来源:浪潮服务器
1956年,达特茅斯会议,“人工智能”概念被首次提出。他们梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样特性的机器。
发展至今,人工智能可以划分为两类:弱人工智能和强人工智能。前者让机器具备观察和感知的能力,能做到一定程度的理解和推理;而强人工智能是让机器获得自适应能力,解决一些从没遇到过的问题。这里的“智能”从何而来?人工智能又如何取得突破?要从一种实现人工智能的方法——机器学习说起。
白话版走心解读:从发展阶段来看,我们目前还处于弱人工智能阶段。幸运的是,似乎还不用担心人工智能是不是会把人类打趴在地;不幸的是,那些落地的人工智能应用已经出现了各种弊端和不足。所以我们现在更需要做的,可能不是恐惧机器会变成我们,而是如何让机器更理解我们。
什么是机器学习?
与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
白话版走心解读:在人工智能的研究上,“猫”一直是热门明星,所以我们就用“识别猫咪”来解释一下机器学习。假设要构建一个识别猫的程序:传统上如果想让计算机识别,需要输入一串指令,例如猫长着毛茸茸的毛、顶着一对三角形的耳朵等,然后计算机根据这些指令执行下去。但如果我们对程序展示一只老虎的照片,程序可能会沙雕……

除此外,传统方式要制定全部所需规则,而且过程中必然会涉及到一些困难的概念,比如对毛茸茸的定义。因此更好的方式是让机器自学。为计算机提供大量猫的照片,随着实验增加,系统会不断学习更新,最终能准确地判断出哪些是猫,哪些不是。
这里有三个重要信息:1. “机器学习”是“模拟、延伸和扩展人的智能”的一条路径,是人工智能的一个子集;2. “机器学习”要基于大量数据,也就是说它的“智能”是用大量数据喂出来的;(敲黑板!!!这个后面会用到)3. 正是因为要处理海量数据,所以大数据技术尤为重要,而“机器学习”只是大数据技术上的一个应用。
虽然传统的机器学习算法在指纹识别、人脸检测等领域的应用基本达到了商业化要求,但“再进一步”却很艰难,直到深度学习算法的出现。
什么是深度学习?
深度学习(Deep Learning)属于机器学习的子类,是目前最热的机器学习方法,但它并不意味着是机器学习的终点。它的灵感来源于人类大脑的工作方式,是利用深度神经网络来解决特征表达的一种学习过程。深度神经网络本身并非是一个全新概念,可理解为包含多个隐含层的神经网络结构。
白话版走心解读:我们来看看深度学习是如何工作的。以人脸识别为栗子。如果是传统机器学习,首先要确定相应的“面部特征”作为机器学习的特征(眼睛、鼻子等等),以此来对对象进行分类识别。而深度学习能自动找出这个分类问题所需要的重要特征。它是如何做到的?让机器深度学习,总共分三步:1. 确定出哪些边和角跟识别出人脸关系最大;2. 根据上一步找出的很多小元素(边、角等)构建层级网络,找出它们之间的各种组合;3. 在构建层级网络之后,就可以确定哪些组合可以识别人脸。来个示意。
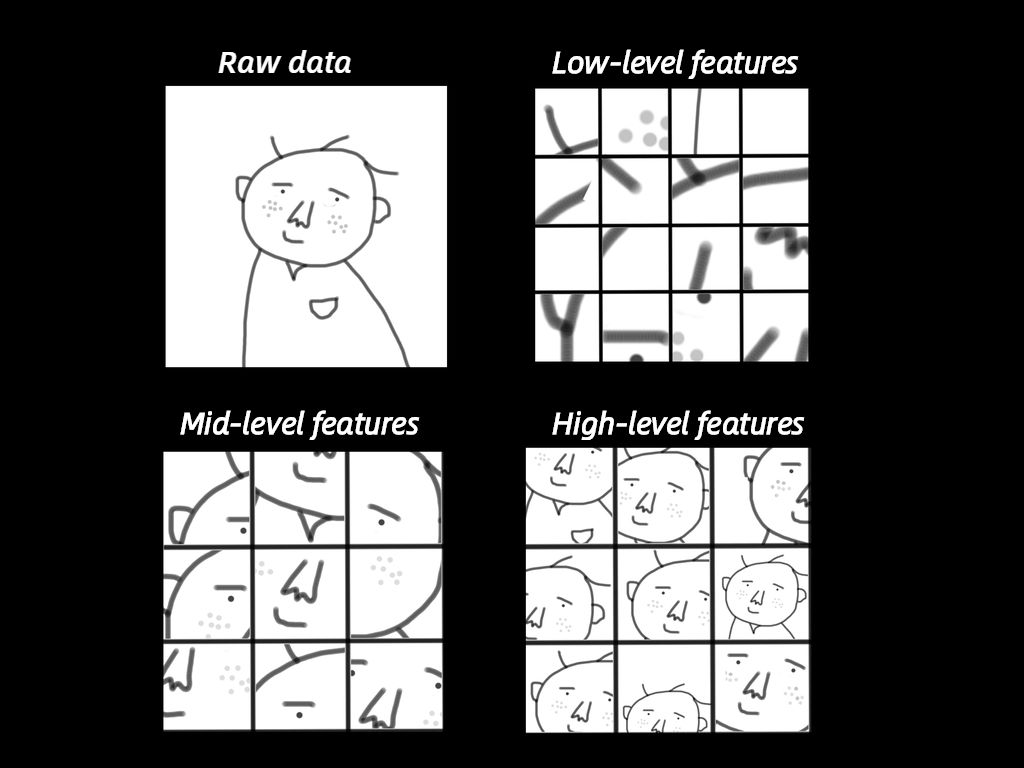
第一步,输入的是Raw Data,就是原始数据,这个机器是没法理解的。于是,深度学习首先尽可能找到与这个头像相关的各种边,这些边就是底层的特征(Low-level features);然后下一步,对这些底层特征进行组合,就可以看到鼻子、眼睛、耳朵等,它们是中间层特征(Mid-level features);最后,对鼻子、眼睛等进行组合,就可以组成各种各样的头像,也就是高层特征(High-level features)。这个时候,它就可以识别出各种人的头像了。
机器学习和深度学习有哪些维度的不同?
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。一个同心圆就可以展现出它们的关系。
具体不同大致有以下几点。
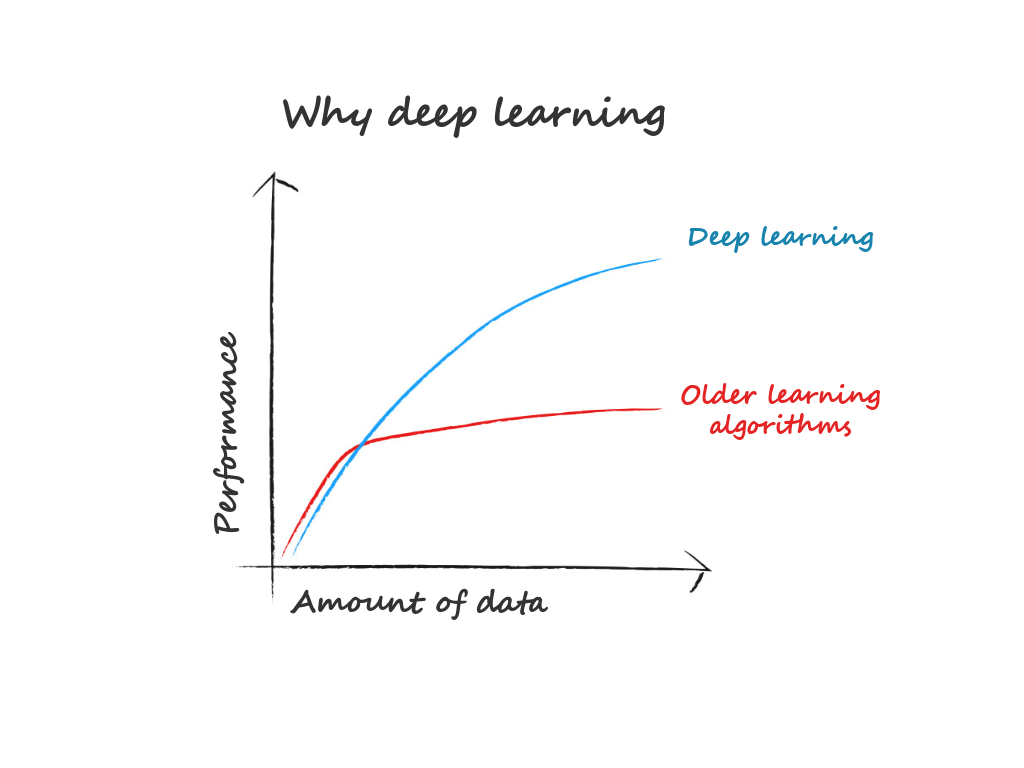
1. 数据依赖。随着数据量的增加,二者的表现有很大区别。深度学习适合处理大数据,而数据量比较小的时候,用传统机器学习方法也许更合适。
2. 硬件依赖。深度学习十分地依赖于高端的硬件设施,因为计算量实在太大。它会涉及很多矩阵运算,因此很多深度学习都要求有GPU(专门为矩阵运算而设计的)参与运算。
3. 特征工程。简单讲就是在训练一个模型的时候,需要首先确定哪些特征。在机器学习方法中,几乎所有特征都需要人为确认后,再进行手工特征编码。而深度学习试图自己从数据中学习特征。
4. 解决问题的方式。(重点!)解决问题时,机器学习通常先把问题分成几块,一个个地解决好之后,再重新组合。但是深度学习是一次性、端到端地解决。
白话版走心解读:举个栗子。
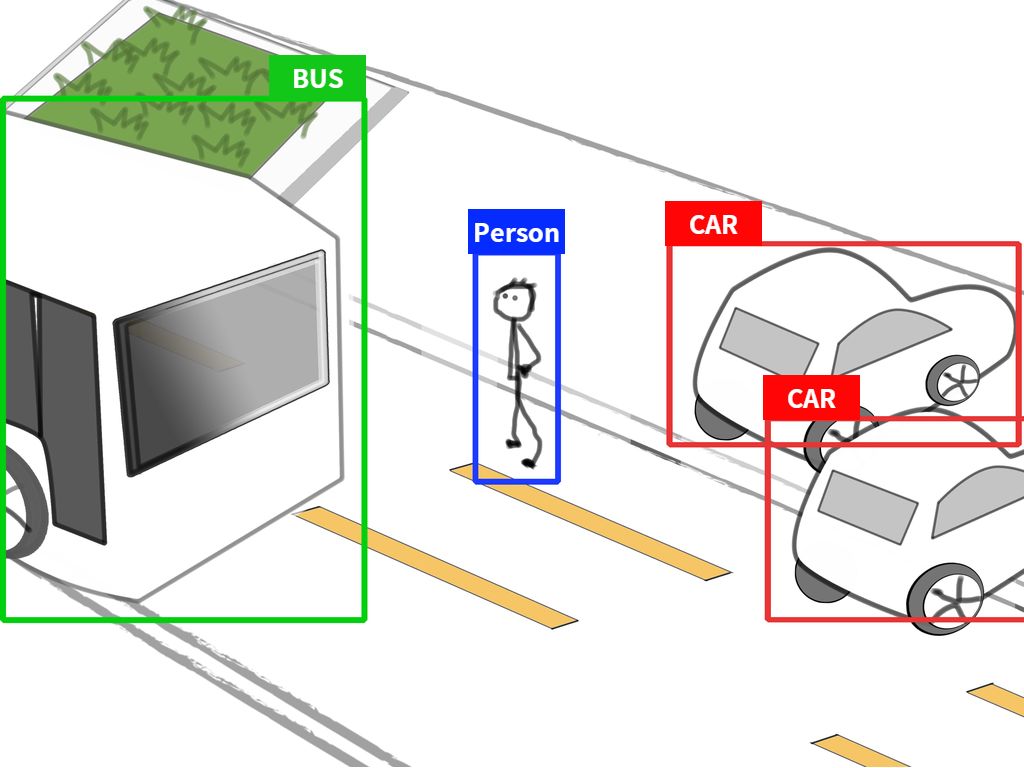
我们设定任务是识别出图片上有哪些物体,并找出它们的位置。机器学习的做法是把问题分两步:发现物体和识别物体。但深度学习不同,它可以直接把对应物体识别出来,同时还能标明对应物体名字。这个好处就是,实时性。
5. 运行时间。深度学习需要花大量时间来训练,因为有太多参数要去学习。机器学习一般几秒钟最多几小时就可以训练好。但深度学习训练出的模型优势就在于,在预测任务上运行非常快。也是刚刚提到的实时物体检测。
深度学习前加个“分布式”,又是怎么回事?
面对越来越复杂的任务,数据和深度学习模型的规模都变得日益庞大。当训练数据词表增大到成百上千万时,如果不做任何剪枝处理,深度学习模型可能会拥有上百亿、甚至是几千亿个参数。
为了提高深度学习模型的训练效率,分布式训练出现了——即同时利用多个工作节点,分布式地、高效地训练出性能优良的神经网络模型。
目前主要有两种并行化/分布式训练方法:数据并行化和模型并行化。
数据并行化里,不同的机器有同一个模型的多个副本,每个机器分配到数据的一部分,然后将所有机器的计算结果按照某种方式合并;模型并行化里,分布式系统中的不同机器负责单个网络模型的不同部分。比如,神经网络模型的不同网络层被分配到不同机器。
白话版走心解读:“并行化”顾名思义,就是一起并肩工作。酷暑正当,我们就用制作棒冰举栗子。先说数据并行化。工厂A要在一天内做50000支棒冰,为了更高效完成,这个任务被分给了100个车间,当然开工前需要大家进行培训,确保每个人都了解了棒冰的制作过程。这里的“车间”就是机器,“50000支”就是数据,“培训资料”就是模型。
同理,模型并行化就是这样。同样是50000支棒冰,但其中10000支生产简单,其余40000支工艺复杂。于是车间里两位师傅分别扛起了这两部分任务,分头进行。“50000支”就是数据,“师傅”就是GPU,生产工艺就是“模型”,不同工艺就相当于不同的网络层。
本文仅做学术分享,如有侵权,请联系删文。










