论文作者 | Karim Slimani1, Brahim Tamadazte1, Catherine Achard
文章解读 | William
本文介绍了一种基于深度学习的三维点云配准新方法。该架构由三个部分组成:
(1)编码器由基于卷积图的描述符组成,该描述符对每个点的近邻进行编码,并采用注意机制对表面法线的变化进行编码,突出同一集合的点之间以及两个集合的点之间的注意力;
(2)使用Sinkhorn算法估计对应矩阵的匹配过程;
(3)通过对应矩阵中的最佳分数Kc,利用RANSAC计算两个点云之间的刚性变换。
最后,在ModelNet40数据集上进行实验,提出的架构在大多数模拟配置中优于最先进的方法,包括部分重叠和高斯噪声的数据增强。
提出的RoCNet网络结构如图1所示,主要包含三个部分:1)由卷积图网络组成的描述符算子,进行编码每个点的近邻和一个编码表面法线变化的注意机制;2) 使用Sinkhorn算法估计对应矩阵的匹配模块;3) 利用RANSAC模块中Kc来计算刚性变换,得到最佳匹配结果
图1 网络结构
3.1 点云描述子
定义点云X和点云Y,存在部分重叠,故至少存在K(K<=min(M,N))对匹配点。令X中匹配点集为 ,Y中匹配点集为数 。由于点云配准的精度取决于编码描述子的质量。
因此,提出了一个新的描述符,通过将X和Y的初始集合投影到一个更高维度的新基中,比初始空间表示更具判别性且尽可能不受旋转和平移的影响,主要结合了一个基于几何的描述符、一个基于法向量的描述符和一个注意机制。
(1)基于几何的描述符
这里选择将DGCNN作为描述符的一部分,因为它可以更好地捕获点云的局部几何特征,同时保持排列不变性。DGCNN主要由EdgeConv卷积层组成,其中点代表以圆弧连接到编码空间中最近的k个近邻节点,以构建表示每个点周围的局部几何结构的图,然后在更高级别(全局编码)动态传播信息。以fXi为点xi提取到的d维特征向量。
(2)基于法向量的描述符
描述符的主要思想是利用邻近点的法线变化来编码每个点周围的表面信息,因为平坦表面上的法线不会变化,沿着脊的法线只在一个方向上变化,而顶点上的法线在所有方向上变化。因此,根据邻域法线角度的变化可以得出曲面类型的信息。
利用主成分分析法来计算法线信息,每个点,定义为局部邻域子集,令表示划分集合点的大小,是以 为中心的球体的半径,是 集合中包含的最大点数。协方差矩阵Cov(Si)的特征值分解允许将法向量
定义为与最小特征值相关的向量,Cov(Si)表示为:
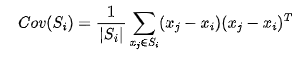
其中,表示为的点数。由于PCA可指向任一个方向的法向量,因此使用新的向量 ( 共线)来解决其模糊性。定义为

由于PCA可指向任一个方向的法向量,因此使用新的向量 (与 共线)来解决其模糊性。定义 为
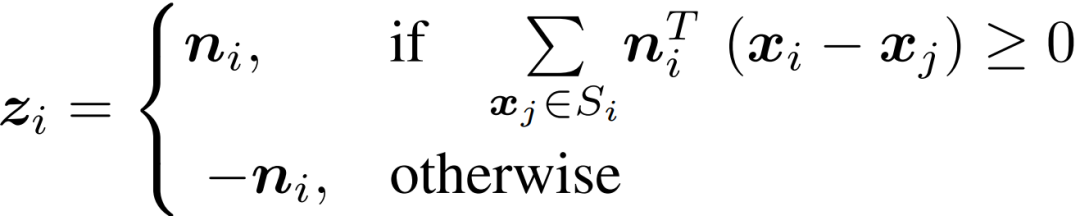
最后,使用不同频率的正弦函数构建最终编码。已知两点和 的法线夹角为,则编码法线向量为:
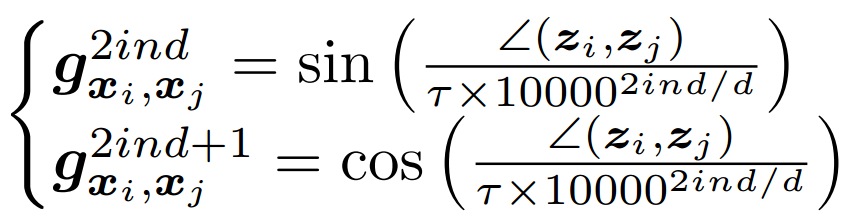
其中,为 当前值指数, 为归一化系数, 是描述符数学公式: 的维数,将其固定为与基于几何的描述符DGCNN相同的大小,然后对 用全连接层以获得最终嵌入
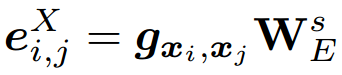
其中,是学习投影矩阵
(3)注意力机制
本文方法采用在每个集合X和Y中使用四个具有几何自我注意的注意头,分别对相关的法线嵌入 和 进行积分,然后在两组点之间进行交叉注意,交替执行L次
(4)自注意力
自注意力层为点云的每个点预测一个基于注意力的特征。对点云X和Y中的所有点都使用相同的算法,即可得到每个query/key对应的注意力权重:
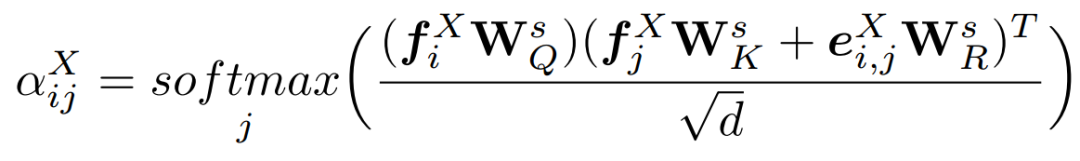
其中,是学习投影矩阵
(3)注意力机制
本文方法采用在每个集合X和Y中使用四个具有几何自我注意的注意头,分别对相关的法线嵌入和进行积分,然后在两组点之间进行交叉注意,交替执行L次
(4)自注意力
自注意力层为点云的每个点预测一个基于注意力的特征。对点云X和Y中的所有点都使用相同的算法,即可得到每个query/key对应的注意力权重:
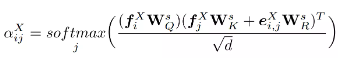
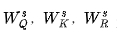 是学习到的用于query、key和基于法向量的嵌入投影矩阵,d是特征的维数和 。权重用于评估注意的一些元素,并获得最终的基于自注意的特征 :
是学习到的用于query、key和基于法向量的嵌入投影矩阵,d是特征的维数和 。权重用于评估注意的一些元素,并获得最终的基于自注意的特征 :
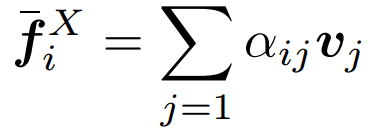
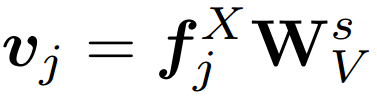
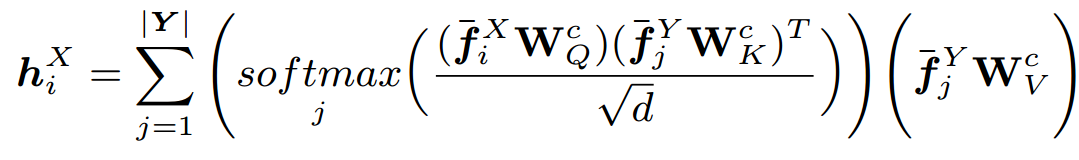
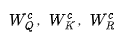 是交叉注意层中学习到的query、key和value的投影矩阵。
是交叉注意层中学习到的query、key和value的投影矩阵。
3.2 点匹配
在每个点数学公式: 之间估计一个分数矩阵C:
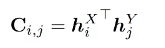
其中, 和是定义点和 的最终编码。然后将C的维度分别增加到M+1和N+1,从而建立一个对应概率 的矩阵,再使用可微的Sinkhorn算法。
由于前面所有步骤都是可微的,因此可以通过引入损失函数来学习网络的权重。为此,采用gap损失函数,表示为
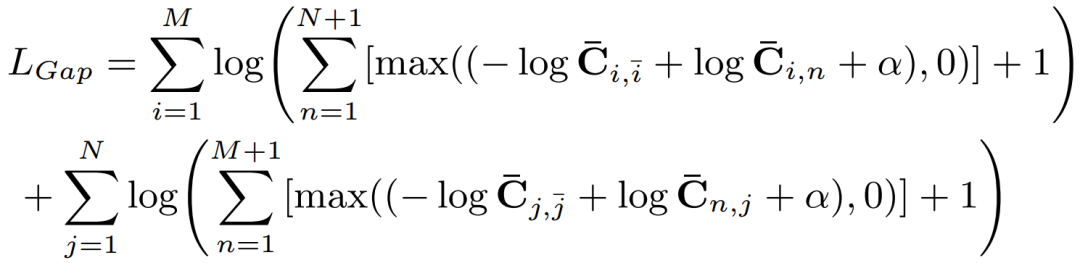
其中, 是一个值为0.5的正标量,和分别是点和的基本匹配分数。
3.3 位姿估计
在求值阶段,通过以下算法构建一个硬赋值二进制矩阵a:
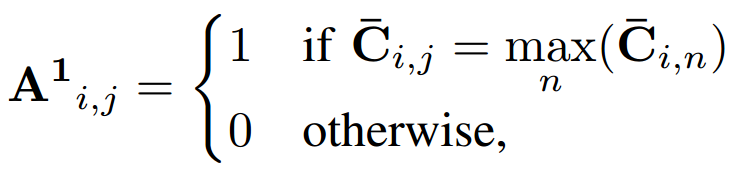
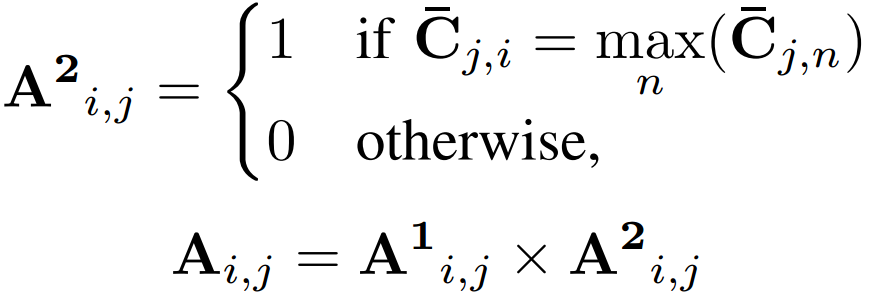
矩阵A分别用非零值的行向量和列向量重新索引原始点云X和Y,得到了两个最终匹配点和的集合,匹配执行如图3所示。建立了匹配点集后,本文使用基于预测对应的RANSAC来减少计算成本。此外,不考虑所有K个匹配点,只使用个最相关的点,同时在第一次迭代之前过滤异常值。
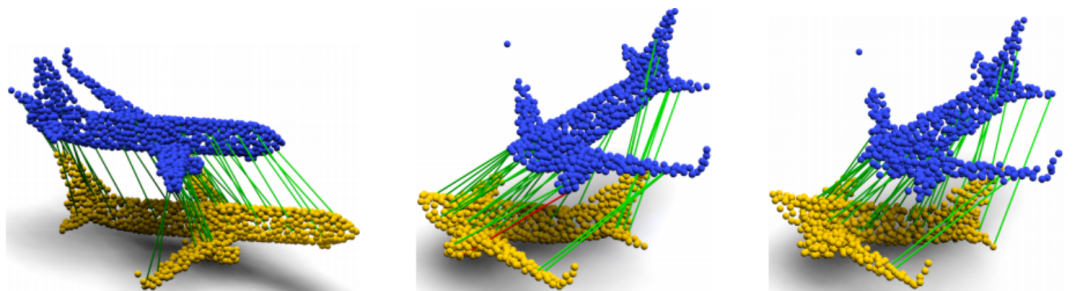
图2 3D匹配示例((a)干净数据;(b)部分重叠;(c)噪声数据和部分重叠)
以下所有的对比结果均基于VRNet论文中的结果。首先在干净的数据上进行性能对比,如表1所示。
可以发现,本文方法在RMSE和MAE方面的性能优于其他方法。然而,VRNet在旋转性方面仍然是最好的,尽管与RoCNet相比差异很小,特别是在MAE(t)中,RoCNet排名第二。
可视化实例如图3所示,第一行显示待对齐点云X和Y的初始位置,第二行显示已执行的配准,第三行显示地面真值
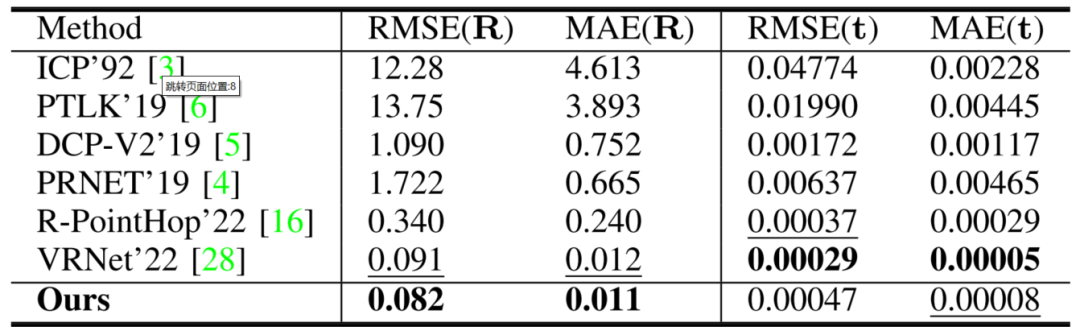
图3 干净且无遮挡的情况下,RoCNet配准实例
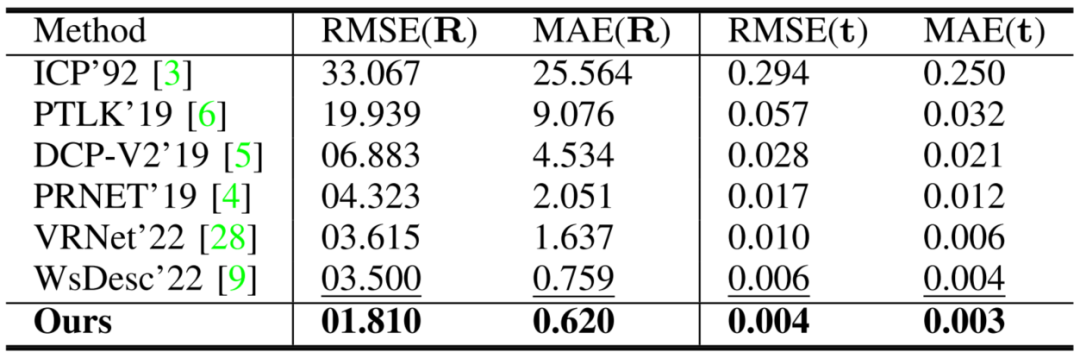
在带有噪声数据和部分遮挡的所有类别上训练的模型结果如表2所示,RoCNet在所有指标上都优于其他方法,包括旋转和平移。RoCNet允许显著增强的配准误差,从三分之二到四分之一不等,与WsDesc、VRNet相比,拥有对部分遮挡或噪声或两者同时的鲁棒性。
此外,为了直观地评估所提出方法的鲁棒性,通过逐步降低(从95%到50%)X和Y之间共享点的比率来进行不同的配准,如图4所示。
可以看到,RoCNet即使只使用50%的数据也可以很容易地配准点云。但另一方面,对于完全对称的物体,当重叠度较低时,该方法显示出其局限性。
图4 RoCNet鲁棒性证明
本文提出了一种基于深度学习的三维点云配准和姿态估计方法。所提出的体系结构由三个主要部分组成:1)新设计的描述符编码每个点的邻域和编码表面法线变化的注意机制;2)使用Sinkhorn算法估计对应矩阵的匹配方法;3)使用RANSAC应用于对应矩阵的K^c最佳匹配来估计刚性变换。使用ModelNet40数据集在不同的配置下对所提出的架构进行了评估。
实验证明,本文方法优于相关的最先进的算法,特别是在噪声的数据和部分遮挡的条件下。
未来,打算将这项工作扩展到一种新的方法,在这种方法中,描述符将在频率范围内表示。这当然会提高我们架构的准确性,但也提高了它对噪声和部分遮挡的鲁棒性。
这是一篇十分标准的基于深度学习的点云配准的论文,整体结构可以作为借鉴学习,所提出的编码算法的性能很好,最终也在ModelNet40数据集上进行测试所提算法的有效性。同时,该方法可以扩展接入其余点云配准的方法,希望源码早日公开,进行学习。
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。









