
官网地址:http://ggml.ai
Github地址:https://github.com/ggerganov/ggml
Examples
Short voice command detection on a Raspberry Pi 4 using whisper.cpp
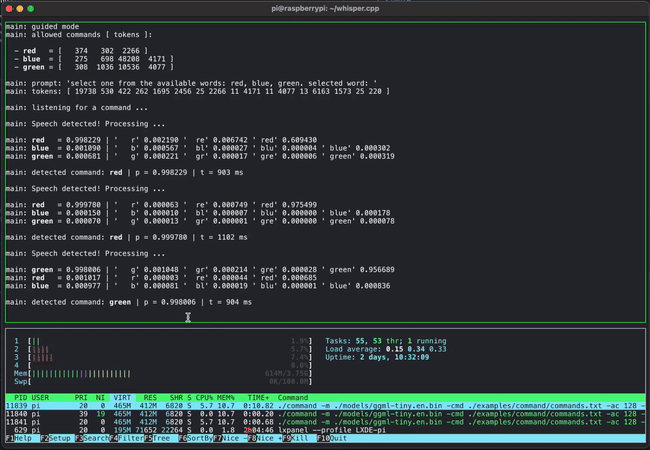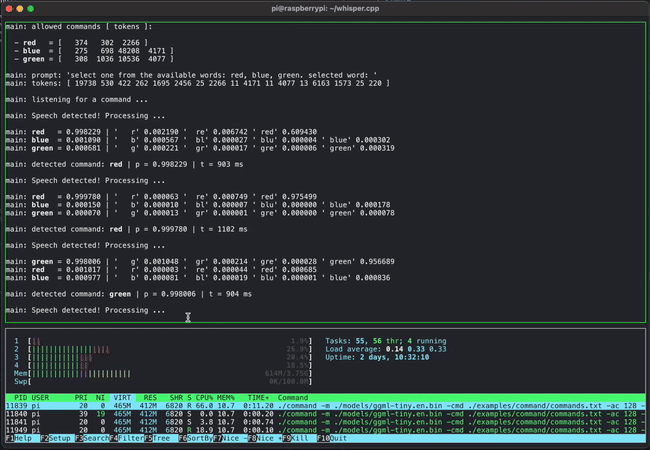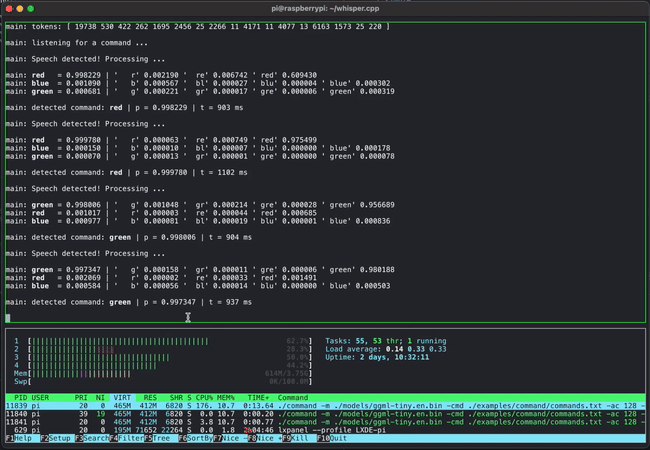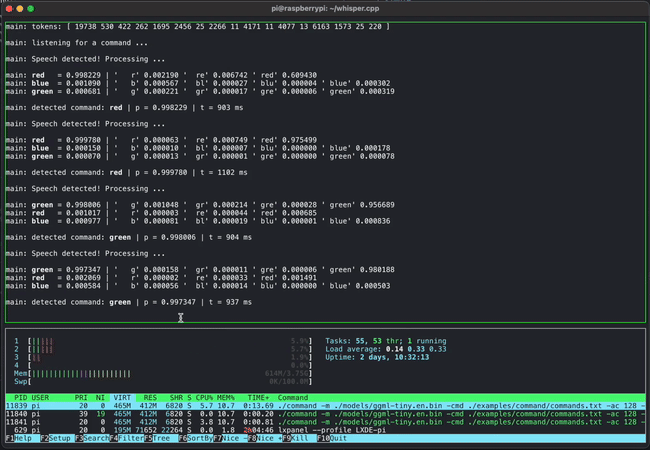
Simultaneously running 4 instances of 13B LLaMA + Whisper Small on a single M1 Pro
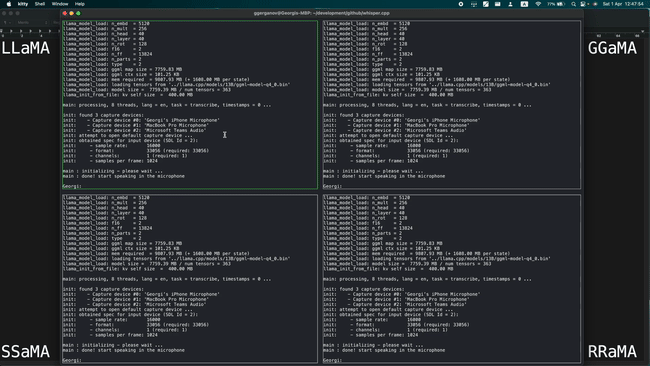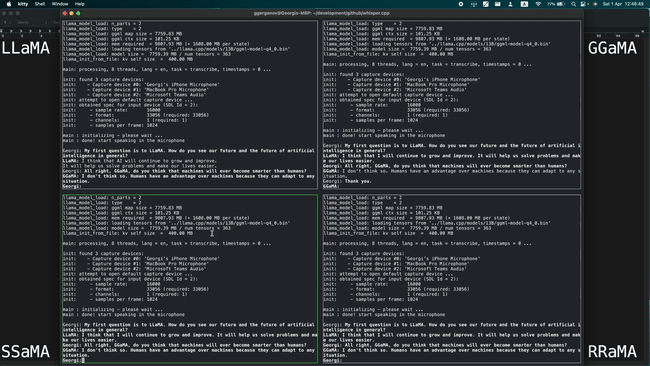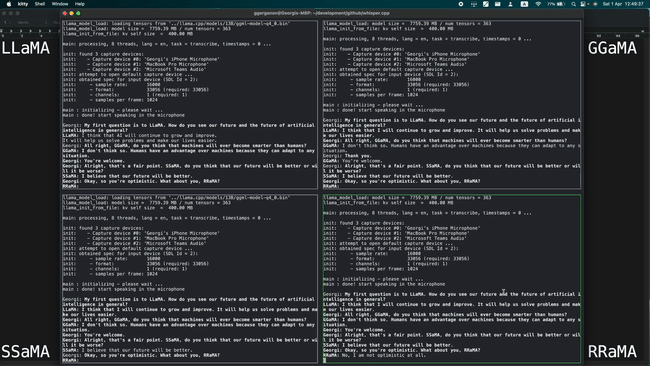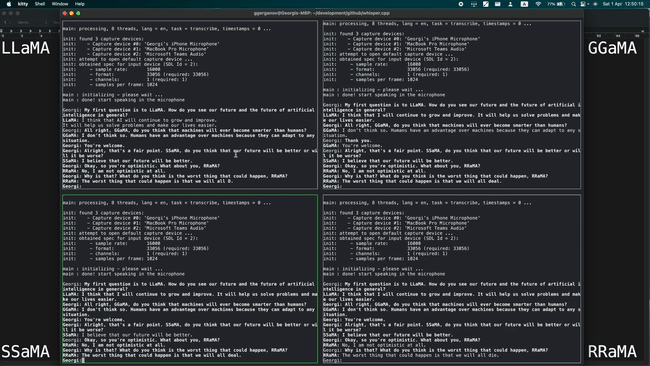
Running 7B LLaMA at 40 tok/s on M2 Max
Here are some sample performance stats on Apple Silicon June 2023:
Whisper Small Encoder, M1 Pro, 7 CPU threads: 600 ms / run
Whisper Small Encoder, M1 Pro, ANE via Core ML: 200 ms / run
7B LLaMA, 4-bit quantization, 3.5 GB, M1 Pro, 8 CPU threads: 43 ms / token
13B LLaMA, 4-bit quantization, 6.8 GB, M1 Pro, 8 CPU threads: 73 ms / token
7B LLaMA, 4-bit quantization, 3.5 GB, M2 Max GPU: 25 ms / token
13B LLaMA, 4-bit quantization, 6.8 GB, M2 Max GPU: 42 ms / token









