正则表达式(Regular Expression)是用来匹配字符串的强有力武器,在数据处理有着不容小觑的地位。想要使用python的正则表达式功能需要调用re模块,re模块为高级字符串处理提供了几乎所有的正则表达式,包括字符串的匹配、替换、检索等。
在脚本中引入re模块的方法很简单,只需输入命令语句import re即可。今天,我们先为大家介绍该模块中常用几个的字符串函数。
(1)match函数
功能:从字符串的起始位置匹配一个正则表达式,如果匹配成功则返回一个匹配的对象,如果不是起始位置匹配成功的话,match函数就返回None。
语法:
re.match(pattern,string,flags=0)
其中,参数pattern:是一个正则表达式,参数string:表示要匹配的字符串;参数flags用于控制正则表达式的匹配方式,如:re.I代表区分大小写,re.S代表使正则表达式的元字符“.”匹配包括换行符\n在内的所有字符等等。
举个小例子:首先,我们导入re库并定义一个字符串:
import re
str='stata club'
我们想要匹配字符串str中的字符“a”,若执行如下命令:
print(re.match(r'a',str)
得到结果:
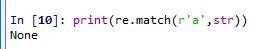
我们发现,字符串str起始位置的字符不是“a”,所以函数
re.match的匹配结果是None。
(2)search函数
功能:search 扫描整个字符串并返回第一个成功的匹配,如果匹配成功search函数返回第一个匹配到的对象,否则返回None。
语法:re.search(pattern, string, flags=0),每一个参数的含义同上
同样,我们用函数search匹配字符串str中的字符“a”:
print(re.search(r'a',str))
得到结果:
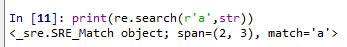
可以看到:search函数匹配到了字符“a”,且只匹配一次,并返回匹配的起始和结束位置的元组分别为2和3(0表示初始位置)。
(3)findall函数
功能:在字符串中找到正则表达式所匹配的所有子字符串,并返回一个列表,如果没有找到匹配成功的,则返回空列表。
语法:re.findall (pattern, string,flags=0),每一个参数的含义同上。
那么,用函数findall匹配字符串str中的字符“a”,又会出现的怎样的结果呢?
print(re.findall(r'a',str))
结果如下:

可以看到,findall函数则将返回一个所有匹配的字符串的字符串列表,也就是findall函数查找到了所有的匹配结果。
学习了这三个函数的基本区别,我们来看看这三个函数与正则表达式中一些元字符的搭配使用:
(1)match函数
str1 = 'Wen0128Yue0625Feng1004Lu0721'
h=re.match(r'[a-z]{3}',str1,re.I)
print(h.group())
print(h.span())
得到结果:
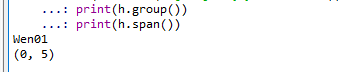
可以看到匹配到的字符串是Wen01,返回的匹配起止位置的元组是(0,5)
(2)search函数
str2="08116 zhongnancai 430070 tongshu "
m=re.search(r'\d+',str2)
print(m.group())
print(m.end())
得到结果:

可以看到匹配到的字符串是08116,返回的匹配终止位置的元组是5
(3)findall函数
str3="abc188ef9431g6666"
n=re.findall(r'\d+',str3)
print(n)
得到结果:
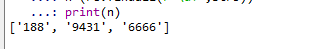
可以看到返回的值是个列表,并且返回了字符串中所有匹配到的子字符串。
总结一下:即函数 match和 search 只匹配一次,匹配不到返回None,而函数findall 是查找所有匹配结果。
以上就是我们今天介绍的3个字符串函数与正则表达式搭配使用的方法以及它们的用法区别,不过正则表达式的内容远不止此,在后面的推文中我们会相继介绍其他相关内容,与大家一起交流学习哟~










