年内出现M2以上逾期、催收、呆账、强停、拒往和协商等,皆可作为评分模型中的违约条件。 我们要制作评分卡,最终想要得到的结果是要给各个特征进⾏分档,以便业务⼈员能够根据新客户填写的信息为客户打分。我们知道变量(即特征)的形态可分为离散型和连续型,离散型天然就是分档的,因此,我们需要重点如何使连续变量分档,即连续变量离散化。 连续变量离散化,我们也常称为分箱或者分组操作。它是评分卡制作过程中⼀个非常重要的步骤,是评分卡最难,也是最核⼼的思路。目的就是使拥有不同属性的客户被分成不同的类别,进而评上不同的分数。在评分卡建模流程中,我们常用WOE(Weight of Evidence,迹象权数)方法对变量进行分箱。用与之相关的另一个重要概念,IV值 (Information Value,信息值)则用来衡量该变量(特征)对好坏客户的预测能力。避免变量值中出现极端值(Outliers)的情形,减少模型过度配适(Overfitting)的现象。下面我们以某数据集中“年收入”变量为例,计算其对应WOE值和IV值,见表2-2。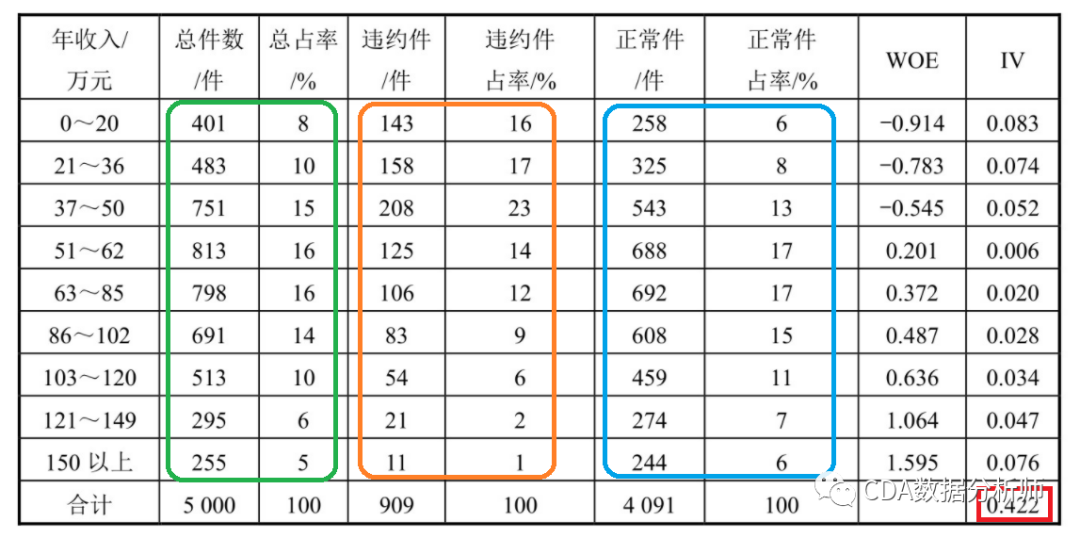
表2-2 WOE和IV值的计算
表2-2首先对“年收入”变量排序,然后依变量值大小切分较细的组别(Fine Classing)。分组的原则为:组间差异⼤:每个箱⼦之间需要有差异性,保证不同档位评分的差异性;组内差异⼩:每个箱⼦内部的⼈群的相似性程度⾜够⼤;WOE (Weight Of Evidence),计算公式为
IV值(Information Value),计算公式为

其中, 表示数据的分组数。注意,IV值与变量对应,即每个变量对应一个IV值。而不是像WOE那样和分组对应。 结合表2-2中数据,我们来计算其对应的WOE和IV值。首先,最重要的是计算每个分组中“违约件占比”和“正常件占比”。其中,“违约件占比”等于该组中对应的“违约件/总的违约件”;“正常件占比”等于该组中对应的“正常件/总的正常件”。以表中第一组“0~20”为例,违约件占比=143/909=16%,正常件占比=258/4091=6%,其他组类似。然后根据WOE的计算公式计算出每个分组对应的WOE值。最后再根据计算的WOE值,计算右下角红框圈出的IV 值=0.422,即该数据中,“年收入”变量对应的IV值为0.422。 表2-3展示了IV值常用的判断标准。由此可知,表2-2中,“年收入”变量对于区别好坏客户的具有良好的预测能力。
表2-3 IV值的判断标准
实际中,为了提高IV值,常常需要调整合并WOE相近的组别,最后得到的分组结果称为粗分类(Coarse Classing)。当所有变量的IV值都计算完成后,即可从中挑选变量,优先排除高度相关、趋势异常、解释不易及容易偏移者。由此可见,IV值也是模型变量筛选的一种方法。 最后,关于OWE和IV值还有如下几点需要补充说明的地方:- 根据定义,违约件占比高于正常件占比时,WOE为负数。WOE绝对值越 高,表示该组别好坏客户的区隔程度越高。各组之间WOE值差距应尽可 能拉开并呈现由低至高的合理趋势。
- 需要指出的是,变量在进行WOE分箱后,常常用WOE值来取代原来的变 量值作为特征投入模型训练,因此,WOE分箱也可以称作WOE特征变 换。
- 信息值可用来表示变量预测能力的强度。因此,可以协助模型开发人员了 解各变量对于目标事件的单一预测能力的高低,借以挑选出高预测能力的 变量进行开发。
由于篇幅太长,明日更新第二部内容