

导读 随着 ChatGPT 的热潮,小布助手也借鉴其思想,在 AIGC 方面进行了一些探索。本文将分享小布在 AIGC 画图上的进展和 AIGC 的 OPEN 问题。希望通过本次分享,为读者带来一些经验和灵感。
1. AIGC 定义及其种类
2. 小布在 AIGC 画图上的进展
3. AIGC 的 OPEN 问题
分享嘉宾|郑志彤(Liam) OPPO 数智系统多模态学习负责人
编辑整理|华永奎
内容校对|李瑶
出品社区|DataFun
01
1. AIGC 的定义
AIGC,即 Artificial Intelligence Generated Content,是一种利用人工智能技术生成内容的新型形式。AIGC 相比于 UGC(User
Generated Content)和 PGC(Professional
Generated Content)具有如下优势:比 PGC 效率高,比 UGC 质量稳定,并且节省成本、可拓展性强。2. AIGC 的关键指标
- Performance(性能):FID(图片感知距离)、Perplexity(困惑度)、FOV(视频感知距离),Diffusion model=GAN>VAE。
- Diversity(多样性):生成样本的分布差异距离的方差,diffusionmodel=VAE>GAN。
- Novelty(新颖性):生成样本和训练集数据最小分布距离最大化。
前两类都有很多很好的指标来衡量,但新颖性方面目前还没有特别好的指标,主要是主观评价。在 Perplexity 方面,在画图上,扩散模型和 GAN 的指标差不多,相比 VAE 要更好。在多样性上,扩散模型与 VAE 相当,但是比 GAN 要好,所以现在画图上面大家通常都会使用扩散模型。扩散模型也会用在自然语言的大语言模型上,在一些小的领域中表现效果不错。3. AIGC 的种类-GFlowNet
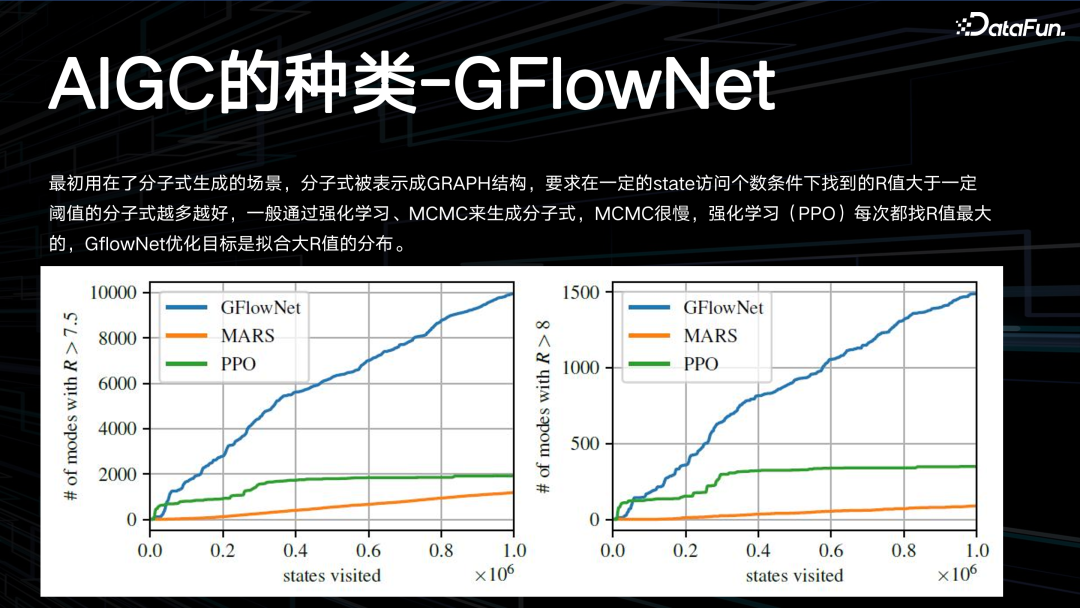
GFlowNet 最初被用在分子式生成的场景,分子式被表示成 GRAPH 结构,要求在一定的 state 访问个数条件下找到的 R 值大于一定阈值的分子式越多越好,一般通过强化学习、MCMC 来生成分子式。MCMC 很慢,强化学习(PPO)每次都找 R 值最大的,GFlowNet 的优化目标是拟合大 R 值的分布。4. AIGC 的种类-扩散模型
扩散模型的基本思想是通过一个可逆的过程,将“结构化数据”(如图片)逐步转化为无结构的噪声数据,然后再逆向这个过程,从噪声中恢复出原始数据或生成新的数据实例。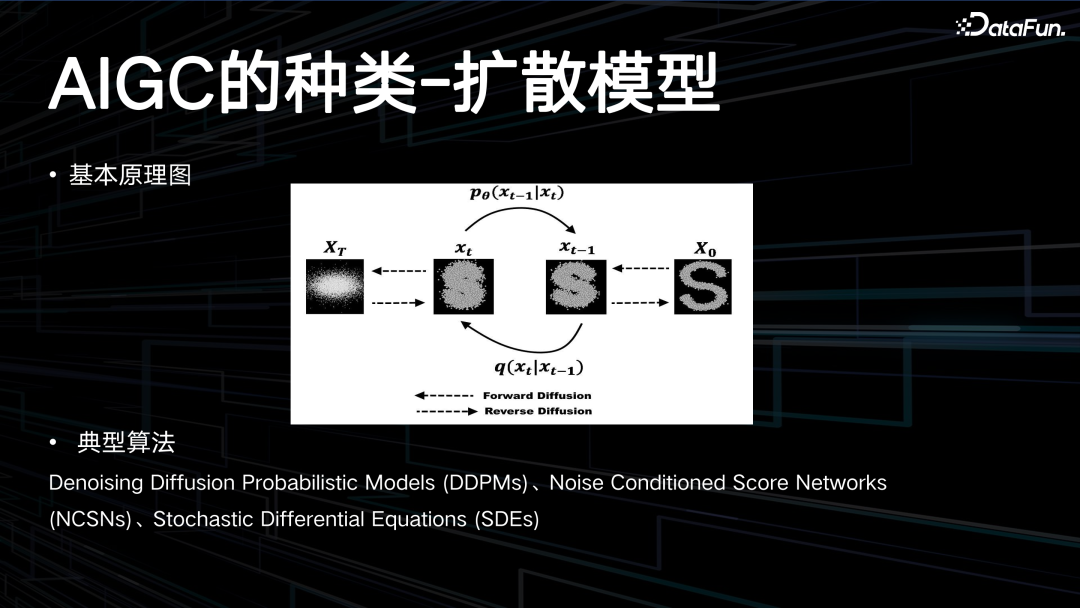
上图中展示了扩散模型的基本原理,即热扩散的一个逆过程。典型算法包括:Denoising
Diffusion Probabilistic Models (DDPMs)、Noise
Conditioned Score Networks(NCSNs)、Stochastic
Differential Equations (SDEs)。5. AIGC 的种类-生成式对抗网络
生成式对抗网络(GAN)由两个核心部分组成:生成器(Generator)和判别器(Discriminator),它们共同工作以达到特定的目标。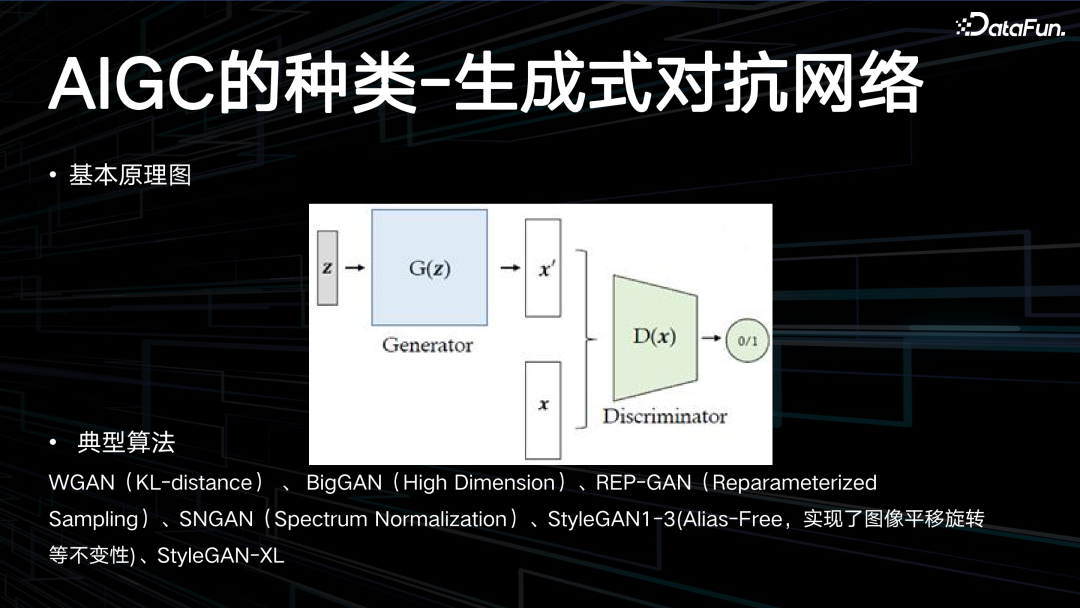
基本原理图如上所示,生成器负责从一定的随机分布(如正态分布)中抽取随机噪声,并通过一系列的神经网络层将其映射到数据空间。其目标是生成与真实数据分布非常相似的样本,从而迷惑判别器。判别器则尝试区分由生成器生成的样本和真实的样本。判别器是一个二元分类器,其输入可以是真实数据样本或生成器生成的样本,输出是一个标量,表示样本是真实的概率。典型算法包括:WGAN(KL-distance)、BigGAN(High
Dimension)、REP-GAN(ReparameterizedSampling)、SNGAN(Spectrum Normalization)、StyleGAN1-3(Alias-Free,实现了图像平移旋转等不变性)、StyleGAN-XL。6. AIGC 的种类-变分自编码
变分自编码 Variational AutoEncoder,简称 VAE,是包含隐变量的一种模型。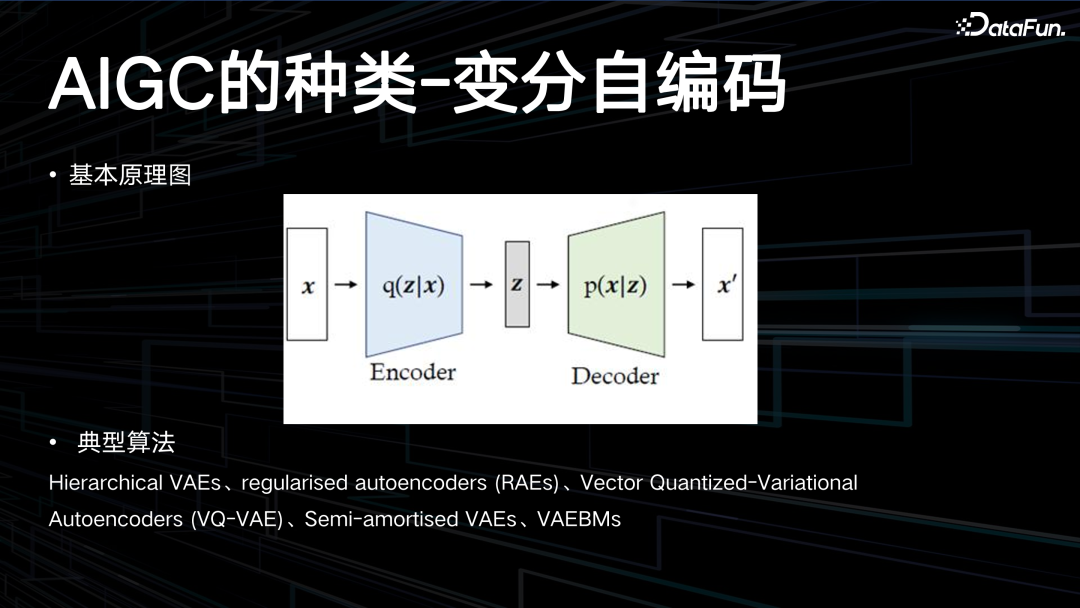
VAE 主要用在一些隐函数,加速推理的过程中,比如 stable diffusion,其本质上就是 VAE 加上扩散模型才能够实现秒级推理。变分自编码器与对抗生成网络类似,均是为了解决数据生成问题而生的。在自编码器结构中,通常需要一个输入数据,而且所生成的数据与输入数据是相同的。但是通常希望生成的数据具有一定程度的不同,这需要输入随机向量并且模型能够学习生成图像的风格化特点,因此在后续研究中以随机化向量作为输入生成特定样本的对抗生成网络结构便产生了。变分自编码器同样以特定分布的随机样本作为输入,并且可以生成相应的图像,从此方面来看其与对抗生成网络目标是相似的。但是变分自编码器不需要判别器,而是使用编码器来估计特定分布。总体结构来看与自编码器结构类似,但是中间传递向量为特定分布的随机向量,这里需要特别区分:编码器、解码器、生成器和判别器。典型算法包括:Hierarchical
VAEs、regularised autoencoders (RAEs)、Vector Quantized-Variational、Autoencoders
(VQ-VAE)、Semi-amortised VAEs、VAEBMs。7. AIGC 的种类-能量模型
能量模型,早期有 Boltzmann machine、RBM。现在常见的是在多模态预训练当中用对比学习的方法来提高高维数据的采样效率。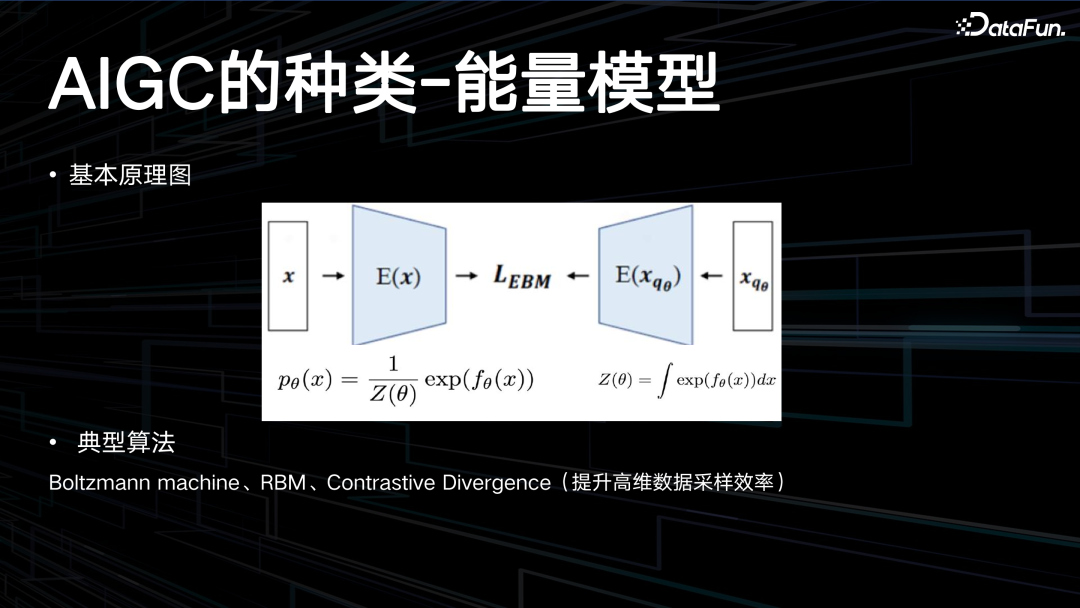
基于能量的学习为许多概率和非概率的学习方法提供了一个统一的框架,特别是图模型和其他结构化模型的非概率训练。基于能量的学习可以被看作是预测、分类或决策任务的概率估计的替代方法。由于不需要适当的归一化,基于能量的方法避免了概率模型中与估计归一化常数相关的问题。此外,由于没有标准化条件,在学习机器的设计中允许了更多的灵活性。大多数概率模型都可以看作是特殊类型的基于能量的模型,其中能量函数满足一定的归一化条件,损失函数通过学习优化,具有特定的形式。Boltzmann machine、RBM、Contrastive Divergence(提升高维数据采样效率)。8. AIGC 的种类-自回归模型
自回归模型是目前非常火热的一类模型,比如 ChatGPT,以及图像的 PixelRNN、Gated PixelCNN 等都属于自回归模型。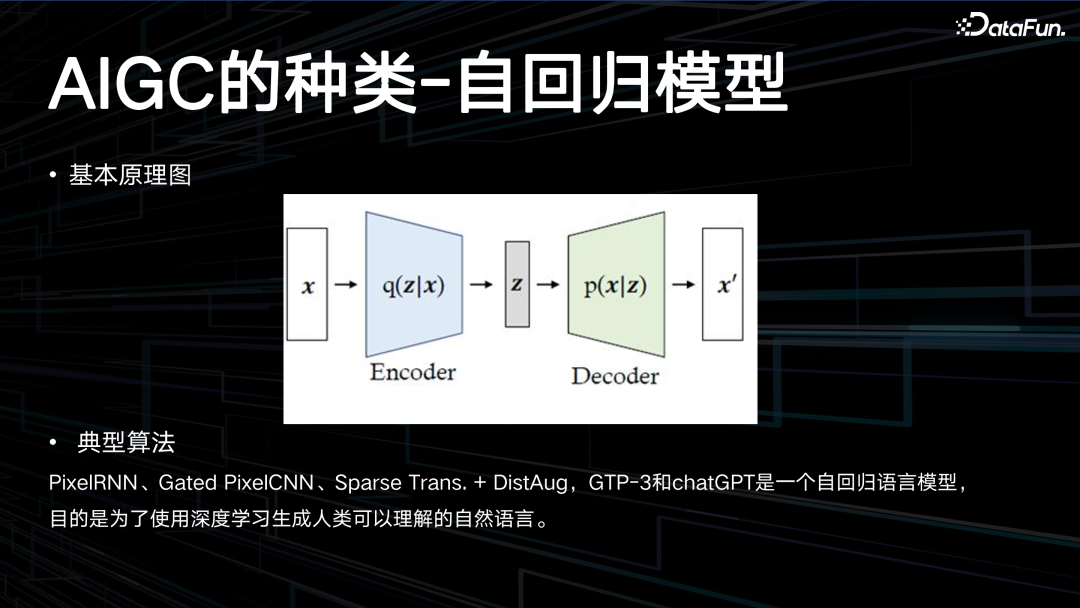
自回归模型 (Autoregressive Models) 是一类机器学习 (ML) 模型,它通过对序列中先前的输入进行测量来自动预测序列中的下一个组件。自回归是时间序列分析中使用的一种统计技术,它假设时间序列的当前值是其过去值的函数。自回归模型使用类似的数学技术来确定序列中元素之间的概率相关性。然后,使用获得的知识来猜测未知序列中的下一个元素。PixelRNN、Gated PixelCNN、Sparse
Trans. + DistAug,GTP-3 和 ChatGPT是一个自回归语言模型,目的是为了使用深度学习生成人类可以理解的自然语言。9. AIGC 的种类-标准化流
最后一类是标准化流,GLOW 残差模型,用一系列函数去推到 z,再用逆函数返回。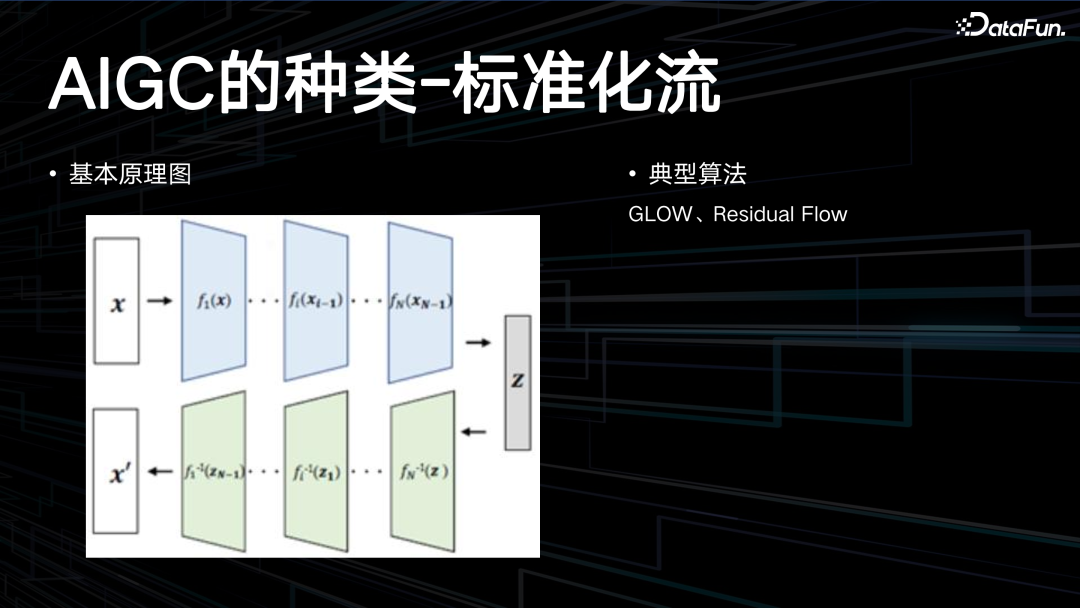
GLOW 模型的工作原理基于可逆生成模型的概念,它通过精确的潜在变量推断和对数似然评估来生成数据。具体如下:潜在变量推断:与变分自编码器(VAE)或生成对抗网络(GAN)不同,GLOW 能够实现潜在变量的精确推理,而不仅仅是近似值。这意味着 GLOW 可以直接在潜在空间中表征数据点,而不是依赖于近似方法。对数似然优化:GLOW 模型可以优化数据的精确对数似然,而不是其下限。这使得模型能够更好地拟合真实数据的分布。高效的推理与合成:尽管自回归模型如 PixelCNN 也是可逆的,但它们在并行硬件上通常效率较低。GLOW 模型则能够在没有近似的情况下高效地进行推理和合成。内存利用:在可逆神经网络中,计算梯度需要一定量的内存,这与传统深度网络相比,可以减少内存的使用量。GLOW 模型通过其独特的可逆设计和 1x1 卷积结构,能够有效地进行图像生成和操作,同时提供了对潜在空间的直接访问和更高效的资源利用。这些特点使得GLOW 在生成模型领域具有显著的优势。典型算法:GLOW、Residual Flow,GLOW 是一个创新的生成模型,它利用可逆的 1x1 卷积和其他流模型技术来实现高效的数据处理和生成。Residual Flow 作为 GLOW 的一部分,帮助模型更深入地学习数据分布,从而产生高质量的合成结果。这些技术的应用不仅限于图像生成,还可以扩展到其他需要复杂数据建模的领域。02
小布在 AIGC 画图上的进展
1. AIGC 画图上线的各种场景展示

AIGC 画图主要是基于 stable confusion 这个路线。主要落在锁屏场景、主题商店场景,以及 APP 内小布空间壁纸场景。多模态的双塔模型用在云相册的搜索场景,在 coco_cn 上的指标达到了最优。壁纸生成在上线后获得了很好的效果,也卖出了一些很好的业绩。2. AIGC 画图的技术创新点

在 CV background 上做的一个创新点是在 VIP 模型上加入了卷积层,一个卷积层一个 VIP 的 block,宏观上交替叠加。在微观注意力上也进行了微调,目前还是一个生态的指标,只列出来它在 switch Transformer 上做了改造后能得到 82.7 的最小模型。在另外一个更好的架构上改造,能得到 84.2 的水平。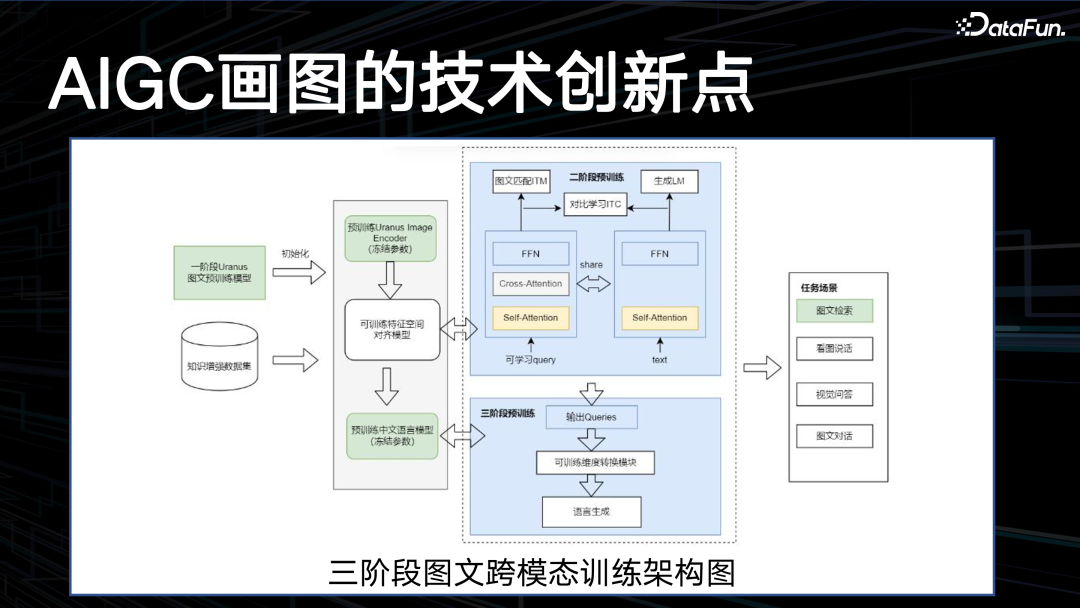
三阶段图文跨模态训练架构如上图所示,先做单模态的训练,再做两个模态的对齐,最后再做一个端到端任务训练,这是在半年前提出的,与 mini
GPT 的路线基本一致。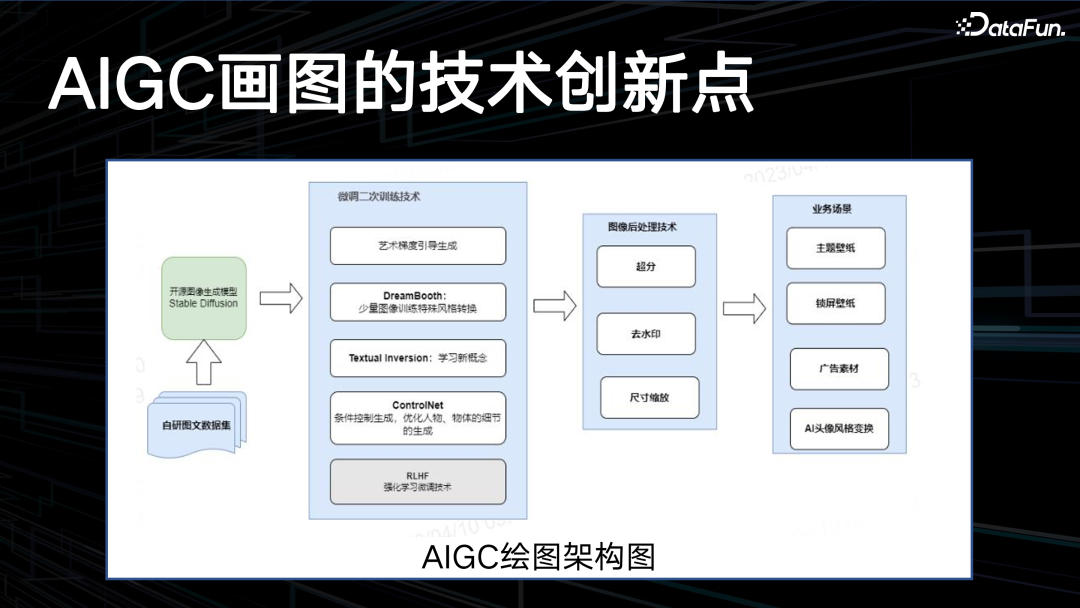
上图是 AIGC 绘图架构图,基于 stable
diffusion 做了大量微调的二次训练技术,比如艺术梯度的引导生成 DreamBooth,还有Textual Inversion、ControlNet。如果根据用户输入的 prompt 直接生成,结果可能并不理想,因此需要做 prompt 的改写。这就用到了 RLHF 技术,强化学习的反馈调试。主要优化两个指标,一个是美学指标,另一个是 CLIPScore,在一定范围之内不能改写用户输入的 prompt 的原始意图,同时不断地提升美学指标。目前该优化已经上线,用户随便说一个 prompt 就能够生成一个比较好看的图画,后面还有一些后处理的工作。AIGC 的 OPEN 问题
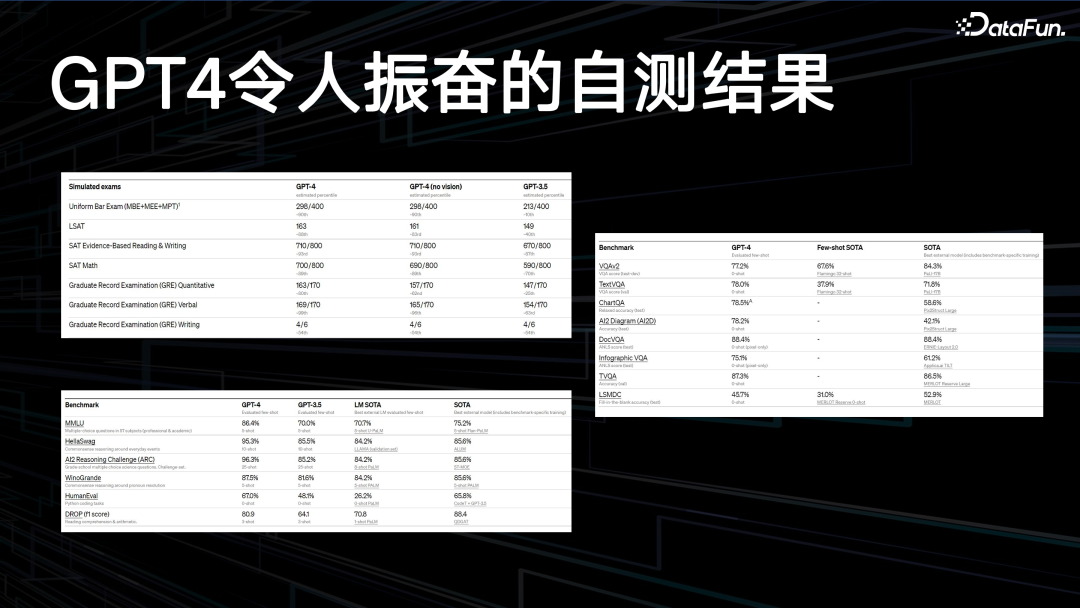
1. GPT4 令人振奋的自测结果
2. Yann LeCun 的观点

这是来自杨立昆的观点,我比较赞同。原模型只是预估了下一个 token 的概率,正确的 answer 是在他预测的一个大空间里面很小的一部分。他提出的 World Model 这一框架,也是我比较赞同的一个方向。后面有我提出的一些观点,相似但并不完全相同。3. 三方的测评
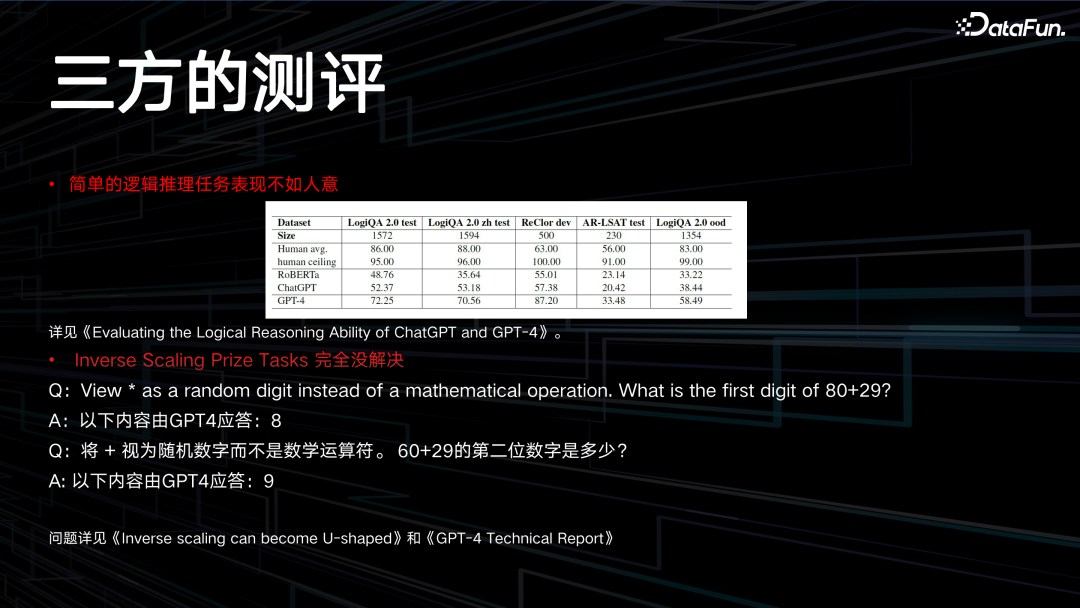
在对 GPT4 的一些第三方测评中,某些简单的逻辑推理任务表现并不理想。顶尖的模型在 LogiQA 数据集可以达到接近 100% 的表现,而 GPT4 目前还没有达到这个水平。说明 Transformer 不是万能的,大语言模型也有其能力达不到的领域。另外,Inverse Scaling Prize Tasks 也没有完全解决。在 GPT4 的技术报告中宣称通过一个 u 型反转已彻底解决了这一问题。但用一个特别简单的问题测试,如上图中所示,GPT4 会将运算符号认为是数字,给出错误的答案,连续追问,每次的答案是跟上下文相关的,但其实本身这个问题是跟上下文没有任何关系的。4. 我的观点
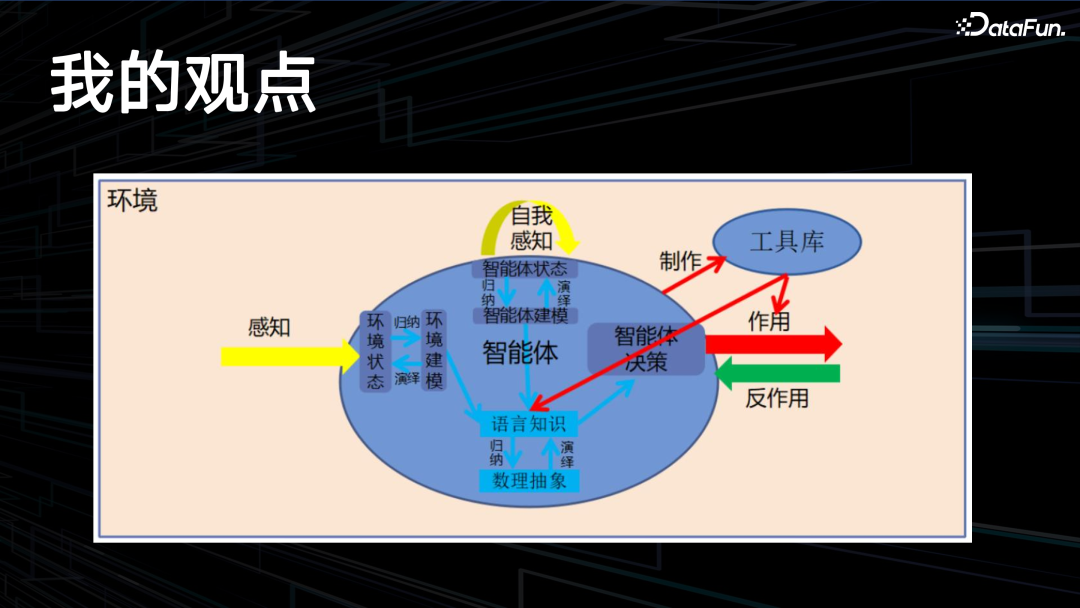
五年前我提出了一个 AIGC 的架构,这是单智能体的架构,首先感知环境。这是一个数据模型,然后会归纳到一个理论模型,对环境的建模,理论模型还会演绎到这个数据模型上。其最核心的是语言知识,语言知识会归纳抽象到数理抽象的模型,再演绎到语言知识。语言知识会控制智能体的决策,做一些对话,作用到这个环境当中。在这一过程中,可能会使用到各种工具库,也有可能去制作工具。智能体会有自我感知,会对自己的行为进行评价,对自己状态自我感知。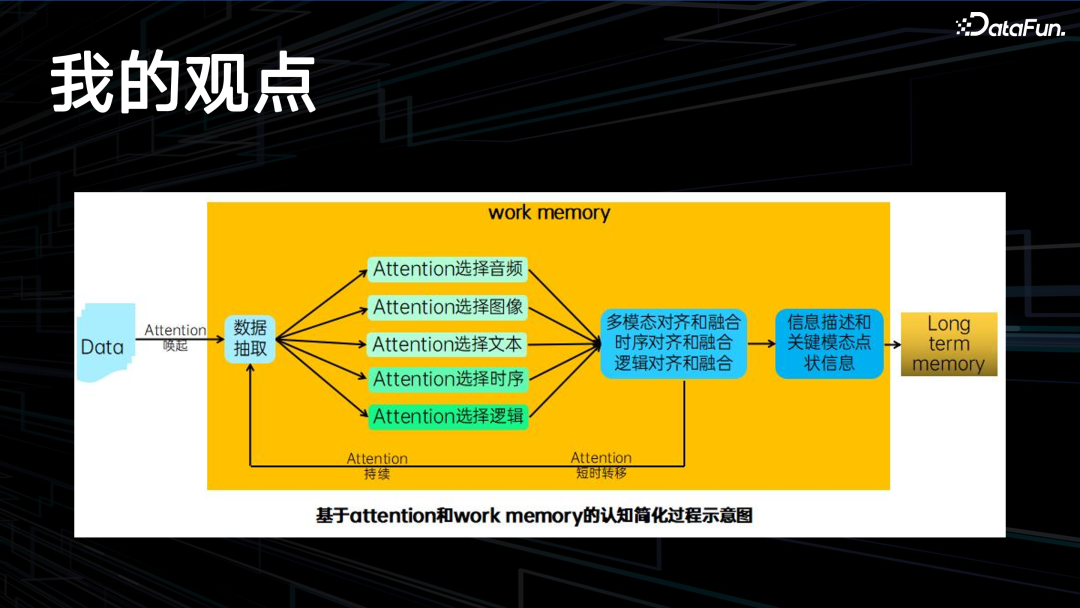
这是近期我画的一个图,基于认知心理学的短期 memory 和长期 memory 的过程。在短期 memory 部分,attention 有三个过程,与 Transformer 的 attention 不太一样,这里要有 attention 的唤起,中间有 attention 词序,还有 attention 的转词转移。智能体短时间内在做某个 task 会换到另外一个 task,然后还能换回来。其中包括多模态,比如音频、图像、文本,还有一些比较特殊的,如时序,它会感知到每个发生事件的前后时间关系,还有一些逻辑关系,它会做一些逻辑的对齐,时序的对齐,再做融合,最后做一些长期的抽象,存储到长期 memory 里面。在每次认知过程中,又会把这个长期 memory 的人生观、世界观抽出来去影响其再认知。下面介绍的是 Howard Gardner 8 种智商的理论。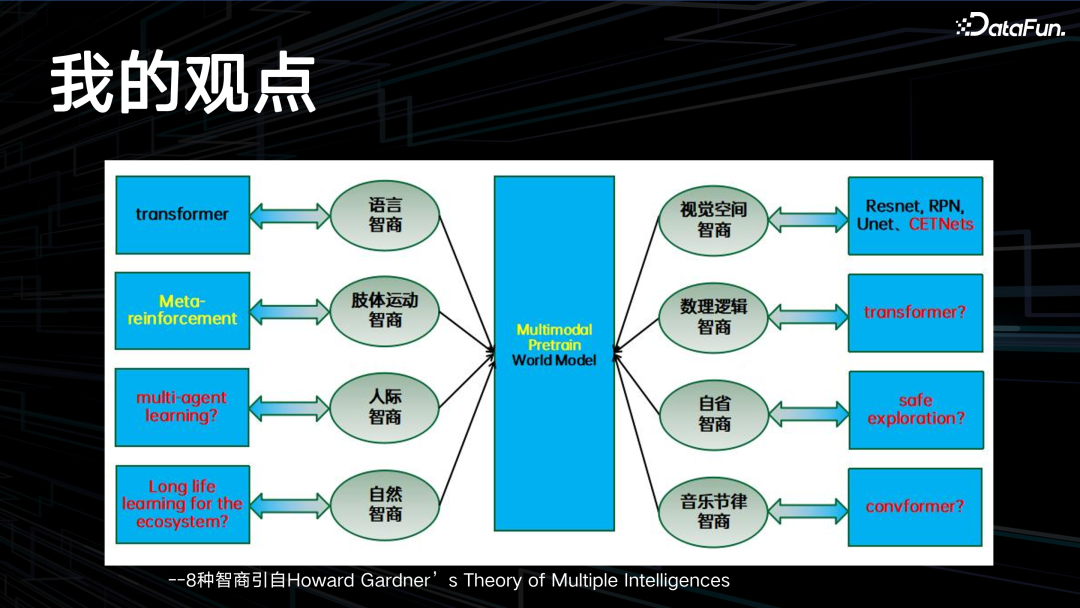
一般的 IQ 测试只涉及到三种智商,即语言智商、视觉空间智商和数理逻辑智商。其实另外还有五种智商,包括人际智商、自省智商,这两个属于情商的范畴,还有肢体运动智商、自然智商、音乐节律智商。目前 AI 领域都有对应的一些模型架构的尝试,但是红色字体部分还没有很完美的解决方案。中间是一个多模态的 Pretrain,还有 World Model。- 缺少归纳和演绎的联结主义实现,即缺少数据模型到理论模型的升华,也是当前机器学习模型存在
OOD 泛化问题的本质原因。
- 除语言智商和视觉空间智商外,其它六个智商都没有较好的人工神经网络表征和训练方法出来。
- 目前基于 transformer 的 AR-LLM,仅仅学习了语言的语法信息和浅层语义信息,需要和数理逻辑智商的优秀 AI 实现结合起来。
OPPO 高级算法架构师,现任数智系统机器学习 TMG 主任、小布智能中心多模态学习负责人,促进小布从语音助手进化成多模态助手,打造 AndesGPT 多模态能力,落地了多个小布 AIGC 场景,有小布绘画、锁屏壁纸生成、小布空间图片生成等。2020 年 8 月加入 OPPO,参加商业算法软件商店首页攻坚,贡献了千6AUC 提升和 2 点多 ARPU 值提升;随后调入数智系统机器学习部,负责了端云协同的 StarFire 项目;之后又调入小布智能中心,负责多模态学习,短时间搭建了虚拟人算法团队和 StarLite 项目团队,启动了多模态预训练和 AIGC 项目。在机器学习领域有十几年经验,对 CV、NLP、音频、推荐系统等算法有深刻认知,对 AI 工程化有实操经验,十分关注通用智能的发展,多模态技术是通用智能的关键一环。硕士毕业于清华大学,本科毕业于人民大学。







