又到了每月一次的 Python 学习时间
(虽然今天是本月最后一天)
本篇延续
极简 Python:10分钟会用 OpenAI / Kimi API
写给不会代码的你:20分钟上手 Python + AI
本篇共包含 10 段简单的 Python
涉及常用语法和常用库
(但毫无疑问删减来很多)
任何不懂的地方
可问 ChatGPT(上面连接里有写)
请一定先看之前的文章
请一定上手试试
以及,请用 Colab 练手
(Colab 使用方法参见上面链接)
注
如果某个地方以 “#” 开始
意思是:这是注释
一、数据类型
涉及 Python 中最常用的基本数据类型及其操作
包括数字、字符串和列表
a = 10b = 3result = a + b print(result)
s = "Hello, Python!"print(s.lower()) print(s.upper()) print(s.replace("Python", "World"))
lst = ["apple", "banana", "cherry"]print(lst[0]) lst.append("date") print(lst) lst.remove("banana") print(lst) print(len(lst))
二、条件判断和循环
我们将遍历一个列表,并检查每个字符串的长度
fruits = ["apple", "banana", "cherry", "date"]for fruit in fruits: if len(fruit) > 5: print(f"{fruit} 的长度大于 5") else: print(f"{fruit} 的长度不大于 5")
三、函数
定义一个简单的问候函数,并调用它
def greet(name): print(
f"Hello, {name}!")
greet("Alice") greet("Bob")
四、文件操作
进行简单的文件操作,包括写入和读取文件内容
with open("example.txt", "w") as file: file.write("Hello, file!\n") file.write("This is a second line.")
with open("example.txt", "r") as file: content = file.read() print(content)
五、对象
定义一个简单的类和对象,包括类的属性和方法
class Student: def __init__(self, name, age): self.name = name self.age = age
def greet(self): print(f"Hello, my name is {self.name} and I am {self.age} years old.")
student1 = Student("Alice", 20)student1.greet()
student2 = Student("Bob", 22)student2.greet()
六、异常处理
使用异常处理机制来处理可能发生的错误,例如文件未找到的情况
try: with open("non_existent_file.txt", "r") as file: content = file.read()except FileNotFoundError: print("文件未找到!")
try: result = 10 / 0except ZeroDivisionError: print("不能除以零!")
七、常用标准库
使用Python的标准库,例如datetime库来处理日期和时间
from datetime import datetime
now = datetime.now()print(now)
formatted_now = now.strftime("%Y-%m-%d %H:%M:%S")print(formatted_now)
date_str = "2023-05-31"parsed_date = datetime.strptime(date_str, "%Y-%m-%d")print(parsed_date)
八、网络请求
用 requests 库发送 HTTP 请求
再用 BeautifulSoup 进行页面抓取
简而言之:爬虫
import requestsfrom bs4 import BeautifulSoup
url = "https://news.ycombinator.com/"response = requests.get(url)
if response.status_code == 200: print("请求成功!") html_content = response.content
soup = BeautifulSoup(html_content, 'html.parser')
page_title = soup.title.get_text() print(f"网页标题: {page_title}")
titles = soup.find_all('a', class_='storylink')
for i, (title, subtext) in enumerate(zip(titles, subtexts), start=1): desc = subtext.get_text().strip() print(f"{i}. 标题: {title.get_text()}")else: print("请求失败!")
实际运行如下:

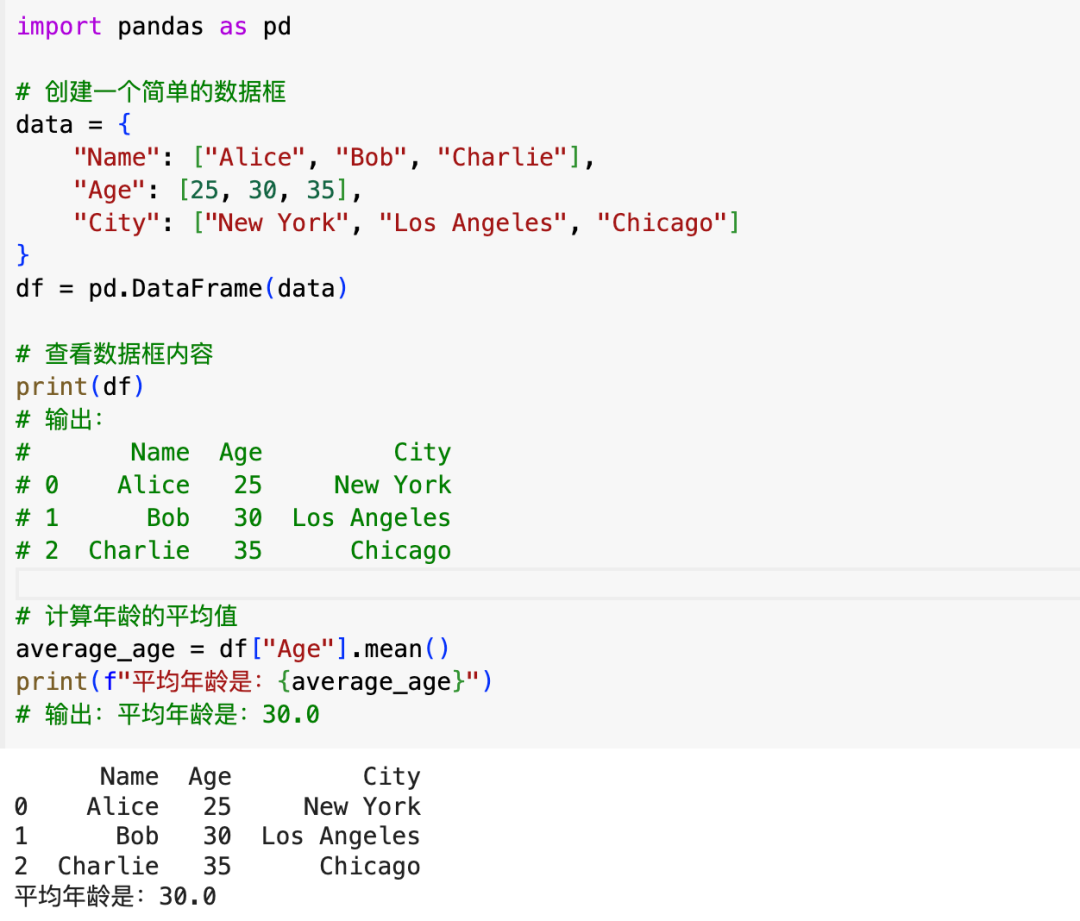
九、数据分析
使用pandas库进行简单的数据处理与分析
import pandas as pd
data = { "Name": ["Alice", "Bob", "Charlie"], "Age": [25, 30, 35], "City": ["New York", "Los Angeles", "Chicago"]}df = pd.DataFrame(data)
print(df)
average_age = df["Age"].mean()print(f"平均年龄是:{average_age}")
实际运行如下:
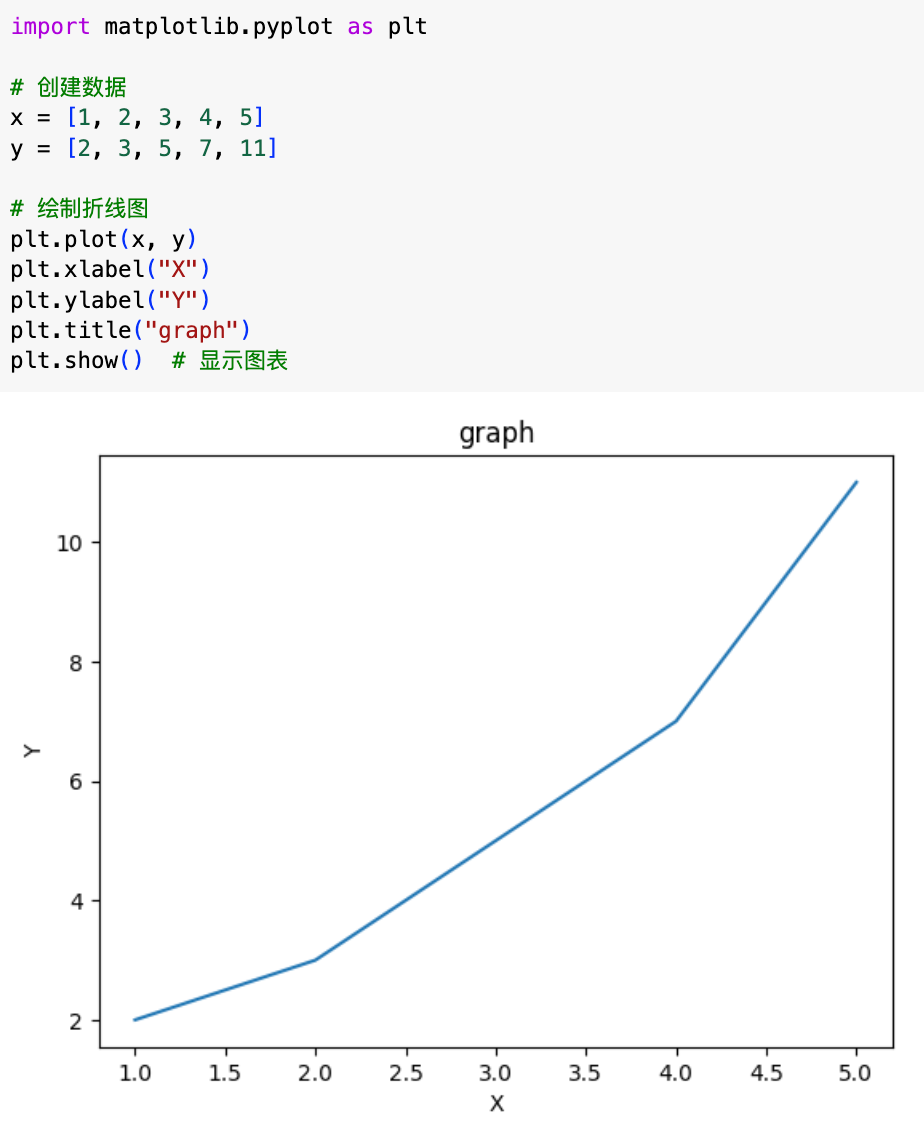
十、数据可视化
使用matplotlib库绘制图表,展示数据分析结果
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]y = [2, 3, 5, 7, 11]
plt.plot(x, y)plt.xlabel("X")plt.ylabel("Y")plt.title("graph")plt.show()
实际运行如下: