编者按:将人工智能技术注入我们每天使用的输入法,会产生什么样的智能体验?微软的SwiftKey就是这样一款智能的输入法产品,它不仅使用深度学习技术优化输入体验,还将深度学习的场景部署到了每个用户的移动设备上,为用户提供“私人定制”的智能输入联想。在前不久的GMIC上,SwiftKey深度学习团队负责人Doug Orr为我们分享了SwiftKey在产品中用深度学习来改善用户体验的心得。本文是此次演讲的文字精简版。
演讲视频:
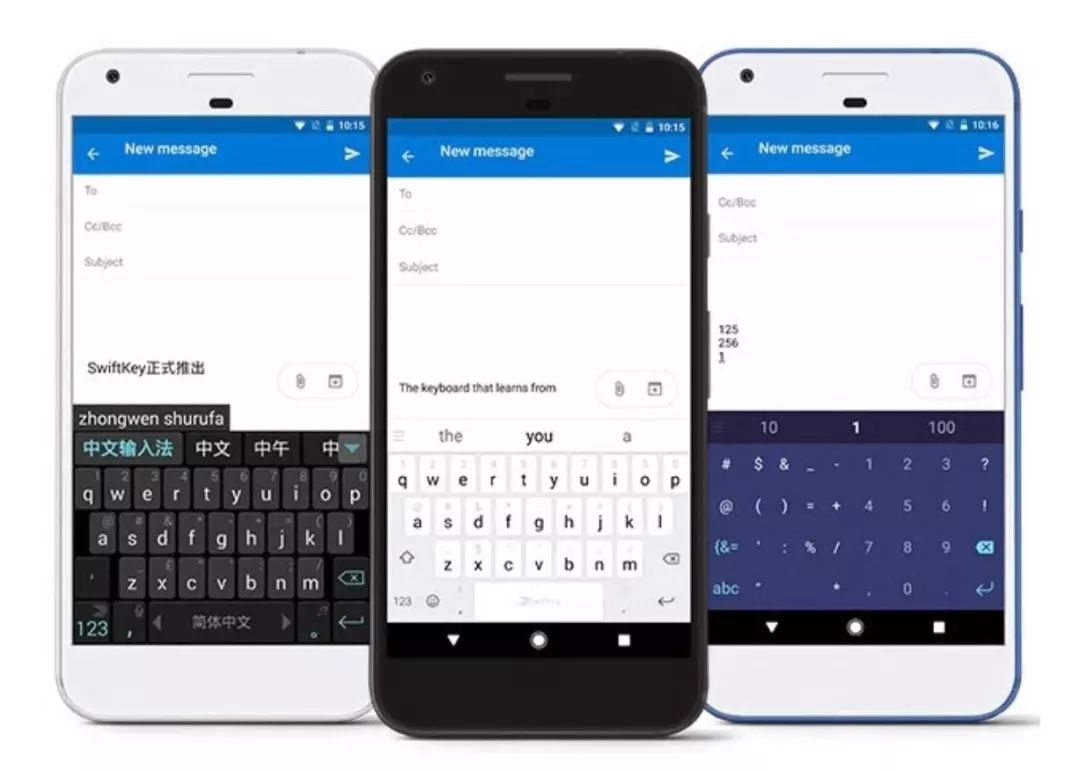
SwiftKey是一款采用人工智能技术的输入法产品,致力于利用人工智能技术为用户提供更轻松的移动端输入体验。SwiftKey诞生于2015年,并在2016年加入了微软大家庭。
为了确保用户在输入时获得最佳的联想结果,我们将深度学习应用到SwiftKey中——用户每点击一次,SwiftKey将执行100万次以上的计算,为用户提供真正智能的智能联想。
一直以来,在移动设备上进行深度学习是令人兴奋又充满挑战的。移动设备是获取最新、与用户个人最相关的大数据的重要媒介。在移动设备上进行深度学习,不仅能为用户提供精准、实时的个人智能,还能用人工智能处理一些只能够存储在移动设备上的信息,同时有利于保护用户隐私。

SwiftKey深度学习团队负责人Doug Orr
但是要实现这一功能又极具挑战。因为开展深度学习有两个基本条件,一是数据集的大小,二是计算速度,因此深度学习通常在有大量存储和计算能力的服务器上进行,手机环境能够提供的两个条件都非常有限,开展深度学习要困难得多。因此我们投入了大量的工作来克服这些挑战,有针对性地构建了高效的深度学习模型,使它适用于目前广泛使用的移动CPU。
我们认为,未来深度学习会越来越多地应用于移动设备。在这个过程中,我们也将面对许多新的研究问题,比如如何保护隐私,如何构建能够快速执行、计算的高效模型等。
深度学习经常被视为一个神秘的“黑匣子”,因为输入数据与输出结果中间的过程并不透明。但是,为了帮助我们更好地在产品中运用深度学习,我们应该深入研究并理解深度学习模型内部发生的情况。
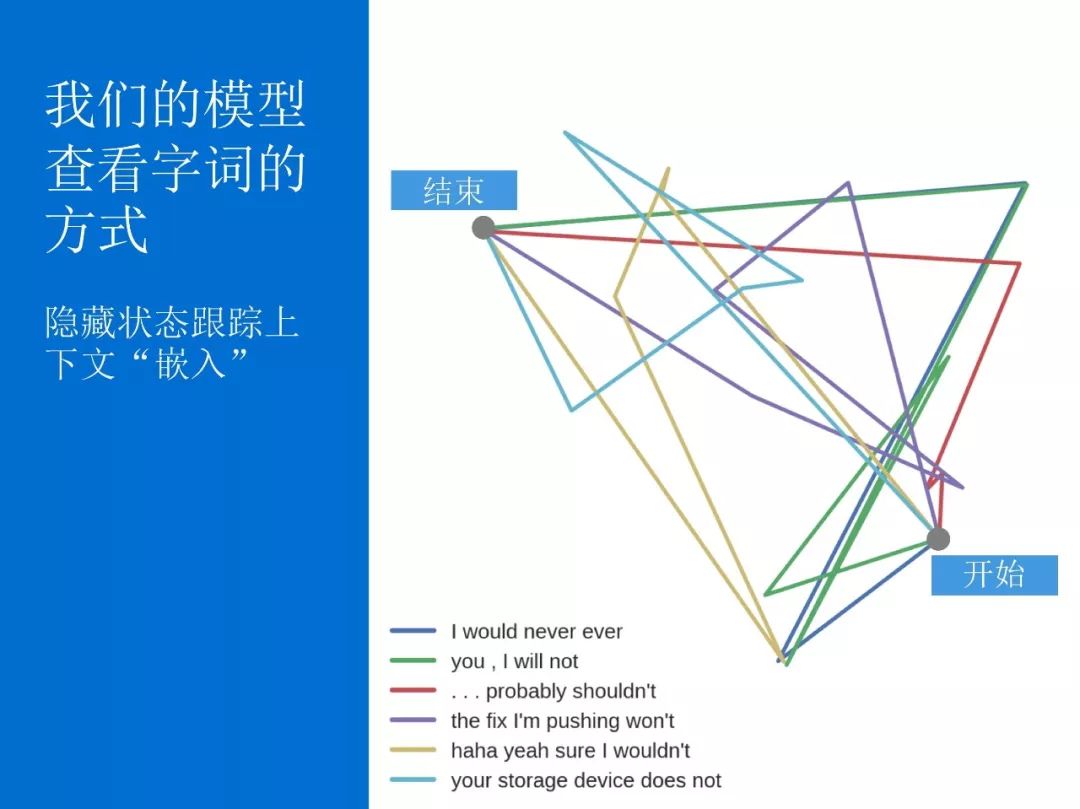
接下来我想打开深度学习模型这个“黑匣子”,和大家分享一下SwiftKey的深度学习语言模型是怎样运作的。
我们来看一个实际的应用场景。比如,人们在日常生活中会用不同的方式来表达他们丢失了手机,比如“I just lost my cell”、 “I just lost my mobile”、“I just lost my iPhone”等,它们就属于一种拥有相似单词的群集。而“I really love it”、“I really adore it”、 “I really hate it”,它们有着同样的句式,属于另一种相似的群集。
那么我们的深度学习语言模型是如何判断出语句相似性的呢?首先,要对语言进行建模,就需要先对词汇进行建模。在一张包含了我们最新模型中的所有单词的词汇地图上,虽然数千个单词呈现出纷繁复杂的状态,但是我们可以观察到,词义相似的单词会形成群集。我们的深度学习模型能够自动将单词根据词义的相似性关联起来,而不需要人工的辅助。

除了单词的词义相似性,在判断语句相似性的时候,模型还会考虑上下文和单词序列。我们的模型会把“on holiday I swim in the”和“on vacation we bathed in a”这两个语句判断为相似,因为它们符合模型相似性判断的两条规则:相似单词前面有相似上下文;相似上下文后面有相似单词。
让我们来看一个单词差别非常大的例子:“I would never ever”和“the fix I’m pushing won’t”,对于这样的情况,我们的模型可以通过不同的上下文来判断这两个句子其实是相似的,进而预测接下来的单词可能是“work”,变成“I would never ever work”和“the fix I’m pushing won't work”。
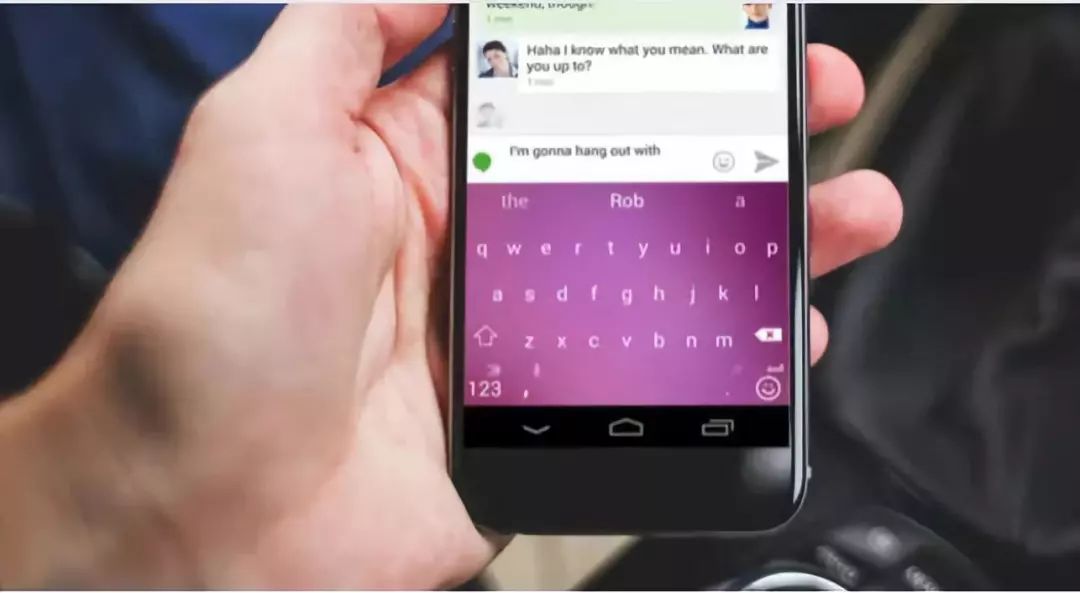
我们将这样智能的深度学习语言模型部署到SwiftKey产品中,使SwiftKey展现出了强大、人性化的理解力。即使遇到不认识的单词,模型仍然能对这个单词后面的词做出合理的联想,而且能够回顾大范围的前文进行联想,这对计算机来说非常不容易。同时,SwiftKey自带拼写更正功能,神经网络模型与智能自动更正的结合,可以让用户在移动设备上获得最佳的使用体验。
要将深度学习部署到用户的移动设备上运行,除了有效的深度学习语言模型,我们还需要解决一个关键问题,那就是移动设备上数据集和计算速度的局限性。在传统的深度学习语言模型中,如果要处理的单词量翻倍,所需的内存量和计算量通常也会翻倍。
为了解决这个问题,我们采取了新的方法,将类似压缩的理念应用到了深度学习中,使我们全新的第三代模型能在不增加内存量和计算量的情况下大大增加所能处理的单词量。目前我们正在进行最后的测试,以确保即将发布的第三代模型能够更好地应用于SwiftKey产品,我相信它的优越性能将真正带来更好的用户体验。
你也许还想看:
● 开源 | 微软开源嵌入式机器学习库ELL:把人工智能扩展到边缘设备
● 秦涛:深度学习的五个挑战和其解决方案
● 没有AI芯片,你的手机也能实现离线神经网络机器翻译

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。












