ChatGPT在自然语言生成应用场景下的生成内容在现有著作权法系统下无法构成“作品”,内容生产和模型训练分别对著作权核心理念和合理使用原则提出了挑战,生成内容的利用有可能引发道德和著作权侵权风险。本文就ChatGPT生成内容的网络传播侵权风险及可版权性进行探讨,供实务参考。
“ChatGPT”火爆网络,成为最引人关注的名词及应用之一。根据UBS发布的研究报告显示,ChatGPT在2023年1月份的活跃用户数已达1亿,成为目前史上用户数增长最快的消费者应用。ChatGPT在自然语言生成应用场景下的生成内容在现有著作权法系统下无法构成“作品”,内容生产和模型训练分别对著作权核心理念和合理使用原则提出了挑战,生成内容的利用有可能引发道德和著作权侵权风险。
- 1 -
ChatGPT的内涵
ChatGPT是由人工智能研究实验室OpenAI(OpenAI于2015年由马斯克、美国创业孵化器YCombinator总裁阿尔特曼、全球在线支付平台PayPal联合创始人彼得·蒂尔等硅谷科技大亨创立)在2022年11月30号发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。ChatGPT能学习和理解人类的语言,像人类一样进行聊天交流,并能根据上下文与人类进行互动。
但如果仅仅将ChatGPT理解为聊天机器人就过于狭隘了,ChatGPT被大量运用于各类应用场景,如智能客服,不仅能回答客户的问题,还能依据客户的意图和情绪,提供交互式、人性化、24小时不间断的服务;文本生成,可以自动生成各种类型的文本,包括新闻报道、小说、演讲稿、诗歌、散文、论文甚至法律意见书等;语音识别与生成,可以智能识别语音并做出相应的回应;数据分析与营销决策支持,利用ChatGPT可以进行数据分析和挖掘,并根据数据分析和挖掘的结果,生成数据可视化和报告,为营销决策提供支持。ChatGPT亦被广泛应用于各行各业,如教育行业、金融行业、医疗行业、传媒行业等。
ChatGPT需要大量的数据形成训练集进行模型训练,通过对训练集的深度学习掌握人类语言的语法、语义及使用习惯,并在此基础上,通过使用Transformer模型来构建ChatGPT自身的语言模型,再通过语言模型处理用户的输入及回答的输出(见下图)。
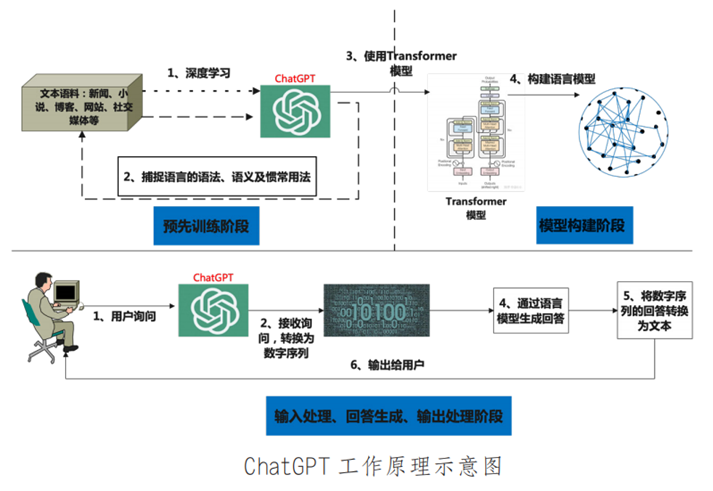
- 2 -
信息挖掘的合法性
ChatGPT在对整个互联网信息挖掘的过程中,不免会涉及到享有著作权的作品。若未经权利主体的授权,直接在“信息挖掘”得到的文本、图片基础上创作得到的内容,存在侵犯原著作权人的信息网络传播权的风险。
根据2021年施行的《最高人民法院关于审理侵害信息网络传播权民事纠纷案件适用法律若干问题的规定》第3条, 网络用户、网络服务提供者未经许可,通过信息网络提供权利人享有信息网络传播权的作品、表演、录音录像制品,除法律、行政法规另有规定外,人民法院应当认定其构成侵害信息网络传播权行为。
在尚不存在相关判例的情况下,我们可以通过研究相似模式的“深度链接”行为,探讨ChatGPT是否存在侵犯原作者信息网络传播权的风险。
所谓深度链接,是指设链网站绕过被链网站首页,直接链接到被链网站深层页面,使用户在不脱离设链网站页面的情况下获取被链网站的信息内容。
ChatGPT通过对相关信息的抓取并提供给用户,类似于在所抓取信息与用户之间提供了一个深度链接。而对于深度链接是否侵害信息网络传播权的判断,目前我国司法实践中存在服务器标准、用户感知标准、实质替代标准等多种标准,可用以借鉴参考:
1. 服务器标准
北京知识产权法院在“湖南快乐阳光互动娱乐传媒有限公司与同方股份有限公司著作权纠纷上诉案”中对服务器标准则作出了论述:
服务器标准是指,判断被诉行为是否为信息网络传播行为,应考虑的是被诉内容是否存储于上诉人的服务器中。无论被诉行为的外在表现形式是否使得用户认为被诉内容系由上诉人提供,只要被诉内容未存储在上诉人服务器中,则不应认定上诉人实施了信息网络传播行为。需要指
出的是,此处的“服务器”系广义概念,泛指一切可存储信息的硬件介质,既包括网站服务器,亦包括个人电脑、手机等。
2. 用户感知标准
在“湖南快乐阳光互动娱乐传媒有限公司与同方股份有限公司著作权纠纷上诉案”中,北京知识产权法院同样对用户感知标准作出了论述:
用户感知标准是指,判断被诉行为是否为信息网络传播行为,应考虑网络
用 户的感知,如果被诉行为使得用户认为被诉内容系由上诉人提供,即应认定上诉人实施了信息网络传播行为。该标准通常考虑的是被诉行为的外在表现形式,至于被诉内容是否存储于上诉人服务器中则在所不论。”
3. 实质性替代标准
在“腾讯计算机系统有限公司诉北京易联伟达科技有限公司侵犯信息网络传播权纠纷案”中,北京知识产权法院对实质性替代标准进行了概括:
因选择、编辑、整理等行为、破坏技术措施行为及深层链接行为,对著作权人所造成的损害及为行为人所带来的利益与直接向用户提供作品的行为并无实
质差别,因此,上述行为构成信息网络传播行为。
就ChatGPT而言,可参考借鉴上述链接行为侵权的裁判思路。若确实构成侵犯原著作权人的信息网络传播权,则需要进一步判断是否存在《著作权法》中规定的合理使用、法定许可等情形。
- 3 -
网络公开的合法性
(一)合理使用的标准的认定
《著作权法》第二十四条关于合理使用的规定,采用了半开放式的立法方式,除了明确列明的十二种已被认定为合理使用的情形外,还可以通过法律和行政法规形式进一步增补。根据《保护文学艺术作品伯尔尼公约》第九条二款“Possible exceptions”、《著作权法》第二十四条和《著作权法实施条例》第二十一条的规定,当前学界和司法界的通说认为,合理使用应同时满足如下三个条件,即有限例外情形、不得影响该作品的正常使用、不得不合理地损害著作权人的合法利益,又称“三步检验法”。
司法实践中已有多个案例适用前述三步检验法认定合理使用。丛文辉诉北京搜狗信息服务有限公司著作权侵权纠纷[1]就是一例。该案中,原告系涉案文字作品《可耻的幸灾乐祸》的作者,涉案文字作品字数约为一千字,原载于天涯社区。在天涯社区删除涉案作品五个月后,原告通过被告经营的搜索引擎网站(www.sogou.com)仍能搜索到涉案作品,原告认为被告的行为侵害了其信息网络传播权。被告抗辩称其提供的系网页快照,属于搜索链接行为;同时,原告在起诉前并未向其发送通知要求删除、屏蔽网页快照,其不存在侵权的主观过错,故不应承担侵权责任。
海淀法院一审认为:搜狗公司实施的网页快照提供行为属于系统缓存行为,不符合《信息网络传播权保护条例》第二十一条所规定的临时缓存,故其构成对涉案作品著作权的侵犯。二审法院则认为,如果某一行为虽属于著作权所控制的行为,但其不会对著作权人的利益造成“不合理”的损害,且同时有利于社会公众利益,则该行为符合合理使用行为的“实质条件”。具体到涉案场景,二审法院认为对著作权人造成“不合理”的损害行为是指实质性替代,单从网络用户、搜索引擎服务商、著作权人和社会公众四个角度看,网页快照都不会实质性替代涉案作品,进而也不会影响涉案作品的正常使用,也不会不合理地损害权利人的利益[2]。最终二审法院认定涉案行为属于合理使用,不构成侵权。
无独有偶,上海知识产权法院在其审理的“80后的独立宣言电影海报侵权案[3]”中,提出“转换性使用”这一标准,认定电影海报中使用上海美术电影制片厂享有版权的“黑猫警长”“葫芦娃”形象属于合理使用。
为了满足社会对知识和信息的需求,各国著作权制度均规定了著作权的限制和例外,其中,合理使用制度是著作权限制最重要的一种形式。“合理使用”是指在一定条件下不经著作权人的许可,也不必向其支付报酬而对作品所进行的使用(王迁,2015:315)。如果ChatGPT等生成式人工智能开发者对于作品的大规模使用属于合理使用的情形,则该行为不构成著作权侵权。
如果不同阶段对于作品的使用行为在目标和效果层面一致,可以将其视作一个整体给予统一定性(蒋珂,2015),因此,本文对于ChatGPT的大规模机器学习行为不再根据不同阶段进行细分。
我国《著作权法》未规定判定特定行为是否属于著作权“限制和例外”的一般性原则,而是在第二十四条列举了十三种可以适用合理使用规则的具体情形,目前人工智能的大规模机器学习行为无法被涵盖在内。一方面,ChatGPT等生成式人工智能投资者多为法人组织,不属于“为个人学习、研究或者欣赏”的范畴;另一方面,生成式人工智能的大规模机器学习往往是为了企业后续盈利做铺垫,商业性目的无法满足“学校课堂教学或者科学研究”等要求。在比较法层面,日本(曹源,2018)和欧盟(Official Journal of the European
Union, 2019)在著作权立法中已对合理使用的范围进行了扩大,将人工智能训练中的“文本数据挖掘”增列为一项新的合适使用情形。但人工智能对受著作权法保护的作品的大规模复制能否适用合理使用原则并非一个新颖的话题,美国曾有判例对这一问题进行回应。美国法院通过Perfect 10 v. Amazon案(United States Court of
Appeals & Ninth Circuit, 2007)和Authors Guild v. Google案(U.S. Court of
Appeals for the Second Circuit, 2014)确立了人工智能的大规模复制行为适用合理使用原则的两个基本条件:
一是机器对于作品的复制并不会用于激励他人生产新的作品,
二是机器对于作品的使用不会对与被使用著作权作品的潜在市场和价值产生影响。而ChatGPT等生成式人工智能的出现对以上两个前提均提出了挑战。
一方面,ChatGPT对于作品的大规模复制和学习是为了生成内容,而生成的内容很有可能被用于用户的作品创作;另一方面,更高效、低价的机器生成内容可能会取代一部分作品,从而对著作权相关市场具有潜在性影响。无论大规模机器学习能否适用合理使用规则,生成式人工智能的这一行为都会对合理使用规则带来挑战。
生成式人工智能的大规模机器学习行为不适用合理使用规则的最直接负面影响就是人工智能开发者需要投入大量金钱获取作品授权,否则就有可能需要承担巨额赔偿。训练内容库的规模在很大程度上决定了人工智能的学习能力和使用效果。当前,ChatGPT的训练数据规模已达几十TB,可能有数十万甚至上百万的版权作品被包含在其中。如果使用每一件作品都需要获取许可和支付报酬,无疑会大大增加人工智能开发者的经济负担,甚至引发技术层面的“寒蝉效应”(王文敏,2022)。人工智能技术作为21世纪最重要的尖端技术之一,著作权法层面的严格限制可能会阻碍这一关键技术的进步甚至社会的整体发展。
其次,如果大规模机器学习行为无法被纳入合理使用的情形,出于对高昂费用和潜在法律风险的考量,人工智能开发者可能会选择使用公共领域的作品或者经由协议获得的有限作品来训练算法模型。基于有限规模甚至低质量的文本和数据训练出来的语言模型极有可能会形成“算法偏见”,导致生成式人工智能无法区别甚至生产出危险的言论或建议,回复内容的“毒性”可能大大增加,从长远来看也不利于人工智能技术的进步。
此外,获取著作权授权需要支付的高昂费用将进一步扩大不同规模人工智能研发企业之间的差距,造成不公平的竞争环境甚至行业垄断。实力雄厚的大企业更有可能依托各方面资源获取更多的训练数据,在此基础上优化模型以提供更全面、更优质的服务,吸引更多用户以巩固其市场占有率,并形成良性循环,最终导致“赢者通吃”的行业竞争局面。
然而,大规模机器学习适用合理使用规则会对著作权法律制度本身提出挑战。
一方面,著作权制度的根本价值在于维护个人利益与公共利益之间的平衡,其所有规则的核心宛如一张由私人利益和公共利益错综交织的网络;有学者将二者间的界限比喻为难以捉摸的“形而上学”,且技术变革总是让二者关系处于更不稳定的状态(保罗·戈斯汀,2008:11)。合理使用原则设立的初衷是为了平衡著作权法保护作者和其他著作权人的利益与促进知识、信息广泛传播的双重目的,其最直观的考虑是不允许使用他人作品会阻碍自由表达与思想交流,因此,其最关注的行为是非营利性目的的使用(冯晓青,2009)。例如,我国《著作权法》第二十四条所列举的“为新闻报道”,“为学校课堂教学和科学研究”,“图书馆、档案馆、纪念馆、博物馆、美术馆、文化馆等为陈列或者保存版本的需要”等情形。合理使用原则之设立绝非为保障个人获利,而是意图通过对经济利益等的重新分配,以促进更多人利益的实现。在生成式人工智能的大规模机器学习行为中,实际的版权作品大量使用者是开发人工智能的企业,其对作品的使用最终是为了吸引更多的用户、获取更多的商业利润,就使用性质而言是商业性的而非公共性的。维护大型企业经济利益的实际效果可谓背离了合理使用原则设立的初衷,将大规模机器学习行为纳入合理使用范畴会使著作权法在某种程度上偏离了平衡公私利益的轨道。
另一方面,知识产权法的一个重要作用是促进知识创新,但ChatGPT本身无法创造新的知识,而是基于既有的人类知识储备进行“知识重组”,其生成内容的新颖性、权威性等值得进一步考量。ChatGPT能够通过非复制粘贴方式对所学习的人类知识进行表达,也“鼓励”了一些投机取巧的行为,如果此种基于“机器喂料”生成的、不具有新颖性内容被广泛使用,从长远来看不利于人类创造力的提升。合理使用制度的初衷也是为解决后续作者为创作新作品如何利用先前作品的问题。如果大规模机器学习的最终结果并非是为了生成具有新颖性的内容和促进人类知识创新,将这一行为纳入合理使用范畴也背离了知识产权保护的目的。
(二)不正当竞争标准的认定
ChatGPT类产品行为是否适用爬虫协议哪?答案是否定的。无论是基于搜索引擎和ChatGPT类产品完全不同的定位,还是基于国内的司法实践,皆是如此。
首先,二者的定位完全不同,这决定了ChatGPT类产品无法适用主要体现搜索引擎行业商业道德的爬虫协议。搜索引擎提供的是信息定位服务,抓取内容的目的是为了更准确地定位信息位置,方便用户从海量内容中迅速定位信息并提供访问路径,客观上会为被抓取网站导流,增加被抓取网站的访问量,最终实现利益共赢,这一点决定了被抓取网站通常不会反对搜索引擎抓取内容;ChatGPT类产品抓取内容的目的是为大模型提供训练和学习素材,改善其服务质量,这不但不会给被抓取网站带来任何益处,反而会替代被抓取网站,损害被抓取网站的利益。换言之,在ChatGPT类产品的商业场景中,其和被抓取网站属于竞争关系而非利益共赢。这也是目前ChatGPT类产品在行业内招致众多反对声音的症结所在。
其次,国内司法实践对于非搜索引擎产品是否适用爬虫协议整体上持否定态度。今日头条诉微博不正当竞争案[8]就是一例。该案中,头条认为微博出于恶意限制竞争的不正当目的,将头条的爬虫机器人“ToutiaoSpider”放入微博的robots.txt文件,阻止其抓取网站内容,且仅针对头条爬虫机器人进行上述限制,构成不正当竞争,要求微博赔偿其经济损失1亿元及制止侵权的合理支出50万元。北京市高级人民法院在该案的二审判决书中指出,《互联网搜索引擎服务自律公约》仅可作为搜索引擎服务行业的商业道德,而不能成为互联网行业通行的商业道德,微博限制头条爬虫机器人的场景并不属于搜索引擎范畴,因此不能使用前述自律公约进行商业道德的分析和判断。在此基础上,北京高院进一步分析到,在不损害消费者利益、不损害公共利益、不损害竞争秩序的情况下,应当允许网站经营者通过robots协议对其他网络机器人的抓取进行限制,这是网站经营者经营自主权的一种体现。
就爬虫行为的正当性,与国内司法机关的观点不同,美国法院近几年的司法判例则持认同观点,其中尤以HiQ Labs Inc v. LinkedIn Corporation案为代表。
该案中,原告HiQ是一家为雇主提供雇员评估服务的数据分析公司,它使用自动化机器人,从被告拥有超过5亿用户的职业社交网站LinkedIn上抓取用户公开的个人资料,包括姓名,职务,工作经历和技能等,并将基于这些数据的分析结果出售给客户。LinkedIn向HiQ发送终止函,要求后者停止抓取行为,并称其将主动采取措施阻止HiQ的访问。HiQ收到终止函后,主动向加利福尼亚州地方法院提起诉讼,并在预先禁令中请求法院认定其行为不违反《计算机欺诈和滥用法案》(“Computer Fraud and Abuse Act”,缩写为“CFAA”)的规定,勒令LinkedIn不得采取措施阻止或者妨碍其访问、复制和使用LinkedIn上的公开信息。该预先禁令获得了地区法院支持。LinkedIn随后提起上诉,但美国第九巡回上诉法院维持了一审禁令裁定。LinkedIn进一步上诉至联邦最高法院,最高法院裁决将案件发回第九巡回上诉法院重审。而第九巡回上诉法院再度作出裁决,重申HiQ的行为并未违反CFAA,维持对LinkedIn的禁令。
尽管该案中双方的争议焦点是CFAA的适用范围不是不正当竞争,但是CFAA确实是近年来美国针对爬虫行为正当性诉讼中常援引的法律依据之一。鉴于上述因素,ChatGPT类产品行为在美国的判例可能对国内同类案例参考性不强。
鉴于ChatGPT类产品行为暂无法归类于《反不正当竞争法》第二章“不正当竞争行为”所规定的各种具体的不正当竞争行为中,需要援引“总则”第二条通用条款进行调整。根据最高人民法院在海带配额案[9]中明确的标准,适用通用条款评价涉案行为需要同时满足如下条件:
(1)法律对该种竞争行为未作出特别规定;
(2)其他经营者的合法权益确因该竞争行为而受到了实际损害;
(3)该种竞争行为确违反诚实信用原则和公认的商业道德而具有不正当性或者说可责性。
根据上述标准,笔者认为ChatGPT类产品行为对被被抓取平台构成不正当竞争,分析如下:
首先,被抓取平台对于该等网络公开内容享有反法保护的合法权益。无论被抓取内容是构成作品还是数据,被抓取平台都为作品创作和数据积累投入了大量的人力和物力,且该等内容具有很高的经济价值。比如文首所提及的各种新闻媒体,其运营平台上所刊载的新闻报道,或者由其雇员创作完成,或者支付了版权费用/资源从其他组织或者媒体采购/置换而来,而这都需要相关运营主体投入大量的人力和物力才能实现。根据劳动价值理论,被抓取平台对该等内容享有法律保护的财产性权益。同时,该等内容也是相关媒体在竞争中争取有利竞争态势的核心资源。正是基于上述原因,被抓取平台对该等内容享有合法知识产权或者反不正当竞争法所保护的权益。司法机关在此前的类似案件也进行了确认。
例如在微博诉脉脉案[10]中,二审法院认为,“本案中,被上诉人微梦公司经营的新浪微博兼具社交媒体网络平台和向第三方应用提供接口开放平台的身份,通过其公司多年的经营活动积累了数以亿计的微博用户,这些用户根据自身需要及新浪微博提供的设置条件,公开、向特定人公开或不公开自己的基本信息、职业、教育、喜好等特色信息。经过用户同意收集并进行商业利用的用户信息不仅是被上诉人微梦公司作为社交媒体平台开展经营活动的基础,也是其向不同第三方应用提供平台资源的重要商业资源。新浪微博将用户信息作为其研发产品、提升企业竞争力的基础和核心,实施开放平台战略向第三方应用有条件地提供用户信息,目的是保护用户信息的同时维护新浪微博自身的核心竞争优势。第三方应用未经新浪微博用户及新浪微博的同意,不得使用新浪微博的用户信息”。
其次,从行为结果看,ChatGPT类产品行为一方面提高了自身的竞争优势,另一方面还对被抓取平台构成了替代,用户通过ChatGPT的输出内容以获得问题的明确回复后,无需再进一步访问被抓取平台,这必然分流被抓取平台的用户,减少其交易机会。
最后,ChatGPT类产品行为有违诚实信用原则或商业道德。ChatGPT类产品行为不适用于爬虫协议,侵害了其他经营者的合法权益,并对其他经营者造成损害性后果,如果不对该行为予以抑制,将会使得市场经营者通过劳动积累的、具有较高经济价值的核心竞争资源被他人随意攫取,“不劳而获”盛行,最终导致没有经营者愿意投入人力和物力进行内容的创作、收集和整理,而这无论是对行业秩序还是对于消费者利益都是有害的,有违诚实信用原则。正如法院在大众点评诉百度地图案[11]中所论述的那样,“百度公司并未对于大众点评网中的点评信息作出贡献,却在百度地图和百度知道中大量使用了这些点评信息,其行为具有明显的“搭便车”、“不劳而获”的特点。基于上述因素考虑,一审法院认为,百度公司大量、全文使用涉案点评信息的行为违反了公认的商业道德和诚实信用原则,具有不正当性”。
- 4 -
ChatGPT生成内容是否具备可版权性
(一)客观主义视角下ChatGPT生成内容可版权性的表象成立
《中华人民共和国著作权法》 (以下简称《著作权法》)第三条规定,作品“是指文学、艺术和科学领域内具有独创性并能以一定形式表现的智力成果”。判断ChatGPT生成内容能否构成作品无法绕开对“独创性”标准的解读。“独创性”标准作为一种通行的做法,各国尚未有立法层面的定义或明确解释,司法实践也莫衷一是。作为大陆法系的代表,法国的传统观点认为“独创性”是作者个性的反映,源自作者在创作过程中有创造性的选择,在具有里程碑性质的Pachot案中,法官将“独创性”定义为“智力投入”,但如果这种投入是自动或者强制逻辑性的,则不会受到保护。英国法院在多个案件中对独创性标准进行了解释,最终确立了两个基本原则:一是该作品并非对他人作品的抄袭,二是该作品必须投入了“个人的技巧、劳动或判断”(姜颖,2004)。美国1909年著作权法提出了对作品独创性的要求,其司法实践在早期采用与英国传统标准相似的“额头出汗”原则,但在Feist案后要求“独创性”包含“独立创作”和“少量的创造性”两方面内涵(李伟文,2000)。由此可见,关于“独创性”的理解和讨论主要围绕“独立创作”和“创造性”两个概念的含义展开。
有学者认为,“独立创作”被纳入“独创性”的内涵范围,是由版权法的历史背景、解决版权制度操作性难题的需要以及司法实践的偶然因素等多方面因素共同作用的结果;“独立创作”描述了作品与创作者之间的关系,而非作品在本质上区别于其他事物的属性,“创造性”才是版权法基于一定的价值目标、对作品法定属性和要求所作出的规定(乔丽春,2011)。“独立创作”涉及作品著作权归属,判断创作物是否能够构成“作品”应首先坚持一种客观主义的判断标准,即判断创作物在表达形式上能否满足著作权法要求的足够的“创造性”。在客观主义的独创性标准下,无需考虑ChatGPT生成内容的创作者和创作过程,只需要考虑其生成内容是否达到了最低限度的创造性及其是否能以一定形式表现。就第一个问题而言,如今,ChatGPT可以撰写诗歌、在一定的用户提示下完成短篇小说,且已有多篇学术论文将ChatGPT列为合作者;由此可见,ChatGPT生成内容在形式上与人类作品具有接近性,在没有明确标明内容来源的情况下,其生成内容与人类作品在表象层面已经较难区分出来。
因此,ChatGPT生成内容可以被认定为能够满足最低限度的创造性。而就“能否以一定形式表现”这一问题来看,ChatGPT生成的文本内容无疑可以通过一定形式被固定下来。由此可见,在客观主义标准下,ChatGPT生成内容具备表象层面的可版权性。
(二)民法权利主体——人视角下ChatGPT内容可版权性的实质不成立
“民法对事实行为的概括往往以行为所造成的客观后果作为最终构成要件”(董安生,1997:113),创作行为作为一种事实行为,创作内容是这一行为的结果,以创作内容本身去判断生成内容是否具有独创性在某种程度上具备合理性(杨述兴,2007)。但理论和方法的有效性应建立在适用条件和具体语境的基础之上。客观主义判断标准适用的前提是生成内容源自于人,只有对于自然人的创作成果而言,依据创作结果讨论独创性才是可行的。著作权法保护思想之表达,但“表达”并非只是作为“符号之组合”存在,其本身即蕴含了人的主体意味。以往新技术对著作权法的影响主要体现在作品的复制和传播方面,在此背景下,客观主义标准在法律适用层面的明显优势是有望通过一种简单的方法判断某一成果是否具有独创性。如今,ChatGPT等生成式人工智能直接介入了内容的创造性生产过程——直观看来,人们不再是利用计算机以新的方式生产作品,而是让计算机用新的方式生产作品。
因此,在忽略“作品是人的表达”这一前提的情况下,直接运用客观主义标准去评判非自然人生成内容能否构成作品是不妥当的。在仅考虑作品本身的可区别性、不考虑创作主体和过程的情况下,不仅机器生成的内容具有可版权性,动物乃至自然界中产生的“符号组合”都可能构成作品,这将造成著作权客体范围无端扩张,动摇私人利益与公共利益的平衡甚至著作权法律制度的稳定。
循着著作权产生、发展的历史可见,无论是作为自然权利还是功利主义视角下的经济激励,人类的创造始终是著作权的重心(Gervais D J, 2020)。既有的司法判例也将著作权之船锚定在人类创造力的水域。早在一个多世纪前的“Sarony诉Burrow-Giles平版印刷公司”案中,美国最高法院判决意见书中就将“作者”界定为“拥有原创性事物之人”(U.S. Supreme Court, 1884),表明“作者”必须是“自然人”。在此后的Mazer v. Stein案(U.S. Supreme Court, 1954)、Goldstein v. California案(U.S. Supreme Court, 1973)等判例中,法院也多次援引“Sarony诉Burrow-Giles平版印刷公司”案中的观点,这表明人类作者身份是作品受到版权法保护的先决条件。
2018年,美国版权局拒绝了人工智能自动生成视觉内容《通往天堂的近路》(A Recent
Road to Paradise)的版权申请,并强调著作权法保护的是“独创性作品的作者”(original
work of authorship)将其创作物固定在有形载体的表达;国会在立法时对于“独创性作品的作者”这一身份的定义进行了刻意留白,是在为了“不改变法院依著作权法所建构的独创性标准”这一前提下,避免出现著作权法的法定保护范围与宪法授权国会保护的材料范围不一致的情况;“独创性作品的作者”这一概念指涉范围相当广泛,但法律并非对其毫无限制(U.S. Copyright Review Board, 2022)。因此,在现行版权法中,“人”是权利的主体,只有人类的智力成果才可能具有可版权性。
基于上述讨论,判断ChatGPT生成内容能否构成作品的关键,在于厘清其生成内容与人的关系,即人在ChatGPT内容生产过程中是否发挥关键作用。2023年3月16日,美国版权局在联邦公告上发布了一则声明,对使用人工智能技术产生的作品之著作权审查和登记进行了说明。根据声明,讨论一份创作物是否具有可版权性的基础是“作者是否为人类”,即作品中文学性、艺术性、音乐性要素的表达、选择或安排是否是由自然人构思和执行的;对于包含部分人工智能生成内容的创作物,其可版权性的判定要看人类在多大程度上创造性地控制了作品的表达以及是否“实际创作”了作品中的创造性元素(traditional elements of authorship in the work)。
在就含人工智能生成内容的创作物进行作品申请时,作者有义务对人工智能生成内容进行标注,并对人类作者对作品的贡献进行简要说明;如果机器完成部分超出最大限制,则该创作物不能被认定为作品(U.S. Copyright Office & Library of Congress, 2023)。美国版权局在拒绝《通往天堂的近路》的版权申请时,理由就是“没有证据表明人类作者在该图像中进行了充分的创造性投入或干预”(U.S. Copyright Review Board, 2022)。
有观点将人工智能视为人类进行创作的工具,并在此基础上主张人工智能生成内容的可版权性。然而,ChatGPT在内容生成过程中是否只是人类进行创作的工具呢?工具是“人在生产过程中用来加工制造产品的器具”或“用以达到目的的事物”(中国社会科学院语言研究所词典编辑室,2020:448)。从定义来看,就智力产品而言,“人”是在生产过程中发挥主观能动性的一方,工具只具有辅助作用。ChatGPT的本质是人工智能内容生成技术的具体应用,通俗来讲,人们运用现有的人类作品对人工智能技术进行大规模训练,并使用训练获得的规律生成内容。具体而言,训练过程是在给定一段文本序列的基础上,模型将前文的单词序列作为输入,逐个预测下一个单词的分布概率,由此学习单词之间的关系、上下文语义和语法规则等,最终训练出对人类语言的理解能力。ChatGPT的预训练数据主要来源于维基百科、书籍、期刊、Reddit链接、Common Crawl系列语料库和其他数据集等,学习内容均是人类的智力成果。在系统运行过程中,用户给出文本指令(prompt),然后ChatGPT根据指令生成一定的文本结果(answer)。即使ChatGPT在生成文本内容前接受了人类(用户)的提示,用户也无法对ChatGPT如何理解人类提示和实际生成文本材料进行足够的创造性控制;换言之,是机器而非用户对所输出文字进行实际的选择和组织。用户的指令只是明确了人类希望机器输出内容的主题,但机器实际决定了这些指令是如何在其输出文本中实现的。
例如,如果用户指示ChatGPT以思乡为主题写一首李白风格的七言律诗,他期望系统生成体裁为一首七言律诗、涉及思想和类似李白风格的诗作,但ChatGPT决定了生成内容的押韵模式、每句中的语词和结构顺序。著作权法对作品的保护在任何情况下都不延及思想,用户关于“李白风格的思乡诗”的构想更接近于“思想”的范畴,而关于思想的表达实际上是由机器生成的。
早在1997年的Urantia Foundation v. Maaherra案中(United States Court of Appeals, Ninth Circuit, 1997),法院就对一件作品中所包含的“人类智力因素”进行了说明。在该案中,原告声称在神的授意下撰写了一本名为《神之启示》的书,被告Maaherra将这本书通过电脑光盘进行了复制和传播。原告认为这本书应该作为神创作的作品受到著作权法保护,而被告之行为构成著作权侵权;被告抗辩称本书作为“神的作品”不包含人类创作成分,因此无法受到著作权法保护,自己的行为也不构成侵权。美国第九巡回法院在判决意见书中表明,“作者”是首个对文字做出汇编、选择、协调和安排的人,在《神之启示》一书中,人类的智力性劳动体现为对内容的选择和编排,因此本书能够作为人的创造性成果受到著作权法保护。
而在ChatGPT内容生成的过程中,对文字进行选择、编排和表达的是机器。ChatGPT生成内容应属于“人工智能自动生成的”,而非“人工智能辅助完成的”。根据世界知识产权组织发布的《经修订的关于知识产权政策和人工智能问题的议题文件》,“人工智能生成的”与“人工智能自主创造的”是可以互替使用的术语,指在没有人类干预的情况下由人工智能生成产出;“人工智能生成的”应该与“人工智能辅助完成的”产出加以区分,后者需要大量人类干预或引导。将人工智能看作是人之创作工具的观点混淆了以上两个概念:ChatGPT生成内容属于“人工智能生成的”产出,不是“人工智能辅助完成的”的产出,因此不具有可版权性。
- 5 -
结语
法律仅是社会问题的一种解法。就ChatGPT类产品行为所引发的社会问题,行业也已开始寻找法律之外的商业解决路径。法律制度具有滞后性,但对于法律问题的思考应具有前瞻性(吴汉东,2017)。近年来,大数据与人工智能技术的迅速发展引发了人工智能能否作为适格著作权主体等相关讨论。当前,ChatGPT等生成式人工智能对人类行为的模拟仅限于内容创作,与强人工智能还有很大差距。若未来人工智能技术发展到了具有自主意识的阶段,也需要民法在主体制度中对人工智能之法律地位做出回应,而不是在著作权法领域率先进行突破性变革。
此外,权利的实现与义务的履行往往相伴而生,不能因人工智能生成内容与人类作品具有表象性相似便急于对其提供保护,也应考虑侵权责任的承担。如果著作权法为人工智能生成内容提供了保护,当生成内容侵犯他人权益时,权利所有人也应为其“创作”承担侵权责任。若生成式人工智能的所有者、研发者或使用者享有机器生成物的权益,那么当这些内容侵犯他人复制权、改编权或构成诽谤侵犯他人人格权益时,他们就需要为此担责。考虑到ChatGPT等生成内容的实际过程,由并未直接参与创作的自然人或法人来承担机器创作物的侵权责任不具有足够的合理性。自1709年《安娜法》颁布以来,技术变革总是为著作权法律制度带来新的紧张。著作权法在未来对人工智能生成技术带来的新问题进行回应时,不仅要考虑技术自身的变革程度,也要考虑其对公共利益与私人利益之平衡的影响程度,对既有法律规则变革与否,需要在著作权法基本原理的基础上探寻其在新技术背景下的适用条件。
[1]参见北京知识产权法院(2015)京知民终字第559号判决书。[2]参见北京知识产权法院(2016)京73民终143号判决书。[3]参见广东省深圳市南山区人民法院(2019)粤0305民初14010号民事判决书。[4]参见北京知识产权法院(2019)京73民终2030号判决书。[5]参见https://openai.com/terms/。[6]丛文辉诉北京搜狗信息服务有限公司著作权侵权纠纷,一审北京市海淀区人民法院,案号:(2013)海民初字第11368号;二审北京市第一中级人民法院,案号:(2013)一中民终字第12533号;[7]《网页快照服务提供行为的侵权认定》,芮松艳著,http://www.chinaipmagazine.com/zl/Column
View.asp?fId =59&id=109;[8]上海美术电影制片厂(“上美厂”)诉浙江新影年代文化传播有限公司(“新影年代公司”)、华谊兄弟上海影院管理有限公司(“华谊公司”)著作权纠纷,该案中,新影年代公司投资制作的电影《80后的独立宣言》正式上映,宣传海报中使用了上美厂享有合法权益的“葫芦娃”和“黑猫警长”卡通形象,上美厂认为新影年代公司未经许可,使用上述两个角色形象的美术作品,构成对其修改权、复制权、发行权、信息网络传播权的侵犯;华谊公司在其官方微博上发布了该电影的涉案海报,构成对其信息网络传播权的侵犯,并与新影年代公司构成共同侵权。故诉至法院,请求判令新影年代公司和华谊公司连带赔偿上美厂经济损失及维权费用合计人民币53万余元。新影年代公司提出抗辩,认为涉案电影讲述的是“80后”青年创业故事,其对涉案作品的使用是为了说明电影主角的年龄特征,构成著作权法上的“合理使用”,不构成侵权;
[9]王莘诉谷歌公司、北京谷翔信息技术有限公司侵害著作权纠纷,一审北京市第一中级人民法院,案号:(2011)一中民初字第1321号;二审北京市高级人民法院,案号(2013)高民终字第1221号。在该案中,一审法院认为谷歌公司将涉案作品进行电子化扫描的复制行为不属于合理使用,构成侵权;同时,谷翔公司实施的涉案信息网络传播行为构成合理使用,谷翔公司和谷歌公司并不应对此行为承担侵权责任。谷歌公司不服一审判决提起上诉。北京市高级人民法院二审认为谷歌公司虽然主张其复制行为构成合理使用,但并未就此进行充分举证,最终认定复制行为构成侵权。二审法院在判决中同时指出,“专门为了合理使用行为而进行的复制,应当与后续使用行为结合起来作为一个整体看待,不应当与后续的合理使用行为割裂开来看。换言之,如果是专门为了后续的合理使用行为而未经许可复制他人作品,应当认定为合理使用行为的一个部分,同样构成合理使用”,但因为一审原告未提起上诉,二审法院并未就一审法院认定谷翔公司的信息网络传播行为构成合理使用专门展开论述。但是根据二审法院的逻辑,可以清楚的推论出二审法院认为涉案信息网络传播行为也是构成侵权的;[10]谷歌数字图书馆项目,是谷歌与部分图书馆合作,由图书馆从他们的藏书中选择书籍交给谷歌,谷歌通过扫描形式制作图书电子版,并收录到谷歌数字图书馆中。谷歌在此基础上推出了“谷歌图书”产品,该产品可以根据输入的检索关键词,向用户提供包含关键词的图书以及关键词在图书中出现的次数,以及几个世纪以来该关键词使用频率的统计数据;同时搜索结果还会显示含有这些关键词的文字片断,通常不会超过八分之一页;[12]The AUTHORS GUILD, INC., Betty Miles, Joseph
Goulden, and Jim Bouton v. GOOGLE INC.;[13]北京字节跳动科技有限公司诉北京微梦创科网络技术有限公司不正当竞争纠纷,一审法院为北京知识产权法院,案号:(2017)京73民初2020号;二审法院为北京高级人民法院,案号:(2021)京民终281号;[14]山东省食品进出口公司、山东山孚集团有限公司、山东山孚日水有限公司与马达庆、青岛圣克达诚贸易有限公司不正当竞争纠纷,最高人民法院再审案件,案号:(2009)民申字第1065号;[15]北京微梦创科网络技术有限公司诉北京淘友天下技术有限公司、北京淘友天下科技发展有限公司不正当竞争纠纷,一审法院为北京市海淀区人民法院,案号:2015年海民(知)初字第12602号;二审法院为北京知识产权法院,案号:(2016)京73民终588号;[16]上海汉涛信息咨询有限公司诉北京百度网讯科技有限公司、上海杰图软件技术有限公司不正当竞争纠纷,一审法院为上海市杨浦区人民法院,案号:(2015)浦民三(知)初字第528号;二审法院为上海知识产权法院,案号:(2016)沪73民终242号。[17]朱鸿军 李辛扬:《ChatGPT生成内容的非版权性及著作权侵权风险》,2023年第6期[18]Dash B.&Sharma P., Are ChatGPT and Deepfake
AlgorithmsEndangering the Cybersecurity Industry? A
Review[J],International Journal ofEngineering and Applied Sciences.2023,10(1):4-5.[19] 陈永伟 . 超越Chat GPT: 生成式 AI 的机遇、风险与挑战 [J].山东大学学报 ( 哲学社会科学版 ).2023(3).[20]John V. Pavlik.Collaborating With ChatGPT:
Considering theImplications of Generative Artificial Intelligence for
Journalism and MediaEducation[J].Journalism & Mass Communication
Educator. 2023, 78(1):[21][10][15]Hacker P, Engel A, Mauer M. Regulating
ChatGPT and otherLarge Generative AI Models[EB/OL].(2023-2-10). https://arxiv.org/[22]Agomuoh F. The 6 Biggest Problems with ChatGPT
Right Now[EB/OL].(2023-01-27).https://www.digitaltrends.com/computing/the-6-biggest-problems-with-chatgpt-right-now/.[23]McGee R W. Is Chat GPT Biased against
Conservatives? AnEmpirical Study[EB/OL].(2023-2-15).https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4359405.[24]Hartmann J, Schwenzow J, Witte M. The political
ideology ofconversational AI: Converging evidence on ChatGPT's
pro-environmental,left-libertarian orientation[EB/OL].(2023-1-1).https://ssrn.com/[25][12]Rozado, David. The Political Biases of
ChatGPT[J]. Social[26] Chris Stokel-Walker ,Richard Van Noorden.The
Promise and Perilof Generative AI[J].Nature.2023,614(7947):216.[27] Van Dis E A M, Bollen J, Zuidema W, et al.
ChatGPT: fivepriorities for research[J]. Nature. 2023, 614(7947):
224-226.[28]Natali Helberger,Nicholas Diakopoulos.ChatGPT and
the AI Act[J].Internet Policy Review.2023,12(1):1-6.[29]Gina M. Raimondo,Laurie E. Locascio.Artificial
Intelligence RiskManagement Framework[EB/OL].(2023-1-26).https://nvlpubs.nist.gov/
nistpubs/ai/NIST.AI.100-1.pdf.[30]Sourabh Gupta.Best Practices for Reducing Bias in
AI[EB/OL].(2023-2-28).https://techbeacon.com/app-dev-testing/best-practices-[31]Dipankar Dasgupta,Kishor Datta
Gupta.Dual-filtering (DF) schemesfor learning systems to prevent adversarial attacks,” Complex & IntelligentSystems[EB/OL].(2022-1-21).https://doi.org/10.1007/s40747-022-[32]Bibhu Dash,Pawankumar Sharma. Are ChatGPT and
DeepfakeAlgorithms Endangering the Cybersecurity Industry?
[J].A Review,InternationalJournal of Engineering and Applied
Sciences.2023,10(1):4-5.田力玮律师,本科毕业于安徽师范大学,硕士毕业于安徽财经大学,无诉平台认证作者。曾实习于蚌埠市中级人民法院审判监督庭,担任法官助理,论文《国际公共卫生事件认定影响与对策》获评第三十二届全国副省级城市二等奖;论文《无人驾驶环境下我国机动车交强险的不足与改进》获评华东政法大学第三届法治战略论,坛二等奖;论文《挪用资金罪量刑标准存在的问题与解决》获评西北政法大学第三届刑事辩护高峰论,坛一等奖;论文《智慧司法:法律智能机器人对于未来的“问”与“答”》发表于东方法学公众号并收录于《上海法学研究》;论文《施工单位破产程序中实际施工人相关债权处理》获评成都理工大学第四届破产法治天府论,坛优,秀奖。咨询电话:18855265720。
- End -

新则入驻小红书,与更多年轻法律人一起,分享法律知识和实务内容,欢迎关注。扫描海报二维码或点击下方图片,关注新则小红书
9月20日(周三)晚上7点,恒都律师事务所婚姻与家庭专业部门召集人罗艳杰将在直播间分享「婚家案件的思维破局」。
欢迎扫码预约









