大家好,本篇和大家介绍pandas中的多级索引操作。
我们知道dataframe是一个二维的数据表结构,通常情况下行和列索引都只有一个。但当需要多维度分析时,我们就需要添加多层级索引了。在关系型数据库中也被叫做复合主键。
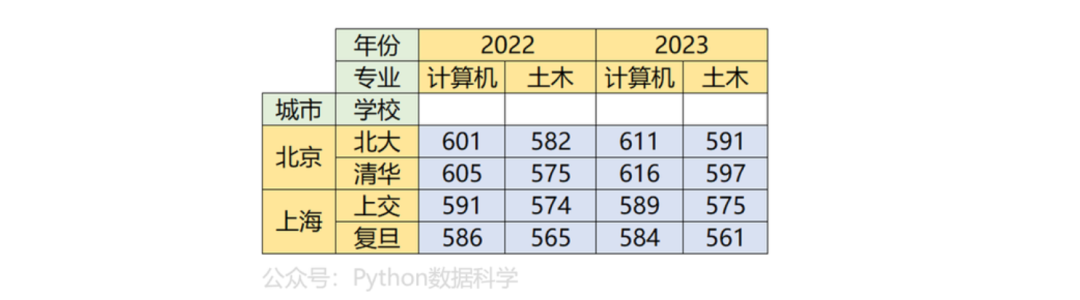
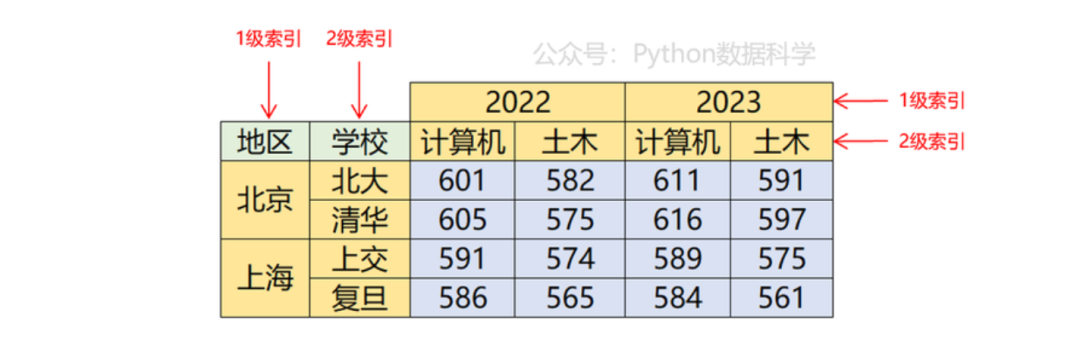
比如,下面这个数据是高考录取分数线,行索引是地区、学校,列索引是年份、专业,分别对应1级和2级索引,因此共有四个维度。
1、多层级索引创建
多级索引的创建分两种情况。一种是只有纯数据,索引需要新建立;另一种是索引可从数据中获取。
因为两种情况建立多级索引的方法不同,下面分情况来介绍。
当只有数据没有索引时,我们需要指定索引值,比如下图。
df = pd.DataFrame(
[[601,582,611,591],
[605,575,616,597],
[591,574,589,575],
[586,565,584,561]])
print(df)
有四种创建多级层级的方法:MultiIndex.from_arrays,MultiIndex.from_product,MultiIndex.from_tuples,MultiIndex.from_frame。
# 数组
# 每个数组对应着一个层级的索引值
arrays = [['北京','北京','上海','上海'],['北大','清华','上交','复旦']]
mindex = pd.MultiIndex.from_arrays(arrays, names=['城市','大学'])
# 元组
# 每个元组是对应着一对多级索引
tuples = [('北京','北大'),('北京','清华'),('上海','上交'),('上海','复旦')]
mindex = pd.MultiIndex.from_tuples(tuples, names=['城市','大学'])
# dataframe
# 创建一个dataframe,方式与元组类似,每个元组对应一对多级索引值
frame = pd.DataFrame([('北京','北大'),(
'北京','清华'),('上海','上交'),('上海','复旦')])
mindex = pd.MultiIndex.from_frame(frame, names=['城市','大学'])
# 给df行索引赋值
df.index = mindex
通过以上三种方式均可为数据添加行索引值,索引值结果一样,如下图。

# product笛卡尔积
city = ['北京', '上海']
college = ['北大','清华','上交','复旦']
mindex1 = pd.MultiIndex.from_product([city,college], names=['城市','大学'])
mindex1

第四种方法是对两个序列生成笛卡尔积,即两两组合,结果如上。这种方式生成的索引和我们上面想要的形式不同,因此对行索引不适用,但是我们发现列索引column目前还没指定,此时是默认的1,2,3,4,进一步发现这里的列索引是符合笛卡尔积形式的,因此我们用from_product来生成column列索引。
# product生成column列索引
year = ['2022','2023']
pro = ['计算机','土木']
mcol = pd.MultiIndex.from_product([year,pro], names=['年份','专业'])
# 对df的行索引、列索引赋值
df.index = mindex
df.columns = mcol
display(df)

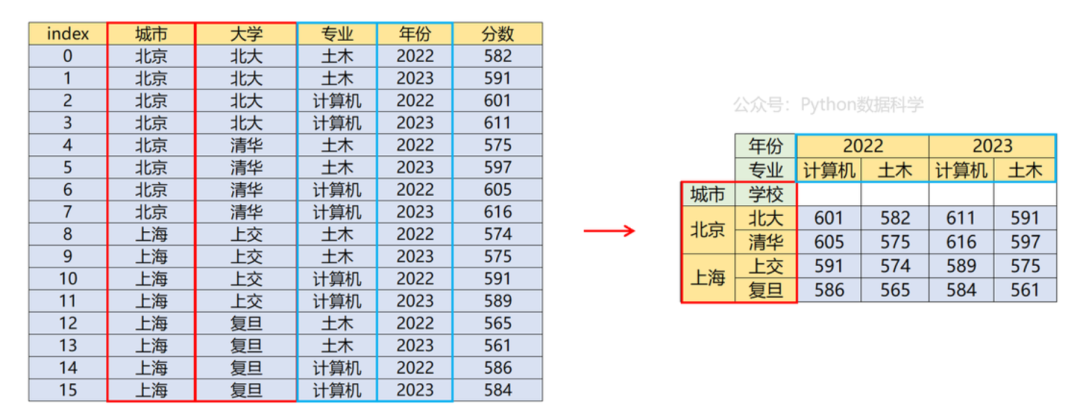
02 从数据中获取多级索引
第二种情况是我们既有数值数据又有维度数据,此时可以使用透视的方法比如pivot_table,stack,unstack来设置多层级索引。
# pivot_table
pd.pivot_table(df1, index=['城市','大学'],columns=['年份','专业'])
# unstack将行索引最内层连续翻转两次
df1.set_index(['城市','大学','专业','年份']).unstack().unstack()
以上两种方式结果相同,均可从原数据中抽取列维度数据并设置为行列的多级索引。
2、多层级索引筛选
通过MultiIndex访问dataFrame的好处是,可以很容易地一次引用所有层次(可能会省略内部层次),语法简单方便。
这里通过
.loc查询方法进行举例。
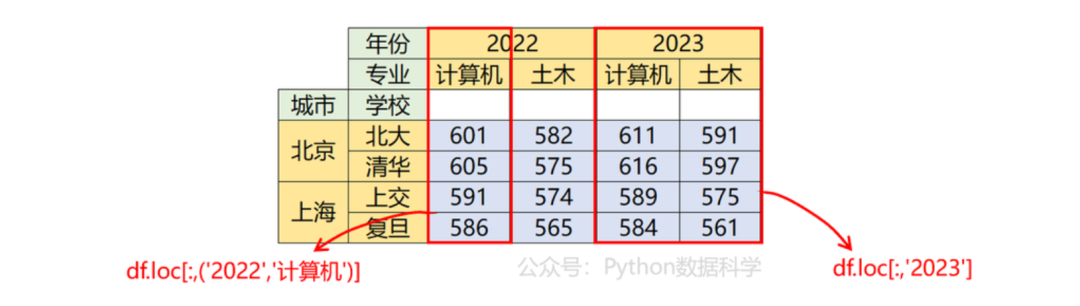
01列索引筛选
# 筛选列一级索引
df.loc[:,'2023']
df['2023']
# 同时筛选列一二级索引
df.loc[:,('2022','计算机')]
df['2022','计算机']
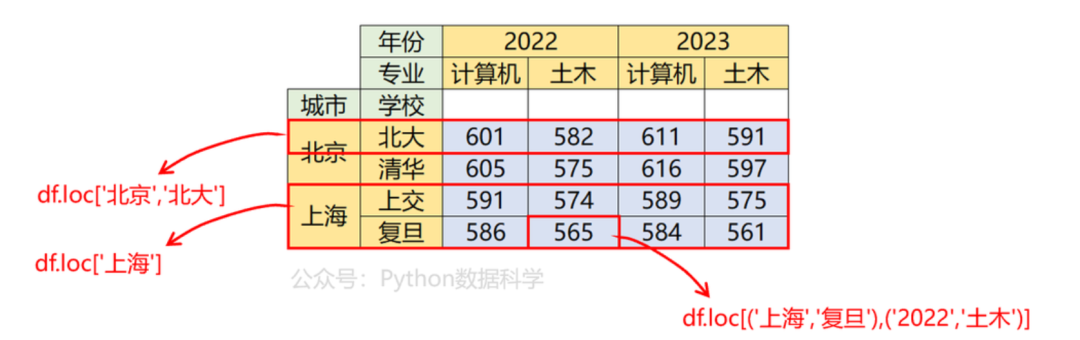
02 行索引筛选
通过.loc可对行、列或单元格进行筛选。
# 同时筛选行一二级索引
df.loc['北京','北大']
# 筛选行一级索引
df.loc['上海']
# 同时筛选行和列一二级索引,得到元素
df.loc[('上海','复旦'),('2022','土木')]
3、多层级索引操作
对于多层级索引来说,可以按照不同的level层级有多种的操作,包括了查询、删除、修改、排序、互换、拼接、拆分等。
这些操作对行(index)、列(columns)索引均适用。
get_level_values可以对指定层级索引查询,level指定层级。
# 按层级获取索引
df.index.get_level_values(level=1) # 查找行的二级索引
df.index.get_level_values(level=0) # 查找行的一级索引
df.columns.get_level_values(level=1) # 查找列的二级索引
df.columns.get_level_values(level=0) # 查找列的一级索引
droplevel可以对指定层级索引删除,level指定层级。
# 按层级删除索引
df.index.droplevel(level=0) # 删除行一级索引
df.index.droplevel(level=1) # 删除行二级索引
df.columns.droplevel(level=0) # 删除行一级索引
df.columns.droplevel(level=1) # 删除行二级索引
set_levels可以对指定层级的索引重新设置覆盖原索引,level指定层级。
df.index.set_levels(['北方','南方'], level=0) # 修改行一级索引
df.index.set_levels(['北交','人大','同济','华东师范'], level=1) # 修改行二级索引
df.columns.set_levels(['2020','2021'], level=0) # 修改列一级索引
df.columns.set_levels(['机械','电子'], level=1) # 修改列二级索引
04 按层级排序索引
sortlevel对索引的不同层级按升降序的方法排序,level指定层级,ascending指定是否升序。
df.index.sortlevel(level=0, ascending=False) # 对行一级索引倒序排序
df.index.sortlevel(level=1, ascending=False) # 对行二级索引倒序排序
df.columns.sortlevel(level=0, ascending=False) # 对列一级索引倒序排序
df.columns.sortlevel(level=1, ascending=False) # 对列二级索引倒序排序
05 索引层级互换
swaplevel对指定的两个索引层级进行互换,比如将2和3互换,1和2互换等等。
df.index.swaplevel(i=0, j=1) # 对行索引层级互换
df.columns.swaplevel(i=0, j=1) # 对行索引层级互换
06 按层级重排索引
reorder_levels函数可以按指定的顺序进行重新排序,order参数可以是整数的level层级或者字符串的索引名,用法如下。
df.index.reorder_levels(order=['大学','城市']) # 指定行索引名称name重排
df.index.reorder_levels(order=[1,0]) # 指定行索引层级level数字重排
df.columns.reorder_levels(order=['专业','年份']) # 指定列索引名称name重排
df.columns.reorder_levels(order=[1,0]) # 指定列索引层级level数字重排
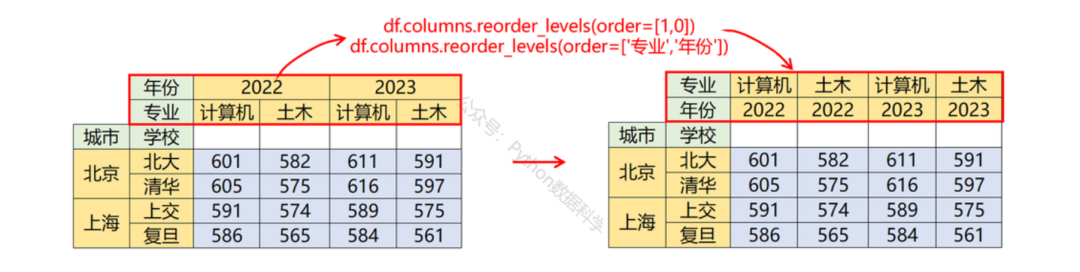
索引有两个层级时,重排效果和互换一样,只有当索引有三个层级时,重排可以发挥出作用。
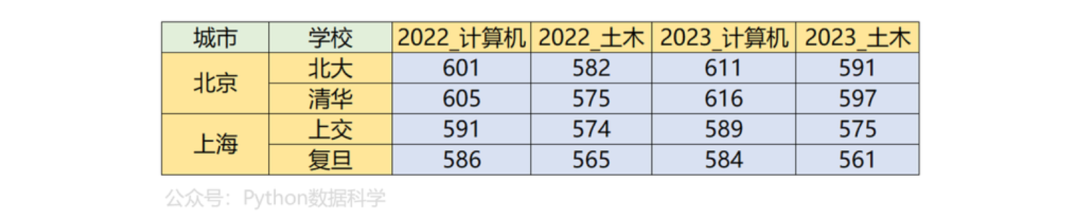
除此外,对于多层级索引而言,我们有时需要将多层级进行拼接,此时我们可以借助to_flat_index函数,它可以将多级索引放在一起(相当于from_tuples的逆操作)。
比如,对列索引进行此操作,得到了元组形式的一二级索引对。
df.columns.to_flat_index()
------
Index([('2022', '计算机'), ('2022', '土木'), ('2023', '计算机'), (
'2023', '土木')], dtype='object')
然后再通过python的join字符串拼接用法就实现了索引拼接。
df.columns = ['_'.join(k) for k in df.columns.to_flat_index()]
display(df)
08 多级索引拆分
通过split函数将上面列索引拆分成元组,然后利用from_tuples方法创建多层级索引。
df.columns = pd.MultiIndex.from_tuples(k.split('_') for k in df.columns)
display(df)
这样就把上面拼接的结果进行了还原。