
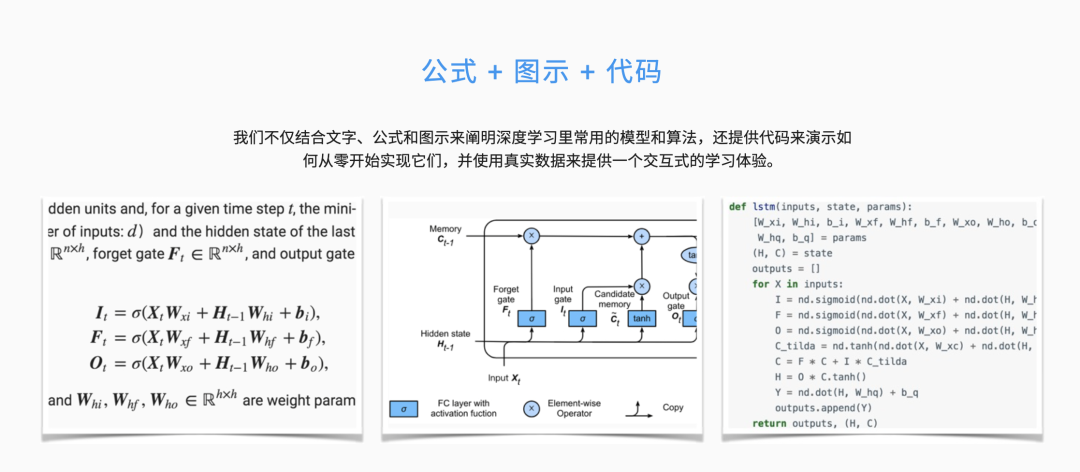
向AI转型的程序员都关注了这个号👇👇👇
预备知识
要学习深度学习,首先需要先掌握一些基本技能。所有机器学习方法都涉及从数据中提取信息。因此,我们先学习一些关于数据的实用技能,包括存储、操作和预处理数据。
机器学习通常需要处理大型数据集。我们可以将某些数据集视为一个表,其中表的行对应样本,列对应属性。线性代数为人们提供了一些用来处理表格数据的方法。我们不会太深究细节,而是将重点放在矩阵运算的基本原理及其实现上。
深度学习是关于优化的学习。对于一个带有参数的模型,我们想要找到其中能拟合数据的最好模型。在算法的每个步骤中,决定以何种方式调整参数需要一点微积分知识。本章将简要介绍这些知识。幸运的是,autograd包会自动计算微分,本章也将介绍它。
机器学习还涉及如何做出预测:给定观察到的信息,某些未知属性可能的值是多少?要在不确定的情况下进行严格的推断,我们需要借用概率语言。
最后,官方文档提供了本书之外的大量描述和示例。在本章的结尾,我们将展示如何在官方文档中查找所需信息。
本书对读者数学基础无过分要求,只要可以正确理解深度学习所需的数学知识即可。但这并不意味着本书中不涉及数学方面的内容,本章会快速介绍一些基本且常用的数学知识, 以便读者能够理解书中的大部分数学内容。如果读者想要深入理解全部数学内容,可以进一步学习本书数学附录中给出的数学基础知识。
目录
简介
阅读指南
1. 深度学习简介
2. 预备知识
2.1 环境配置
2.2 数据操作
2.1. 数据操作
2.1.1. 入门
2.1.2. 运算符
2.1.3. 广播机制
2.1.4. 索引和切片
2.1.5. 节省内存
2.1.6. 转换为其他Python对象
2.1.7. 小结
2.1.8. 练习
2.2. 数据预处理
2.2.1. 读取数据集
2.2.2. 处理缺失值
2.2.3. 转换为张量格式
2.2.4. 小结
2.2.5. 练习
2.3. 线性代数
2.3.1. 标量
2.3.2. 向量
2.3.3. 矩阵
2.3.4. 张量
2.3.5. 张量算法的基本性质
2.3.6. 降维
2.3.7. 点积(Dot Product)
2.3.8. 矩阵-向量积
2.3.9. 矩阵-矩阵乘法
2.3.10. 范数
2.3.11. 关于线性代数的更多信息
2.3.12. 小结
2.3.13. 练习
2.4. 微积分
2.4.1. 导数和微分
2.4.2. 偏导数
2.4.3. 梯度
2.4.4. 链式法则
2.4.5. 小结
2.4.6. 练习
2.5. 自动微分
2.5.1. 一个简单的例子
2.5.2. 非标量变量的反向传播
2.5.3. 分离计算
2.5.4. Python控制流的梯度计算
2.5.5. 小结
2.5.6. 练习
2.6. 概率
2.6.1. 基本概率论
2.6.2. 处理多个随机变量
2.6.3. 期望和方差
2.6.4. 小结
2.6.5. 练习
2.7. 查阅文档
2.7.1. 查找模块中的所有函数和类
2.7.2. 查找特定函数和类的用法
2.7.3. 小结
2.7.4. 练习
2.3 自动求梯度
3. 深度学习基础
3.1 线性回归
3.2 线性回归的从零开始实现
3.3 线性回归的简洁实现
3.4 softmax回归
3.5 图像分类数据集(Fashion-MNIST)
3.6 softmax回归的从零开始实现
3.7 softmax回归的简洁实现
3.8 多层感知机
3.9 多层感知机的从零开始实现
3.10 多层感知机的简洁实现
3.11 模型选择、欠拟合和过拟合
3.12 权重衰减
3.13 丢弃法
3.14 正向传播、反向传播和计算图
3.15 数值稳定性和模型初始化
3.16 实战Kaggle比赛:房价预测
4. 深度学习计算
4.1 模型构造
4.2 模型参数的访问、初始化和共享
4.3 模型参数的延后初始化
4.4 自定义层
4.5 读取和存储
4.6 GPU计算
5. 卷积神经网络
5.1 二维卷积层
5.2 填充和步幅
5.3 多输入通道和多输出通道
5.4 池化层
5.5 卷积神经网络(LeNet)
5.6 深度卷积神经网络(AlexNet)
5.7 使用重复元素的网络(VGG)
5.8 网络中的网络(NiN)
5.9 含并行连结的网络(GoogLeNet)
5.10 批量归一化
5.11 残差网络(ResNet)
5.12 稠密连接网络(DenseNet)
6. 循环神经网络
6.1 语言模型
6.2 循环神经网络
6.3 语言模型数据集(周杰伦专辑歌词)
6.4 循环神经网络的从零开始实现
6.5 循环神经网络的简洁实现
6.6 通过时间反向传播
6.7 门控循环单元(GRU)
6.8 长短期记忆(LSTM)
6.9 深度循环神经网络
6.10 双向循环神经网络
7. 优化算法
7.1 优化与深度学习
7.2 梯度下降和随机梯度下降
7.3 小批量随机梯度下降
7.4 动量法
7.5 AdaGrad算法
7.6 RMSProp算法
7.7 AdaDelta算法
7.8 Adam算法
8. 计算性能
8.1 命令式和符号式混合编程
8.2 异步计算
8.3 自动并行计算
8.4 多GPU计算
9. 计算机视觉
9.1 图像增广
9.2 微调
9.3 目标检测和边界框
9.4 锚框
9.5 多尺度目标检测
9.6 目标检测数据集(皮卡丘)
9.7 单发多框检测(SSD)
9.8 区域卷积神经网络(R-CNN)系列
9.9 语义分割和数据集
9.10 全卷积网络(FCN)
9.11 样式迁移
9.12 实战Kaggle比赛:图像分类(CIFAR-10)
9.13 实战Kaggle比赛:狗的品种识别(ImageNet Dogs)
10. 自然语言处理
10.1 词嵌入(word2vec)
10.2 近似训练
10.3 word2vec的实现
10.4 子词嵌入(fastText)
10.5 全局向量的词嵌入(GloVe)
10.6 求近义词和类比词
10.7 文本情感分类:使用循环神经网络
10.8 文本情感分类:使用卷积神经网络(textCNN)
10.9 编码器—解码器(seq2seq)
10.10 束搜索
10.11 注意力机制
10.12 机器翻译
11. 优化算法
截止到目前,本书已经使用了许多优化算法来训练深度学习模型。优化算法使我们能够继续更新模型参数,并使损失函数的值最小化。这就像在训练集上评估一样。事实上,任何满足于将优化视为黑盒装置,以在简单的设置中最小化目标函数的人,都可能会知道存在着一系列此类“咒语”(名称如“SGD”和“Adam”)。
但是,为了做得更好,还需要更深入的知识。优化算法对于深度学习非常重要。一方面,训练复杂的深度学习模型可能需要数小时、几天甚至数周。优化算法的性能直接影响模型的训练效率。另一方面,了解不同优化算法的原则及其超参数的作用将使我们能够以有针对性的方式调整超参数,以提高深度学习模型的性能。
在本章中,我们深入探讨常见的深度学习优化算法。深度学习中出现的几乎所有优化问题都是非凸的。尽管如此,在凸问题背景下设计和分析算法是非常有启发性的。正是出于这个原因,本章包括了凸优化的入门,以及凸目标函数上非常简单的随机梯度下降算法的证明。
11.1. 优化和深度学习
11.1.1. 优化的目标
11.1.2. 深度学习中的优化挑战
11.1.3. 小结
11.1.4. 练习
11.2. 凸性
11.2.1. 定义
11.2.2. 性质
11.2.3. 约束
11.2.4. 小结
11.2.5. 练习
11.3. 梯度下降
11.3.1. 一维梯度下降
11.3.2. 多元梯度下降
11.3.3. 自适应方法
11.3.4. 小结
11.3.5. 练习
11.4. 随机梯度下降
11.4.1. 随机梯度更新
11.4.2. 动态学习率
11.4.3. 凸目标的收敛性分析
11.4.4. 随机梯度和有限样本
11.4.5. 小结
11.4.6. 练习
11.5. 小批量随机梯度下降
11.5.1. 向量化和缓存
11.5.2. 小批量
11.5.3. 读取数据集
11.5.4. 从零开始实现
11.5.5. 简洁实现
11.5.6. 小结
11.5.7. 练习
11.6. 动量法
11.6.1. 基础
11.6.2. 实际实验
11.6.3. 理论分析
11.6.4. 小结
11.6.5. 练习
11.7. AdaGrad算法
11.7.1. 稀疏特征和学习率
11.7.2. 预处理
11.7.3. 算法
11.7.4. 从零开始实现
11.7.5. 简洁实现
11.7.6. 小结
11.7.7. 练习
11.8. RMSProp算法
11.8.1. 算法
11.8.2. 从零开始实现
11.8.3. 简洁实现
11.8.4. 小结
11.8.5. 练习
11.9. Adadelta
11.9.1. Adadelta算法
11.9.2. 代码实现
11.9.3. 小结
11.9.4. 练习
11.10. Adam算法
11.10.1. 算法
11.10.2. 实现
11.10.3. Yogi
11.10.4. 小结
11.10.5. 练习
11.11. 学习率调度器
11.11.1. 一个简单的问题
11.11.2. 学习率调度器
11.11.3. 策略
11.11.4. 小结
11.11.5. 练习
12. 计算性能
在深度学习中,数据集和模型通常都很大,导致计算量也会很大。因此,计算的性能非常重要。本章将集中讨论影响计算性能的主要因素:命令式编程、符号编程、 异步计算、自动并行和多GPU计算。通过学习本章,对于前几章中实现的那些模型,可以进一步提高它们的计算性能。例如,我们可以在不影响准确性的前提下,大大减少训练时间。
12.1. 编译器和解释器
12.1.1. 符号式编程
12.1.2. 混合式编程
12.1.3. Sequential的混合式编程
12.1.4. 小结
12.1.5. 练习
12.2. 异步计算
12.2.1. 通过后端异步处理
12.2.2. 障碍器与阻塞器
12.2.3. 改进计算
12.2.4. 小结
12.2.5. 练习
12.3. 自动并行
12.3.1. 基于GPU的并行计算
12.3.2. 并行计算与通信
12.3.3. 小结
12.3.4. 练习
12.4. 硬件
12.4.1. 计算机
12.4.2. 内存
12.4.3. 存储器
12.4.4. CPU
12.4.5. GPU和其他加速卡
12.4.6. 网络和总线
12.4.7. 更多延迟
12.4.8. 小结
12.4.9. 练习
12.5. 多GPU训练
12.5.1. 问题拆分
12.5.2. 数据并行性
12.5.3. 简单网络
12.5.4. 数据同步
12.5.5. 数据分发
12.5.6. 训练
12.5.7. 小结
12.5.8. 练习
12.6. 多GPU的简洁实现
12.6.1. 简单网络
12.6.2. 网络初始化
12.6.3. 训练
12.6.4. 小结
12.6.5. 练习
12.7. 参数服务器
13. 计算机视觉
近年来,深度学习一直是提高计算机视觉系统性能的变革力量。 无论是医疗诊断、自动驾驶,还是智能滤波器、摄像头监控,许多计算机视觉领域的应用都与我们当前和未来的生活密切相关。 可以说,最先进的计算机视觉应用与深度学习几乎是不可分割的。 有鉴于此,本章将重点介绍计算机视觉领域,并探讨最近在学术界和行业中具有影响力的方法和应用。
在 6节和 7节中,我们研究了计算机视觉中常用的各种卷积神经网络,并将它们应用到简单的图像分类任务中。 本章开头,我们将介绍两种可以改进模型泛化的方法,即图像增广和微调,并将它们应用于图像分类。 由于深度神经网络可以有效地表示多个层次的图像,因此这种分层表示已成功用于各种计算机视觉任务,例如目标检测(object detection)、语义分割(semantic segmentation)和样式迁移(style transfer)。 秉承计算机视觉中利用分层表示的关键思想,我们将从物体检测的主要组件和技术开始,继而展示如何使用完全卷积网络对图像进行语义分割,然后我们将解释如何使用样式迁移技术来生成像本书封面一样的图像。 最后在结束本章时,我们将本章和前几章的知识应用于两个流行的计算机视觉基准数据集。
14. 自然语言处理:预训练
人与人之间需要交流。出于人类这种基本需要,每天都有大量的书面文本产生。比如,社交媒体、聊天应用、电子邮件、产品评论、新闻文章、 研究论文和书籍中的丰富文本, 使计算机能够理解它们以提供帮助或基于人类语言做出决策变得至关重要。
自然语言处理是指研究使用自然语言的计算机和人类之间的交互。在实践中,使用自然语言处理技术来处理和分析文本数据是非常常见的, 例如 8.3节的语言模型 和 9.5节的机器翻译模型。
要理解文本,我们可以从学习它的表示开始。利用来自大型语料库的现有文本序列, 自监督学习
(self-supervised learning) 已被广泛用于预训练文本表示, 例如通过使用周围文本的其它部分来预测文本的隐藏部分。通过这种方式,模型可以通过有监督地从海量文本数据中学习,而不需要昂贵的标签标注!
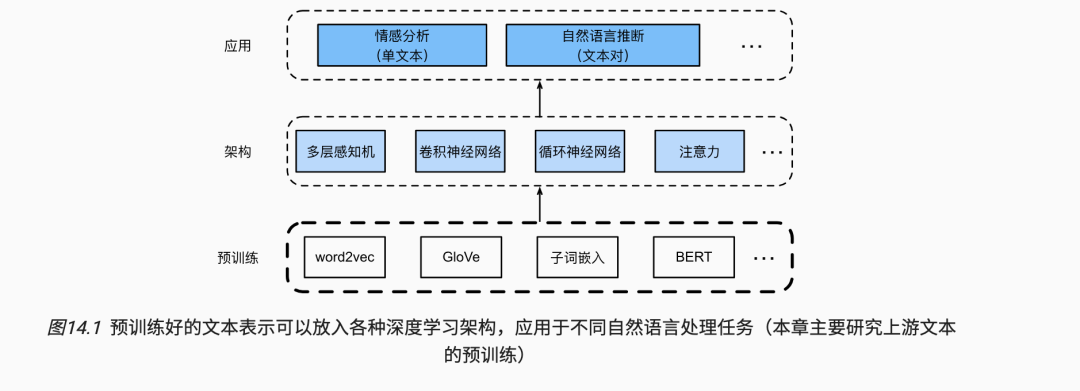
本章我们将看到:当将每个单词或子词视为单个词元时, 可以在大型语料库上使用word2vec、GloVe或子词嵌入模型预先训练每个词元的词元。经过预训练后,每个词元的表示可以是一个向量。但是,无论上下文是什么,它都保持不变。例如,“bank”(可以译作银行或者河岸)的向量表示在 “go to the bank to deposit some money”(去银行存点钱) 和“go to the bank to sit down”(去河岸坐下来)中是相同的。因此,许多较新的预训练模型使相同词元的表示适应于不同的上下文, 其中包括基于Transformer编码器的更深的自监督模型BERT。在本章中,我们将重点讨论如何预训练文本的这种表示, 如 图14.1中所强调的那样。
环境
matplotlib==3.3.2
torch==1.1.0
torchvision==0.3.0
torchtext==0.4.0
CUDA Version==11.0
参考(大家可以在这里下载代码)
本书PyTorch实现:Dive-into-DL-PyTorch
https://github.com/ShusenTang/Dive-into-DL-PyTorch
本书TendorFlow2.0实现:Dive-into-DL-TensorFlow2.0
https://github.com/TrickyGo/Dive-into-DL-TensorFlow2.0
原书地址(大家可以在这里阅读电子版PDF内容)
中文版:动手学深度学习
https://github.com/ShusenTang/Dive-into-DL-PyTorch
Github仓库
https://github.com/TrickyGo/Dive-into-DL-TensorFlow2.0
English Version: Dive into Deep Learning
https://zh.d2l.ai/
Github Repo
https://github.com/d2l-ai/d2l-en
阅读指南
和原书一样,docs内容大体可以分为3个部分:
第一部分(第1章至第3章)涵盖预备工作和基础知识。第1章介绍深度学习的背景。第2章提供动手学深度学习所需要的预备知识。第3章包括深度学习最基础的概念和技术,如多层感知机和模型正则化。如果读者时间有限,并且只想了解深度学习最基础的概念和技术,那么只需阅读第一部分。
第二部分(第4章至第6章)关注现代深度学习技术。第4章描述深度学习计算的各个重要组成部分,并为实现后续更复杂的模型打下基础。第5章解释近年来令深度学习在计算机视觉领域大获成功的卷积神经网络。第6章阐述近年来常用于处理序列数据的循环神经网络。阅读第二部分有助于掌握现代深度学习技术。
第三部分(第7章至第10章)讨论计算性能和应用。第7章评价各种用来训练深度学习模型的优化算法。第8章检验影响深度学习计算性能的几个重要因素。第9章和第10章分别列举深度学习在计算机视觉和自然语言处理中的重要应用。这部分内容读者可根据兴趣选择阅读。
下图描绘了《动手学深度学习》的结构。
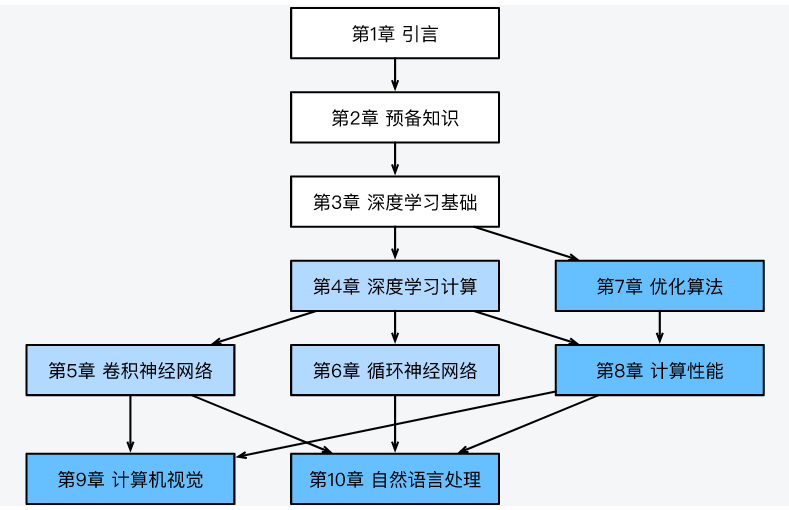
上图中由甲章指向乙章的箭头表明甲章的知识有助于理解乙章的内容。
如果读者想短时间了解深度学习最基础的概念和技术,只需阅读第1章至第3章;
如果读者希望掌握现代深度学习技术,还需阅读第4章至第6章。
第7章至第10章读者可以根据兴趣选择阅读。
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
《深度学习:基于Keras的Python实践》PDF和代码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx










