
日前,Kaggle发布了ICR - Identifying Age-Related Conditions疾病识别大赛。这是一个机器学习中的二分类任务,需要你使用ML的方法对病人进行诊断,判断病人是否有相关疾病,从而为医生提供进行合理诊断的依据。
本次比赛提供了4份数据,分别是:train、test、sample_submission、greeks。其中:
train文件标记了每个病人的相关特征和label。
test、sample_submission为提交答案时用。
greeks是补充元数据,仅适用于训练集。
为了帮助同学们冲分拿牌,我邀请了Kaggle大神William老师为同学们带来本次疾病识别大赛的专题讲座。内容包含赛题解析、数据EDA与baseline详解,帮助同学们快速掌握赛题核心思路。
现在扫码,即可随时观看赛题讲座。不仅如此,扫码即免费送高分baseline!并且还能参与抽奖,抽取50名同学包邮赠送《算法竞赛入门经典(第2版)》!
扫码看讲座,领baseline,抽图书!
Number of rows in train data: 617 Number of columns data: 58
数据样例:

数据分布: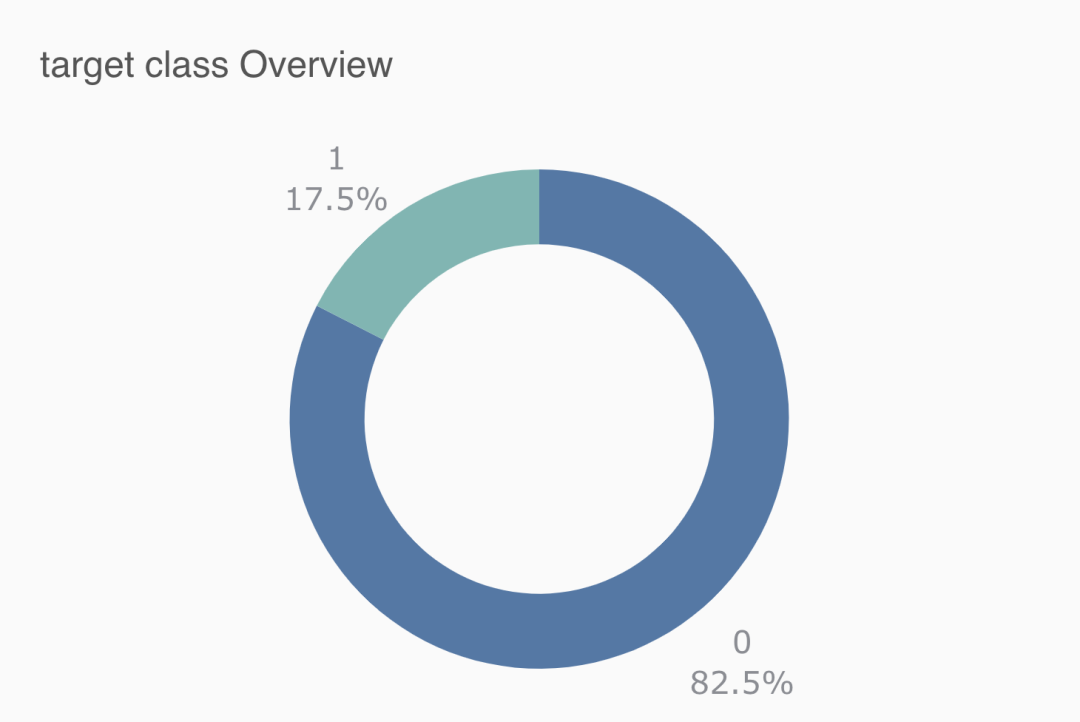
相关性分析: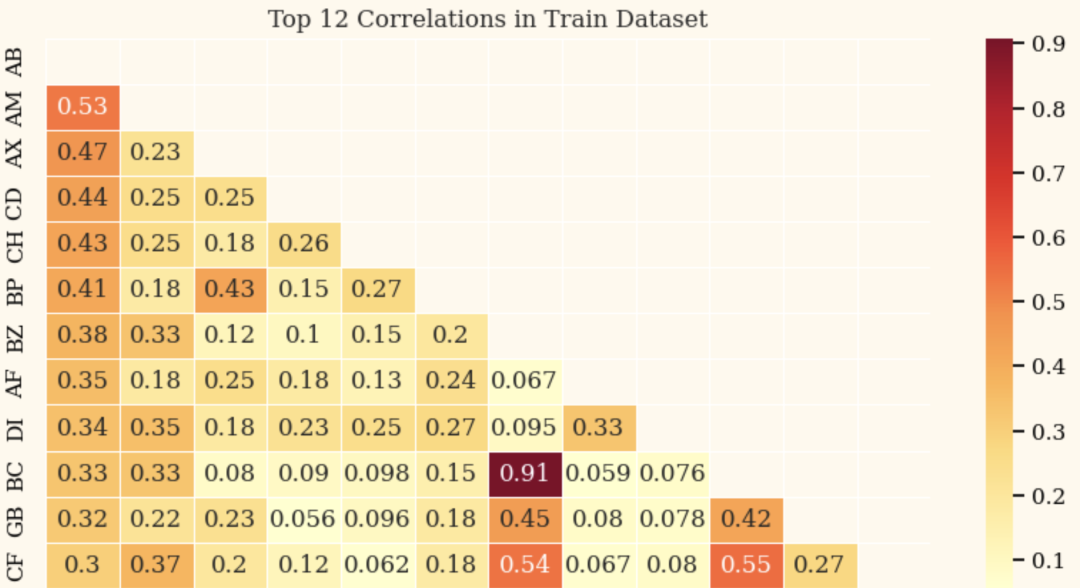
读取数据,具体可以详见baseline代码,里面有更为详细的介绍
train = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/train.csv') test = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/test.csv') greeks = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/greeks.csv') sample_submission = pd.read_csv('/kaggle/input/icr-identify-age-related-conditions/sample_submission.csv')
加载数据,特征处理:
from sklearn.impute import SimpleImputerfrom sklearn.preprocessing import MinMaxScaler, OneHotEncoder
# Combine numeric and categorical featuresFEATURES = num_cols + cat_cols
# Fill missing values with mean for numeric variablesimputer = SimpleImputer(strategy='mean')numeric_df = pd.DataFrame(imputer.fit_transform(train[num_cols]), columns=num_cols)
# Scale numeric variables using min-max scalingscaler = MinMaxScaler()scaled_numeric_df = pd.DataFrame(scaler.fit_transform(numeric_df), columns=num_cols)
# Encode categorical variables using one-hot encodingencoder = OneHotEncoder(sparse=False, handle_unknown='ignore')encoded_cat_df = pd.DataFrame(encoder.fit_transform(train[cat_cols]), columns=encoder.get_feature_names_out(cat_cols))
# Concatenate the scaled numeric and encoded categorical variablesprocessed_df = pd.concat([scaled_numeric_df, encoded_cat_df], axis=1)
定义训练函数:
from sklearn.utils import class_weight
FOLDS = 10SEED = 1004xgb_models = []xgb_oof = []f_imp = []
counter = 1X = processed_dfy = train['Class']
# Calculate the sample weightsweights = class_weight.compute_sample_weight('balanced', y)
skf = StratifiedKFold(n_splits=FOLDS, shuffle=True, random_state=SEED)for fold, (train_idx, val_idx) in
enumerate(skf.split(X, y)): if (fold + 1)%5 == 0 or (fold + 1) == 1: print(f'{"#"*24} Training FOLD {fold+1} {"#"*24}') X_train, y_train = X.iloc[train_idx], y.iloc[train_idx] X_valid, y_valid = X.iloc[val_idx], y.iloc[val_idx] watchlist = [(X_train, y_train), (X_valid, y_valid)] # Apply weights in the XGBClassifier model = XGBClassifier(n_estimators=1000, n_jobs=-1, max_depth=4, eta=0.2, colsample_bytree=0.67) model.fit(X_train, y_train, sample_weight=weights[train_idx], eval_set=watchlist, early_stopping_rounds=300, verbose=0) val_preds = model.predict_proba(X_valid)[:, 1] # Apply weights in the log_loss val_score = log_loss(y_valid, val_preds, sample_weight=weights[val_idx]) best_iter = model.best_iteration idx_pred_target = np.vstack([val_idx, val_preds, y_valid]).T f_imp.append({i: j for i, j in zip(X.columns, model.feature_importances_)}) print(f'{" "*20} Log-loss: {val_score:.5f} {" "*6} best iteration: {best_iter}') xgb_oof.append(idx_pred_target) xgb_models.append(model) print('*'*45)print(f'Mean Log-loss: {np.mean([log_loss(item[:, 2], item[:, 1], sample_weight=weights[item[:, 0].astype(int)]) for item in xgb_oof]):.5f}')
特征重要性查看:
cm = confusion_matrix(y_valid, model.predict(X_valid))
feature_imp = pd.DataFrame({'Value':xgb_models[-1].feature_importances_, 'Feature':X.columns})feature_imp = feature_imp.sort_values(by="Value", ascending=False)feature_imp_top20 = feature_imp.iloc[:20]
fig, ax = plt.subplots(1, 2, figsize=(14, 4))
sns.heatmap(cm, annot=True, fmt='d', ax=ax[0], cmap='YlOrRd')ax[0].set_title('Confusion Matrix')ax[0].set_xlabel('Predicted')ax[0].set_ylabel('True')
sns.barplot(x="Value", y="Feature", data=feature_imp_top20, ax=ax[1], palette='YlOrRd_r')ax[1].set_title('Feature Importance')
plt.tight_layout()plt.show()
扫码看讲座,领baseline,抽图书!
添加客服,凭当前文章截图参与抽奖送书。抽取50名同学,包邮送出《算法竞赛入门经典(第2版)》!
扫码看讲座,领baseline,抽图书!










