基于最优传输思想设计的分类损失函数EMO解决了交叉熵损失函数在某些场景暴露的一些问题,如偏离评价指标、过度自信等,它源于交叉熵损失函数,能大幅提高 LLM 的微调效果。
交叉熵损失函数是最常用的一种损失函数。在机器学习中,损失函数是衡量模型性能的关键性指标,它不仅指导着模型的训练过程,影响模型的优化方向,还直接影响到最终模型的泛化能力和实用性,对于实现高效、准确的机器学习模型至关重要。
常用的损失函数主要可以分为两大类:分类问题的损失函数和回归问题的损失函数。今天我就从这两大类入手,介绍6个深度学习最常用的损失函数,每种损失函数都附上了2024最新的研究成果(共18篇),方便各位学习。
扫码添加小享,回复“损失函数”
免费获取全部论文+开源代码

分类问题的损失函数:
交叉熵损失函数
主要用于度量分类问题中预测值与真实标签之间的差距,尤其在多分类问题中表现良好,如图像分类、自然语言处理等领域。
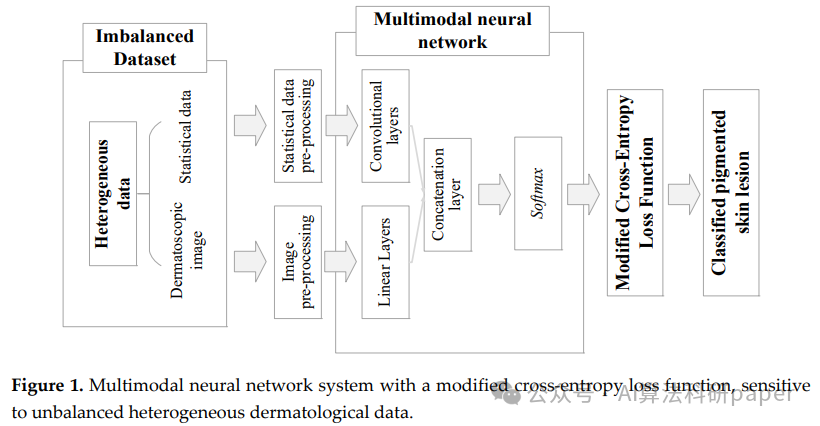
例文:Multimodal Neural Network System for Skin Cancer Recognition with a Modified Cross-Entropy Loss Function
方法:本研究提出了一种具有修改的交叉熵损失函数的多模态神经网络系统,用于识别恶性色素性皮肤病变。通过使用权重系数来修改学习损失函数,可以提高神经网络分析的准确性,并减少将皮肤癌误认为良性的假阴性预测的数量。
创新点:
- 本研究提出了一种多模态神经网络系统,使用改进的交叉熵损失函数来分析异质皮肤病变数据。
- 该研究开发的多模态神经网络系统在敏感于不平衡数据的情况下,具有更高的皮肤病变识别准确率。
- 该研究提出的改进的交叉熵损失函数在训练多模态神经网络系统时起到了关键作用。
EMO损失函数
针对交叉熵损失存在问题的改进方案,源于交叉熵损失,它通过引入最优传输的思想来解决传统交叉熵损失函数的某些局限性,从而在特定任务中实现了性能的提升。
EMO: Earth Mover Distance Optimization for Auto-Regressive Language Modeling
方法:论文介绍了一种用于训练自回归语言模型的新方法,名为EMO。与传统的基于最大似然估计(MLE)的训练方法相比,EMO通过优化地球移动距离(EMD)的可微上界来改进模型的分布与人类文本分布之间的匹配。
创新点:
- 引入了Earth Mover Distance Optimization作为自回归语言模型训练的一种方法,通过优化模型分布与人类文本分布之间的可微上界来改进MLE的训练目标。
- 开发了可微分的EMD的上界(DEMD),可以在端到端的方式下进行优化,而无需外部专门的求解器。
- 通过EMO在轻量级微调阶段应用于预训练LLM,可以显著提高LLM在多个下游语言理解任务上的性能。

合页损失
常用于支持向量机(SVM)中,适用于二分类问题,能够提供最大间隔的划分超平面。
例文:High-dimensional sparse classification using exponential weighting with empirical hinge loss
方法:针对高维二分类问题,论文提出了一种基于指数权重和经验hinge损失的聚合技术解决方案。通过使用适当的稀疏先验分布,证明了该方法在预测误差上具有良好的理论结果。
创新点:
- 提出了一种基于指数加权和经验铰链损失的聚合技术,用于解决高维二分类问题。
- 引入了适合的稀疏先验分布,展示了我们的方法在预测错误方面的有利理论结果。

回归问题的损失函数:
均方误差
是回归任务中最通用的损失函数,表示目标值与预测值之间差值平方和的均值,具有易导和存在解析解的优点,但对异常值不鲁棒。
例文:Interpolatory model order reduction of large-scale dynamical systems with root mean squared error measures
方法:论文提出了一种用于模拟大规模频域问题的线性二次输出系统类的RMS误差模型的处理方法。作者介绍了一个具体的例子,并讨论了时间域系统的一些已有理论。接着,文章讨论了线性系统的插值方法,并对作者考虑的系统类提出了新的插值理论扩展。
创新点:
- 提出了一种针对频域线性二次输出系统的插值方法,旨在准确近似传递函数。
- 引入了一种新的插值框架,用于针对文中考虑的系统类别进行插值条件的强制。
扫码添加小享,回复“损失函数”
免费获取全部论文+开源代码
平均绝对误差
计算的是真实值与预测值之差的绝对值的平均,对异常值相对更鲁棒。
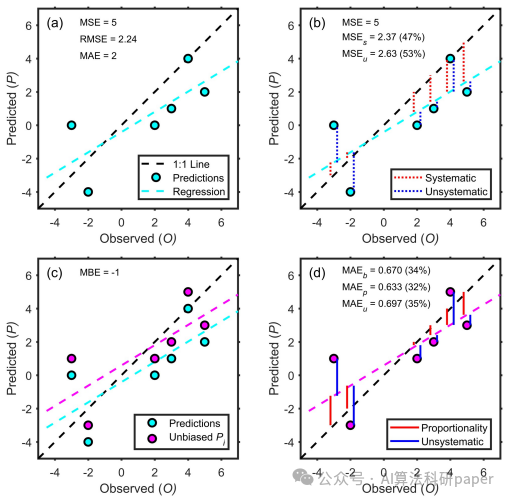
例文:Decomposition of the mean absolute error (MAE) into systematic and unsystematic components
方法:论文提出了一种将均方差(MSE)和均方根误差(RMSE)分解为偏差误差、比例误差和无系统误差三个部分的方法,以更准确地评估模型的误差。
创新点:
- 引入了一种新的方法,将MAE分解为偏差、比例误差和非系统误差。这些组成部分提供了评估模型错误的更可解释的标准,同时指出可能减少的更具体类型的错误。
- 引入了一种新的权重函数,用于将MAE分割为偏差、比例误差和非系统误差。这种权重函数提供了一种合理的方法,用MAE作为平均模型误差的基准。
Huber损失
结合了MSE和MAE的优点,对异常点具有一定的鲁棒性。
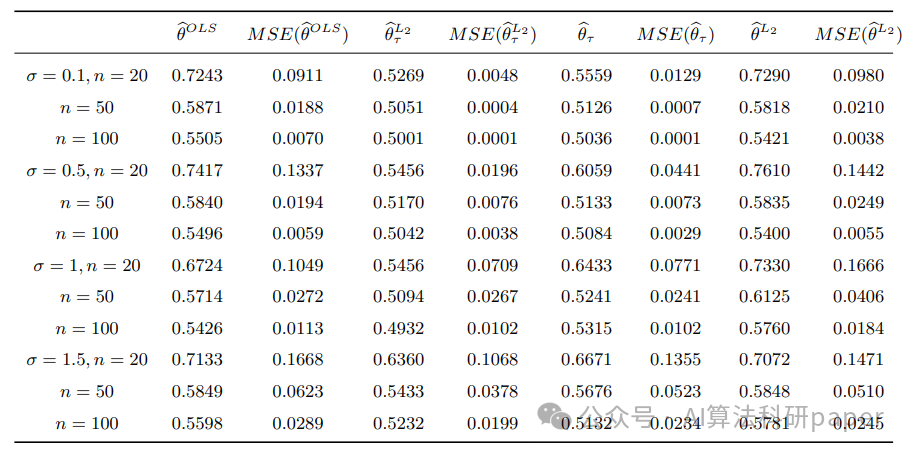
例文:Robust calibration of computer models based on Huber loss
方法:本文提出了一种基于Huber损失的鲁棒校准方法,该方法是对OLS估计量和L2估计量的扩展。通过数值分析,可以得出该方法是最健壮的,并且能够在不同情况下高效地处理异常值。
创新点:
- 提出了一种基于Huber loss的鲁棒校准程序,扩展了OLS估计量和L2估计量,提出了两种鲁棒估计器。
- 研究了所提出的估计器的非渐近和渐近性质,结果表明所提出的估计器具有鲁棒性和高效性。
- 进行了一些模拟实验,验证了所提出的估计器在不同模型设置下的有限样本性质。
分位数损失
回归分析中用来预测分位数的一种损失函数,它允许模型对不同分位数的预测误差赋予不同的权重,在风险管理和区间预测等领域非常有用。
例文:Dynamic Knowledge Enhanced Neural Fashion Trend Forecasting with Quantile Loss
方法:本文改进了KERN模型,以更准确地预测时尚趋势。首先,使用动态LSTM在编码器-解码器中使用长度不同的序列,将时间序列输入和相关序列信息结合在一个统一模型和多水平预测中。其次,使用Quantile损失函数,该函数专门用于时间序列,以使时尚趋势预测更好更准确。
创新点:
- 提出了Dynamic Knowledge Enhanced Recurrent Network模型(DKERN)以及使用Quantile loss函数的方法,对时序数据进行更准确的预测。
- 基于社交媒体图像和机器学习的大数据分析,提出了一种分析服装风格和趋势的方法,可以预测未来的流行风格。

扫码添加小享,回复“损失函数”
免费获取全部论文+开源代码











