每位代码开发者的目标都是让事情正常运作。逐渐需要关心代码的可读性和可扩展性。装饰器(Decorators)是赋予函数额外行为的绝佳方式。而在函数定义中,代码开发者/数据科学家经常需要注入一些小的通用功能。通过装饰器(Decorators),可以大大减少代码重复,提高代码的可读性。接下来介绍一下python 装饰器(Decorators)以及在数据分析/数据科学中的常用的装饰器。
什么是Python装饰器(Decorators)
Python 装饰器是是个十分强大的功能,允许您修改函数或类的行为而不更改其源代码。它们本质上是接受另一个函数作为参数并返回一个包装原始函数的新函数的函数。这样,可以在不修改原始函数的情况下添加一些额外的功能或逻辑。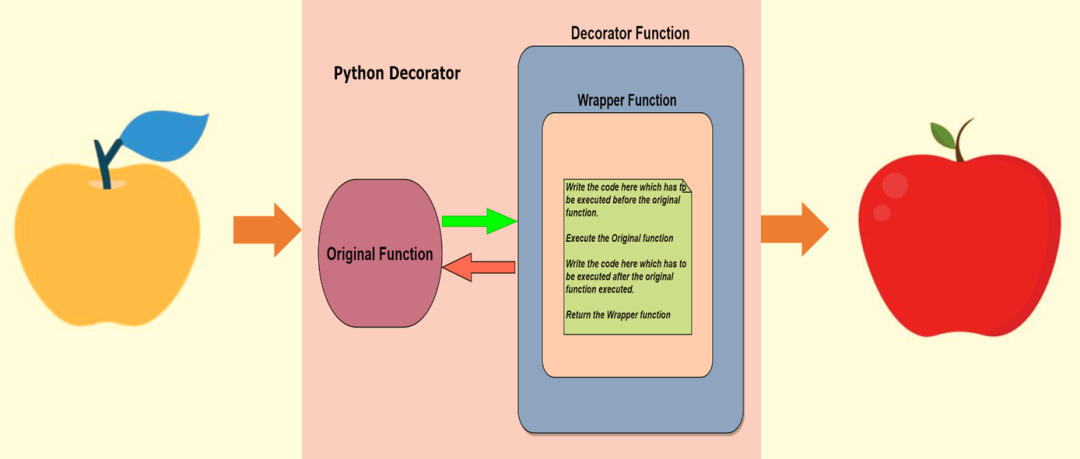
假如有一个打印hello world 的函数如下:
def hello(): print("Hello, world!")
现在我们想度量一下函数hello 的执行时间,我们可以写一个函数使用time 记录执行hello前后的时间差并进行输出,可以知道原始函数的执行时间。
import time
def measure_time(func): def wrapper(): start = time.time() func() end = time.time() print(f"Execution time: {end - start} seconds") return wrapper
注意,measure_time 函数返回另一个名为 wrapper 的函数,这是原始函数的修改版本。wrapper 函数执行两项任务:记录执行的开始和结束时间,并调用原始函数。
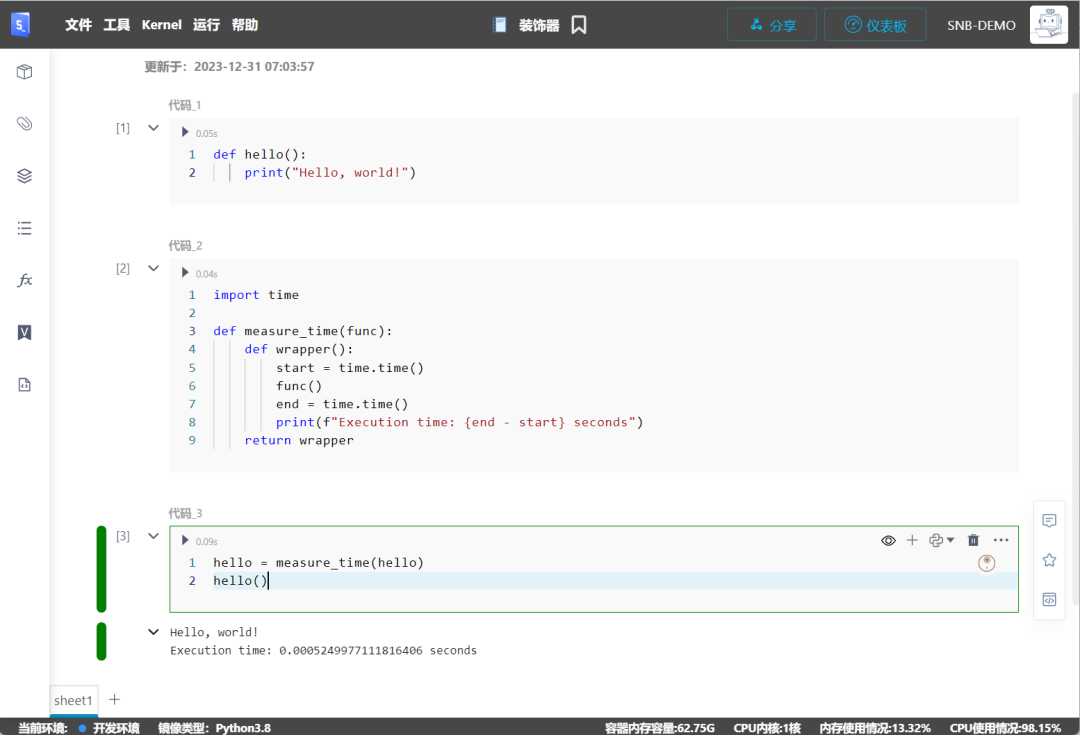
如下方式使用measure_time 套用hello 函数:
hello = measure_time(hello)hello()
执行结果如下:
如上图成功地为 hello 函数添加了一些额外的功能,而不改变其代码。然而,使用装饰器有一种更优雅且简洁的方式来实现这一点。装饰器只是一种语法糖,允许你使用 @ 符号将一个函数应用到另一个函数。例如,我们可以像这样重写前面的代码:
@measure_timedef hello(): print("Hello, world!")
hello()
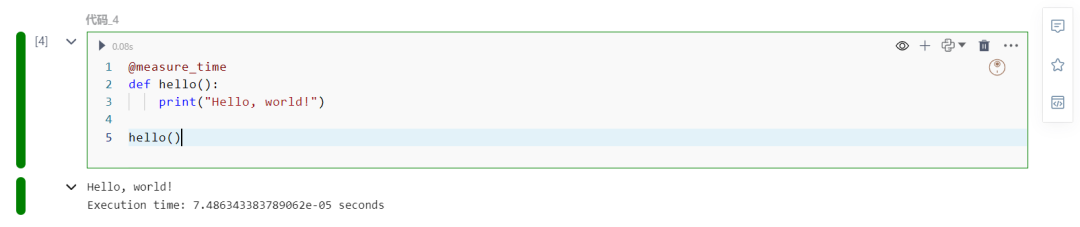
这将产生与之前相同的输出,但代码量要少得多。@measure_time 这一行等同于说 hello = measure_time(hello),但它看起来更加清晰和可读。
Python装饰器有许多有用之处,比如:
代码重用和避免重复: 允许你重复使用代码而不必反复编写相同的代码。例如,如果有许多函数需要测量它们的执行时间,你可以简单地将相同的装饰器应用于它们,而不是一遍又一遍地编写相同的代码。
分离关注点和遵循单一职责原则: 允许你将关注点分离,并遵循单一职责原则。例如,如果有一个执行一些复杂计算的函数,你可以使用装饰器处理日志记录、错误处理、缓存或输入输出的验证,而不会使函数的主要逻辑变得混乱。
扩展现有函数或类的功能而无需修改源代码: 允许你在不修改源代码的情况下扩展现有函数或类的功能。例如,如果你正在使用一个提供一些有用函数或类的第三方库,但你想要为它们添加一些额外的功能或行为,你可以使用装饰器将它们包装起来,并按照你的需求进行定制。
以下是数据分析/数据科学项目中经常使用的五种最常见的装饰器。
1. @retry 装饰器
在数据科学项目和软件开发项目中,我们经常依赖于外部系统,比如数据同步或数据加载,经常受限于网络等因素,导致数据同步或数据加载失败。当发生意外事件时,我们可能希望我们的代码等待一段时间,以便外部系统纠正自身并重新运行。Python装饰器中实现这种重试逻辑,可以在任何函数上加注以应用重试行为。这样可以复用和代码结构简单。
import timefrom functools import wrapsimport requests
def retry(max_tries=3, delay_seconds=1):
def decorator_retry(func): @wraps(func) def wrapper_retry(*args, **kwargs): tries = 0 while tries < max_tries: try: return func(*args, **kwargs) except Exception as e: tries += 1 if tries == max_tries: raise e time.sleep(delay_seconds) return wrapper_retry return decorator_retry
@retry(max_tries=5, delay_seconds=2)def call_dummy_api(): response = requests.get("https://www.kaggle.com/dd") return response
call_dummy_api()
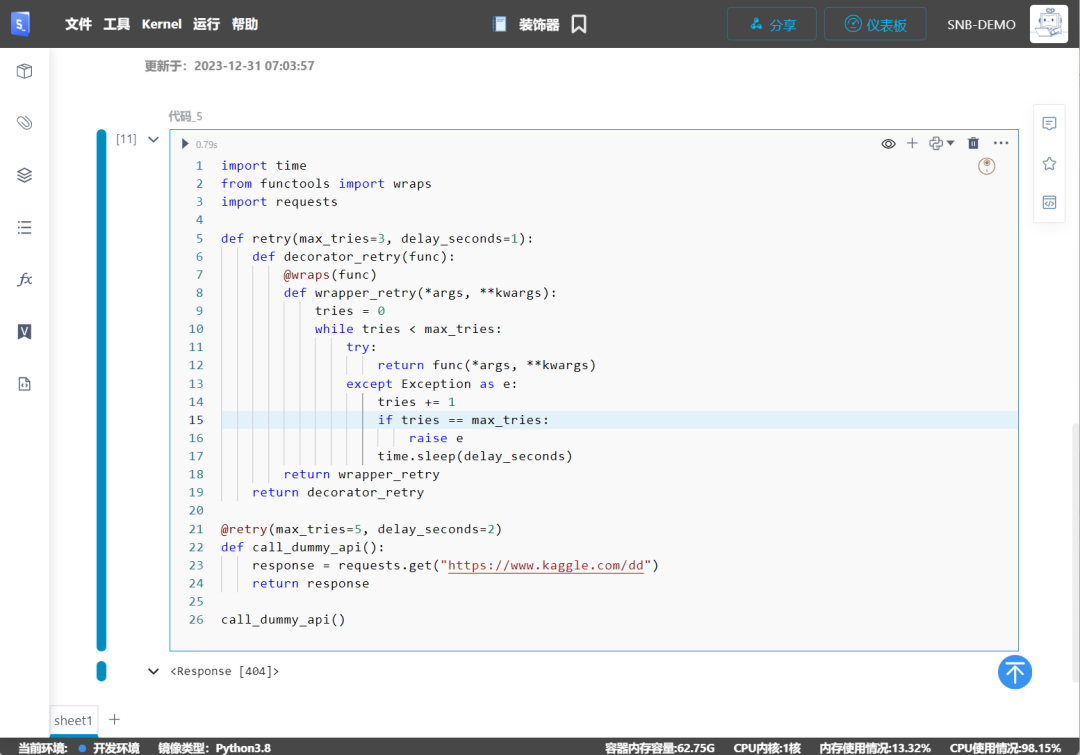
在上述代码中,我们尝试获取一个API响应。如果失败,我们将重试相同的任务5次。在每次重试之间,我们等待2秒钟。
2. @memoize 缓存装饰器(Caching function results)
我们的功能代码某些部分很少改变其行为。然而,它可能占用了大量的计算资源。在这种情况下,我们可以使用一个装饰器来缓存函数调用。如果输入相同,该函数将只运行一次。在每次后续运行中,结果将从缓存中获取。因此,我们不必一直执行昂贵的计算。def memoize(func): cache = {} def wrapper(*args): if args in cache: return cache[args] else: result = func(*args) cache[args] = result return result return wrapper
该装饰器使用一个字典来存储函数的参数和返回值。当我们执行该函数时,装饰器将在字典中查找先前的结果。只有在没有存储的值时才会调用实际的函数。
以下是一个计算斐波那契数的函数。由于这是一个递归函数,相同的函数被多次调用。但通过缓存,我们可以加速这个过程。
@memoizedef fibonacci(n): if n <= 1: return n else: return fibonacci(n-1) + fibonacci(n-2)
def slow_fibonacci(n): if n <= 1: return n else: return slow_fibonacci(n-1) + slow_fibonacci(n-2)
以下是该函数使用缓存和不使用缓存时的执行时间。下图计算n=40 的数列值,缓存版本只需要60毫秒的时间来运行,而非缓存版本几乎花费了44秒,二次相差700倍。
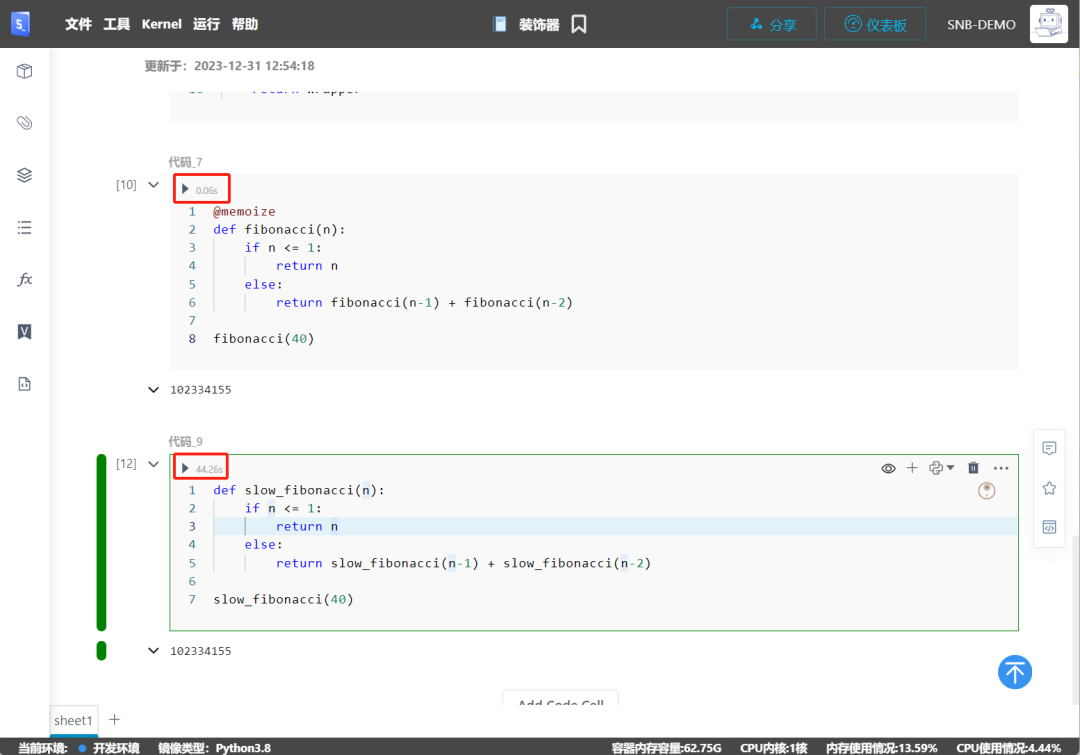
使用字典来保存先前的执行数据是一种直接的方法。然而,还有一种更复杂的存储缓存数据的方式,你可以使用内存数据库,比如Redis。3. @timing_decorator 记时装饰器(Timing functions)
在处理数据高密度计算函数时,我们渴望了解其运行时间。通常的做法是收集两个时间戳,一个在函数开始时,另一个在函数结束时。然后我们可以计算持续时间,并将其与返回值一起打印出来。但对多个函数重复执行这个过程很麻烦。相反,我们可以使用一个装饰器来实现。我们可以为任何需要打印持续时间的函数加注释。
下面是一个例子,展示了一个在调用时打印函数运行时间的Python装饰器:
import time
def timing_decorator(func): def wrapper(*args, **kwargs): start_time = time.time() result = func(*args, **kwargs) end_time = time.time() print(f"Function {func.__name__} took {end_time - start_time} seconds to run.") return result return wrapper
@timing_decoratordef my_function(): time.sleep(1) return
4. @log_execution 日志装饰器(Logging function calls)
日志装饰器是常用的功能,我们程序需要记录日志以便排查问题,使用日志装饰器可以简化代码,使日志更统一和明了;特别是在处理ETL(抽取、转换、加载)流水线时,需要标准统一日志规范。import loggingimport functools
logging.basicConfig(level=logging.INFO)
def log_execution(func): @functools.wraps(func) def wrapper(*args, **kwargs): logging.info(f"Executing {func.__name__}") result = func(*args, **kwargs) logging.info(f"Finished executing {func.__name__}") return result return wrapper
@log_executiondef my_function(x, y): time.sleep(1) return x + y
my_function(10,20)
单个函数上使用多个装饰器的方法:
@log_execution@timing_decoratordef my_function(x, y): time.sleep(1) return x + y
my_function(10,20)
5. 通知装饰器(Notification decorator)
在生产系统中非常有用的一个装饰器是通知装饰器。您的程序即使进行了多次重试,即使代码库经过了充分测试,仍然可能发生故障。当这种情况发生时,我们需要通知某人以便迅速采取行动。以下的装饰器在内部函数的执行失败时发送电子邮件。在你的情况下,这不一定是电子邮件通知,也可以配置它来发送短信、微信等其他通知。
import smtplibimport tracebackfrom email.mime.text import MIMEText
def email_on_failure(sender_email, password, recipient_email):
def decorator(func): def wrapper(*args, **kwargs): try: return func(*args, **kwargs) except Exception as e: err_msg = f"Error: {str(e)}\n\nTraceback:\n{traceback.format_exc()}" message = MIMEText(err_msg) message['Subject'] = f"{func.__name__} failed" message['From'] = sender_email message['To'] = recipient_email with smtplib.SMTP_SSL('smtp.gmail.com', 465) as smtp: smtp.login(sender_email, password) smtp.sendmail(sender_email, recipient_email, message.as_string()) raise return wrapper return decorator
@email_on_failure(sender_email='your_email@gmail.com', password='your_password', recipient_email='recipient_email@gmail.com')def my_function():
装饰器是将新行为应用于我们的函数的一种非常方便的方式。如果没有它们,将会有很多代码重复。我们讨论了数据集成/数据分析/数据科学项目最常使用的装饰器。你可以根据自己的需求对其进行扩展。例如,你可以使用Redis服务器来存储缓存响应,而不是使用字典。这将使你对数据有更多的控制,比如持久性。或者你可以调整代码,逐渐增加重试装饰器中的等待时间。











