【新智元导读】全新代码大模型Magicoder,不到7B参数,就能在代码生成领域与顶级代码模型不相上下。
开源「代码大模型」来了!
UIUC清华团队的研究人员发布了Magicoder,不到7B参数,就能在代码生成领域与顶级代码模型不相上下。
值得一提的是,Magicoder的代码、权重和数据,毫无保留完全开源。
论文地址:https://arxiv.org/abs/2312.02120
Magicoder依靠的OSS-INSTRUCT的方法,是通过对现有顶级代码模型(例如ChatGPT)的提示,加上网络上的种子代码片段,来生成的代码。

这可真是取之于大模型,用之于大模型;就有网友转发说道:通过这些结果,看到了提高用于LLMs的合成数据的潜力也是一个非常有趣的领域。

话不多说,那就让我们来具体了解一下Magicoder的来历吧!
代码生成(Code Generation),也叫程序合成(Program Synthesis),近几十年来,一直都是学术界的一块「硬骨头」,在此领域进行过的许多尝试,例如基于抽象的合成和基于示例的编程,都没有取得很好的效果。
直到最近,使用在代码上训练的大型语言模型取得了显著的突破,被广泛应用于辅助实际软件开发。
最初,诸如GPT-3.5 Turbo和GPT-4之类的闭源模型主导了各种代码生成基准和排行榜。
为了推动开源LLM在代码生成领域的应用,SELF-INSTRUCT方法被开发出来,通过使用强大的LLM生成合成的编码指令,并利用这些指令对较弱的学生模型进行微调,以从强大的教师模型中提取知识。
然而,SELF-INSTRUCT在提高LLM的指令遵循能力时,仍然依赖于狭窄范围的预定义任务或启发式方法。
为了解决这一问题,UIUC和清华的研究人员提出了Magicoder,其中采用的OSS-INSTRUCT方法,旨在减轻LLM固有的偏见,通过直接学习开源代码释放其创造高质量和创意编码指令的潜力。
OSS-INSTRUCT通过从开源中搜集的随机代码片段获得灵感,自动生成新的编码问题。借助于不同的种子代码片段,OSS-INSTRUCT能够直接产生多样、真实和可控的编码指令数据。
如下图所示,在这个例子中,LLM从两个不同函数的不完整代码片段中获取灵感,成功地将它们关联起来,并构建出一个现实的机器学习问题。

由于OSS-INSTRUCT与现有的数据生成方法是正交的,OSS-INSTRUCT可以被同时结合使用,进一步推动模型在编码任务中的能力。
OSS-INSTRUCT的工作方式是通过对LLM(例如ChatGPT)进行提示,然后根据从互联网搜集的一些种子代码片段(例如来自GitHub)生成编程问题及其解决方案。
一方面,种子片段提供了生成的可控性;
另一方面,OSS-INSTRUCT加强了LLM创建编程问题的多样化,更符合真实的编程场景。
我们可以从以下几个指标中一探究竟:
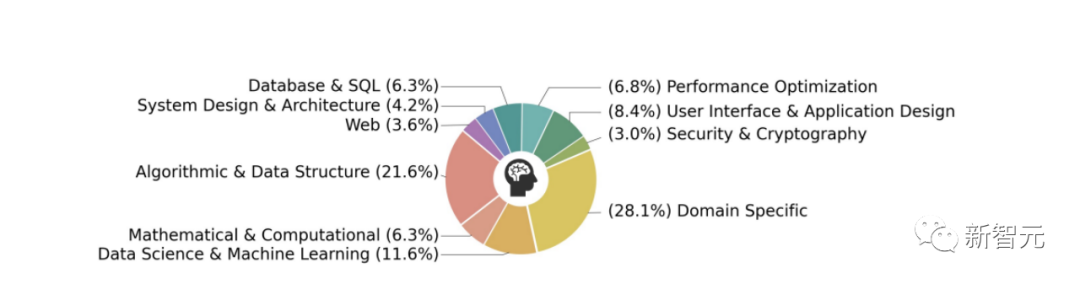
1. 类别平衡
如下图所示,通过计算OSS-INSTRUCT中每个样本的嵌入与这10个类别之间的余弦相似性,可以看出其在不同类别之间表现出了多样性和平衡。
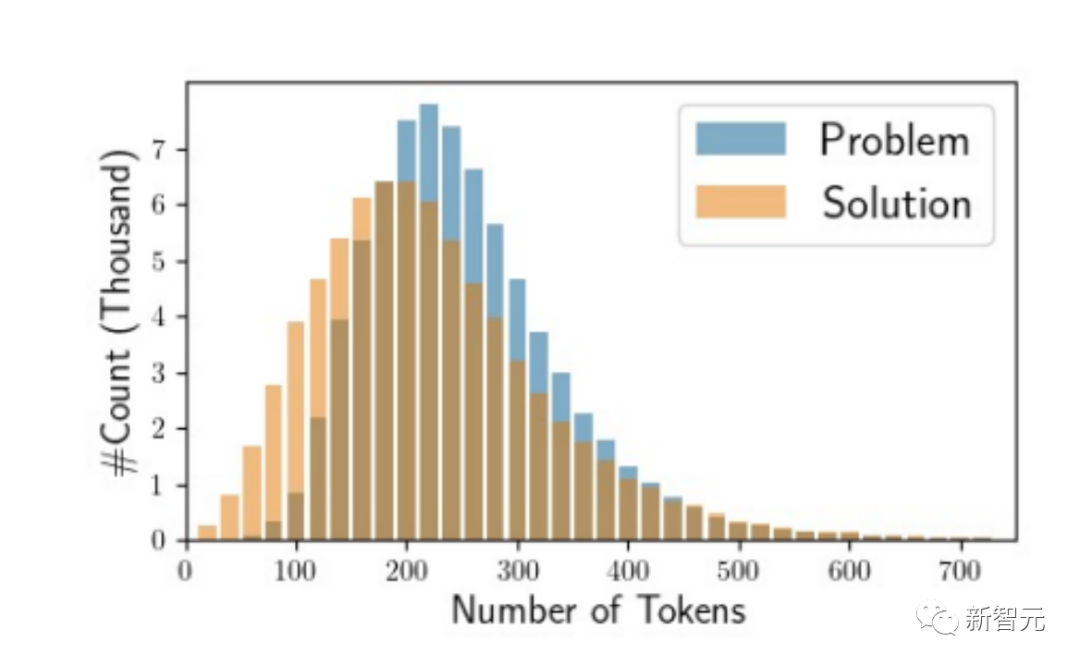
2. 长度分布
下图展示生成问题和解决方案的长度分布,良好的平衡性让OSS-INSTRUCT更贴合实际应用场景。
3. 与HumanEval的相似性计算
下图展示了与HumanEval样本的余弦相似性。
可以看出,OSS--INSTRUCT在所有研究的数据生成技术中表现出最低的平均相似度,这说明OSS--INSTRUCT生成的数据是最富有多样性的。
但是,既然OSS-INSTRUCT获取到的种子片段来自于开源代码,为什么不直接在这些开源代码上进行微调呢?为了回答这个问题,研究人员遵循CodeSearchNet,使用基础的CODELLAMA-PYTHON-7B对配对数据进行了2个时期的微调,遵循相同训练设置。对比结果如下表,在75,000个配对注释-函数数据上,微调甚至使基础模型恶化,而OSS-INSTRUCT有助于引入实质性的提升。研究人员推测,这种恶化可能是由这些配对数据固有的大量噪声和不一致性导致的。这进一步表明,数据的真实性对于代码指令调整至关重要,而非格式。该结果还凸显了OSS-INSTRUCT的优越性,可以将这些松散相关的代码片段转化为语义一致的指令调整数据。
研究团队首先构建了使用OSS-INSTRUCT进行训练的Magicoder系列,同时进一步组合使用OSS-INSTRUCT和Evol--INSTRUCT构建了MagicoderS系列,并在两个系列上都进行了测试。代码生成基准使用的是HumanEval和MBPP,这是目前两个最广泛使用的基准。这些基准中的每个任务都包括一个任务描述(例如docstring)作为提示,然后让LLMs生成相应的代码。其正确性由少量测试用例进行检查。为了更严格的评估,研究人员还使用了由EvalPlus框架支持的HumanEval+和MBPP+以获取更多的测试。值得注意的是,MagicoderS-CL和MagicoderS-DS在HumanEval+上的表现都优于只有7B参数的ChatGPT。1. Python语言
我们首先可以观察到Magicoder-CL相在HumanEval和HumanEval+上相对于CODELLAMA-PYTHON-34B有了实质性的改进。
MagicoderS-CL在HumanEval+上优于ChatGPT和所有其他开源模型。此外,尽管在HumanEval上得分略低于WizardCoder-CL-34B和ChatGPT,但在更严格的HumanEval+数据集上超过了它们,这表明MagicoderS-CL可能生成更稳健的代码。2. 其他编程语言
在除了Python之外的语言对比中,Magicoder-CL在所有研究过的编程语言中都大幅超过了基础的CODELLAMA-PYTHON-7B。此外,MagicoderS-CL在所有编程语言上都进一步改进了Magicoder-CL,仅使用7B参数就实现了与WizardCoder-CL-34B相当的性能。值得注意的是,Magicoder-CL仅使用非常有限的多语言数据进行训练,但仍然优于其他具有相似甚至更大规模的LLMs。这意味着LLMs可以从数据中学习超出其格式的知识。3. 数据科学库
最后,针对7个热门Python数据科学库的1,000个独特的数据科学编码问题(DS-1000 dataset),研究人员也进行了单元测试,旨在评估LLMs在实际用例中的表现。从表中可以看出,Magicoder-CL-7B已经在所有评估的基线中表现出色,包括最先进的WizardCoder-SC-15B,改善了8.3个百分点。虽然Magicoder还不够完美,但作者认为,通过公开分享所有的数据
和代码细节,会有越来越多的先进代码模型出现。https://arxiv.org/abs/2312.02120










