编者荐语:
这篇论文探讨了利用机器学习技术在冲突预测领域的潜在可行性,并对数据的选择进行了详细论述。文章的研究结果指出:暴力事件受到详细的事件分类历史的影响,同时社会经济数据可以很好地替代历史事件数据,这一发现对于数据的可替代性提供了新的视角。
点击标题下方蓝字 关注+星标 “Political理论志”
不错过社会科学前沿精彩信息哦
具体操作如右 →
暴力事件预测的可行性有多大?哥伦比亚和印度尼西亚拥有异常精细的数据。我们收集了二十年来当地发生的暴力事件以及数百个年度-风险因素。我们尝试使用一系列机器学习技术提前一年预测暴力事件。我们的模型可以可靠地识别出持续的暴力高发热点。暴力事件并不是简单的自回归现象,详细的暴力事件分类历史最能说明问题,但社会经济数据能很好地替代这些历史数据。然而,即使有异常丰富的数据,我们的模型也很难预测新的暴力爆发或暴力升级。这些使用年度数据的 "最佳情况 "并不是可行的预警系统。
Samuel Bazzi. 加州大学圣地亚哥分校教授
Robert A. Blair. 布朗大学国际与公共事务副教授
Christopher Blattman. 芝加哥大学哈里斯公共政策学院教授
Oeindrila Dube. 芝加哥大学哈里斯公共政策学院教授
Matthew Gudgeon. 塔夫茨大学经济系助理教授
Richard Peck. 伊利诺伊大学芝加哥分校经济学副教授
文献来源:
Bazzi, S., Blair, R. A., Blattman, C., Dube, O., Gudgeon, M., & Peck, R. (2022). The promise and pitfalls of conflict prediction: evidence from Colombia and Indonesia. Review of Economics and Statistics, 104(4), 764-779.

主流的冲突预测仍侧重于大规模的国家级事件,包括政变、内战和恐怖袭击。但是,国家层面的冲突预测是复杂且随机的,在广泛的时间和空间内难以实施。地方层面的预测可能会更加富有成果。通过对印度尼西亚和哥伦比亚两个案例的分析,并使用多种机器学习方法来生成年度当地暴力事件的预测,我们尝试阐明地方层面冲突预测的前景和陷阱。这项研究的一个重要贡献是我们收集的两个数据集。在每个国家,我们收集并拼接了数十个地方级数据集,其中大部分以前从未整合过。我们选择这印度尼西亚和哥伦比亚这两个案例的原因是,就年度面板形式的暴力和潜在暴力预测因素的数据可用性而言,它们是当前最好的案例之一。迄今为止,此类年度数据是各国最常见的数据类型(尤其是预测变量)。另外,两国在向国家和平过渡的过程中都反复发生局部暴力事件。印度尼西亚:我们的分析单位是印度尼西亚的第三级行政区划,称为分区 (kecamatan),是可以随着时间的推移系统跟踪暴力的最精细级别。我们的主要数据来自印度尼西亚国家暴力监测系统(印度尼西亚语缩写 SNPK),提供有关微观层面暴力的独特而丰富的数据。该数据库是根据当地媒体对暴力事件的报道建立的。SNPK 研究人员收集了 120 份当地报纸的所有可用印刷档案,记录了超过 200 万张图像。然后,编码人员使用标准化模板根据潜在触发因素对每个事件进行编码,从广泛的分组开始:家庭暴力、暴力犯罪、执法期间的暴力和冲突。在冲突中,编码员进一步分类为身份、选举和任命、治理、资源暴力、大众正义、分裂主义和其他。
除了详细的暴力历史之外,我们还从多个数据源收集了一组 482 个分区级预测变量。为了评估相关协变量集的预测性能有何差异,我们将协变量分为多个预测变量组。有些特征,如地理特征,本质上是不随时间变化的。其他因素,例如 2000 年人口普查中的种族和宗教比例,仅在研究期开始时观察到一次,因此它们在我们的面板中是不随时间变化的。
哥伦比亚:我们对哥伦比亚的分析单位是市镇 (municipio)。冲突分析资源中心 (CERAC) 提供 1988 年至 2005 年武装对抗的数据。我们还通过使用罗萨里奥大学截至 2014 年收集的冲突数据的其他来源,将数据扩展到 2005 年之后。CERAC 数据集包含超过 21,000 件哥伦比亚内战事件,这些事件取自两个哥伦比亚非政府组织:研究与大众教育/和平计划中心 (CINEP) 和 Justiciay Paz 出版的期刊。该数据集专注于出于政治动机的武装团体所实施的与战争相关的行动。事件被编码为双方之间的双边冲突或任何一方对另一方的单方面攻击。这些数据分别对军队、各种准军事组织和几个游击队组织(最大的是哥伦比亚革命武装力量)的暴力行为进行了分类。
与印度尼西亚一样,我们从多个来源收集了广泛的预测变量:总共超过 310 个。我们的模型包括所有暴力预测变量的两个滞后以及其他随时间变化的预测变量的滞后(视可用性而定)。
为什么选择印度尼西亚和哥伦比亚的暴力数据:首先,长时间在如此多的地方单位系统地提供大量的协变量数据是很少见的。其次,两国都提供最先进的地方暴力数据。例如,SNPK 就是为了解决印度尼西亚早期暴力数据集的缺陷而做出的明确尝试,两种来源均经过精心记录,并接受各种质量控制措施。每一项都已在学术文献中得到有效部署。第三,数据来源于大量高质量的本地语言报纸。这种情况很少见,因为大多数新闻编码数据集主要来自国际新闻服务。在许多低收入国家,当地报纸的数量和质量都极差,冲突地区的新闻报道很少。
方法简述:对于每年 t,我们预测 t + 1 年的暴力事件。虽然事件是用特定日期编码的,但我们汇总到年度水平,因为很少有预测变量以亚年频率进行测量,而且分解会加剧暴力事件的发生。
我们使用五重交叉验证来选择特定于每种机器学习算法的最佳调整参数。首先,将数据随机划分为五个大小相等的子样本,然后将模型拟合到四个子样本并用于预测第五个子样本中的暴力行为。对五个子样本中的每一个重复此操作,以便对每个观察结果进行样本外预测。我们使用不同的随机分区重复步骤十次,以生成十个“最佳”调整参数,然后我们取这十次试验的平均值。使用选定的调整参数值,我们将模型拟合到整个训练集。通过这个拟合模型,我们使用 t 年测量的预测变量和估计参数来预测 t + 1 年的暴力事件。 结果1:表 1 显示,经测试的所有机器学习方法都具有很强的预测性能,且在印度尼西亚和哥伦比亚的案例中表现相似。对于整体平均值 (EBMA),预测一个或多个事件的 AUC 高于 0.82,预测五个或更多事件的 AUC 高于 0.91,预测 1 个或多个标准差的 AUC 高于 0.80。表1 机器学习的性能优于相对简单的基准模型。表2将机器学习方法与更简单的基准模型进行了比较。使用广泛的冲突预测数据集,仅 OLS 就可以很好地预测冲突。但是,线性回归模型似乎对数据过度拟合,生成的预测表现不如表1第1列中灵活性较差的 LASSO 模型。此外,线性回归无法对变量之间的相互作用进行建模。滞后预测模型(the lagged predictand model)在预测印度尼西亚和哥伦比亚冲突数量迅速增加方面尤其糟糕。
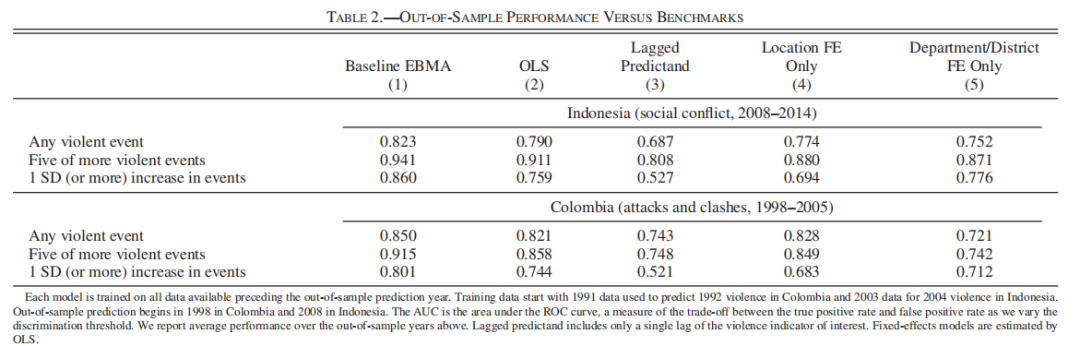
表2
我们的模型包含足够的随时间不变的协变量(time-invariant covariates),原则上机器学习性能可以简单地近似固定效应。因此,第4栏研究了一个简单的 OLS 固定效应模型。我们发现,在所有情况下,使用全套协变量进行的预测都优于固定效应模型。事实上,我们的基线模型在印度尼西亚的相对表现最好,并且在因变量较少的情况下,从估计方差的角度来看是直观的。
结果2:我们的算法的强大性能主要是由对暴力可能发生的地点而不是时间的预测驱动的。冲突历史本身就能很好地预测未来的冲突。我们仅考察暴力历史的预测能力,如表3所示,这些历史不仅仅是滞后的因变量。相反,它们包括事件的数量和严重程度(例如死亡人数、财产破坏)以及所涉及的行为者,并且在印度尼西亚,区分了十种不同暴力类别中的每一种。
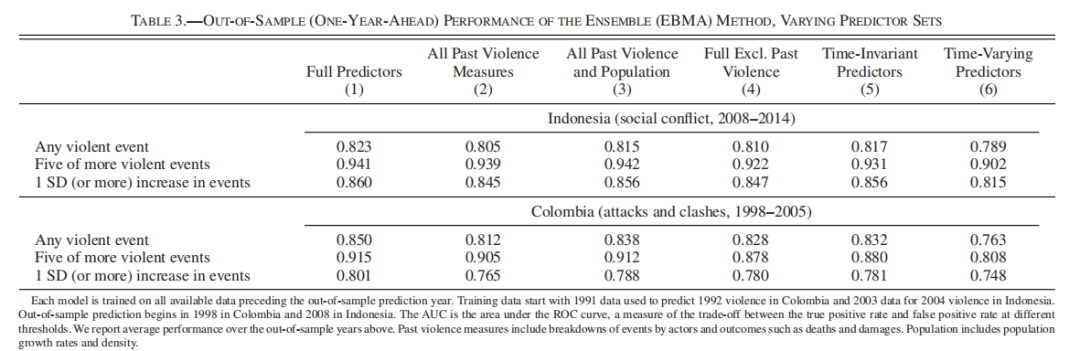
表3
时不变预测变量在我们的模型中最有效。表3第4列显示了仅使用不直接衡量过去暴力行为的预测变量的模型的结果。其中包括上面讨论的数百项社会经济和人口统计指标。第1列中的完整模型和第2列中的暴力模型性能相当。这表明这些社会经济和人口变量或多或少包含与详细暴力历史相同的信息,但它们几乎没有增加任何价值。特别是,我们的模型包含许多变化缓慢或根本不变化的预测变量。有些,例如地形特征或殖民历史,在定义上并没有变化。其他特征,例如印度尼西亚的种族和宗教特征,在我们的样本中没有变化,因为它们只测量一次。
我们尝试预测每个地点的暴力事件数量与其历史平均值的偏差。性能很差。这些结果进一步凸显了根据现有数据预测单位内暴力变化的难度。跨地点预测和未来一年预测之间的一个显着区别是,前者使用训练集跨地点方法中所有年份的可用数据。算法会观察一段时间内天气、灾害和商品价格波动的整个相关分布。这些变量每年的表现可能有很大不同。当我们预测未来一年的暴力事件时,如果训练期包括此类冲击而测试期不包括这些冲击,那么这些时期缺乏共同支持可能会抑制这些变量的预测能力。因此,训练和测试样本的时间序列较短,以及生成无支持预测的困难,可以解释为什么随着时间的推移,天气冲击等时变协变量在我们的预测中表现较差。本研究的结果似乎表明,印度尼西亚和哥伦比亚的当地暴力是可以预测的,且准确度相对较高。这种可预测性很大程度上建立在特定时间何地点的风险。机器学习方法可以帮助识别暴力热点,而如果使用更简单的预测方法,这些热点可能会更加模糊。然而,暴力的逐年变化仍然难以预测。首先,暴力随时间变化的维度可能只是特殊的,因此难以预测。再来,暴力预测对武装行为者的战略计算做出内生反应。例如,政府安全部队粗略地预测了该地区的高冲突风险并相应地分配了资源,恐怖分子也可能因为那里是最不可能发生袭击的地方决定攻击某个地区。各种测量问题也可能限制模型性能。编码的暴力数据或来自新闻报道的数据通常是最好或唯一的可用信息来源,但这些数据仍然容易出现错误分类或遗漏。再来,暴力发生的时间可能取决于一些本质上难以观察和衡量的因素,例如社会不满或社区信任的恶化。获取当地暴力的高频数据和主要测量指标是冲突预测的改进途径。目前,很少有发展中国家提供此类数据。但在不久的将来,社交媒体数据、手机元数据、实时事件数据和媒体监测数据都有可能出现,有助于研究随时间变化的冲突预测。本文内容仅供参考,不代表Political理论志观点
“在看”给我一朵小黄花









