
最新消息!
在Meta AI发布Code Llama后仅两天的时间,WizardLM 团队基于该模型及其最新的对齐算法训练的WizardCoder-Python 34B V1.0在权威代码生成评测榜单HumanEval上即达到了惊人的 73.2% pass@1分值,同时超越了Claude-2(71.2%), 3月份版本的GPT-4(67.0%), 以及最新的ChatGPT-3.5 (72.5%)。与此同时,WizardCoder 团队也在Github和HuggingFace开源了该模型细节及权重:
Github: https://github.com/nlpxucan/WizardLM/tree/main/WizardCoder
HuggingFace:https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0
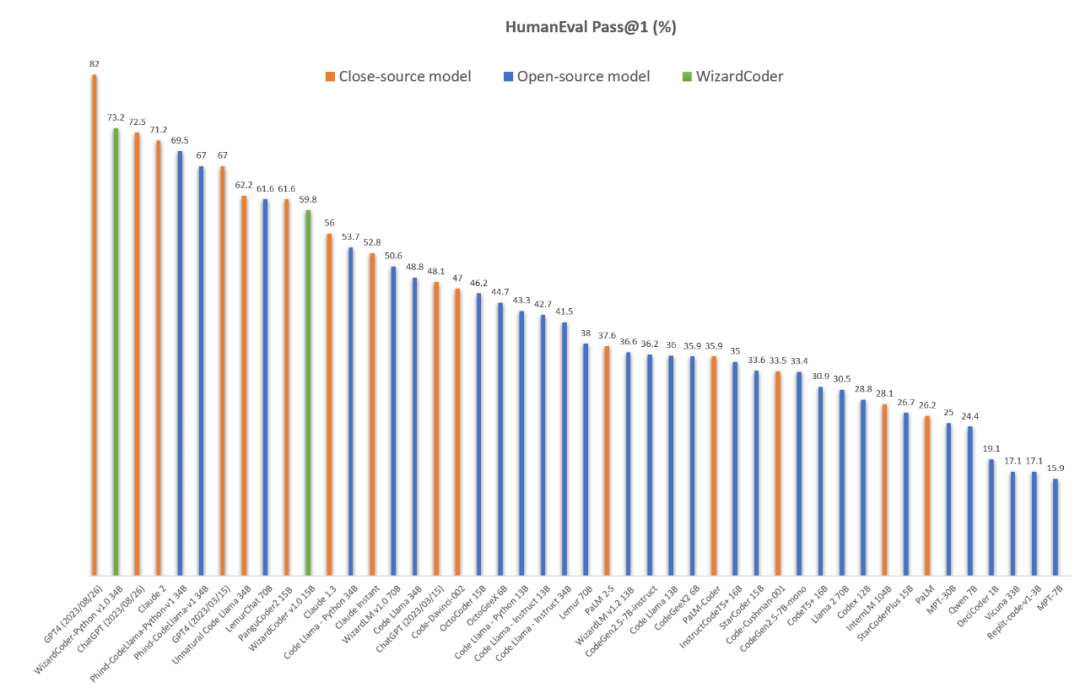
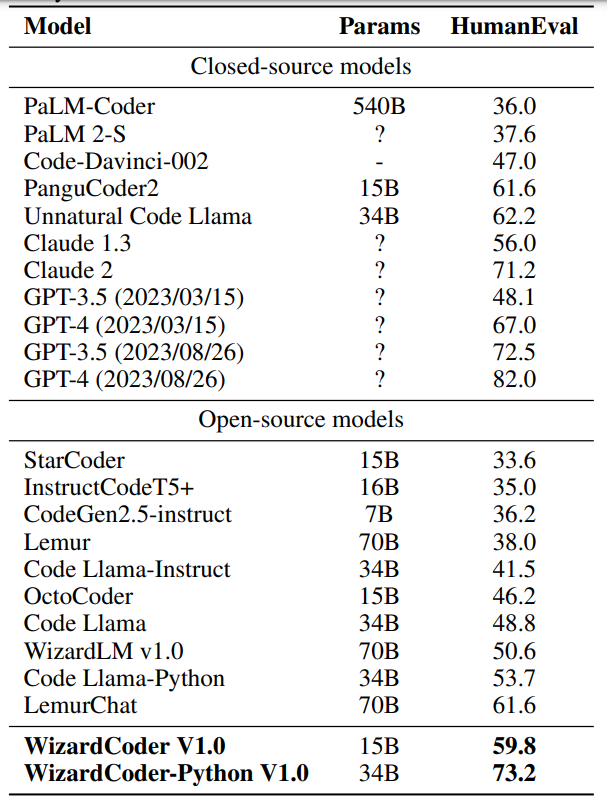
对于该全新代码模型,PaperWeekly团队将进行全面评测,并继续发布详细报道。今天,我们主要介绍Wizard家族的另一位重要成员WizardMath,及其数学能力超越ChatGPT-3.5的RLEIF算法。

前言
作为大语言模型(LLM)最重要也最具挑战性的能力之一,数学推理同时吸引了 AIGC 学术界与工业界广泛研究和关注。根据 OpenAI 相关技术报告,GPT-4 在 GSM8k 和 MATH 基准测试中取得了惊人的成绩,通过率分别高达 92% 和 42% 以上!
与此同时,在开源领域,由 Meta 主导发布的 Llama 2 更进一步提升了开源模型在这一领域的表现,达到了新的先进水平。
然而,作者团队依然注意到,目前最佳开源模型 Llama 2 在 GSM8k 任务上的通过率也仅约为 56.8%,仍远低于包括 GPT-4、ChatGPT、Claude、PalM 2 等在内的一众闭源模型性能。由于数学推理对于计算过程准确度与逻辑推理能力的严苛标准,因此追赶和提升难度也更高。
最近,在 WizardLM 团队相继开源WizardLM和WizardCoder模型后,又开源一款全新的数学推理大模型——WizardMath,它打破了闭源模型的垄断地位,显著超越 OpenAI 的 ChatGPT, Anthropic 的 Claude 以及 Google 的 PaLM 2 等 ,在参数只有 700 亿远不及他们情况之下,成为新时代的开源领军者。
距离 WizardLM 宣布团队开源 WizardMath 仅 5 天,该模型即获得了大模型社区广泛的关注与认可。
著名 CMU 科学家,MXNet,XGBooST,TVM 等著名项目创建者,以及 OctoML 首席科学家陈天奇也祝贺 WizardMath 在开源大模型数学领域的突破。甚至著名科学家 Yam Peleg 也详细解读并转发 WizardMath 的论文:
也有国外大佬 Charles H. Martin 转发了 WizardMath 论文:
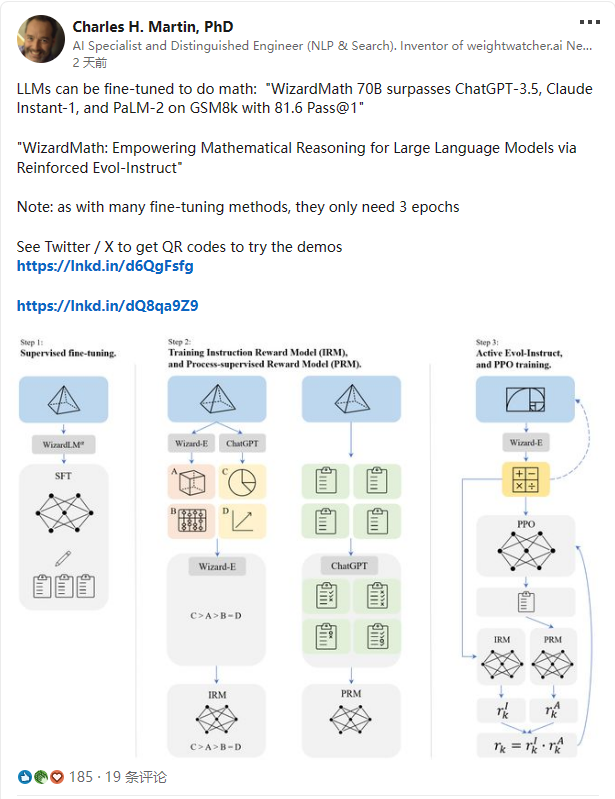
RLEIF(Reinforced Evol-Instruct)方法
WizardMath 取得成功主要依靠的就是一种成为 RLEIF 的全新强化学习方法。受 WizardLM 的 Evol-instruct 和 OpenAI 过程监督的强化学习 PRMs 的启发,作者提出一个新范式:基于强化学习的指令进化方法 Reinforced Evol-Instruct,旨在增强 LLaMA-2 数学推理能力,如 Figure 1 表示,主要包含三步: 3)进行 Active Evol-Instruct 和 PPO 训练
1. SFT:按照 InstructGPT,作者首先用生成的有监督指令对 Llama 2 进行微调,包含两部分:
2. 数学指令进化范式:为了增加指令数据的复杂度和多样性,同时受该团队另外两篇工作 WizardLM 和 WizardCoder 指令进化的启发,从两个方面进行着手:
3. 受 InstructGPT 和 PRMs 启发,训练两个奖励模型来预测生成的指令质量和相应答案的每一步正确性:
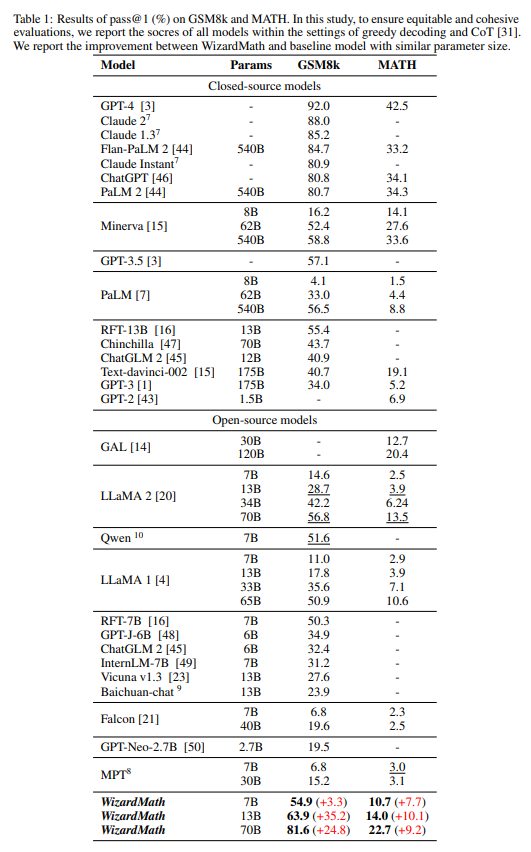
作者主要在两个常用数学推理基准测试集(GSM8k 和 MATH)上评估 WizardMath。GSM8k 数据集包含大约 7500 个训练数据和 1319 个测试数据,主要是小学水平的数学问题,每个问题都由基本的算术运算(加、减、乘、除)组成,一般需要 2 到 8 个步骤来解决。
MATH 数据集收集来自著名数学竞赛问题(如 AMC 10、AMC 12 和 AIME)。它包含 7500 个训练数据和 5000 个具有挑战性的测试数据,涉及七个学术领域:预备代数、代数、数论、计数与概率论、几何学、中级代数和微积分。这些问题被分为五个难度等级,' 1 '表示相对较低的难度等级,' 5 '表示最高的难度等级。
3.2 训练和测试Prompt
训练 WizardMath 的 Prompt 格式来自 Alpaca,如下:
测试时采用了 CoT 方式进行评估,如下:

作者与大量基线模型进行性能比较,包括闭源 LLM 模型:OpenAI 的 GPT-3、GPT-3.5、ChatGPT、GPT-4,谷歌的 PaLM、PaLM 2、Minerva,Anthropic 的 Claude Instant、Claude 1.3、Claude 2, DeepMind 的 Chinchilla;开源 LLM 模型:Llama 1、Llama 2、GAL、GPT-J、GPT-Neo、Vicuna、MPT、Falcon、Baichuan、ChatGLM、Qwen 和 RFT 等。
4.1 与闭源模型比较
表 1 中,在 GSM8k 上,WizardMath 显著超过一些闭源 LLM 模型,包括 OpenAI 的 ChatGPT,Google 的 PaLM 1 和 PaLM 2,Anthropic 的 Claude Instant;同时 WizardMath 目前在所有模型上排名前五,如图二所示。在 MATH 数据集上 WizardMath 70B 超越了 Text-davinci-002.
1. WizardMath 13B 在 GSM8k 上优于 PaLM 1 540B(63.9 vs 56.5)、Minerva 540B(63.9 vs 58.8)和 GPT-3.5(63.9 vs 57.1)。同时,它在 MATH 上超越了 PaLM 1 540B(14.0 vs. 8.8)、GPT-3 175B(14.0 vs. 5.2);2. WizardMath 70B 在 GSM8k 上超过 Claude Instant(81.6 vs 80.9)、ChatGPT(81.6 vs 80.8)和 PaLM 2(81.6 vs 80.7)。同时,WizardMath 70B 在 MATH 上超过了 Text-davinci-002(22.7 比 19.1)。
4.2 与开源模型比较
表 1 中所示的结果表明,WizardMath 70B 在 GSM8k 和 MATH 基准测试中大幅度超过所有开源模型。详细结果如下:1. WizardMath 7B 超越了大多数参数量从 7B 到 40B 之间的开源模型,包括 MPT、Falcon、Baichuan-chat、Vicuna v1.3、ChatGLM 2、Qwen、Llama 1 和 Llama 2;2. WizardMath 13B 在 GSM8k 上明显优于 Llama 1 65B(63.9 vs. 50.9)和 Llama 2 70B(63.9 vs. 56.8)。同时它在 MATH 上的表现远远优于 Llama 1 65B(14.0 vs. 10.6)和 Llama 2 70B(14.0 vs. 13.5);3. WizardMath 70B 在 GSM8k 上超越了 Llama 2 70B(81.6 vs. 56.8),提升 24.8 个点。同时它在数学方面也比 Llama 2 70B(22.7 比 13.5)高出 9.2个点。
WizardLM 团队在开源 LLM 研发上表现异常耀眼,多项世界公认大模型基准能力测评中比肩闭源巨头(OpenAI 和 Anthropic), 这到底是怎么样的一个团队,对于大模型技术有怎样的理解和认知,外界多有好奇。PaperWeekly 有幸采访到该团队负责人,来自微软的大模型专家徐粲来深入解读 WizardLM 背后的技术原理。

徐粲,微软高级应用科学家,之前曾在微软小冰和微软亚研院从事聊天机器人系统研究。在 NeurIPS、ICLR、ACL、EMNLP、CVPR、ICCV 等国际学术顶级会议发表论文 30 余篇,谷歌总引用 1300+ 次。
| PaperWeekly:最近我们注意到 WizardMath 在国际认可的数学基准 Gsm8k 上面超过了 ChatGPT 3.5,使用了一种称为 RLEIF 的强化学习方法,它跟 OpenAI 提出的 RLHF 方法有什么优势? 徐粲:OpenAI 的 RLHF 和 Claude 的 RLAIF(AI 代替人类作为反馈器)是强化学习做对齐的代表性工作,这两种方法我们亲测都可以显著提升预训练后的 LLM 在各种场景的表现,但这两种强化学习方法只在 response 空间进行探索获得使得 reward 最大的策略。而我们提出的 RLEIF 不仅在 response 空间做搜索,也在指令(instruction)空间进行搜索,这样可以保证相比于 RLHF 能够探索到更优的学习策略。
| PaperWeekly:从 Evol-Instuct 到新近的 RLEIF,和大部分做大模型团队强调参数量和数据相比,似乎你们更看重独创性的方法?大部分人似乎觉得大模型只要参数量足够多,数据质量足够好就可以取得很好的效果。 徐粲:我本人比较认可竞争优势来自于差异化的认知,参数量越大,数据质量越高肯定大模型训练效果越好,我并不反对这种观点,但是这种观点几乎为所有人所知晓,这一点无法构成优势。从一开始做 WizardLM 我就想的比较清楚,如果沿用 OpenAI PreTrain-SFT-RLHF 的框架,作为后来追赶者几乎是鲜有机会胜出的,唯有自创流派自建技术体系才能形成差异化优势,我从现实场景中 ChatGPT 处理较复杂指令吃力这一点入手,提出“指令进化论”,像生物进化历程一样,逐步由简单指令进化成复杂指令进行大模型训练,这种方式可以在不增加参数量的情况下大幅提升模型能力。后来我们在指令近进化的框架下又完成了强化学习版本 RLEIF,进一步提升了指令进化的效力。后续我们还会围绕指令进化的方方面面做出改进,做出更强的指令进化术使得单位参数量拥有更强的模型性能。
| PaperWeekly:看样子未来我们可以看到更多版本的 Evol-Instruct。Evol-Instruct 最早版本使用了 ChatGPT 的输出作为回复,而在最新的 WizardMath 中已经几乎不再使用 ChatGPT,这种变化的出发点是什么? 徐粲:首先,ChatGPT 输出的质量并不是绝对的高,尤其是数学等较为高精尖的领域,ChatGPT 的回复质量其实并不十分理想。随着我们 Wizard 家族模型水平逐步提升,通过解码出大量回复加质量筛选的模式我们自己模型输出的回复质量慢慢地已经达到 ChatGPT 水平,慢慢地实现了对 ChatGPT 回复的替代。我们还用少量的 ChatGPT 来帮助我们进行指令进化,之如前面所说,“指令进化”是我们技术体系的核心,我们慢慢地也在构建自己的指令进化器即 RLEIF 里面的 Wizard-E 模型,它在指令进化上面可以做的比 ChatGPT 还要好。
|
PaperWeekly:早在网上爆料出 GPT4 采用多专家的 MOE 架构之前,似乎 WizardLM 就已经在考虑多专家发展路线,很早推出了 WizardCoder 这一专注 coding 的模型,到最近专注数学的 WizardMath 模型,这块你们当时具体的考虑是怎么样的? 徐粲:我不太喜欢 MOE 的架构,因为它会带来参数量的增大,让模型变笨重。我们很早就注意到大模型的后预训练中有一种“技能墙”效应的存在。和人类学习知识过程不太一样,大模型学习不同门类的技能不一定会相互促进,反而有时候会相互伤害。多专家+MOE 的架构是一种有效的破除技能墙的方法,除了低效外。在最开始 Wizard 家族做多专家时候我们确实是奔着组 MOE 去的,但我们也在积极寻找更好的办法来破除技能墙,如果能够找到或许就不会再像 GPT4一 样采取 MOE 架构。
| PaperWeekly:现在 Wizard 大模型家族已经有三位成员,后续还会有第四位成员吗? 徐粲:目前有第四位成员的计划,但是还没有完全想清楚它的特点,前三位成员定位清晰且已经都有很大的 scope。
| PaperWeekly:WizardMath 如果专注于数学领域,似乎它的 scope 并不是很大? 徐粲:数学本身就是极其庞大深奥且足够底层的学科。目前 WizardMath 主要能力还是在解决给定的数学问题上面,如何自己发现问题,提出假设,进行推导验证这一整套数学研究的流程 WizardMath 后续还会深入的学习,另外 WizardMath,我期望它的未来长期规划是在多个理工科学科(如物理,化学,生物等)上面达到博士的水平,将来会逐步成长为综合性科学推理计算平台,来帮助人类理解、处理各种深奥复杂的科学事务。当 WizardMath 在各个学科都有了一定积累后,我们会让它去参加一些国内外的大学或者职业考试来检验自己的学习成果。
| PaperWeekly:我看你提到一个推理计算平台的概念,似乎你并不认为它仅仅是一个模型。徐粲:对,我认为对于大模型来说,模型即应用即平台。太多人将模型,应用,平台三者割裂来看,其实我对 Wizard 家族规划成多专家除了做 MOE 的考虑外,更多是希望其往不同的应用平台能力去发展,比如 WizardLM 其擅长语言能力,除了基础的语言功底外,可以慢慢地发展出情感计算,虚拟人格,虚拟世界,成为综合性语言平台,任何跟语言能力强相关的应用它都可以完成。类似地,WizardMath 除了帮你解题外,还可以帮你做理财,做数据分析,任何你可以用语言定义的应用需求,本质上大语言模型都可以直接帮你处理完成,这种情况下大语言模型本身就一个应用平台旗舰。WizardCoder 后续除了基本的帮你写代码外,我对他后续期望和规划是逐步成长为完全的自动 agent 可以在互联网世界自由行动。
| PaperWeekly:我们看到,现在基于全新的Code Llama训练的WizardCoder-Python 34B模型,在代码生成领域同时击败了GPT-4与Claude-2,那么拥有最强代码模型后,你们接下来的计划是什么呢?徐粲:是的,WizardCoder在最权威的HumanEval上超越了GPT-4的3月份版本,但是我们依然需要认识到GPT-4的强大,它其实一直在进化,根据我们的评测,最新的GPT-4已经达到了82%的HumanEval pass@1,这就是我们接下来的关键目标之一。而对于Claude,我们也是同样的态度。
| PaperWeekly:WizardLM是开源LLM顶级对齐团队,OpenAI刚刚成立了Superalignment团队来加大对齐领域的投入,你们后续在预训练方面有没有打算或者投入?
徐粲:
我们其实已经开始在预训练技术上展开研究,但是我们的方法会和主流预训练方法不太一样。因为我们的后预训练阶段基于指令进化论构建,我们在预训练阶段也会引入相应的指令进化方法,一边对预训练语料进行进化形变,一边进行预训练,以期望彻底打开指令进化的所有空间和可能性。
| PaperWeekly:目前来看,你们主要在语言大模型发力,未来在多模态大模型领域,你们后续会进行研发投入吗? 徐粲:我们在多模态领域有计划,目前也在结合语言大模型和视觉大模型做一些新形态的应用尝试,很快我们会发布我们的 beta 测试版。
| PaperWeekly:目前开源 LLM 进展飞速,你们作为开源 LLM 非常活跃的一分子。怎么看待像 OpenAI,Claude 等闭源 LLM 和开源 LLM 的未来? 徐粲:完全预测闭源开源 LLM 的未来是非常难的一件事情。只能说从目前情况来看,Stability AI 的 FreeWilly2 在 mmlu 上面超过了 ChatGPT3.5,SqlCoder 在 text2sql 上超过了 ChatGPT 3.5,我们 WizardMath 也在 Gsm8k 上面击败了 ChatGPT3.5,Wizardcoder在HumanEval上击败了最新的ChatGPT-3.5和3月版本的GPT-4, 越来越多的开源 LLM 在慢慢突破闭源 LLM 的门槛 ChatGPT3.5,如果后续闭源 LLM 不能通过进一步提升参数规模来获得显著性能提升,将会感受到来自开源 LLM 社区更大的压力。

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧










