
/免责声明>
说到这里,后面的我负责了。
我们从哪里开始?
从整体上看这个项目可能会比实际上更困难。所幸的是,我们能够把它划分成更小的部分,当这些部分合并在一起时,我们就可以使增强现实应用程序工作了。现在的问题是,我们需要哪些更小的块?

1、识别参考平面。
2、估计单应性。
3、从单应性推导出从参考面坐标系到目标图像坐标系的转换。
4、在图像(像素空间)中投影我们的3D模型并绘制它。
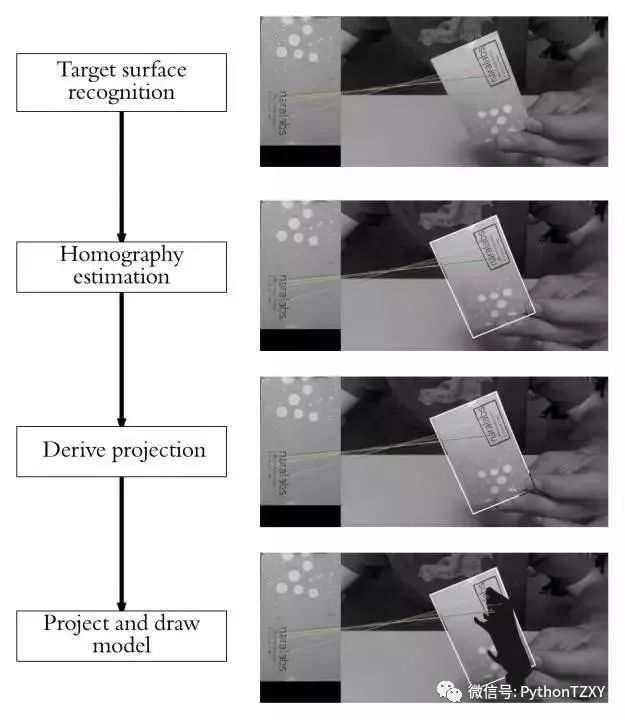
图2:概述增强现实应用程序的整个过程。
我们将使用的主要工具是Python和OpenCV,因为它们都是开源的,易于建立和使用,并且使用它们能快速构建原型。用到代数,我将使用numpy。


图3:左侧,从我将使用的表面模型中提取的特征。右侧,从场景中提取的特征。注意,最右侧图形的角落是如何检测为兴趣点的。
特征描述
一旦找到特征,我们应该找到它们提供的信息的适当表示形式。这将允许我们在其它图像中寻找它们,并且还可以获取比较时两个检测到的特征相似的度量。描述符提供由特征及其周围环境给出的信息的表示。一旦描述符被计算出来,待识别的对象就可以被抽象成一个特征vector,该vector包含图像和参考对象中发现的关键点的描述符。
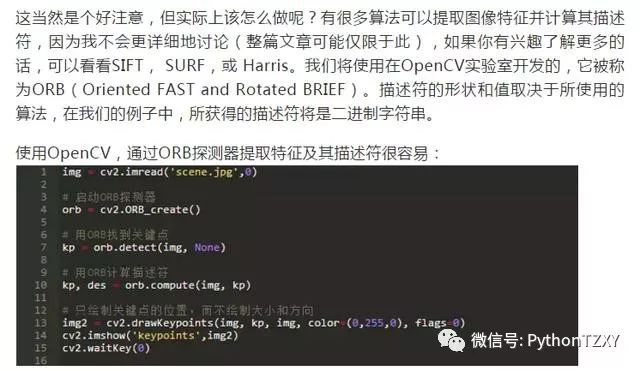


图4:参考面和场景之间找到最接近的15个暴力匹配
最后,在找到匹配之后,我们应该定义一些标准来决定对象是否被找到。为此,我定义了应该找到的最小匹配数的阈值。如果匹配的数量高于阈值,则我们假设对象该已经被找到。否则,我们认为没有足够的证据表明识别是成功的。
使用OpenCV ,所有这些识别过程都可以用几行代码完成:
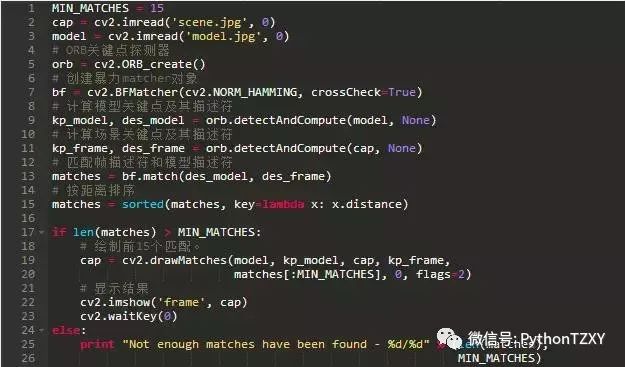

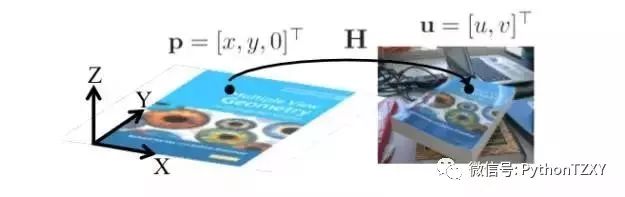
图5:平面和图像之间的单应。来源: F. Moreno.
我们怎么能找到这样的转变呢?既然我们已经找到了两幅图像之间的一组匹配,我们当然可以直接通过任何现有的方法(我提议使用RANSAC)找到一个同构转换来执行映射,但让我们了解一下我们正在做什么(见图6)。如果需要,你可以跳过以下部分(在图10之后继续阅读),因为我只会解释我们将要估计的转换背后的原因。
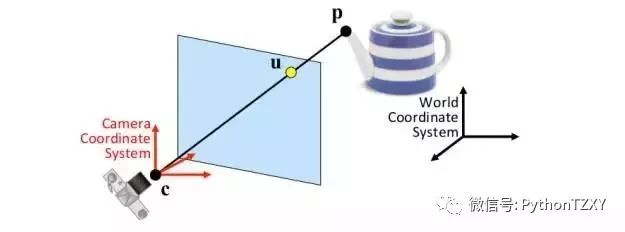
我们所拥有的是一个具有已知坐标的对象(在这种情况下是一个平面),比方说世界坐标系,我们用位于相对于世界坐标系的特定位置和方向的摄像机拍摄它。我们假定相机遵循针孔模型工作,这大致意味着穿过3D点p和相应的2D点u的光线相交于摄像机的中心c。如果你有兴趣了解更多关于针孔模型的知识,这里有一个好的资源。
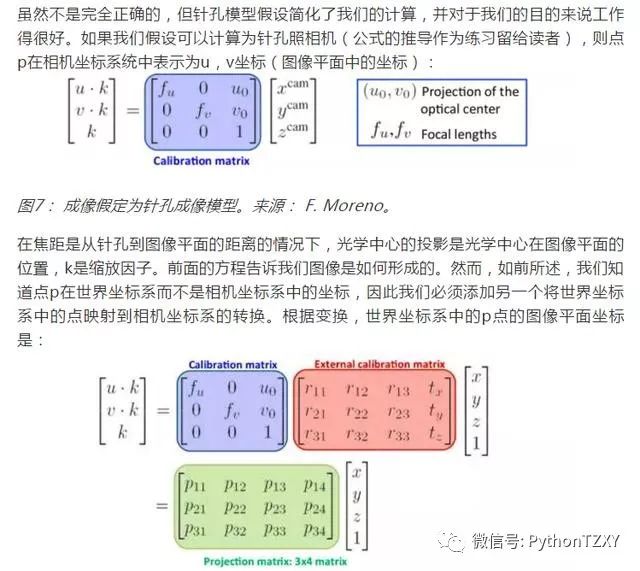
幸运的是,由于参考面的点的z坐标始终等于0(参考图5),我们可以简化上面发现的转换。很容易看出,z坐标和投影矩阵的第三列的乘积将是0,所以我们可以将该列和z坐标从前面的等式中删除。将校准矩阵重命名为A,并考虑到外部校准矩阵是齐次变换:
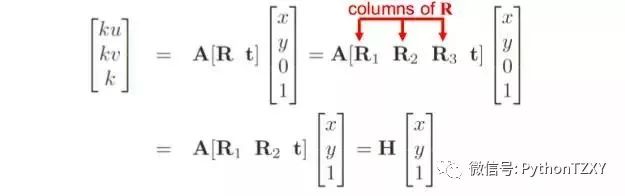
图9:简化投影矩阵。来源: F. Moreno。
从图9我们可以得出结论,参考面与图形平面之间的单应,这是我们从之前发现的匹配中估计出的矩阵:
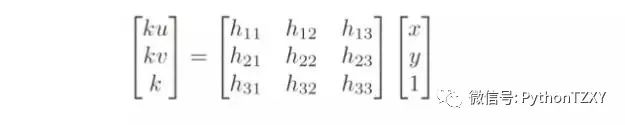
图10:参考平面和目标图像平面之间的单应矩阵。来源: F. Moreno。
有几种可以让我们估计单应矩阵的值,并且你可能熟悉其中的一些。我们将使用的是RANdom SAmple Consensus(RANSAC)。RANSAC是一种用于存在大量异常值的模型拟合的迭代算法,图12列出了该过程的纲要。因为我们不能保证我们发现的所有匹配都是有效的匹配,我们必须考虑有可能存在一些错误的匹配(这将是我们的异常值),因此我们必须使用一种对异常值有效的估计方法。图11说明了如果我们认为没有异常值估计单应时,可能会存在的问题。

图11:存在异常值的单应估计。来源: F. Moreno。

图12:RANSAC算法概述。来源: F. Moreno。
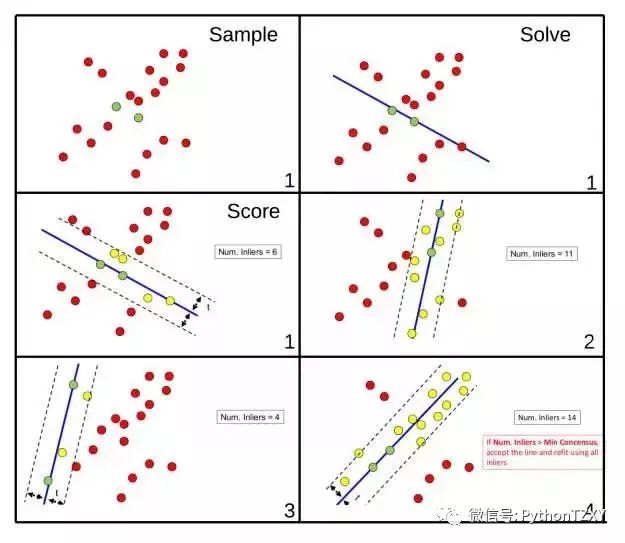
为了说明RANSAC如何工作,并且使事情更清楚,假设我们有一组要使用RANSAC拟合一条线的点:

图13:初始点集。来源: F. Moreno。
根据图12所示的概述,我们可以推导出使用RANSAC拟合线的具体过程(图14)。

图14:RANSAC算法将一条线拟合到一组点。来源: F. Moreno。
运行上述算法的一个可能的结果可以在图15中看到。注意,该算法的前3个步骤只显示第一次迭代(由右下角的数字表示),并且只显示评分步骤。

其中5.0是距离阈值,用来确定匹配与估计单应是否一致。如果在估计单应之后,我们将目标图像的参考面的四个角投影到一条线上,我们应该期望得到的线将参考面包围在目标图像中。我们可以这样做:
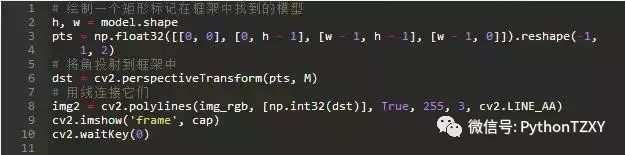
结果是:

图17:具有估算单应的参考面的投射角。
我想今天就到这里了。在下一篇文章,我们将看到如何扩展我们已经估计的单应矩阵,不仅可以在投影参考面上的点,而且可以投影从参考面坐标系到目标图像的任何3D点。我们将使用这个方法来实时计算,每个视频帧的特定投影矩阵,然后从.obj文件选择投影的视频流3D模型。在下一篇文章的结尾,你可以看到类似于下面GIF中所看到的内容:

与往常一样,发布第2部分时,我会上传该项目的完整代码和一些3D模型到GitHub供你测试。
私信小编007即可获取数十套PDF哦!









