引言
在当今的技术时代,大型语言模型如GPT-4和PaLM-2等已成为人工智能领域的重要成就。这些模型以其强大的语言理解和生成能力,在各种应用中发挥着关键作用。此类模型的内部工作机制却鲜为人知,这种不透明性会引发人们对模型安全性的担忧,特别是模型窃取攻击,「这种攻击可能通过API访问来提取模型的关键信息」。
为此,Google、OpenAI等研究人员探索了这种攻击的可行性,特别是针对那些只提供有限输出信息的大模型API。作者攻击恢复了Transformer模型的嵌入投影层(Embedding Projection Layer),且「花费不到 20 美元就提取了 OpenAI 的 Ada 和 Babbage 语言模型的整个投影矩阵」。更令人震惊的是他们精确的恢复了gpt-3.5-turbo 模型的隐藏维度,并指出可以花费不到2000$就能恢复其投影矩阵。 https://arxiv.org/pdf/2403.06634.pdf
https://arxiv.org/pdf/2403.06634.pdf
背景介绍
当前我们震惊于大语言模型(例如 GPT-4、Claude 2 或 Gemini)在各种任务上的表现,但是对于模型的内部工作原理知之甚少。就好比在GPT-4的技术报告中,并没有对模型具体架构、模型大小、硬件、训练方法、数据集构建等做过多详细的介绍;同样在PaLM-2的论文中,也并没有对外详细纰漏模型大小、模型架构等信息。这种保密行为,主要归因于行业竞争和模型安全性,因为大模型训练成本很高。然而,「虽说这些模型的权重和内部细节并未公开,但模型本身却可以通过API公开访问」。那么我们能否通过公开的API接口窥探模型的内部信息呢?再进一步,是否能够获取模型的权重信息呢?
解决以上两个问题的关键就是采用模型窃取攻击技术,此类技术的主要目的是从一个黑盒模型中恢复其原有功能,优化的目标有两个:准确性(Accuracy)和保真度(Fidelity)。
「准确度」:窃取的模型(记为)应该在某个特定数据域上与目标模型(记为)匹配。例如,如果目标是一个图像分类器,窃取的模型在ImageNet数据集上的总体准确率应该与目标模型相匹配。
「保真度」:窃取的模型(记为)应该在所有输入上与目标模型(记为)功能等价。也就是说,对于任何有效输入p,我们希望。
在这里,本文主要关注高保真度攻击。大多数以前的高保真度攻击利用了具有ReLU激活函数的深度神经网络的特定属性。此类攻击方法都无法扩展到生产语言模型,因为它们(1)输入只接收Token(因此执行有限差分是不切实际的);(2)使用了除ReLU之外的激活函数;(3)包含当前攻击无法处理的架构组件,如注意力、层归一化、残差连接等;(4)比之前提取的模型大几个数量级;(5)只暴露有限精度的输出。
基于以上考虑,本文作者介绍了一种可用于黑盒语言的攻击方法,它能够恢复Transformer语言模型的完整嵌入投影层(Embedding Projection Layer)。
攻击提取Logit-Vector
关于Logit-Vector API的提取攻击,作者介绍了一种新的攻击方法,这种方法假设攻击者可以直接观察到模型为词汇表中的每个标记生成的完整logit向量。这种假设在实践中并不总是成立,因为大多数生产模型不会提供这样的API。
作者首先提出了一种简单的攻击,允许攻击者通过向模型提出大量不同的随机前缀查询来「恢复语言模型的隐藏维度大小」。具体算法,如下图所示: 通过这种方式,攻击者可以识别出模型输出向量实际上位于一个较低维度的子空间内,因为嵌入投影层是从较低维度上投影到较高维度的。当查询足够多时,新的查询将与过去的查询线性相关,这时攻击者可以计算这个子空间的维度,从而确定模型的隐藏维度。
通过这种方式,攻击者可以识别出模型输出向量实际上位于一个较低维度的子空间内,因为嵌入投影层是从较低维度上投影到较高维度的。当查询足够多时,新的查询将与过去的查询线性相关,这时攻击者可以计算这个子空间的维度,从而确定模型的隐藏维度。
接着,作者提出了一种更复杂的攻击,旨在「恢复模型的最后一层权重矩阵」,即从最终隐藏层映射到输出logits的矩阵「W」。通过利用之前攻击中确定的隐藏维度,攻击者可以提取模型的嵌入维度或其最终权重矩阵。这种攻击的有效性和效率取决于API提供的信息类型,例如是否提供完整的logprobs或logprobs标记。
攻击提取Logit-Bias
作者详细介绍了一种针对Logit-Bias API的提取攻击,旨在从只提供顶部K个标记的对数概率(logprobs)和允许施加logit偏置的API中恢复出完整的logit信息。这种API虽然限制了信息的直接访问,但攻击者可以通过调整偏置并观察输出来间接推断出未直接提供的logits。
作者提出了一种方法,通过多轮查询和线性规划技术来解决由logit偏置产生的线性约束,从而逐步构建出完整的logit向量。此外,为了提高攻击的效率和稳定性,作者还探讨了如何通过调整偏置来实现所有输出标记的均匀采样。这些技术展示了即使在受限的API环境中,攻击者也能够通过创新的方法提取模型的关键参数,对于加强模型安全性具有重要意义。
Logprob-free攻击
当在模型API中在无法获取log概率信息时,如何从黑盒模型中提取关键信息。面对这种挑战,作者提出了一系列无需logprob的攻击方法,这些方法通过调整logit偏置并观察模型的输出来逐步恢复logit值。
具体来说,攻击者可以使用二分搜索策略来确定每个标记的logit值,或者采用“超矩形松弛中心”方法,通过线性规划来解决由logit偏置产生的线性约束,以更精确地估计logit值。此外,作者还提出了一种将问题转化为加权图中最短路径问题的方法,从而在每次查询后快速计算出所有标记的logit值的精确区间。这些技术展示了即使在严格的API限制下,攻击者也能够通过创新的方法提取模型的关键参数,对于加强模型安全性具有重要意义。
实验结果
如下图,作者能够以高精确度提取OpenAI的ada和babbage模型的嵌入投影矩阵,误差小于7×10^-4,如表4所示。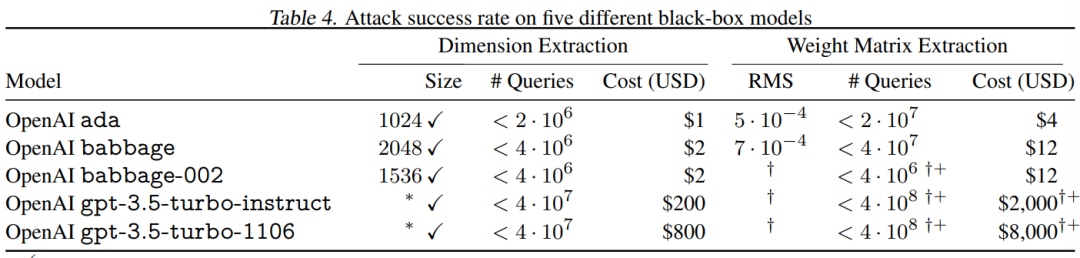
推荐阅读
[1]2024!深入了解:大语言模型微调方法(总结)
[2]AI培训师!微软提出交互式培训框架:IMBUE
[3]特别详细!一文了解扩散模型(不含任何公式)
[4]EMNLP2023 10篇关于中文自然语言的论文!
[5]2023年10月 爆款论文总结,共计12篇
[6]Meta提出BSM,Llama-chat媲美GPT-4!
投稿或寻求报道联系:ainlperbot
点击下方链接🔗关注我们









