案例:用搜索宽度N=2的beam-search实现Think-on-Graph推理
在搜索剪枝任务中,大模型从关键词Canberra出发,匹配到知识图谱中最接近(或一致)的实体,分别搜索了5个「关系→实体」对,并为它们打分(得分越高,则代表此新实体加入推理路径中,可正确回答问题的能力越高)。

将分数从高到低排序后,LLM保留了得分最高的2个,形成两条候选推理路径:
接下来,LLM对候选推理路径进行评估,并将结果以Yes/No的形式反馈给算法。
在案例中可见,LLM连续两轮否决了候选路径,直到完成第三轮迭代时,LLM才判断已获取回答问题的充分信息,因此停止算法迭代,向用户输出答案(该答案确为正确答案)。

研究团队表示,Think-on-Graph算法还有效提升了大模型推理的可解释性,并实现知识的可追溯、可纠错与可修正。尤其是借助人工反馈与LLM推理能力,发现并修正知识图谱中的错误信息,弥补LLM训练时间长、知识更新慢的缺点。
为测试此能力,我们设计了一个实验:在前述「段誉与洪七公武功对比」案例的知识图谱中,故意掺入错误信息「大理段氏的最强武功是一阳指,一般武功是六脉神剑」。

可见,尽管Think-on-Graph根据错误知识得出了错误答案,但由于算法内置的「自我反思」能力,当判断答案可信度不足时,会自动回溯在知识图谱上的推理路径,检查路径中的所有三元组。
此时,LLM将利用自有知识,将疑似有误的三元组挑选出来,并向用户反馈分析与纠错建议。

7个新SOTA,深度推理较ChatGPT最多提升214%
研究在四类知识密集型任务(KBQA, Open-Domain QA, Slot Filling, Fact Checking)的共9个数据集上,对Think-on-Graph的表现进行了评估。
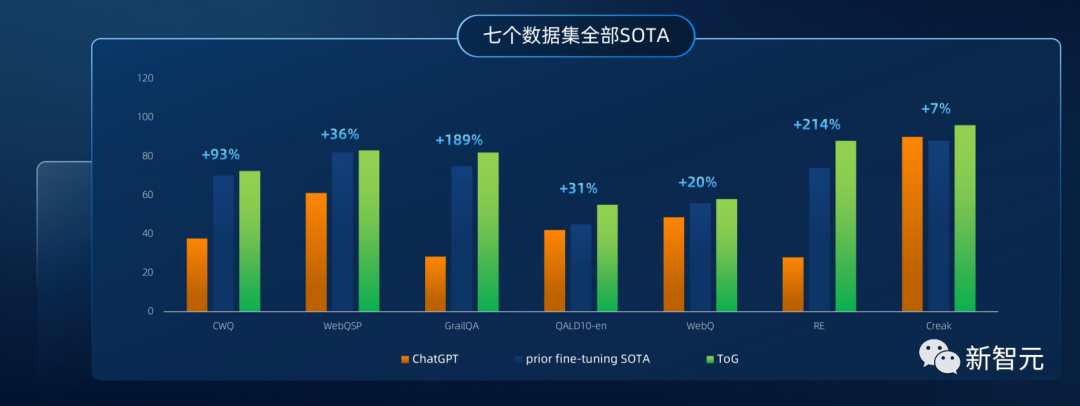
与IO、CoT、CoT-SC等不同prompting策略下的ChatGPT(GPT-3.5)相比,Think-on-Graph在所有数据集上的表现都显著更优。以Zeroshot-RE数据集中的对比为例,基于CoT的ChatGPT精度为28.8%,而同底座的Think-on-Graph精度为88%。
当底座模型升级为GPT-4后,Think-on-Graph的推理精度也明显提升,在7个数据集上取得了SOTA,剩余数据集中的CWQ上也十分接近SOTA。
值得注意的是,Think-on-Graph未在上述任何测试数据集上进行过监督学习性质的增量训练或增量微调,体现出超强的即插即用能力。
此外,研究者还发现,即便替换小规模的底座模型(如LLAMA2-70B),Think-on-Graph依然可在多个数据集上超越ChatGPT,这或可为大模型使用者提供一条低算力需求的技术路线选择。









