mall学习教程官网:macrozheng.com
哈喽,大家好,MySQL作为广泛使用的开源关系型数据库管理系统,应该没有Java开发没使用过吧。
关于MySQL,我们大部分时间都在聊,如何提高查询效率,今天我们来聊聊如何提高MySQL的插入效率。
提高插入效率的方式
一般情况下,数据库是运行在专门的服务器上,提高插入效率最明显的当然是提高服务器配置啦。
比如,使用高性能的CPU和SSD磁盘,使用分布式系统架构,将写入压力分散到多个节点。这个方式的成本也是最高的,老板们当然不会使用这种方式了。
我们还可以从其他方面入手:
- 调整数据库配置:优化缓冲池大小、增大批量插入缓冲区等,通过调整MySQL数据库参数的方式。
- 选择使用
MyISAM存储引擎,因为其简单的表锁机制和无事务开销而在插入速度上表现更优。
考虑到实际的应用场景,我们最可能操作的就是使用第3种实现方式,通过批量插入的方式来提高效率。
探索批量插入
常用的批量插入的方式有2种:
- 拼接SQL,使用
insert into xxx (...) values (...),(...),(...) - 利用事务,将批量插入操作封装在单个事务中,可以减少事务开销并提高并发性能。
- 在mybatisPlus,以及mybatis-flex中,saveBatch 就是使用的这种方式
接下来我们来测试一下这几个方法。
这或许是一个对你有用的开源项目,mall项目是一套基于 SpringBoot3 + JDK 17 + Vue 实现的电商系统(Github标星60K),采用Docker容器化部署,后端支持多模块和微服务架构。包括前台商城项目和后台管理系统,能支持完整的订单流程!涵盖商品、订单、购物车、权限、优惠券、会员、支付等功能!
- Boot项目:https://github.com/macrozheng/mall
- Cloud项目:https://github.com/macrozheng/mall-swarm
- 视频教程:https://www.macrozheng.com/video/
项目演示: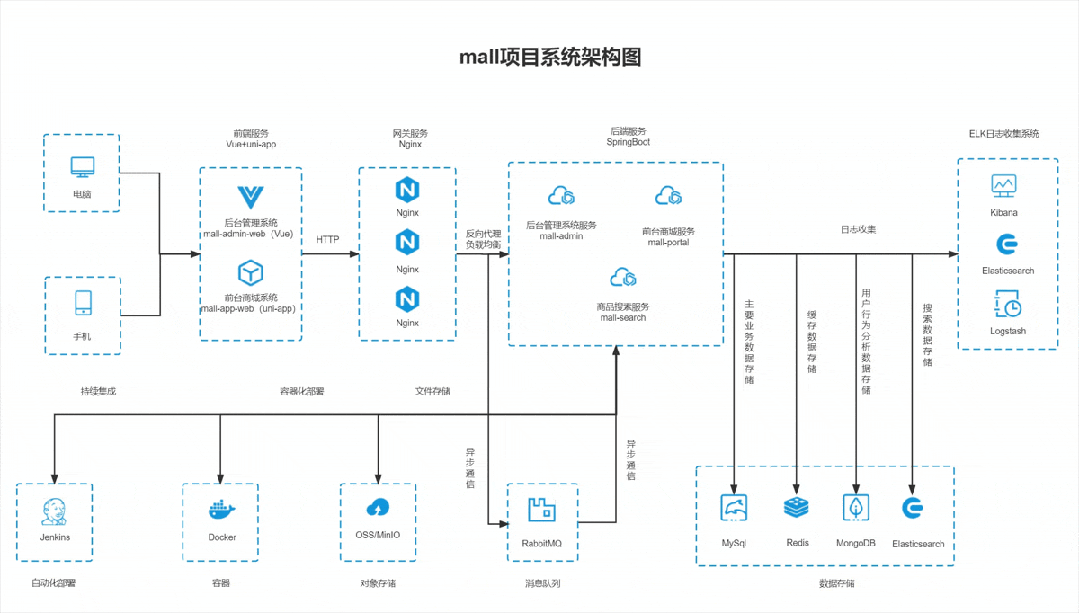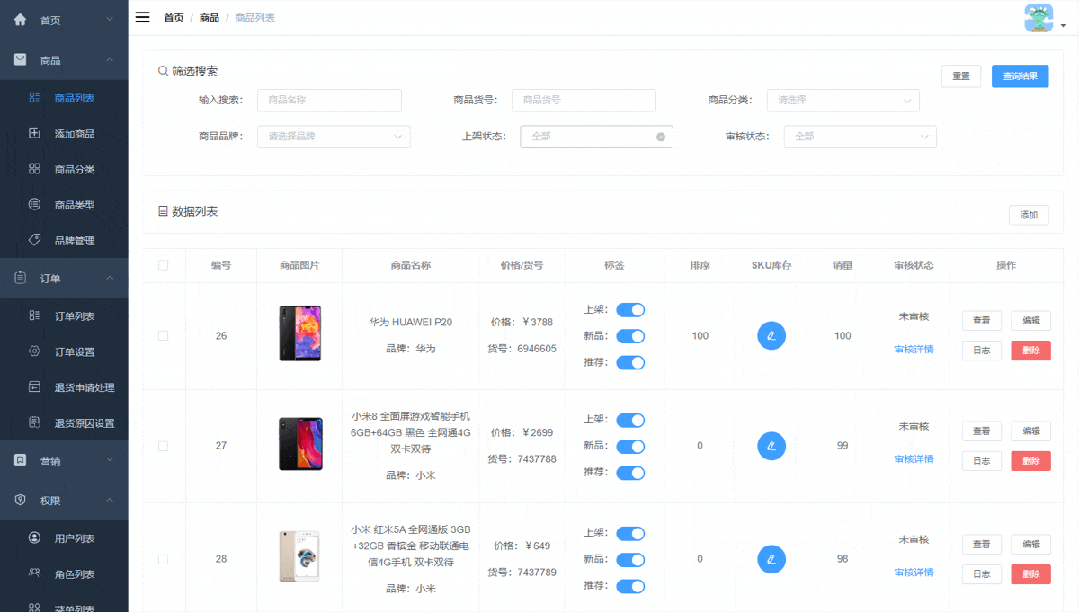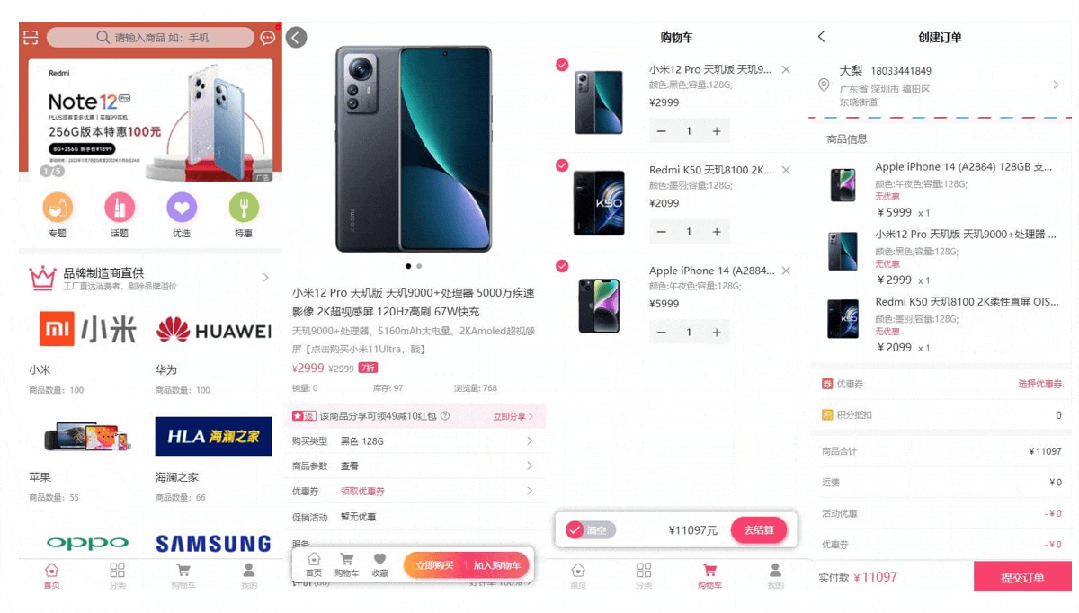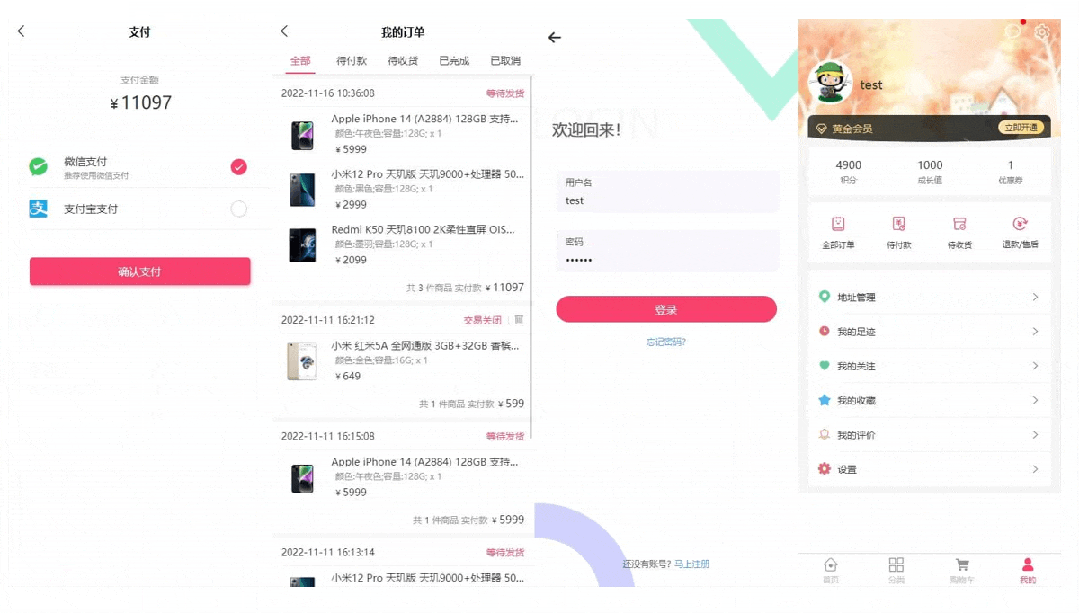
测试代码
测试的SQL
CREATE TABLE `orders`
(
`order_id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '订单ID(主键)',
`customer_id` BIGINT NOT NULL COMMENT '客户ID(关联customer表)',
`order_status` tinyint(4) NOT NULL DEFAULT 1 COMMENT '订单状态 1-待支付 2-已支付 3-待发货 4-已发货 5-已完成 6-已取消',
`payment_method` tinyint
(4) NULL DEFAULT null COMMENT '支付方式; 1-现金 2-支付宝 3-微信 4-银行卡',
`total_amount` DECIMAL(10, 2) NOT NULL COMMENT '订单总金额',
`shipping_fee` DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '运费',
`coupon_discount` DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '优惠券减免金额',
`order_date` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '下单日期',
`payment_time` DATETIME DEFAULT NULL COMMENT '支付时间',
`shipping_address` VARCHAR(255) NULL COMMENT '收货地址',
`receiver_name` VARCHAR(50) NULL COMMENT '收货人姓名',
`receiver_phone` VARCHAR(20) NULL COMMENT '收货人电话',
PRIMARY KEY (`order_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4 COMMENT ='订单信息表';
一、使用 batchXml
insert into orders (order_id, customer_id, order_status, payment_method, order_date, total_amount, shipping_fee, coupon_discount)
values
"orders" item="item" separator=",">
(#{item.orderId}, #{item.customerId}, #{item.orderStatus}, #{item.paymentMethod}, #{item.orderDate}, #{item.totalAmount}, #{item.shippingFee}, #{item.couponDiscount})
二、使用mybatis-flex提供的saveBatch
ordersService.saveBatch(list);
三、手动控制事务的提交,saveBatchSession
public void saveBatchSession(List orders) {
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
OrdersMapper mapper = session.getMapper(OrdersMapper.class);
for (int i = 0,length = orders.size(); i mapper.insert(orders.get(i));
}
session.commit();
session.clearCache();
session.close();
}
启动代码
@Test
public void generatorTestData() {
genOrders(0L, 100000L);
}
private void genOrders(long start, long end) {
List list = new ArrayList<>();
long s = System.currentTimeMillis();
for (long i = start + 1; i <= end; i++) {
if ((i - start) % 1000 == 0) {
ordersService.saveBatchSession(list);
// ordersService.saveBatchXml(list);
// ordersService.saveBatch(list);
list.clear();
itemAll.clear();
System.out.println("生成数据:" + (i - start) + "条,耗时:" + (System.currentTimeMillis() - s) + "ms");
s = System.currentTimeMillis();
continue;
}
// 构建所有属性
list.add(Orders.builder() ... .build());
}
ordersService.saveBatch(list);
}
测试结果
使用了3种方式进行测试
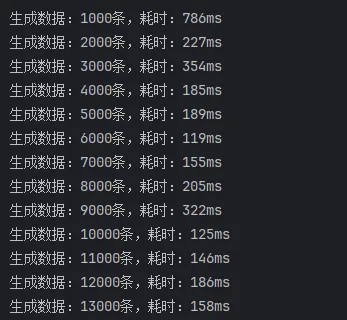
未开启批处理,batchXml
未开启批处理,mybatis-flex提供的saveBatch
未开启批处理,saveBatchSession
从这里的结果可以看出,使用 batchXml 的效率是最高的,远远超越其他方式。但是仔细一想,这些数据应该很不正常,插入1000条数据,竟然需要4秒左右,和单条插入1000次的时间几乎没有区别。
开启批处理
经过一番查询资料,并检查配置,发现果然另有玄机,连接数据库的时候没有开启批处理
开启方式:在spring的配置文件中,连接数据源时,url需要增加 allowPublicKeyRetrieval=true
然后重新测试一遍。
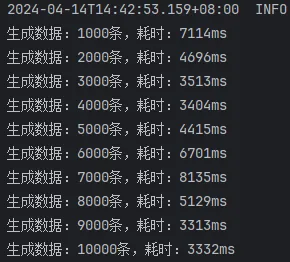
开启批处理,saveBatchXml
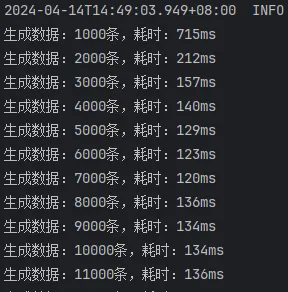
开启批处理,mybatis-flex提供的saveBatch
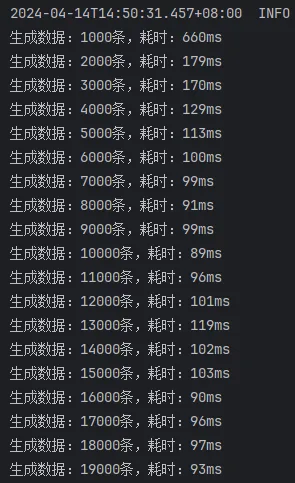
开启批处理,saveBatchSession
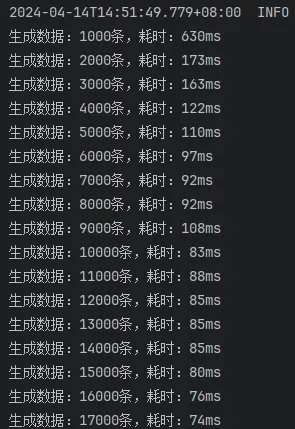
这次的结果就比较正常了,可以看出来:
mybatis-flex提供的saveBatch 因为有些额外的操作,多消耗了10ms左右的时间saveBatchXml 相较于另外两种方式,慢了30ms~40ms。
接下来,把每批次的处理数据由1000次增加到10000次,再次进行测试。
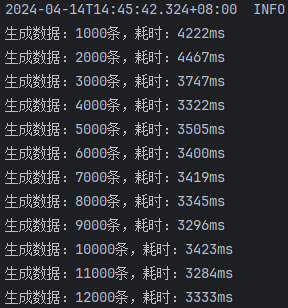
开启批处理,saveBatchXml,10000条一批次
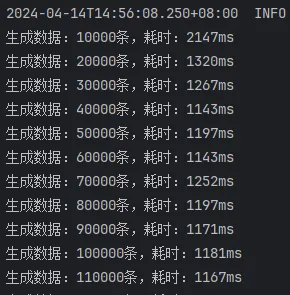
开启批处理,saveBatchSession,10000条一批次
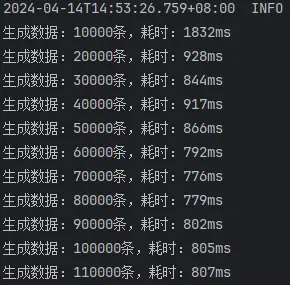
开启批处理,mybatis-flex提供的saveBatch,10000条一批次
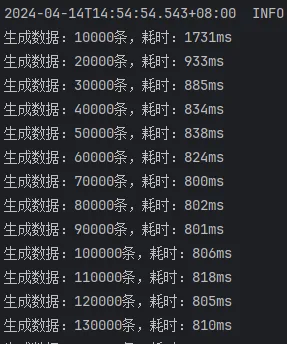
由此结果可以看出来:
saveBatchSession和mybatis-flex提供的saveBatch 耗时基本一致saveBatchXml就明显的慢一些,按照效率差算,差了将近50%的效率
总结
综上,提高MySQL插入效率主要可通过调整数据库配置、选择适合的存储引擎以及运用批量插入策略等方式实现。在实际应用中,尤其是在使用ORM框架进行数据操作时,应合理选择并充分利用批量插入功能,以最大程度提升插入效率。
省流
- 连接数据时,数据源配置文件url加上
allowPublicKeyRetrieval=true - 数据量很大时,使用mybatisPlus或MybatisFlex提供的
saveBatch即可。
Github上标星60K的电商实战项目mall,全套 视频教程(2023最新版) 已更新完毕!全套教程约40小时,共113期,通过这套教程你可以拥有一个涵盖主流Java技术栈的完整项目经验,同时提高自己独立开发一个项目的能力,下面是项目的整体架构图,感兴趣的小伙伴可以点击链接 mall视频教程 加入学习。
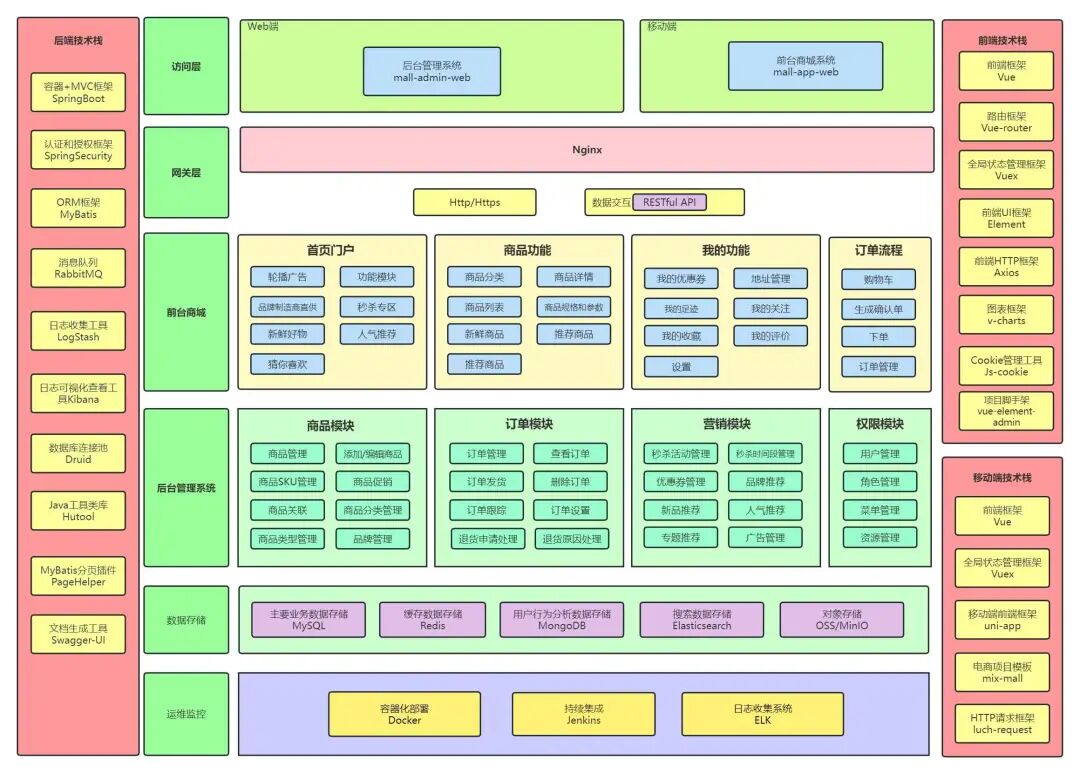
整套 视频教程 的内容还是非常完善的,涵盖了mall项目最佳学习路线、整体框架搭建、业务与技术实现全方位解析、线上Docker环境部署、微服务项目学习等内容,你也可以点击链接 mall视频教程 了解更多内容。
推荐阅读











