对于采用ChatGPT,通过自然语言编程进行功能开发是我一直在摸索和尝试的一个事情。在前面也专门验证了包括办公自动化,运维自动化,网页爬虫,视频字幕抓取等各种场景。
而自己最想做的还是传统的Web应用的开发能否完全通过自然语言编程来实现。在前面个人尝试了采用Springboot+VUE框架来开发一个web应用功能。但是仍然是感觉整体框架偏重,涉及到的各种分层和各类配置文件太多,通过自然语言编程去开发相对来说比较繁琐。
也正是这个原因,个人给出了自然语言开发框架和平台选择上最好能够满足如下要求和约束,具体为:
开发框架要足够简单,不要复制的分层
要体现API接口驱动,通过API接口前后端解耦
要通过最简的Controller来实现页面和逻辑层联动
当具备API接口驱动的时候,我们可以将复杂功能的实现分解为前端场景和后端能力。即先去梳理业务场景拆解出具体的能力库。然后通过自然语言编程来生成各个API接口提供这些能力。接着再完整描述业务场景,告诉GPT如何去组装这些能力实现完整的业务功能。
基于以上思考,我在前面画了一个简图进行说明:
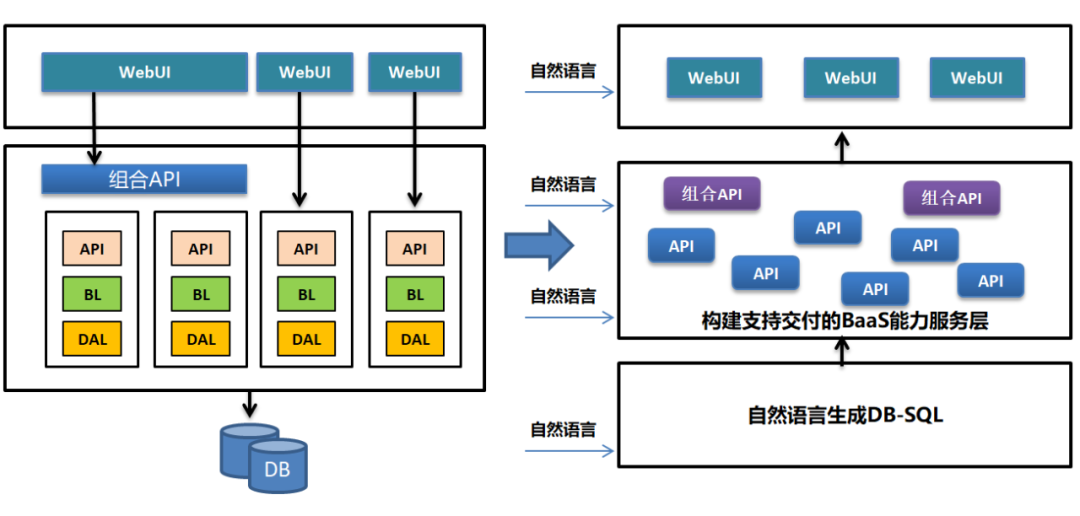
该思路和微服务,API接口驱动,前后端分离的思考基本一致。但是并不需要类似DDD领域建模一样的复杂领域层构建。同时开发框架应该足够简单,开发分层尽可能简化。
也正是这个原因我一直提到类似云原生里面的ServerLess无服务化编程和这个思路相对类似。即一个完整的应用的生成,它的核心就是生成相应的BaaS后端能力和FaaS前端函数,同时完成前后端的能力组装。
在最近的一周我尝试对阿里云的函数计算FC,腾讯云的ServerLess应用开发进行了尝试。当时整体感觉各家公有云厂商对自己的云函数和开发框架,流程,标准规范都进行了额外的封装。GPT自然语言生成的代码很难做到不修改就马上使用。
在后续的选型验证中,发现基于Python+Flask框架,并结合GPT来实现自然语言编程是一个比较好的选择。即Flask框架完全满足我前面谈的开发框架简单,体现API接口驱动,前后端分离又通过Controller和Route实现高效协同。
1. 第一次验证,精细化提示语
在第一次验证中,我希望基于API接口驱动分层,来实现一个用户登录功能,同时在登录成功后跳转到国家信息动态查询功能上面。在数据库提前创建了country数据表和userinfo数据库表。
整个验证我进行了拆分
先实现一个不连接数据库的最简单登录功能。
再实现访问user表的登录用户校验。
最后实现登录成功后跳转到国家信息动态查询功能。
为了实现以上操作,我构建了如下的提示语:
01
我准备用python语言flask框架开发一个登录界面,该登录界面包括username用户名和password密码两个输入框,一个登录按钮。
具体的要求和规则如下:
1.当username=111 and password=222的时候提升用户登录成功,转到一个登录成功的提示页面。
2.当不满足条件1的时候提示用户,用户信息校验不通过,直接在该页面提示不跳转。
3.注意代码文件要有登录异常处理功能。
请帮我生成实现该功能的源代码文件,注意登录页面放在网页上下居中的位置,同时搭配一个当前主流的商用系统的csss界面风格进行美化。
02
请帮我生成一个独立的log_valid方法,具体的要求如下。
1. 该方法的输入参数和username,password两个参数。输出参数为flag,memo两个参数。
2. 该方法需要访问mysql数据库world这个shema下的userinfo表进行校验,该表有username和password两个字段和两个输入参数对应。
具体规则为
2.1 如果用户名和密码能够匹配,则flag返回 pass,memo返回校验通过。
2.2 如果用户名匹配,但是密码不匹配。则flag返回 unpass,memo返回密码校验
3. 采用mysql connector来实现数据访问连接。
接着对登录方法进行改写:
好的,请对前面的登录功能进行改写,即当用户点击登录按钮的时候执行如下操作步骤。
1. 获取到用户在登录界面输入的username和password信息。
2. 基于这两个输入信息作为输入参数,去调用log_valid.py文件中的log_valid方法,获取flag和memo两个返回值。
3 如果获取的flag=unpass,则不用跳转界面,直接将返回的memo信息作为提示信息返回给用户。
4. 如果获取的flag =pass,则跳转重定向到一个新的界面,提升用户登录成功。
请基于以上需求描述,对登录功能进行改写,并提供改写后的源代码文件给我。
第三次验证
请帮我生成一个独立的country_qry.py文件,里面包括了名叫country_qry的方法。
该方法的主要是对mysql的一个叫country的数据库表进行数据模糊查询。
该数据库表包括Code,Name,Continent,Region,SurfaceArea,GNP,LocalName这些字段信息。
具体方法实现要求如下。
1. 该方法实现对country表数据的模糊查询,因此方法有三个输入参数,可以基于Code,Name,Region三个信息进行模糊查询。
2. 对于上面的三个查询条件均采用like进行前后模糊查询。注意如果输入参数值为空,则忽略掉这个查询条件。如果多个参数都有值,则是需要按 and 查询条件进行拼接。
3. 该方法返回一个json的查询结果数据集,包括返回Code,Name,Continent,SurfaceArea,GNP,LocalName这些字段信息
4. 数据库为mysql数据库,本地数据库127.0.01可以连接,对应schema为world,对应的数据库表为country。
现在我需要对login.py文件源代码进行扩展。
即实现一个对country国家信息的模糊查询功能界面,该功能具体要求如下。
1. 提供一个独立的国家信息查询功能界面,查询条件为Code,Name,Region。三个独立的文本框进行输入。
2. 提供一个查询按钮
3. 提供一个查询结果表格信息。
4. 点击查询按钮的时候需要调用上面country_qry.py文件中的country_qry方法实现查询
4.1 Code,Name,Region三个文本框的输入和country_qry方法的三个输入参数对应。
4.2 返回的结果集需要你自己处理最终绑定到查询界面的表格上。
注意实现该功能的路由和方法均命名为country。
同时你需要对原来的登录按钮逻辑进行修改。
即当登录成功的时候原来是跳转到succress.html页面,现在是登录成功后需要直接跳转到上面的查询功能界面。注意查询功能html页面搭配一个当前主流的商用系统的csss界面风格进行美化。
请帮我们生产修改后的login.py文件,已经查询功能的html文件。
当有了上面的提示语后,GPT会帮我生成各个源代码文件和html文件。将这些文件在pycharm里面新建一个项目,并将源代码文件拷贝进去。最终可以成功编译运行。
整个过程中基本没有对代码做任何修改。
2. 第二次验证,最简提示语
在我给出上述的整体实现之后,可以看到整个提示语编写工作量仍然很大。那么是否可以精简提示语,让GPT自己去理解语义,自己去规划各个源代码文件并给出完整实现。
在第二次验证中,我们基于数据库对象驱动的思路。一开始不提前创建数据库,而是给出需求让GPT自动帮我们生成创建数据库的脚本,并帮我们生成30条测试数据。
具体的提示语如下:
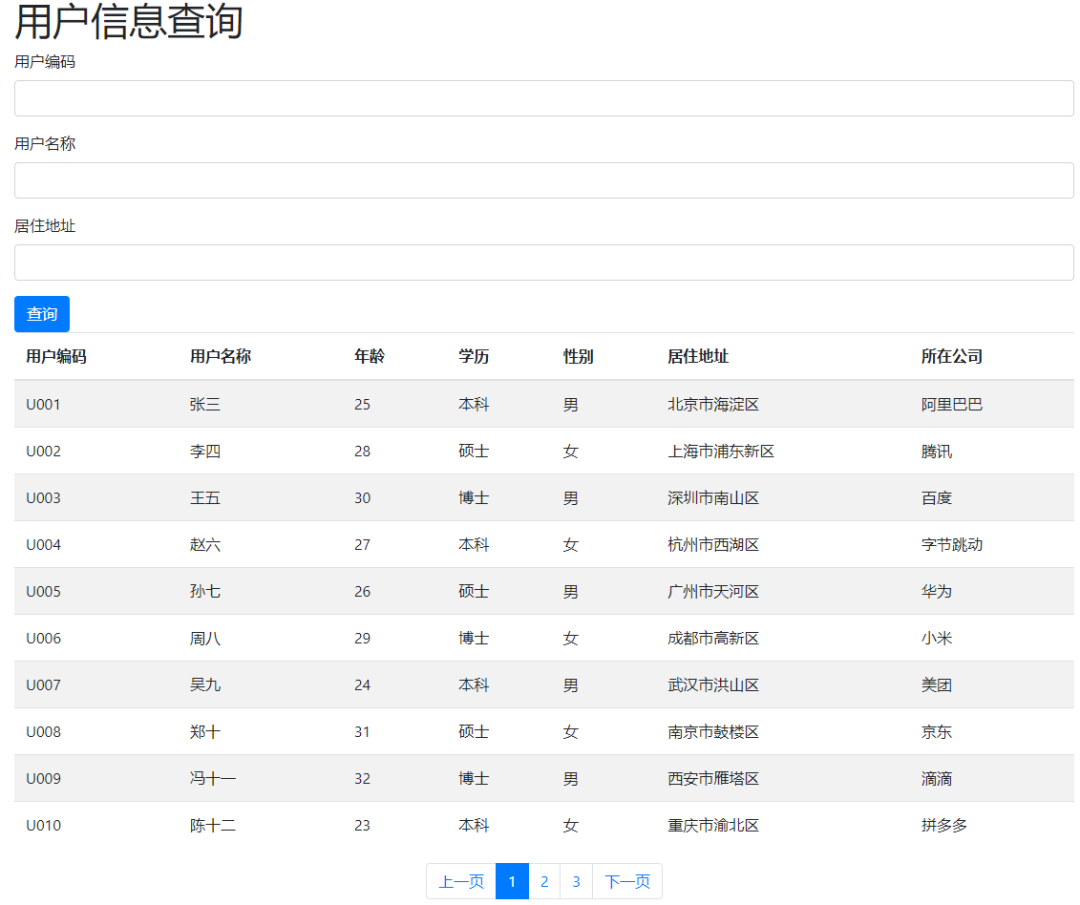
我现在有一个用户信息表,包括了用户id,用户编码,用户名称,年龄,学历,性别,居住地址,所在公司这些字段。请帮我生成一个创建该表的数据库sql脚本,同时提供插入10条测试数据的sql脚本。数据库为mysql数据库。
在数据库创建完成后,我们给出最简提示语来生成动态查询功能。那么简化后的提示语如下:
好的,请基于你上面创建的user_info 用户表,用python+flask框架来实现一个模糊查询的web功能,具体规则如下:
1. mysql数据库为本地数据库127.0.01可以连接,对应schema为world。账号为root账号,密码为 ******。
2. 查询条件用户编码,用户名称,居住地址地址,三个条件要支持模糊查询,均为文本框。
3. 查询结果线上除了id,用户id以外的所有字段,列表显示。
4. 查询要支持分页,每页只显示10条数据。
5. 要注意代码文件的拆分,查询能力的实现不要都体现在主文件里面。
请规划好具体需要哪些源代码文件和html文件,并生成所有的
当有了上述的提示语规划后,GPT会帮我们生成各个分层文件,包括文件详细的源代码。
在这里我通过NewBing的GPT4能力进行测试和验证。
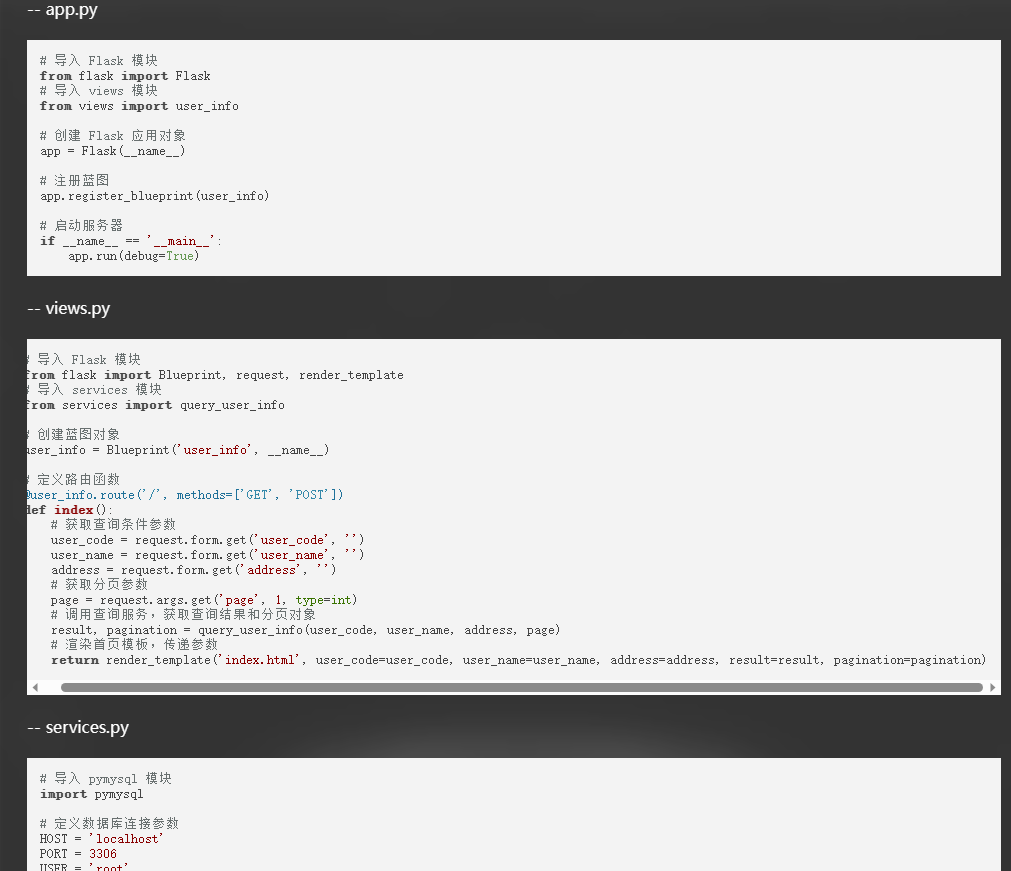
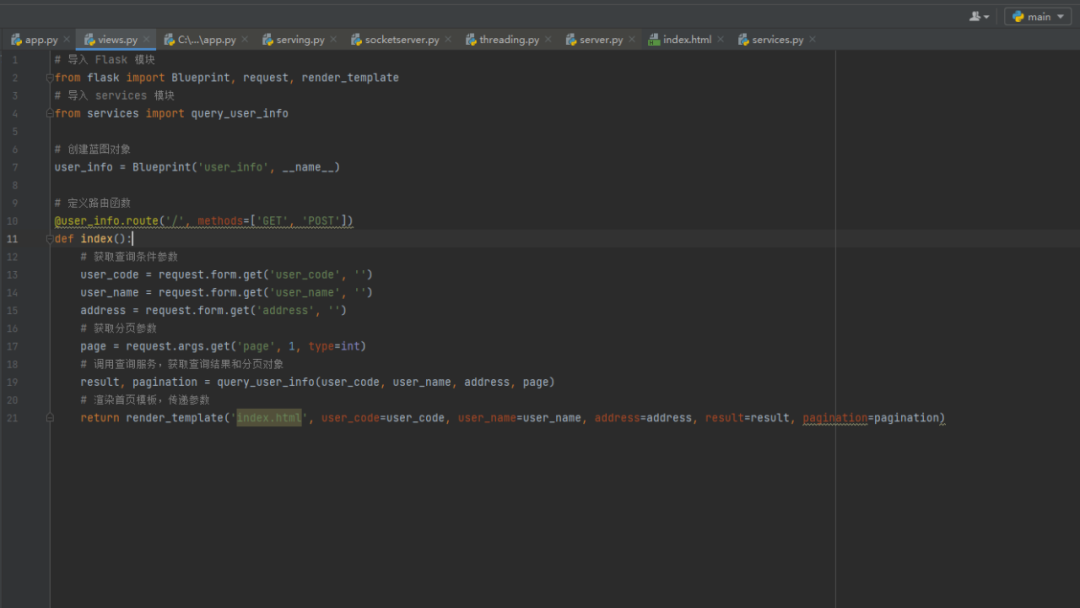
最终生成的代码一次验证通过,我未作任何代码修改跳转。
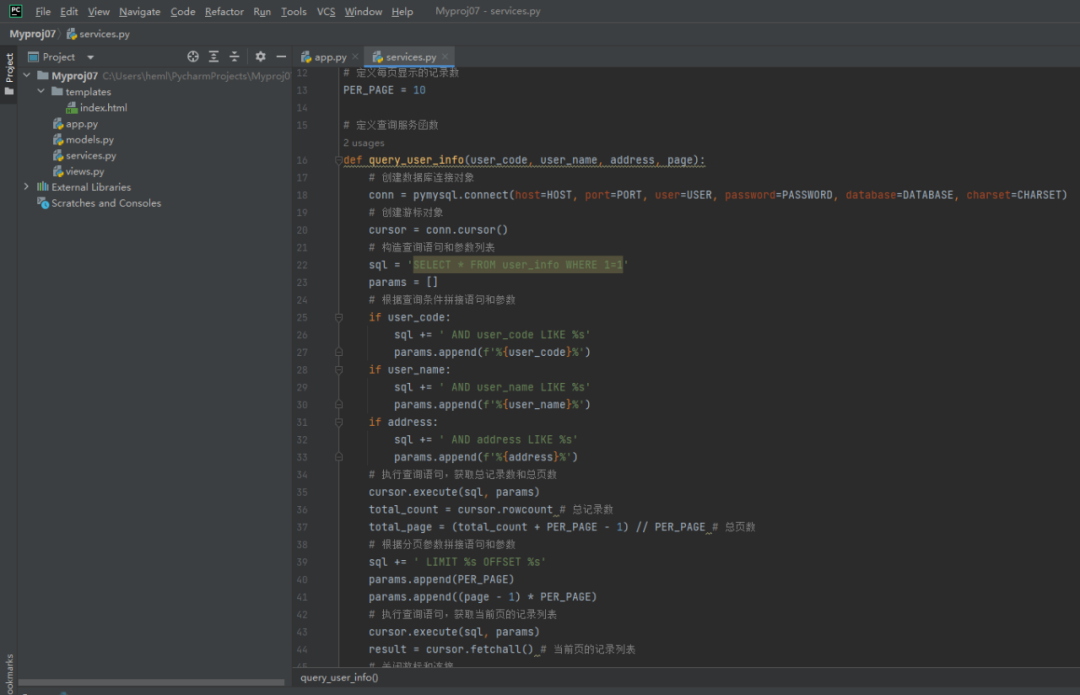
最终实现的界面效果如下:
虽然整个验证的场景相对来说比较简单。
但是基本可以看到GPT已经具备常见的低代码平台的基础能力。同时又具备对低代码平台不具备的各种复杂规则逻辑的编程能力。我们需要做的就是将复杂规则拆分为独立的API接口生成,并在前端场景中进行调用。
下一步需要继续验证的是让GPT能够学习公共组件库,通过强制提示语告知哪些地方需要调用公共基础组件库的能力。而对于前端Web页面展现则需要训练GPT能够了解当前项目标准的UI开发框架和规范,能够生成出符合当前规范的前端页面展示。









