LSTM是RNN的升级版。
RNN 用于解决时序问题,但难以长距离保留信息,从而导致短期记忆问题,所以LSTM 就出现了,其利用了RNN的循环特性,但又略有不同。
回到RNN,有一个神经网络,输入为x,一个隐藏层,其中包含一个使用 tanh 激活函数的神经元,以及一个使用 sigmoid 激活函数的输出神经元:
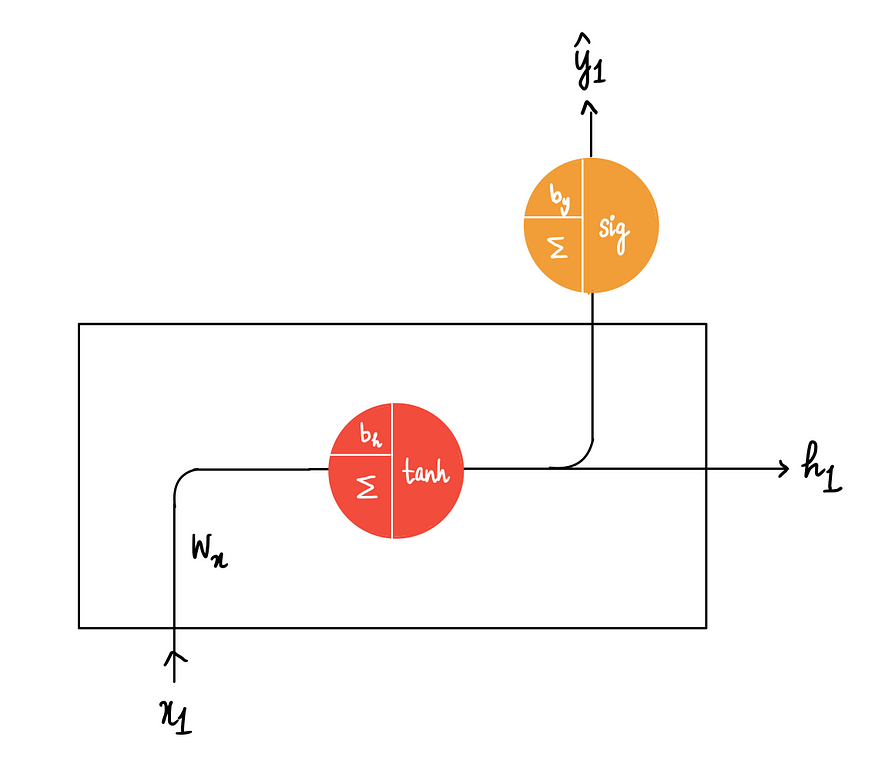
将每一步称为一个隐藏状态。所以上图是 RNN 的第一个隐藏状态。
将第一个输入x ₁传递给隐藏神经元以获得h₁。

h₁ = 第一个隐藏状态输出
现在有两个方案:
方案1:将这个h₁ 传递给输出神经元,仅使用这一个输出即可获得预测。

其中y₁^为第一个隐藏状态预测结果。
上面随意选择了 S 型激活函数作为输出激活函数,实际中可根据要解决的问题类型,可以选择Softmax、ReLU、线性函数等等。
方案2:将此h₁ 传递到下一个隐藏状态,方法是将此值传递到下一个状态的神经元。
如下图所示:
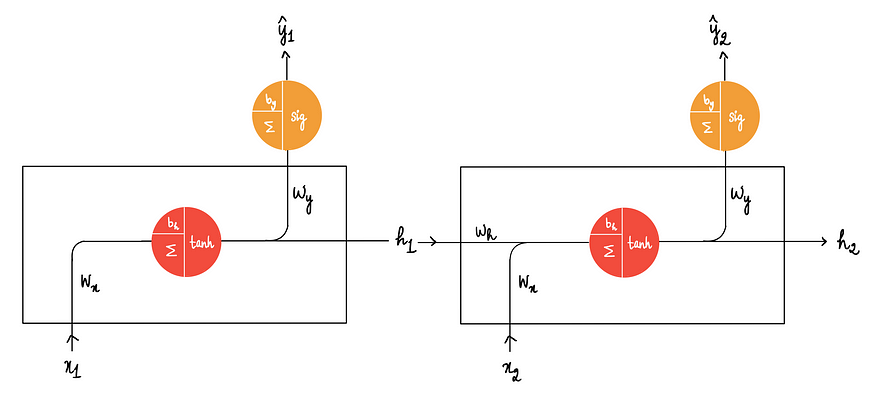
将第一个网络中隐藏神经元的输出与第二个输入x₂ 一起传递给当前网络中的隐藏神经元。这样做就得到了第二个隐藏层的输出h₂ 。
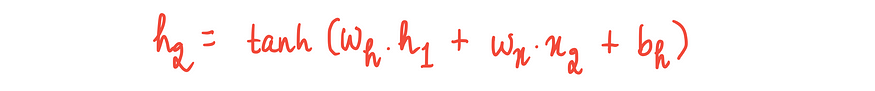
h₂ = 第二个隐藏状态输出
同样用h₂也有两个方案:
方案1:将其传递给输出神经元以获得由第一个输入x₁和第二个输入x₂得出的预测。

其中y₂^为 第2个隐藏状态预测。
方案2:直接将其传递到下一个网络。
这个过程持续进行,每个状态都会从前一个网络的隐藏神经元获取输出(与新的输入一起),并将其馈送到当前状态的隐藏神经元,从而生成当前隐藏层的输出。然后,我们可以将此输出传递到下一个网络或输出神经元,以产生预测。
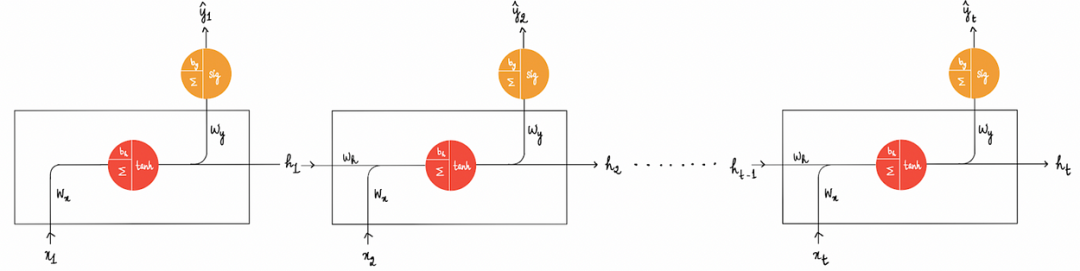
整个过程可以用以下关键方程式来描述:
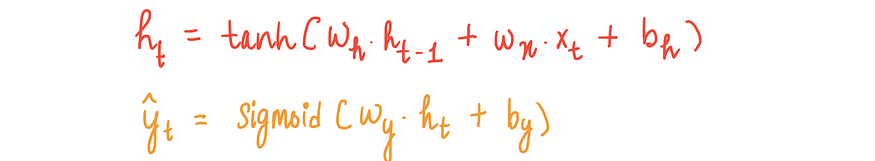
尽管这种方法很简单,但它有一个局限性:随着我们进入最后几步,初始步骤中的信息开始逐渐消失,因为网络无法保留大量信息。输入序列越大,这个问题就越明显。显然,我们需要一种策略来增强这种记忆。
要解决这个问题:在每一步中,它们会丢弃输入和过去步骤中不必要的信息,有效地“忘记”不重要的信息,只保留关键信息。这有点像我们大脑处理信息的方式——我们不会记住每一个细节,只会保留我们认为必要的细节,丢弃其余部分。
回到RNN 的隐藏状态:
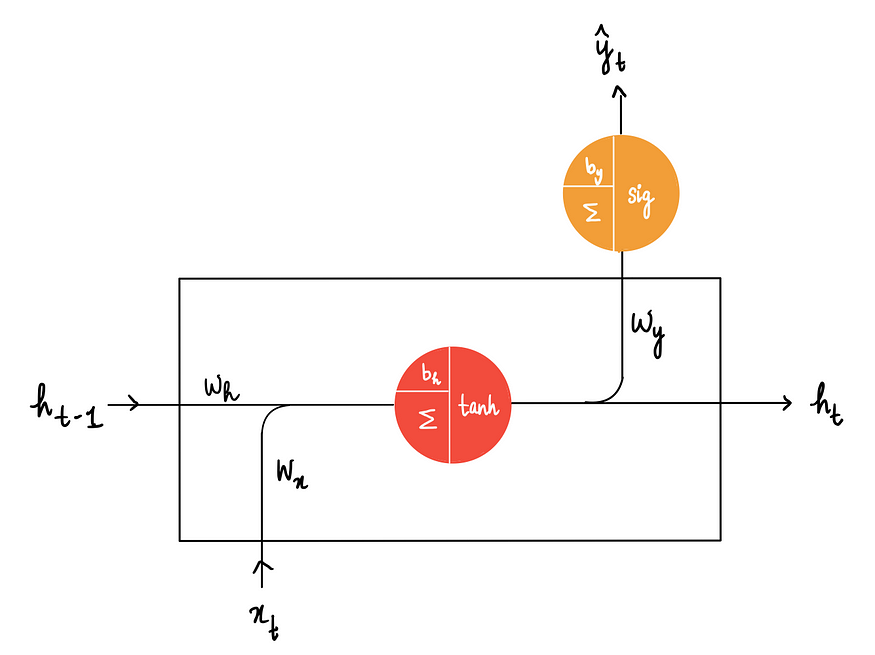
其中每个状态都以两个参与者开始:前一个隐藏状态值h ₜ₋₁ 和当前输入x ₜ。最终目标是产生一个隐藏状态输出hₜ,它可以传递到下一个隐藏状态,也可以传递到输出神经元以产生预测。
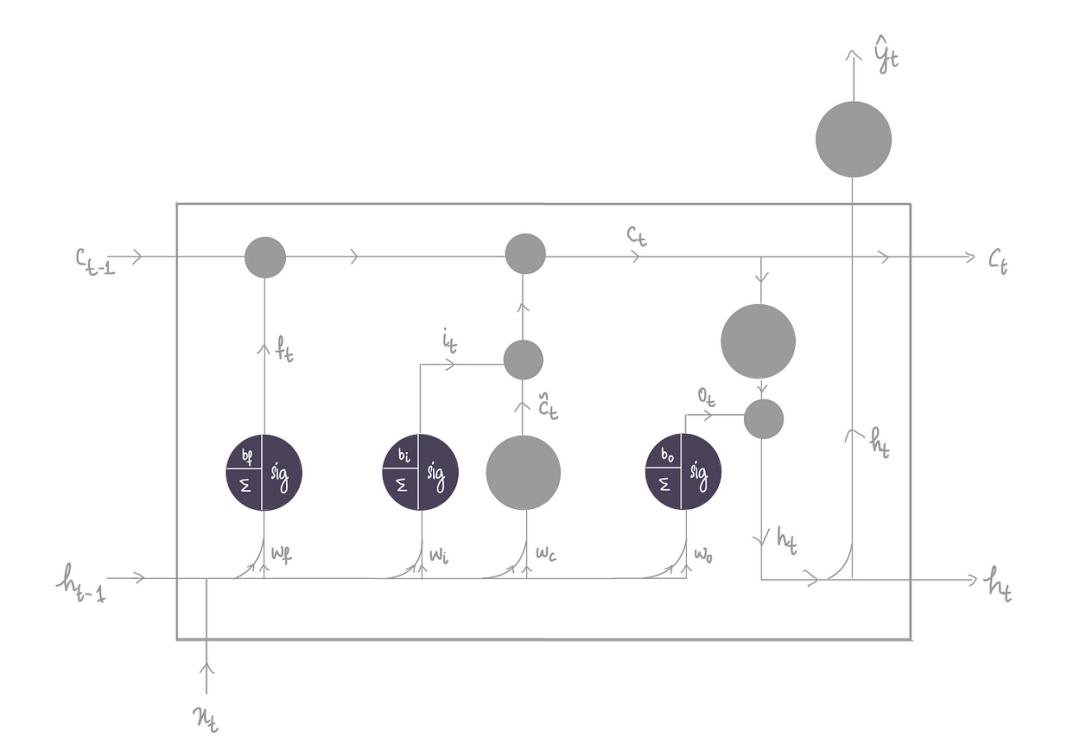
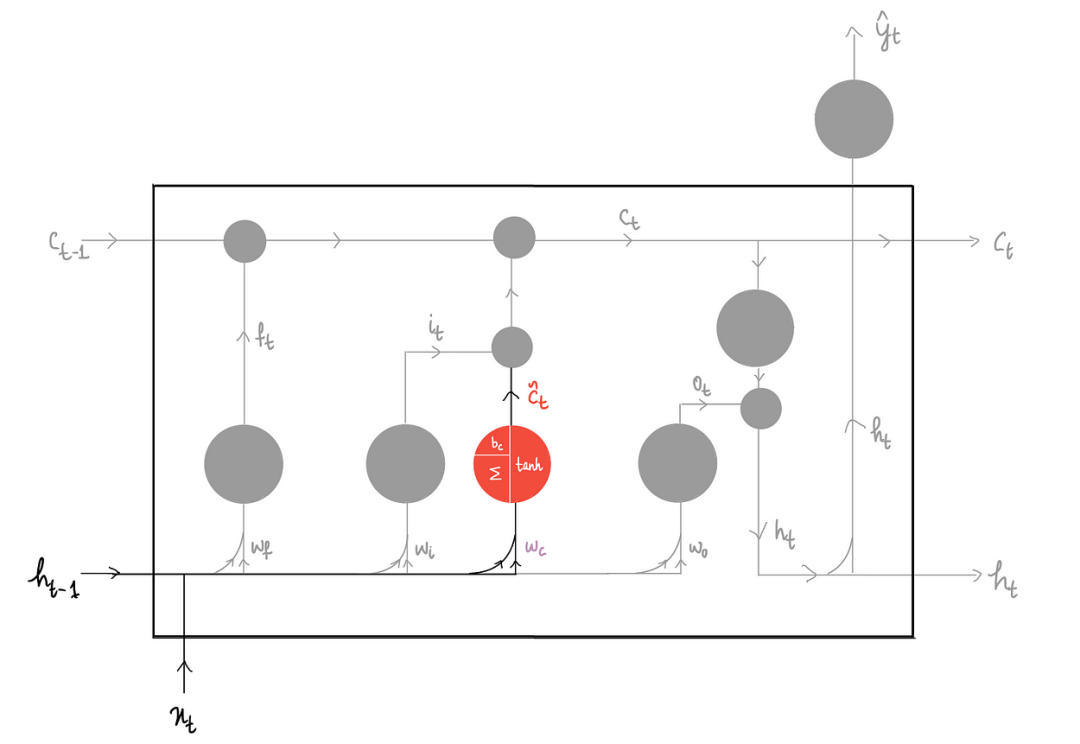
LSTM 具有类似的结构,但复杂性略有提高:
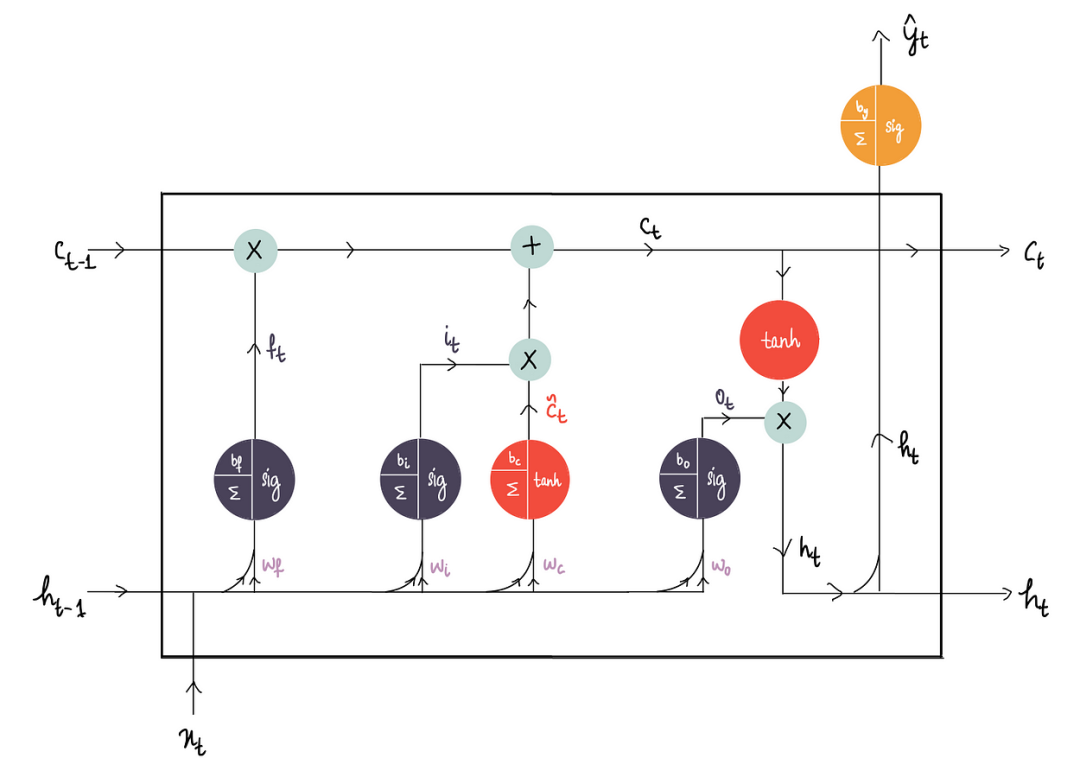
在 RNN 中设置了两个输入,最终目标是生成一个隐藏状态输出。
而现在一开始就有三个输入,它们被输入到 LSTM 中——之前的长期记忆Cₜ₋₁、之前的隐藏状态输出hₜ₋₁以及输入xₜ
:
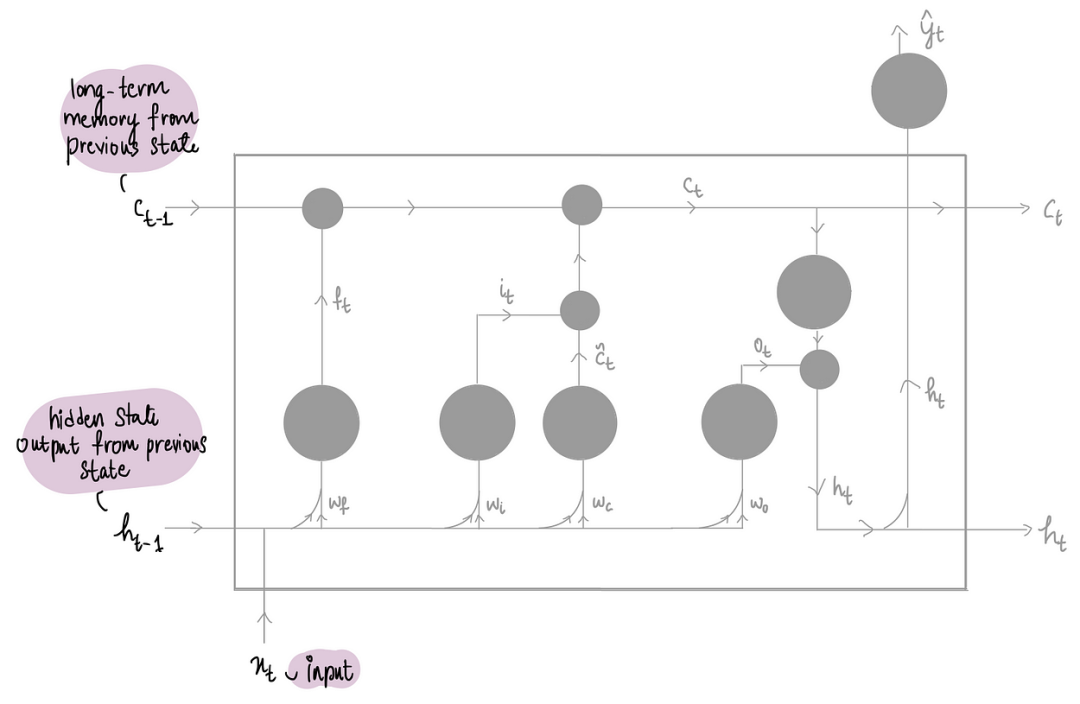
最终目标是产生两个输出——新的长期记忆 Cₜ 和新的隐藏状态输出 hₜ:
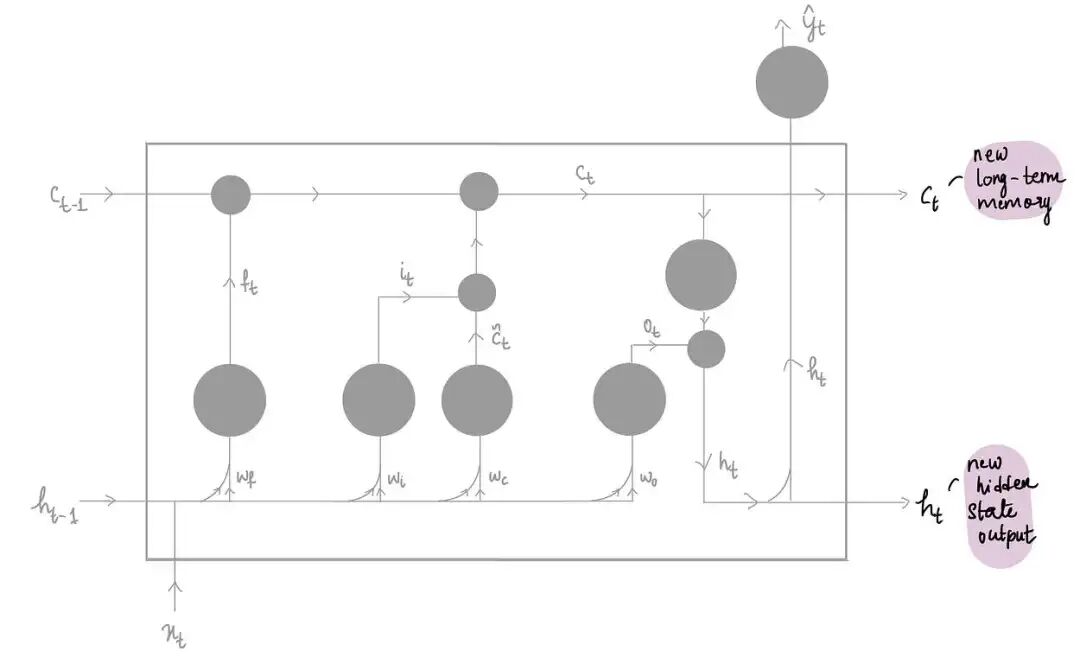
LSTM 的主要重点是丢弃尽可能多的不必要的信息,它通过三个部分实现这一点:
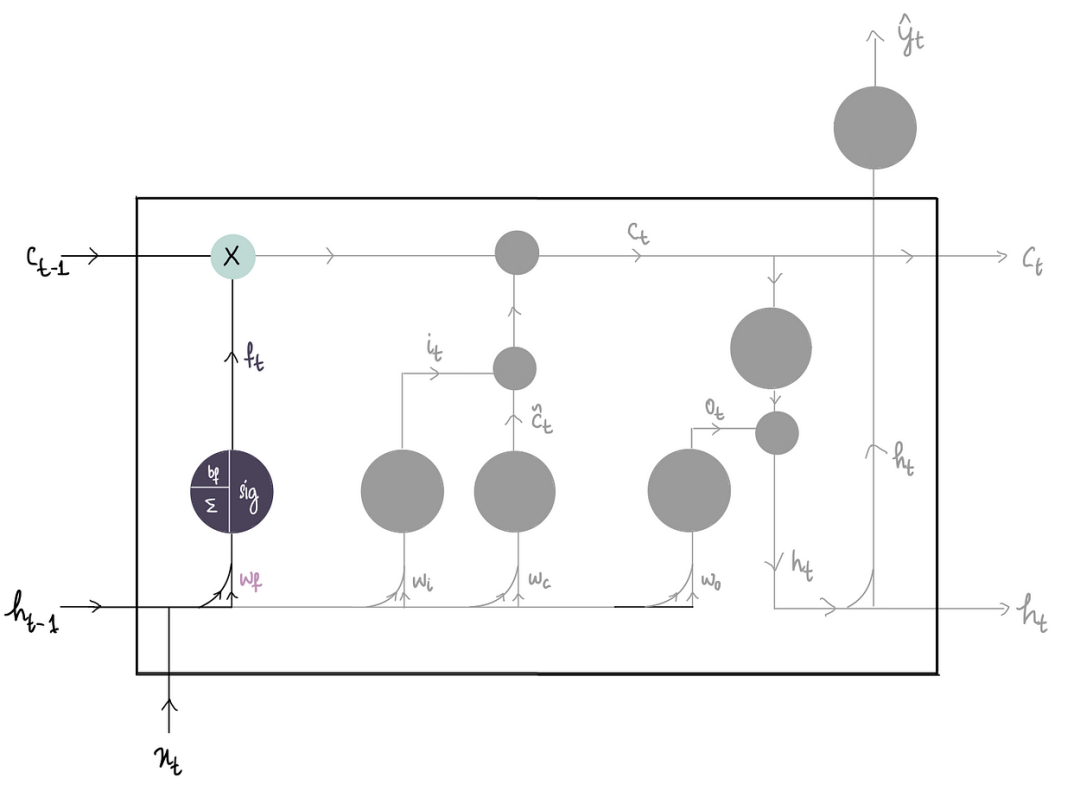
1)忘记部分
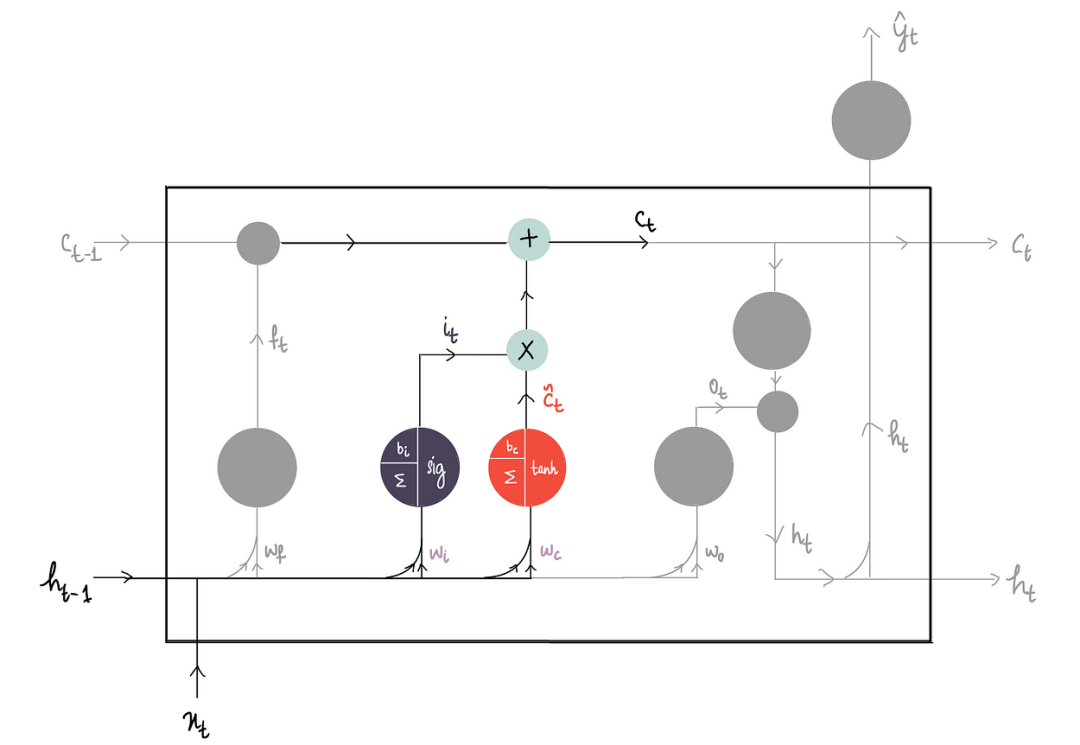
2)输入部分
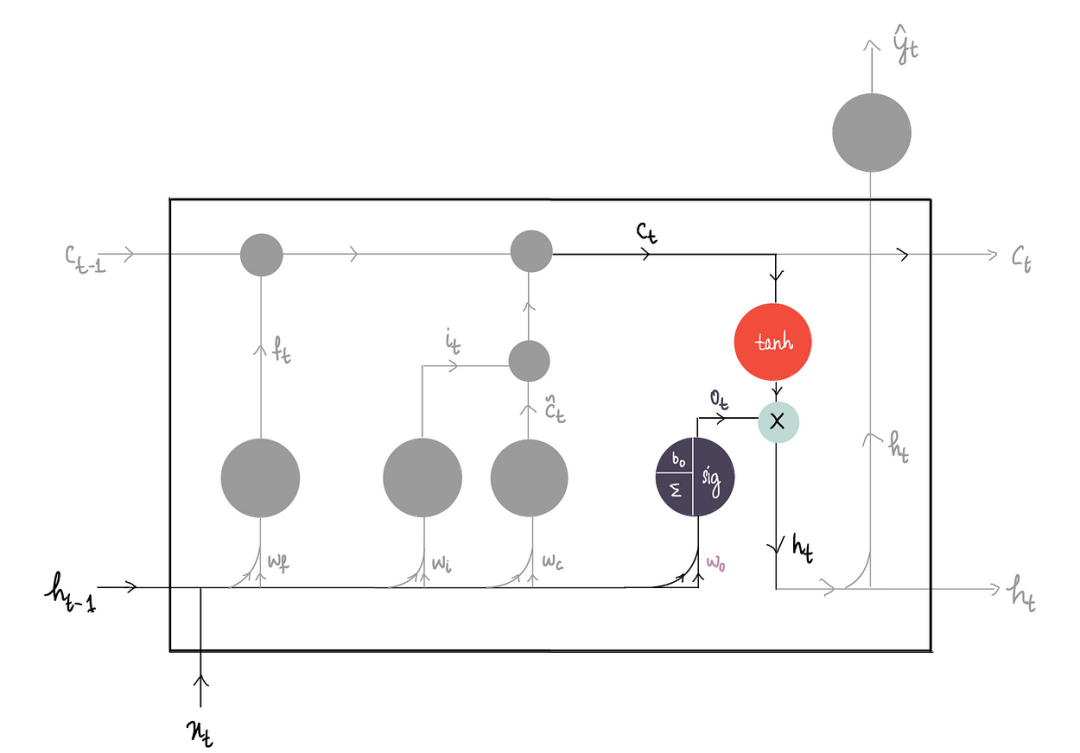
3)输出部分
上图中有一个共同的紫色的单元,这些单元被称为门。
为了判断哪些信息重要,哪些不重要,LSTM 使用这些门,它们本质上是具有 S 型激活函数的神经元。
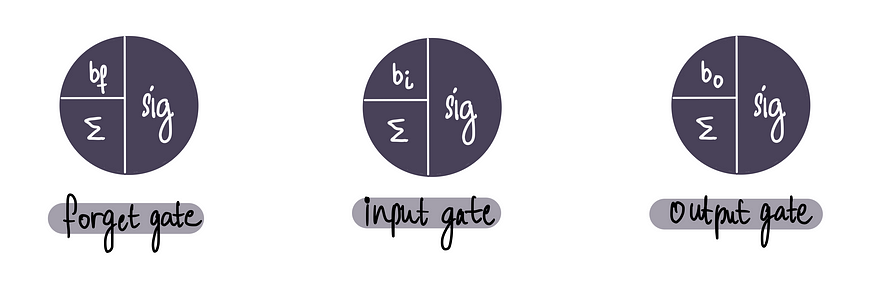
这些门决定在各自的部分中保留多少比例的信息,实际上充当守门人的角色,只允许一定比例的信息通过。
在这种情况下,使用 S 型函数具有策略性,因为它的输出值范围从 0 到 1,这直接对应于我们想要保留的信息比例。例如,值为 1 表示所有信息将被保留,值为 0.5 表示仅保留一半信息,值为 0 表示所有信息将被丢弃。
现在我们来看看所有这些门的公式。如果仔细观察隐藏状态图,我们会发现它们都有相同的输入x ₜ 和h ₜ₋₁,但权重和偏差项不同。
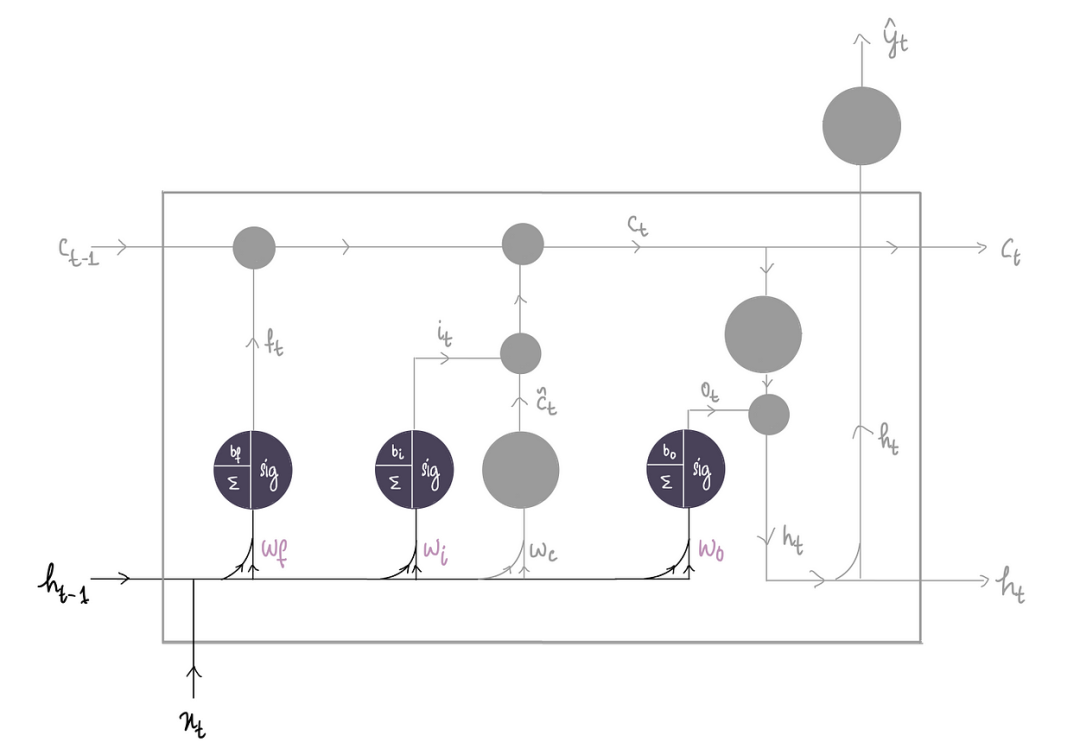
它们都有相同的数学公式,但我们需要适当地交换权重和偏差值。

每个值都会产生 0 到 1 之间的值,因为这就是 S 型函数的工作原理,它将决定我们想要保留每个部分中特定信息的比例。这里你会注意到我们只是使用了权重的向量表示法。这意味着我们要将xₜ和hₜ₋₁w表示)相乘。
在这里所做的就是从遗忘门中获取这个比例(0-1 之间的值)……
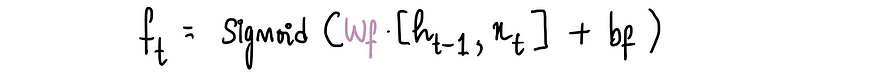
并将其与之前的长期记忆相乘:
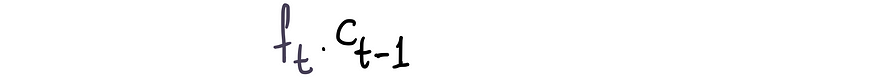
这个乘积给出了遗忘门认为重要的先前长期记忆的精确值,并忘记了其余部分。
因此,遗忘门比例 fₜ 越接近 1,我们保留的先前长期记忆就越多。
其中蓝色气泡内的“x”符号表示乘法运算。此符号在整个图表中始终使用。本质上,这些蓝色气泡表示输入需要经过气泡中所示的数学运算。

创建LSTM可分2个步骤:
1.创建新的长期记忆候选C(tilda) ₜ。
使用带有tanh激活函数的神经元来获取新的长期记忆候选:
这个神经元的输入是x ₜ 和h ₜ₋₁,类似于门电路。所以,将它们传递到神经元。
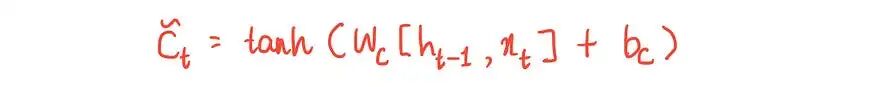
上面的输出是新的LSTM的“候选”。
现在我们只想保留候选集的必要信息。这时输入门就派上用场了。我们使用从输入门获得的比例:
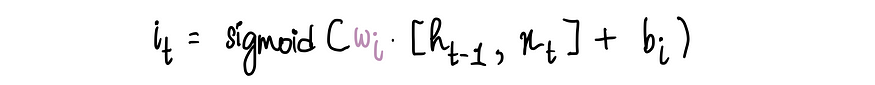
通过将此输入门比例与候选者相乘,仅保留候选者的必要数据:

2.现在为了获得最终的长期记忆,我们把决定保留在遗忘部分的旧长期记忆拿来。
并将其添加到我们决定在此输入部分保留的新候选人数量中:
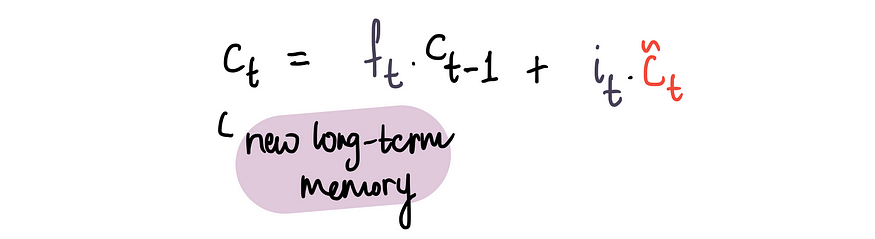
上面就完成了一个LSTM的创建,接下来需要生成一个新的隐藏状态输出。
1.输出部分
获取新的长期记忆Cₜ,并将其传递给tanh函数:
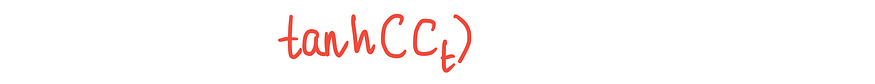
然后将其与输出门比例Oₜ相乘:
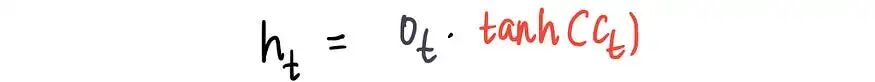
则输出了新的隐藏状态。
2.将这些新的输出传递到下一个隐藏状态,再次重复相同的过程。
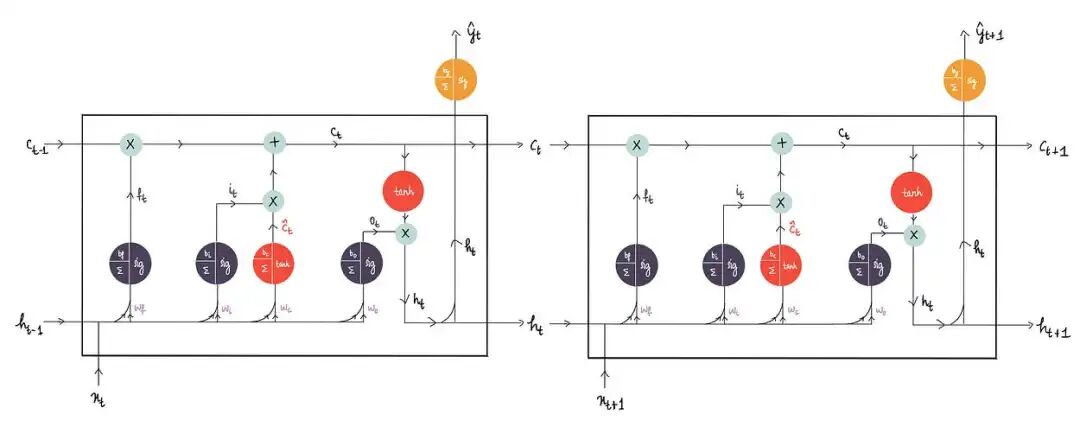
可以看到每个隐藏状态都有一个输出神经元:
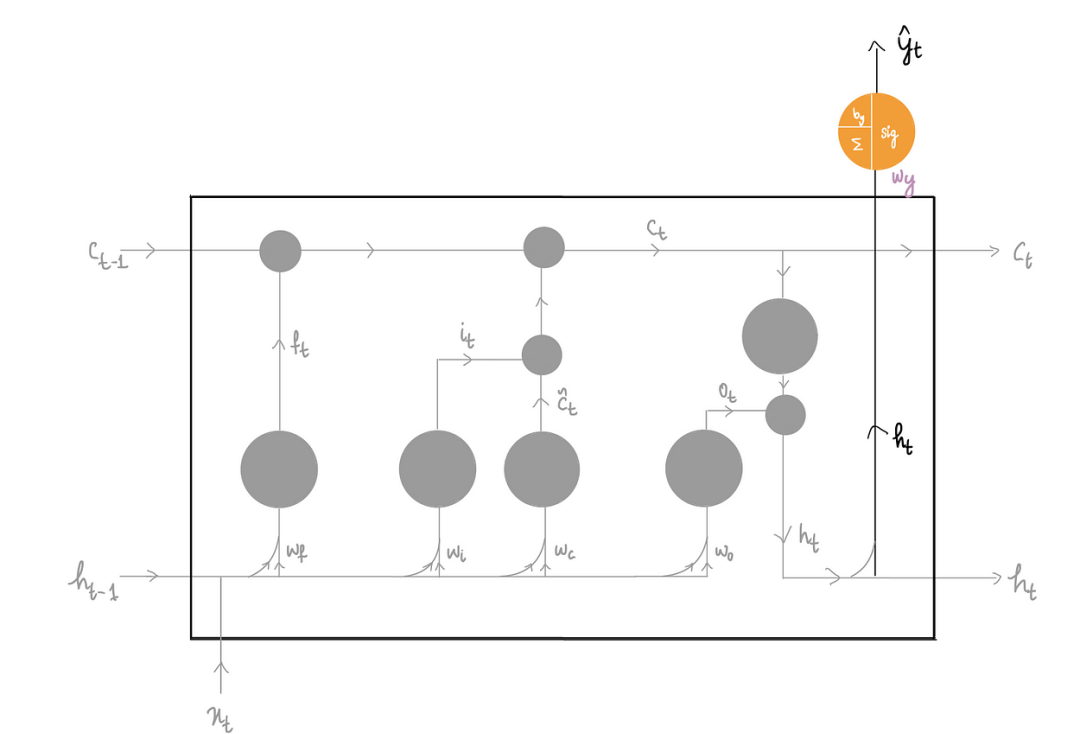
就像在 RNN 中一样,每个状态都可以产生各自的输出。
与 RNN 类似,使用隐藏状态的输出 hₜ 来生成预测。因此,将 hₜ 传递给输出神经元:

这样就得到了这个隐藏状态的预测结果。
LSTM 通过更好地处理序列数据中的长期依赖关系,将 RNN 提升到了一个新的水平。我们看到 LSTM 巧妙地保留重要信息并丢弃无关信息,就像我们的大脑一样。这种在扩展序列中记住重要细节的能力,使得 LSTM 在自然语言处理、语音识别和时间序列预测等任务中尤为强大。
https://medium.com/@shreya.rao/list/deep-learning-illustrated-ae6c27de1640








