2022 年 12 月,帕洛阿尔托特斯拉总部......
在一次会议上,一位名叫 Dhaval Shroff 的自动驾驶工程师向埃隆·马斯克提出了一个新想法:
💡“它就像 Chat-GPT,但适用于汽车!!!” “我们不是根据规则来确定汽车的正确路径,而是使用神经网络来确定汽车的正确路径,该神经网络从数百万个人类所做的事情的训练示例中学习。”
埃隆·马斯克和整个 Autopilot 团队坚信这一点,于是赶紧将新算法应用到下一个 FSD 版本(从 FSD v11 到 FSD v12)。
这就是特斯拉端到端学习的开始......
在这篇文章中,我们将详细分析特斯拉计划如何从现有架构迁移到完整的端到端架构。为此,我将介绍 3 个关键点:
1. 2021 年的特斯拉:推出 HydraNets
2. 2022 年的特斯拉:增加占用网络
3.2023 年后的特斯拉:过渡到端到端学习
这 3 点很重要,特别是因为你会注意到他们实际上早就为端到端做好了准备。
那么让我们从 #1 开始:
2021 年的特斯拉:推出 HydraNets
特斯拉的自动驾驶系统最初依靠 Mobileye 系统作为其感知模块。很快,它就转向了定制系统,从图像光栅化到鸟瞰视图网络,并在某个时候引入了一种名为 HydraNet 的多任务学习算法。
HydraNet 的目标是让一个网络拥有多个头。因此,我们只需一个网络,而不是堆叠 20 多个网络,并且不会重复许多编码操作。
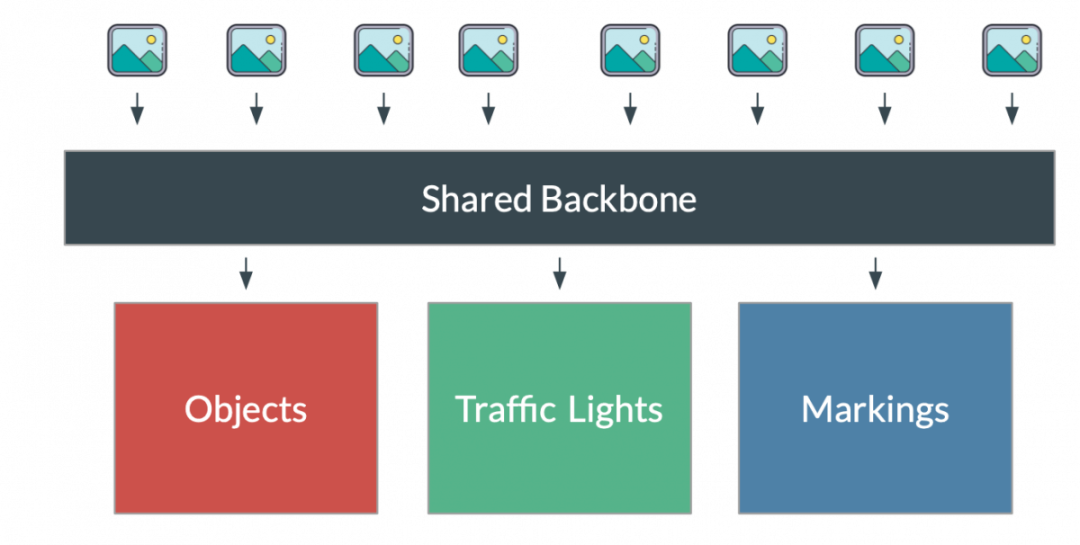
特斯拉的 HydraNet(来源)
该模型是特斯拉架构中的关键元素,因为它允许他们使用单个神经网络运行多个任务。
然而,值得提醒的是,这只是由多个块组成的更大模块化架构的一个组件(感知组件)。当他们解释它时,他们提到了两个主要块:
感知,用于通过 HydraNet 检测物体和环境
规划与控制,用于规划路线和驾驶
感知与 HydraNet
HydraNet 与我刚刚展示的类似。
那么让我快速进入下一部分:
规划与控制:特斯拉自动驾驶仪如何规划到达目的地的路线
在 2021 年人工智能日上,特斯拉介绍了 3 种规划系统,并展示了它们在自动停车示例中运行的示例:
1)传统 A* 算法— 被所有机器人工程师称为搜索中的“关键”算法。此示例显示,在找到正确路径之前,需要进行近 400,000 次“扩展”。
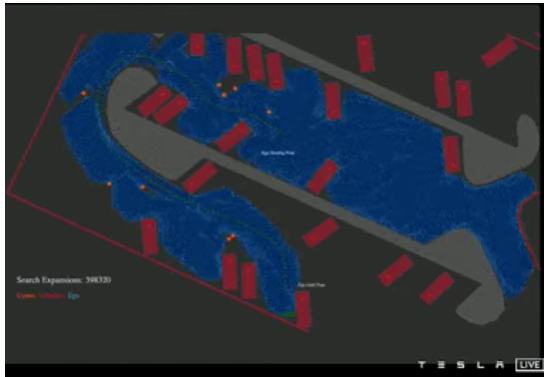
原始 A* 搜索算法的视频需要大约 44,000 个节点进行计算(来源:AI Day 2021 视频)
2) A* 算法,通过导航 路线增强— 这种方法是相同的,但我们提供的不是“启发式”,而是更多输入(地图?路线?目的地?)。这只会导致 22,000 次扩展。
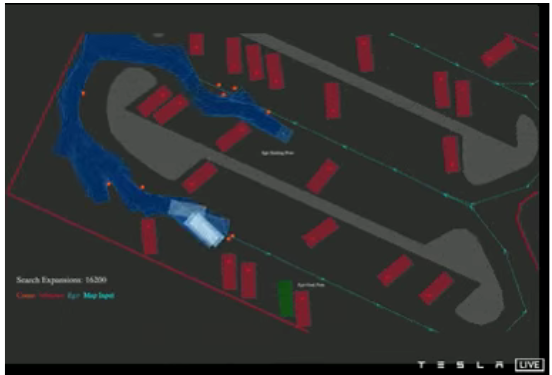
A* 算法的视频,增强了导航信息,仅需 22k 个节点(来源:AI Day 2021 视频)
3) 通过神经网络增强的蒙特卡洛树搜索算法—— 这种方法是特斯拉在 2021 年使用的方法。通过将神经网络与传统的树搜索相结合,它可以用少于 300 个节点达到目标。
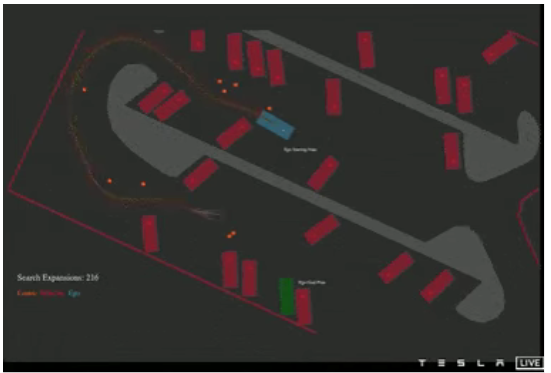
2021 年特斯拉规划算法的视频得益于神经网络 + 蒙特卡洛组合,速度超快(来源:AI Day 2021 视频)
最后一种方法是他们在规划中采用的方法。
2021 年特斯拉概况
让我们快速回顾一下 2021 年:
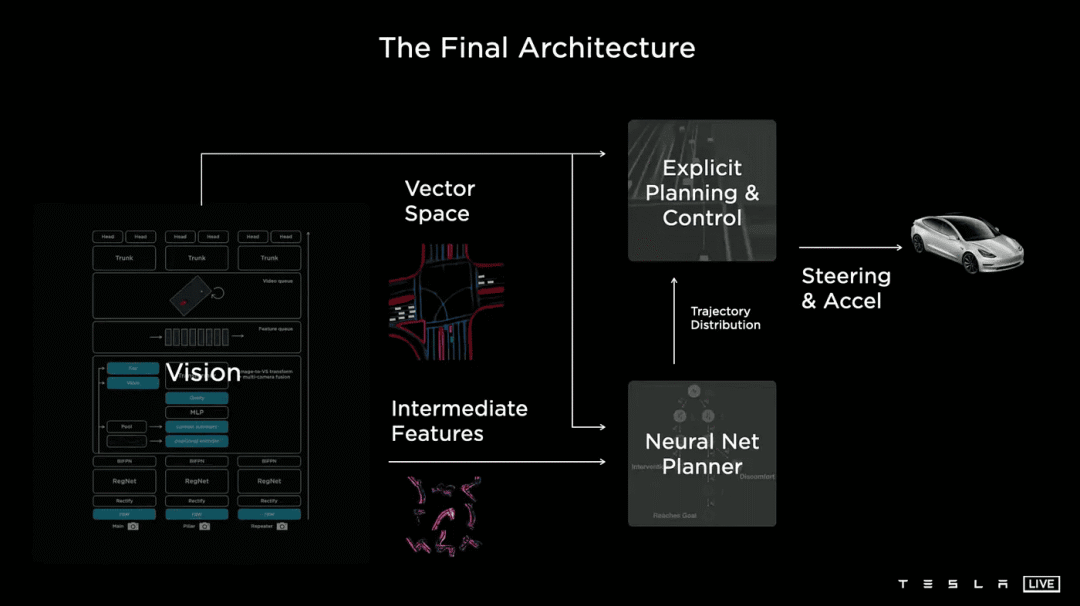
特斯拉 2021 年的架构(来源:AI Day 2021 视频)
我们有 2 个主要模块:HydraNet 执行视觉任务,蒙特卡洛结合神经网络执行规划任务。
现在让我们进入 2022 年,看看感知和规划是如何发展的……
2022 年特斯拉:引入占用网络
2022 年,特斯拉推出了一种名为“占用网络”的新算法。借助“占用网络”,他们不仅能够提高感知能力,还能大大改善规划能力。
当我第一次谈论这个想法时,很多人告诉我“所以他们不再使用 HydraNets 了!”。
是的,确实是!
特斯拉在 2022 年所做的就是在 Perception 中“添加”了一个占用块,因此他们将 Perception 模块分为了 2 个块:
让我们看看这两个:
占用网络
让我们从占用网络开始。
特斯拉创建一个将图像空间转换为体素的网络,然后为每个体素分配一个空闲/占用值。
这增强了感知模块,帮助他们找到更多相关特征。这对他们的堆栈来说是一个很大的改进,因为它使他们能够增加很好的上下文理解,尤其是在 3D 中。
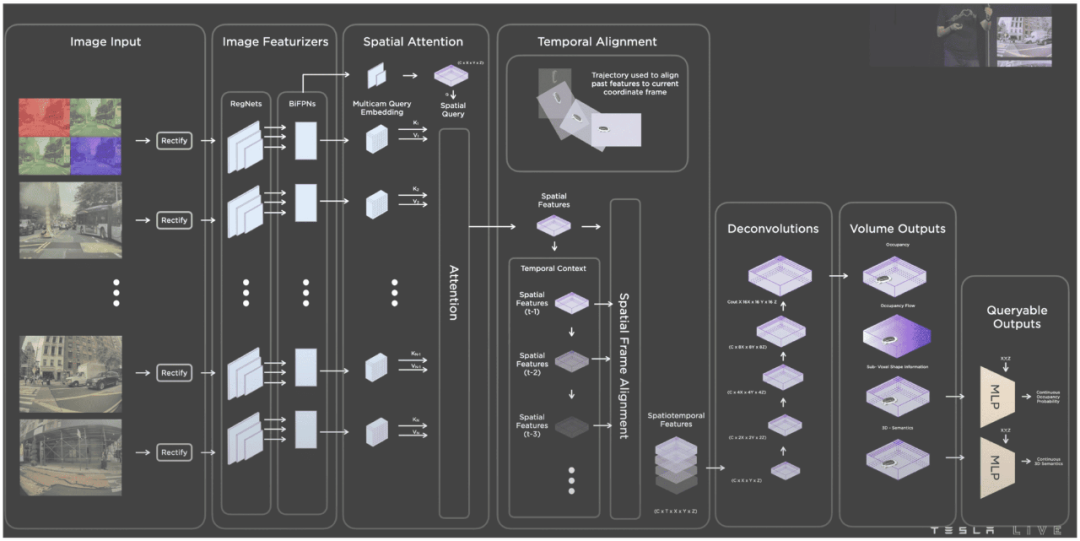
添加了占用网络(2022 年)(来源:AI Day 2022 视频)
这个占用网络正在预测“占用体积”和“占用流量”——这两个重要部分,可帮助我们了解 3D 空间中哪些是空闲的,哪些是占用的。
但它不是唯一用到的东西,它是一个附加部分,为了更好地理解 3D,还可以使用 HydraNet 检测物体和车道。
HydraNet 2.0:车道和物体
HydraNet 与去年的没有太大区别,只是它多了一个“头”,但那实际上不是头,而是一个完整的神经网络,用于执行车道线检测任务。
整体架构如下所示(红色部分):
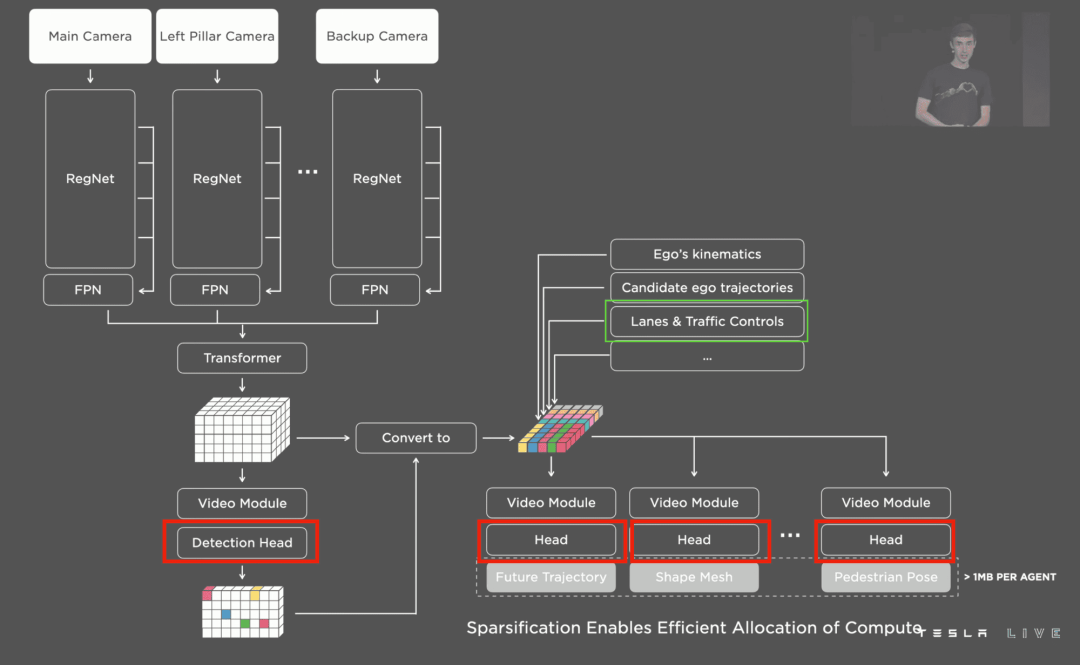
2022 年的 HydraNet(来源:AI Day 2022 视频)
现在,架构的一部分(绿色)实际上是堆叠在这里的另一个神经网络,用于查找车道线。从外观上看,它看起来像这样:
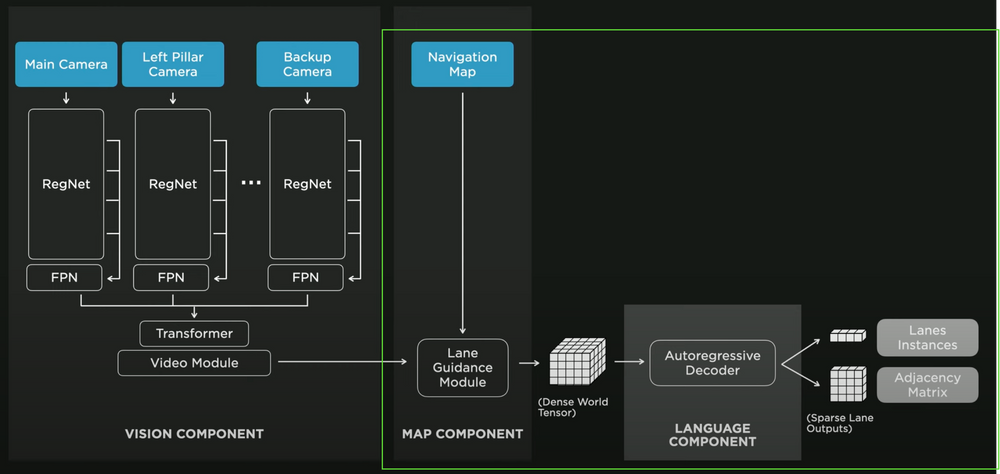
车道检测“头部”(来源:AI Day 2022 视频)
在本文中,我想保持“高水平”,因此我不会深入研究它们如何从自然语言处理中窃取并使用语义等来确定车道,但您是否看到左侧部分与上图相同?这都是 HydraNet,右侧部分只是车道线检测的附加部分。
因此,对于感知来说,我们有:
占用网络,进行 3D 理解
HydraNet ,用于理解车道和物体
现在我们来看看规划:
新的特斯拉规划器
最初的神经网络规划非常棒,但现在我们可以访问 3D 中的占用率,我们应该使用它!因此,新的规划模块将占用率以及车道集成到(仍然)由蒙特卡洛树搜索和神经网络组成的架构中。
为了理解这棵树的逻辑,让我们以特斯拉在 2022 年人工智能日上给出的例子为例:

交叉口示例(来源:AI Day 2022 视频)
在此示例中,车辆必须:
1.非法让行人过路
2.让右侧驶来的车辆先行
因此,它构建了一个树结构,在其中生成并准确评估这些选择。
 2022 年的蒙特卡洛树规划器
2022 年的蒙特卡洛树规划器
从上到下:
我们如何评估这些选择?我们对此有手动规则和标准。生成轨迹后,每个轨迹都会有一个成本函数,该函数取决于 4 个因素:碰撞概率、舒适度、干预可能性和人性化程度。
 特斯拉的轨迹评分和选择标准
特斯拉的轨迹评分和选择标准
因此,如果您生成了 20 条轨迹,则每条轨迹都有一个成本函数,最终您会选择成本最低的函数。
再次强调,这一切都是“手动”完成的。据我所知,我们没有使用机器学习模型或深度神经网络,也没有使用训练数据——我们只是编写规则和算法。
让我们快速看一下我们所拥有的内容:
2022 年特斯拉:摘要
 特斯拉 FSD 将于 2022 年推出
特斯拉 FSD 将于 2022 年推出
我们有两个关键组成部分:
通过占用网络和车道检测增强了感知能力
规划器已被重写以使用占用网络输出
所以你可以看到输入数据(8 张图像)如何从感知流到规划,再流到输出。
现在,让我们看看他们想在 2023/2024 年做些什么:
过渡到 FSD v12 和端到端架构
端到端深度学习是什么意思?它需要对这个架构进行哪些“改变”?
如果我们谷歌搜索“端到端学习定义”,我们得到的结果是:
“端到端学习是指通过将基于梯度的学习应用于整个系统来训练可能复杂的学习系统。端到端学习系统经过专门设计,因此所有模块都是可区分的。”
简而言之,特斯拉有两件事要做:
1. 每个区块都有一个深度神经网络
2. 端到端模型,将这些神经网络组装在一起
目前,对于特斯拉来说:
感知使用深度学习✅
规划使用深度学习模型 + 传统树搜索的组合❌
他们需要将规划部分转变为深度学习部分。他们必须摆脱轨迹评分、手动规则、“如果您在停车标志处,请等待 3 秒”的代码以及“如果您看到红灯,请减速并刹车”的代码。所有这些都消失了!
因此,它看起来将是这样的:
 第一部分将要求规划系统充分利用深度学习
第一部分将要求规划系统充分利用深度学习
然而,这还不够,因为即使我们有 2 个深度学习块,但仍然需要端到端操作。所以有完整的深度学习,也有端到端。
在非端到端但完整的深度学习设置中:
1. 您在数据集上独立训练 Block A 来识别物体。
2. 然后,使用 Block A 的输出独立训练 Block B,以预测轨迹。
重点:在训练过程中,Block A 对 Block B 的目标一无所知。Block B 也不知道 Block A 的目标。它们是两个独立训练的独立实体,它们的训练损失不会进行联合优化。
现在考虑具有相同块 A 和 B 的端到端设置。
1. 您有一个单一的目标函数,它既考虑识别图像中的对象(块 A 的任务),又考虑预测轨迹(块 B 的任务)。
2. 您可以同时训练 Block A 和 Block B,以尽量减少这种联合损失。
要点:信息(以及反向传播期间的梯度)从最终输出一直流回到初始输入。模块 A 的学习直接受到模块 B 执行任务情况的影响,反之亦然。它们共同优化以实现单一、统一的目标。
 从完全深度学习到端到端的转变
从完全深度学习到端到端的转变
因此,主要区别不在于模块本身,而在于如何训练和优化它们。在端到端系统中,模块会联合优化以实现单一的总体目标。在非端到端系统中,每个模块都会单独优化,而不考虑更大系统的目标。
等等:现在它不更像一个黑匣子了吗?我们如何验证它并将其投入使用?!
嘿,我只是这里的信使。
但是,是的,它看起来更像一个黑匣子,但你也可以看到我们仍在使用占用网络和 Hydranet,所有这些,我们只是将元素组装在一起。所以,它是一个黑匣子,但我们也可以在任何时间点可视化占用的输出、可视化物体检测的输出、可视化规划的输出等……
我们也可以分别训练这些元素,然后以端到端的方式进行微调。所以,这是一个黑匣子,但不一定比它原来的黑匣子更复杂。只有一个额外的复杂程度:整体训练。
对于验证以及任何类似问题,我并不是合适的人选。特斯拉并不是唯一一家做端到端的公司,还有Comma.ai和Wayve.ai等公司。
现在 - 埃隆马斯克通知的一件重要事情是,使用端到端方法,我们不再“告诉”车辆在红灯处或停车标志处停车,或者在变道前验证 xyz......
车辆通过“模仿”他们使用的 1000 万个视频中的驾驶员来自己解决问题。因此,这意味着他们一直在使用 1000 万个视频的数据集,他们根据每个视频对驾驶员进行评分,并训练机器模仿“优秀驾驶员”的行为。
从理论上来说,这可能意义重大,因为这意味着模型在面对未知场景时可以更好地概括——它会在训练中找到最接近的行为,而不是停滞不前。
概括
到目前为止,特斯拉正在采用模块化方法实现自动驾驶,其中两个主要模块相互通信:感知和规划。
2021 年,他们推出了 HydraNet,这是一种多任务学习架构,能够同时解决许多感知任务。
他们还宣布他们的规划器是蒙特卡洛树搜索和神经网络的组合。
2022 年,他们添加了占用网络,这有助于更好地理解 3D。HydraNet 还具有车道线检测扩展。
为了从当前系统过渡到端到端系统,他们需要(1)将规划器转变为深度学习系统,以及(2)使用联合损失函数进行训练。
该系统可能看起来像一个黑盒子,但它实际上是现有块的组合——它们不会摆脱已经构建的一切,而只是将它们粘在一起。
Related
1. 自动驾驶算法—利用深度学习进行端到端运动规划
2. 端到端自动驾驶算法—采用卷积神经网络 (CNN) 的自动驾驶汽车
3. 端到端自动驾驶算法—模仿学习(Imitation Learning)(一)
4. 端到端自动驾驶算法—模仿学习(Imitation Learning)(二)











