链接:https://www.zhihu.com/question/375794498
仅做学术分享,侵删
https://www.zhihu.com/question/375794498/answer/2292320194这也是个困扰了我多年的问题:
loss = a * loss1 + b * loss2 + c * loss3 怎么设置 a,b,c?
我的经验是 loss 的尺度一般不太影响性能,除非本来主 loss 是 loss1,但是因为 b,c 设置太大了导致其他 loss 变成了主 loss。
实践上有几个调整方法:
手动把所有 loss 放缩到差不多的尺度,设 a = 1,b 和 c 取 10^k,k 选完不管了;
如果有两项 loss,可以 loss = a * loss1 + (1 - a) * loss2,通过控制一个超参数 a 调整 loss;
我试过的玄学躺平做法 loss = loss1 / loss1.detach() + loss2 / loss2.detach() + loss3 loss3.detach(),分母可能需要加 eps,相当于在每一个 iteration 选定超参数 a, b, c,使得多个 loss 尺度完全一致;进一步更科学一点就 loss = loss1 + loss2 / (loss2 / loss1).detach() + loss3 / (loss3 / loss1).detach(),感觉比 loss 向 1 对齐合理
某大佬告诉我,loss 就像菲涅尔透镜,纵使你能设计它的含义,也很难设计它的梯度。所以暴力一轮就躺平了。我个人见解,很多 paper 设计一堆 loss 只是为了让核心故事更完整,未必强过调参。
作者:Evan
https://www.zhihu.com/question/375794498/answer/1052779937
其实这是目前深度学习领域被某种程度上忽视了的一个重要问题,在近几年大火的multi-task learning,generative adversarial networks, 等等很多机器学习任务和方法里面都会遇到,很多paper的做法都是暴力调参结果玄学……这里偷偷跟大家分享两个很有趣的研究视角
从预测不确定性的角度引入Bayesian框架,根据各个loss分量当前的大小自动设定其权重。有代表性的工作参见Alex Kendall等人的CVPR2018文章 Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics,文章的二作Yarin Gal是Zoubin Ghahramani的高徒,近几年结合Bayesian思想和深度学习做了很多solid的工作。
构建所有loss的Pareto,以一次训练的超低代价得到多种超参组合对应的结果。有代表性的工作参见Intel在2018年NeurIPS(对,就是那个刚改了名字的机器学习顶会)发表的Multi-Task Learning as Multi-Objective Optimization 因为跟文章的作者都是老熟人,这里就不尬吹了,大家有兴趣的可以仔细读一读,干货满满。
https://www.zhihu.com/question/375794498/answer/2307552166
多个loss引入pareto优化理论,基本都可以涨点的。例子:Multi-Task Learning as Multi-Objective Optimization可以写一个通用的class用来优化一个多loss的损失函数,套进任何方法里都基本会涨点。反正我们在自己的研究中直接用是可以涨的。
https://www.zhihu.com/question/375794498/answer/1056695768
Focal loss 会根据每个task的表现帮你自动调整这些参数的。
我们的做法一般是先分几个stage 训练。stage 0 : task 0, stage 1: task 0 and 1. 以此类推。在stage 1以后都用的是focal loss。
是这样的。
首先对于每个 Task,你有个 Loss Function,以及一个映射到 [0, 1] 的 KPI (key performance indicator) 。比如对于分类任务, Loss function 可以是 cross entropy loss,KPI 可以是 Accuracy 或者 Average Precision。对于 regression 来说需要将 IOU 之类的归一化到 [0, 1] 之间。KPI 越高表示这个任务表现越好。
对于每个进来的 batch,每个Task_i 有个 loss_i。每个Task i 还有个不同的 KPI: k_i。那根据 Focal loss 的定义,FL(k_i, gamma_i) = -((1 - k_i)^gamma_i) * log(k_i)。一般来说我们gamma 取 2。
于是对于这个 batch 来说,整个 loss = sum(FL(k_i, gamma_i) * loss_i)
在直观上说,这个 FL,当一个任务的 KPI 接近 0 的时候会趋于无限大,使得你的 loss 完全被那个表现不好的 task 给 dominate。这样你的back prop 就会让所有的权重根据那个kpi 不好的任务调整。当一个任务表现特别好 KPI 接近 1 的时候,FL 就会是0,在整个 loss 里的比重也会变得很小。
当然根据学习的速率不同有可能一开始学的不好的task后面反超其他task。http://svl.stanford.edu/assets/papers/guo2018focus.pdf 这篇文章里讲了如何像momentum 一样的逐渐更新 KPI。
由于整个 loss 里现在也要对 KPI 求导,所以文章里还有一些对于 KPI 求导的推导。
当然我们也说了,KPI 接近 0 时,Loss 会变得很大,所以一开始训练的时候不要用focal loss,要确保网络的权重更新到一定时候再加入 focal loss。
作者:杨奎元
https://www.zhihu.com/question/375794498/answer/1050963528一般都是多个loss之间平衡,即使是单任务,也会有weight decay项。比较简单的组合一般通过调超参就可以。
对于比较复杂的多任务loss之间平衡,这里推荐一篇通过网络直接预测loss权重的方法[1]。以两个loss为例, σ1\sigma_1\sigma_1 和 σ2\sigma_2\sigma_2 由网络输出,由于整体loss要求最小,所以前两项希望 σ\sigma\sigma 越大越好,为防止退化,最后第三项则希望σ\sigma\sigma越小越好。当两个loss中某个比较大时,其对应的σ\sigma\sigma也会取较大值,使得整体loss最小化,也就自然处理量纲不一致或某个loss方差较大问题。
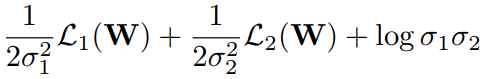
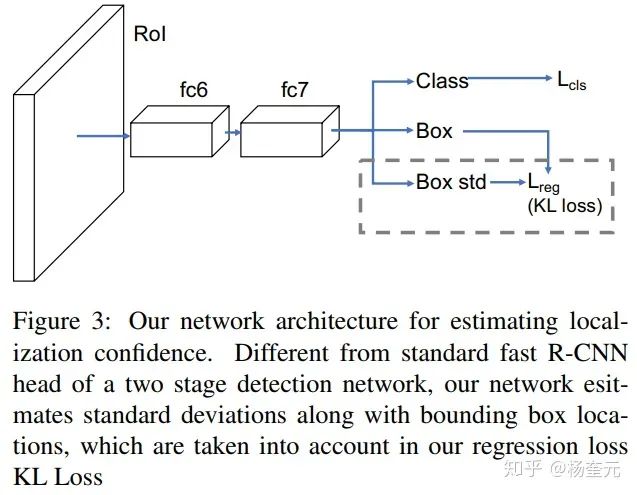
该方法后来被拓展到了物体检测领域[2],用于考虑每个2D框标注可能存在的不确定性问题。
[1] Alex Kendall, Yarin Gal, Roberto Cipolla. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. CVPR, 2018.
[2] Yihui He, Chenchen Zhu, Jianren Wang, Marios Savvides, Xiangyu Zhang. Bounding Box Regression with Uncertainty for Accurate Object Detection. CVPR, 2019.
https://www.zhihu.com/question/375794498/answer/2291842390
对于多任务的loss,最简单的方式是直接将这两个任务的loss直接相加,得到整体的loss,这种loss计算方式的不合理之处是显而易见的,不同任务loss的量级很有可能不一样,loss直接相加的方式有可能会导致多任务的学习被某个任务所主导或学偏。当模型倾向于去拟合某个任务时,其他任务的效果往往可能受到负面影响,效果会相对变差(这是不是有一种零和博弈的感觉,当然也有跷跷板的感觉)。
相对于loss直接相加的方式,这个loss函数对于每个任务的loss进行加权。这种方式允许我们手动调整每个任务的重要性程度;但是固定的w会一直伴随整个训练周期。这种loss权重的设置方式可能也是存在问题的,不同任务学习的难易程度也是不同的;且,不同任务可能处于不同的学习阶段,比如任务A接近收敛,任务B仍然没训练好等。这种固定的权重在某个阶段可能会限制了任务的学习。
其实这是目前深度学习领域被某种程度上忽视了的一个重要问题,在近几年大火的multi-task learning,generative adversarial networks,等等很多机器学习任务和方法里面都会遇到,很多paper的做法都是暴力调参结果玄学。
极端情况下,当某个任务的loss非常的大而其它任务的loss非常的小,此时多任务近似退化为单任务目标学习,网络的权重几乎完全按照大loss任务来进行更新,逐渐丧失了多任务学习的优势。
对于如何解决多个loss平衡的问题,可以查看以下几篇论文:
1、Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics(基于任务不确定性)
2、GradNorm:Gradient Normalization for Adaptive(基于梯度更新)
3、另外还有研究将该问题看做多目标优化问题,这样做的好处是:在优化时将任务之间看做竞争关系,,而不是看作简单的线性组合,这样扩展了模型的适用范围。一个代表性的工作:Multi-Task Learning as Multi-Objective Optimization
4、Efficient Continuous Pareto Exploration in Multi-Task Learning
若觉得还不错的话,请点个 “赞” 或 “在看” 吧CV基础入门班
课程内容:深度学习基础、机器学习基础、数字图像处理、网络设计、模型分析与改进、代码实践等。
课程形式:10次左右的直播(每次大概2小时讲内容)+持续3-4个月的学习反馈、指导、代码实践。
| 网上机构 | CV技术指南入门班 |
授课形式 |
老师单方面授课为主,无法保证所有人学习有效,脑子会了手不会 | 20%直播+80%指导实践,脑子会了,手也得会 |
学习重点 | 所有学员学习任务一致 | 根据学员的情况调整 |
课程价格 | 偏高 | 实惠,性价比高 |
学习内容
| 单一、不成体系 | 系统全面 |
| 人数 | 100+,无法兼顾所有人
| 10人以内,充分考虑每个学员的学习效果
|
相信大家都深有体会,很多东西都是视频看完了,脑子学会了,但自己上手,就啥也不会。网上辅导机构90%讲内容、10%答疑,且上百人的大班无法有效保证学习效果,而我们仅做小班指导,每个班的人数限制在10人以内,不仅讲具体内容,还包括学习效果的反馈与保证,基本做到讲内容占20%,保证学到位、学明白的反馈占80%,确保大家手也会了。
报名请扫描下方二维码了解详细情况,备注:“入门班报名”。










