本文主要讲解MySQL中出现死锁的应用案例,以及相关的业务场景,不会纯讲理论,希望对这块感兴趣的朋友可以有所帮助。
多个线程在访问某些资源的时候,需要等待对方释放彼此所需资源,而进入了等待互斥的状态。
通俗一些来说,A线程持有B锁,然后想要访问A锁,此时B线程持有A锁,想要访问B锁,这种情况下就容易出现死锁。
下文以用户消息表案例来进行说明:
CREATE TABLE `t_user_message` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `user_id` int unsigned NOT NULL DEFAULT '0' COMMENT '发信方id', `object_id` int unsigned NOT NULL DEFAULT '0' COMMENT '收信方id', `relation_id` int unsigned NOT NULL DEFAULT '0' COMMENT '关联id', `is_read` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否已读(0未读,1已读)', `sid` int unsigned NOT NULL DEFAULT '0' COMMENT '消息条数', `status` tinyint unsigned NOT NULL DEFAULT '1' COMMENT '状态(0无效 1有效)', `content` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '消息内容', `type` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '类型(0文本,1语音,2图片,3视频,4表情,5分享链接)', `ext_json` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '扩展字段', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) USING
BTREE COMMENT '发信方id索引', KEY `idx_object_id` (`object_id`) USING BTREE COMMENT '收信方id索引', KEY `idx_relation_id` (`relation_id`) USING BTREE COMMENT '关联id索引') ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin COMMENT='用户消息表';
按照锁的粒度来区分,可以分为以下两种:
select * from t_user_message where user_id=1001 for update;
select * from t_user_message for update;
看到这里,你可能对共享锁和排它锁并不是理解得很彻底,那么先别着急,我们先从实战来加深下你对它的理解。
在Innodb存储引擎中,常见的update,insert,delete这些sql都会默认加入上排他锁,而我们的select语句如果没有加入特殊关键字(下边会讲是什么样的特殊关键字) ,是不会加入排他锁的。
如果select语句希望加入排它锁,那么可以尝试以下方式:使用 for update 关键字。
select * from t_user_message for update;
在正常的select语句中,是不会有加锁的,例如下边这条sql:
select * from t_user_message;
这条sql在innodb中,默认是不会锁表,也不会锁行记录。如果你希望加上一把共享锁,那么可以尝试以下的这种写法:使用 lock in share mode 关键字。
select * from t_user_message lock in share mode;
五、lock in share mode 和 for update使用起来有什么区别?
来看看这个案例,我们准备了两个MySQL的会话窗口。
先来看会话A:会话A中,关闭了自动提交功能,然后执行这个lock in share mode的锁,此时它使用了共享锁锁住了全表的内容。
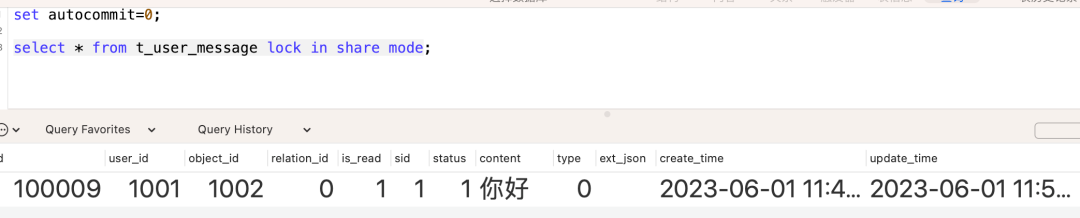
再来看会话B:会话B中也是相同的,关闭自动提交后,执行lock in share mode的共享锁,发现依然可以正常查询,没有堵塞行为。
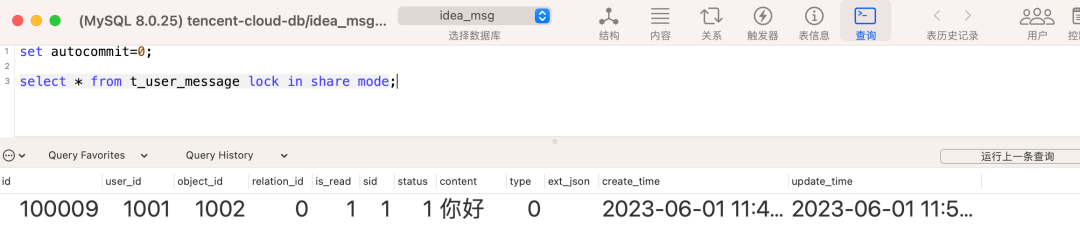
这时候我们将会话B的当前事务先提交,然后在会话B中继续执行一条update语句(非事务状态下) ,要知道update是默认带了拍它锁的,此时因为我们的会话A没有commit,所以会话B的这条update操作会进入堵塞的状态,如下图:
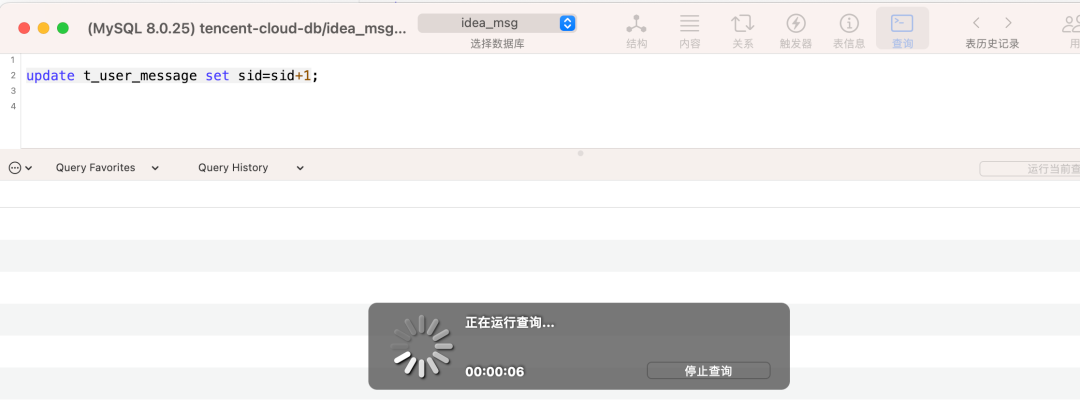
只有当会话A的事务执行完毕了,将lock in share mode的锁给释放掉,会话B才会继续执行。
让我们来看看 for update 加锁的影响,会话A关闭了自动提交,然后执行了一条for update的sql,但是没有commit;此时我们的会话B也开始了同样的步骤,但是却卡住了。
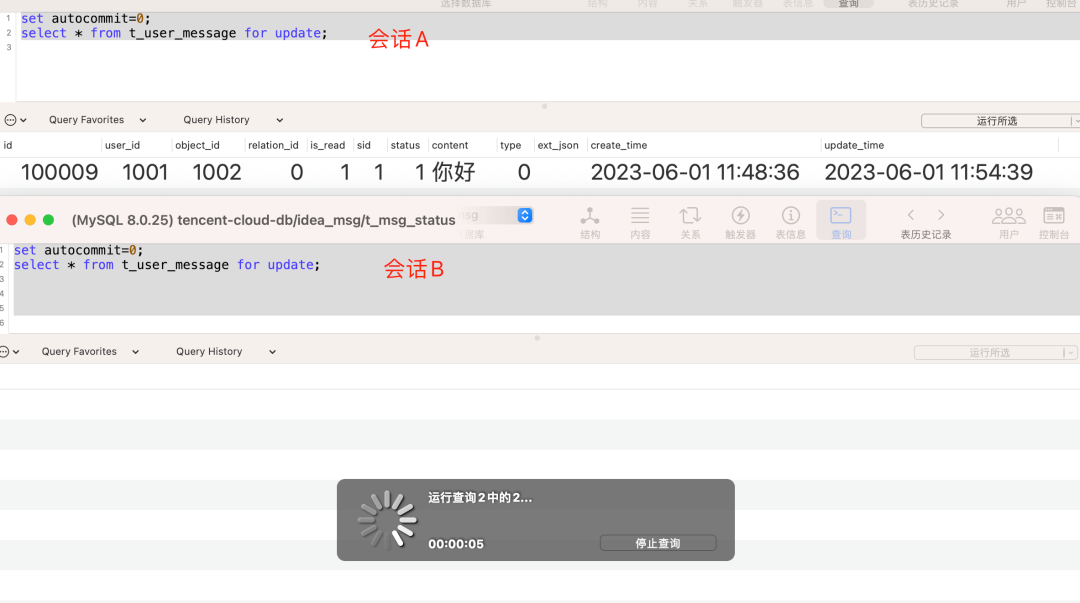
假如事务A一直都不提交的话,那么事务B最终会报出以下异常:
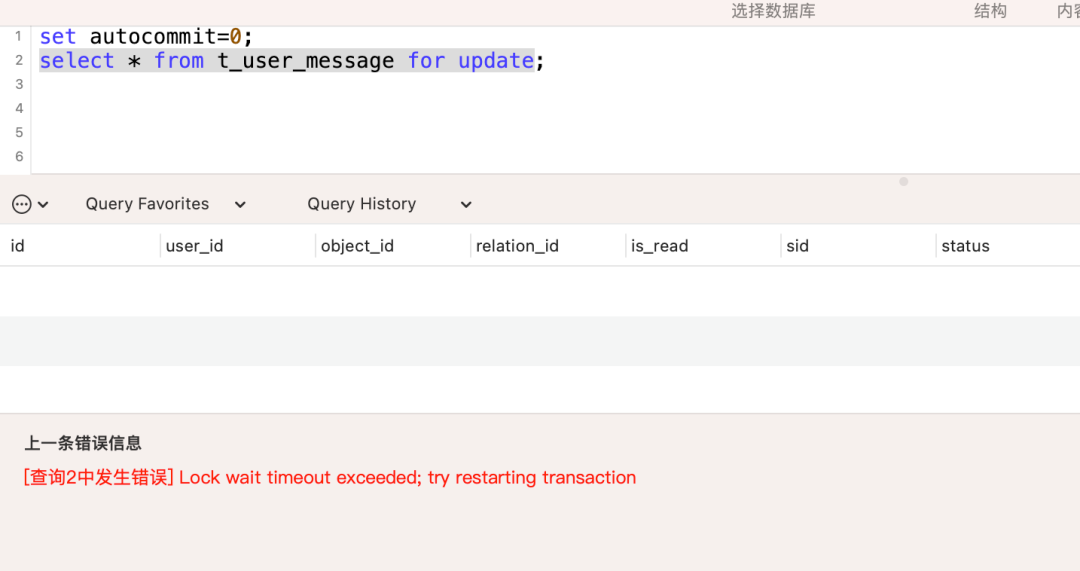
[查询2中发生错误] Lock wait timeout exceeded; try restarting transaction
再来看看for update锁住的数据,对于其他会话的写操作有何影响。
如下图所示,我们的会话A依旧没有commit,但是此时会话B中尝试执行一次update操作,由于update默认带了排他锁,这条sql会锁表,所以和会话A中的for update锁出现了冲突,导致会话B一直处于堵塞状态。
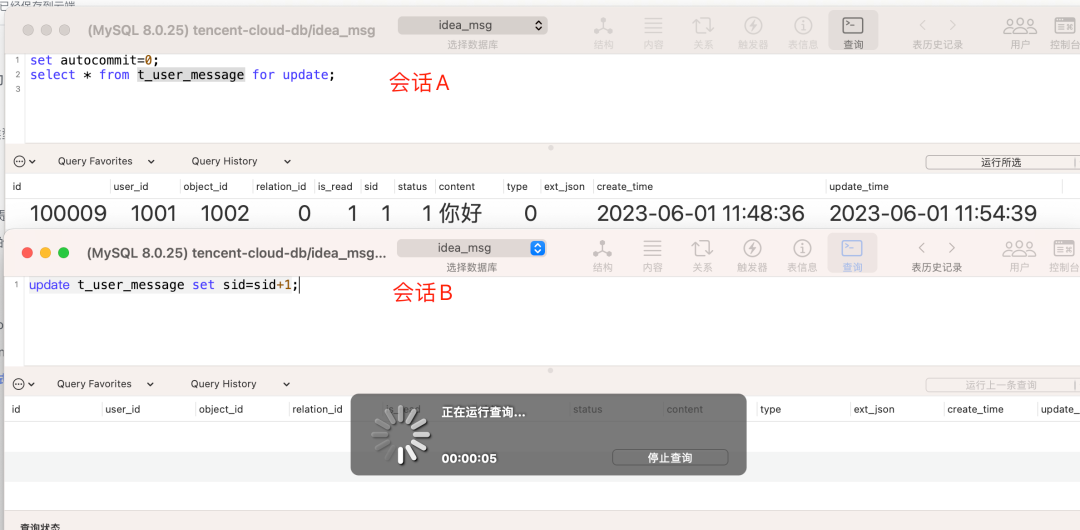
通过上述的几个测试,大家应该也有深刻的体会了,那么我们就来进行下总结,加深下印象。

看到这里,你应该对lock in share mode 和 for update 有一定了解了吧,但是这两种锁,光了解理论,其实还是不够的,需要有实战才能让你对它理解更加深刻,来看下边的案例。
六、lock in share mode使用不当,导致死锁
来看下边的这个业务场景,假设我们有一个账户表,表结构如下:
CREATE TABLE `t_account` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `user_id` int DEFAULT NULL, `coin` int DEFAULT NULL, PRIMARY KEY
(`id`)) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin;
然后在业务操作上,我们的账户扣款和增款逻辑上的设计如下:
//开启一个事务操作set autocommit=0;begin;//如果账户存在,才进行update,如果账户不存在,就得先insertselect * from t_account where user_id=111 lock in share mode;
//这里我们假设账户是存在的,那么就直接选择打款入账update t_account set coin=coin+100 where user_id=111;
//记录到账户流水表中INSERT INTO `transaction_log` (`id`, `business`, `foreign_key`)VALUES (1, X'6F726465722D62697A', X'3234303938413535333031324444443044444137363036333744434233373834333643313138423441414332323236454644463430303034');
commit;
这里为了保证将账户流水记录和打款两个操作保证一致性,得加入一个本地事务去修饰。但是这段代码中使用了一个lock in share mode的关键字,这个关键字是为了避免在并发的情况下,对账户记录进行读的过程中,有其他地方对账户的coin值进行写的修改。
之所以可能会有其他地方对coin值进行额外的写操作,主要原因是因为系统业务中的老旧代码存在,重复造轮子,本来A服务中只有一处地方对账户进行修改操作,结果在B服务里,也有一段类似的代码修改,直接操作了数据库表,但是由于不好去调整那个服务的代码,所以暂时只能用 lock in share mode 操作去加锁。相比于for update锁来说,使用lock in share mode加锁,对于读的影响不大,所以早期设计的时候,没有考虑那么多,就直接用了它上线。并且上线之后并发度不高,暂时就没有发现什么问题。
看到这里,你可能感觉似乎这种设计没有什么问题,那么我们来看看下边的这个场景。
随着并发度的增加,我们将修改余额的这个操作,在A服务里面封装成为了一个方法,并且供各个地方进行调用。但是有一天,出现了这么一个业务场景:
在RocketMQ的消费方,会对用户的账户进行打款操作。在这个消费方的代码中,同一个userId的消息会有许多条,而且是同一时刻的大量并发消费,这就意味着,同一时刻会有大量的请求调用这个打款的操作,而且是并发,同一个userId。那么这种情况下,我们的 lock in share mode会发生什么样的情况呢——死锁。
来看下图:
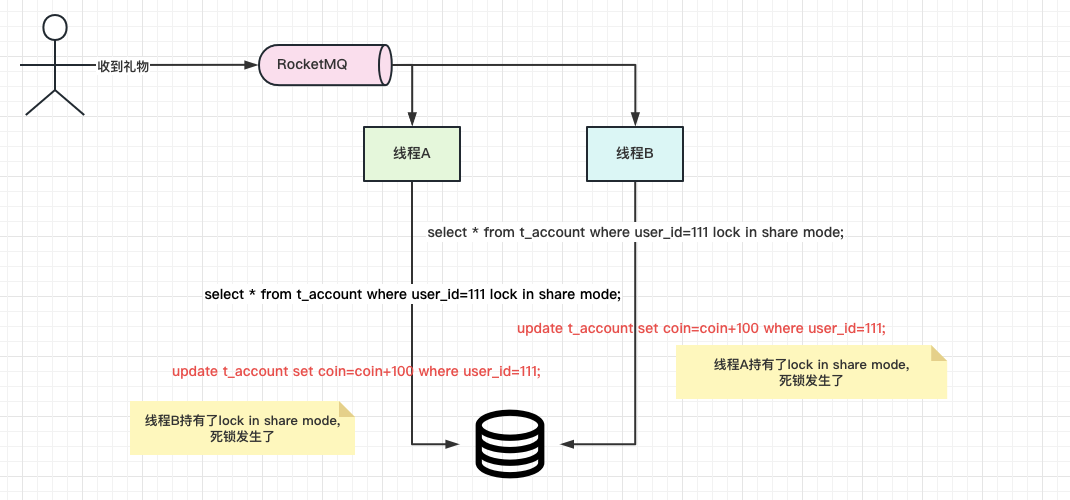
由于我们的线程A持有了锁,线程B也持有了锁,但是它们接下来的update操作,都是得等对方将共享锁释放后才可以继续执行,所以就发生了死锁的场景。

七、如何解决上述的lock in share mode死锁
那么我们如何却避免上边的场景发生呢,这里我给出以下两种思路。
//开启一个事务操作set autocommit=0;
//如果账户存在,才进行update,如果账户不存在,就得先insertselect * from t_account where user_id=111;
//这里我们假设账户是存在的,那么就直接选择打款入账update t_account set coin=coin+100,version=version+1 where user_id=111;
//记录到账户流水表中INSERT INTO `transaction_log` (`id`, `business`, `foreign_key`)VALUES (1, X
'6F726465722D62697A', X'3234303938413535333031324444443044444137363036333744434233373834333643313138423441414332323236454644463430303034');
commit;
2.去掉使用lock in share mode,使用乐观锁
例如加入一个version字段,那么我们在执行账户扣款的时候,加入version的判断。例如:
//开启一个事务操作set autocommit=0;
//如果账户存在,才进行update,如果账户不存在,就得先insertselect * from t_account where user_id=111 and version=
//这里我们假设账户是存在的,那么就直接选择打款入账update t_account set coin=coin+100,version=version+1 where user_id=111 and version=
//记录到账户流水表中INSERT INTO `transaction_log` (`id`, `business`, `foreign_key`)VALUES (1, X'6F726465722D62697A', X'3234303938413535333031324444443044444137363036333744434233373834333643313138423441414332323236454644463430303034');
commit;
这里要注意,当同时两个会话针对同一行数据执行上述更新操作的时候,可能会导致同一行的记录被锁,所以我们在进行update的时候,可以用一个version字段去管理。但是这种设计,可能会导致一次更新失败,需要进行重试,因此并发量高的情况下,容易对MySQL造成较大的压力。
直接在业务层引入一把分布式锁,这种思路比较暴力,但是确实有效。
其实只要我们的select类型的sql中进行显示加锁,就有可能会有死锁情况发生,所以建议大家使用的时候谨慎。
消息数据更新设计不当,导致出现Record Lock死锁。
这里我们需要先了解下消息记录表的结构;
CREATE TABLE `t_user_message` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `user_id` int unsigned NOT NULL
DEFAULT '0' COMMENT '发信方id', `object_id` int unsigned NOT NULL DEFAULT '0' COMMENT '收信方id', `relation_id` int unsigned NOT NULL DEFAULT '0' COMMENT '关联id', `is_read` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否已读(0未读,1已读)', `sid` int unsigned NOT NULL DEFAULT '0' COMMENT '消息条数', `status` tinyint unsigned NOT NULL DEFAULT '1' COMMENT '状态(0未审核 1审核失败 2审核通过)', `content` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '消息内容', `type` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '类型(0文本,1语音,2图片,3视频,4表情,5分享链接)', `ext_json` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '扩展字段', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) USING BTREE COMMENT '发信方id索引', KEY `idx_object_id` (`object_id`) USING BTREE COMMENT '收信方id索引', KEY `idx_relation_id` (`relation_id`) USING BTREE COMMENT '关联id索引') ENGINE=InnoDB AUTO_INCREMENT=100015 DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin COMMENT='用户消息表';
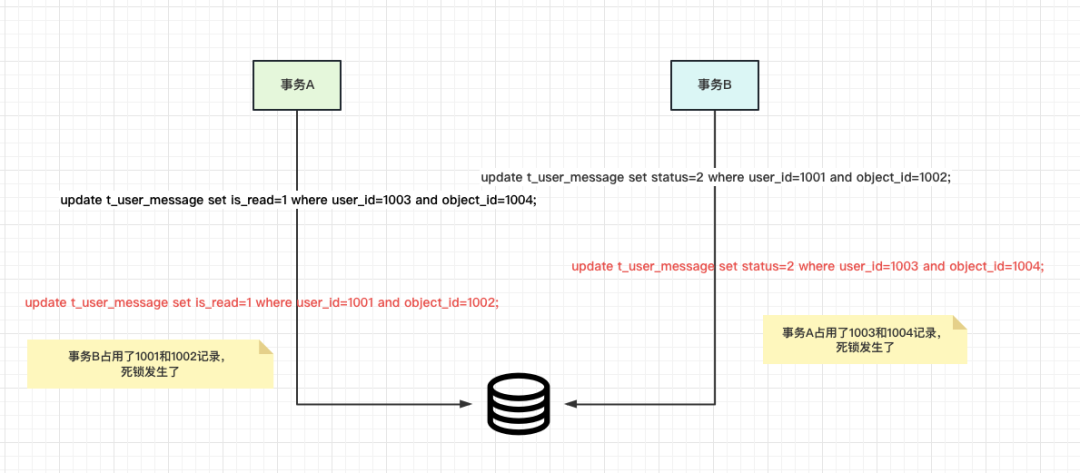
假设我们的会话A执行了以下事务操作:
START TRANSACTION;
//更新用户的消息状态,从未读变为已读update t_user_message set is_read=1 where user_id=1003 and object_id=1004;//...中间有些别的业务操作update t_user_message set is_read=1 where user_id=1001 and object_id=1002;
commit;
而此时我们的会话B在执行一个异步的消息是否合法的检测工作,具体操作如下:
set autocommit=0;START TRANSACTION;
//定时任务更新用户的消息审核状态,从未审核变为审核通过
update t_user_message set status=2 where user_id=1001 and object_id=1002;//...中间有些别的业务操作update t_user_message set status=2 where user_id=1003 and object_id=1004;
commit;
这两个事务如果并发执行,并发度高的情况下,可能会出现死锁情况,死锁产生的步骤如下图所示:
一般遇到这类情况,我们都会推荐在进行更新的时候,尽可能的避免死锁条件发生,例如调整sql的执行顺序。例如变更为如下操作:
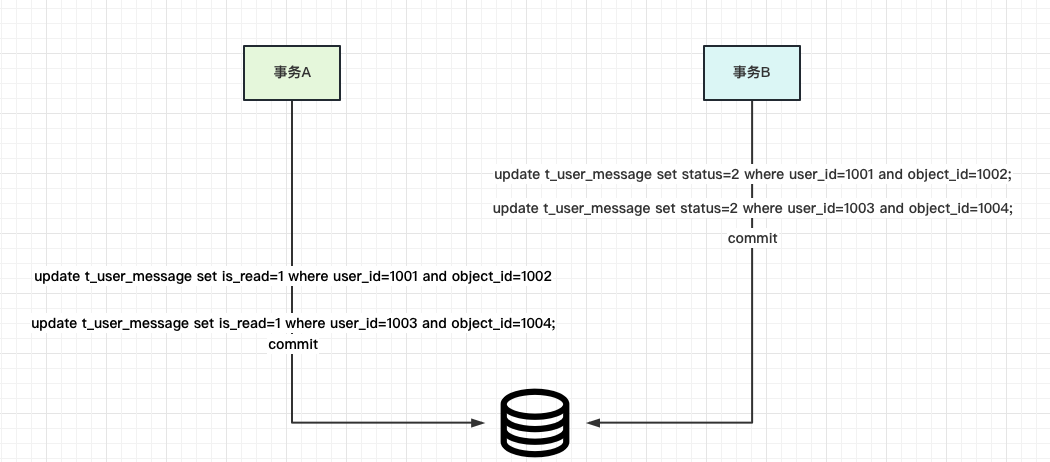
另外,调整顺序后,尽量将本地事务的颗粒度控制到最小,减少因为加锁堵塞带来的性能问题。
首先我们要将当前会话的事务隔离级别设置为可重复读:
set SESSION transaction ISOLATION LEVEL REPEATABLE READ;
如果你想确认当前的会话的事务隔离级别,那么可以使用以下命令去查询:
SELECT @@transaction_isolation; (mysql8.0语法) SELECT @@tx_isolation; (mysql5.7语法)
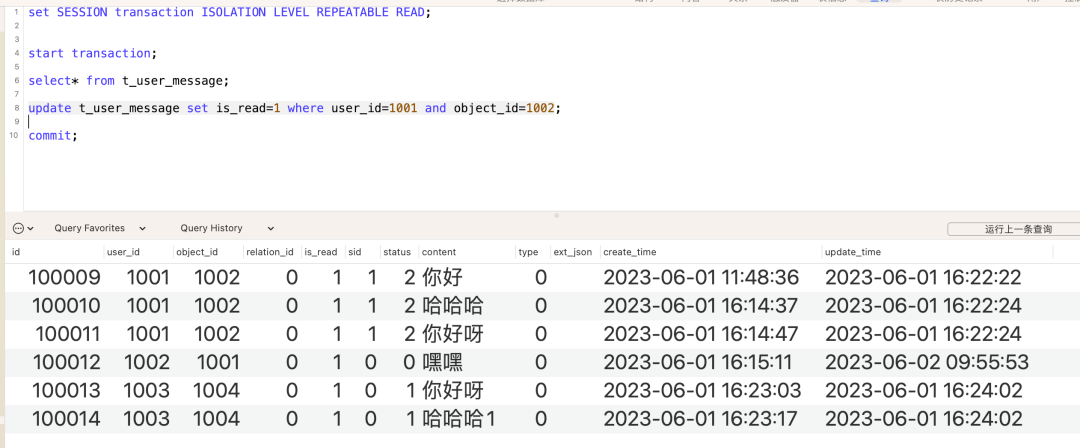
还是针对我们的消息表t_user_message,在某些高并发场景下,如果使用可重复读的话,尤其是事务场景中,出现死锁的概率会加大。例如下边这个场景:
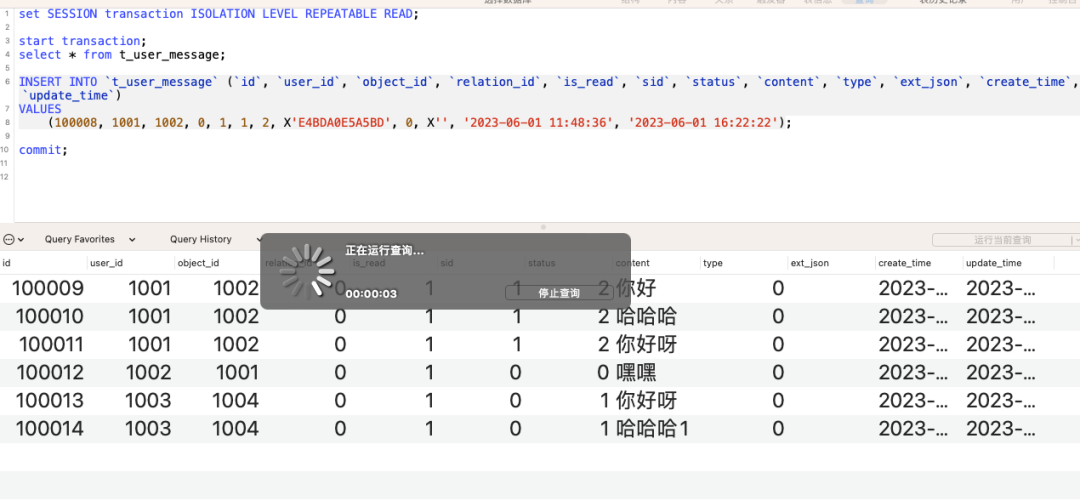
事务1中,对消息表的可读状态进行修改,修改的是记录表中的前3条数据,由于是可重复读,以及非唯一索引user_id和object_id所以这里会锁住的是(0,100011]这个区间的id记录,也就是说只要我们更新的行是超过了100011 id的都没问题。
但是假设此时有个插入请求,打算往100009之前写入一条记录的话,就会出现间隙锁堵塞的问题,例如下图所示:
产生间隙锁的原因:
在mysql5.7、mysql5.8等5系版本中,
查看死锁代码是:
select * from information_schema.innodb_locks;
查看等待锁的代码:
select * from information_schema.innodb_lock_waits
但是要注意,在mysql 8.0中查看死锁代码变了,如果继续用5.7的代码会提示报错。
Unknown table ‘INNODB_LOCKS’ in information_schema
所以在8.0使用以下代码。
查看死锁:
select * from performance_schema.data_locks;
查看死锁等待时间:
select * from performance_schema.data_lock_waits;










