作者:Guest Blog;翻译:张玲;校对:丁楠雅
本文约4700字,建议阅读10+分钟。
本文简要介绍深度学习以及它支持的一些现有信息安全应用,并提出一个基于深度学习的TOR流量检测方案。
简介
我们看到的大多数深度学习应用程序通常面向市场、销售、金融等领域,但在使用深度学习来保护这些领域的产品和业务、避免恶意软件和黑客攻击方面,则鲜有文章或资源。
像谷歌、脸谱、微软和SalesForce这样的大型科技公司已经将深度学习嵌入他们的产品之中,但网络安全行业仍在迎头赶上。这是一个具有挑战性的领域,需要我们全力关注。

本文中,我们简要介绍深度学习(Deep Learning,DL)以及它支持的一些现有信息安全(此处称为InfoSec)应用。然后,我们深入研究匿名TOR流量检测这个有趣的问题,并提出一个基于深度学习的TOR流量检测方案。
本文的目标读者是已经从事机器学习项目的数据科学专业人员。本文内容假设您具备机器学习的基础知识,而且当前是深度学习和其应用案例的初学者或探索者。
为了能够充分理解本文,强烈推荐预读以下两篇文章:
《使用数据科学解开信息安全的神秘面纱》
《深度学习的基础知识-激活功能以及何时使用它们》
目录
一、信息安全领域中深度学习系统的现状
二、前馈神经网络概述
三、案例研究:使用深度学习检测TOR流量
四、数据实验-TOR流量检测
一、信息安全领域中深度学习系统的现状
深度学习不是解决所有信息安全问题的“灵丹妙药”,因为它需要广泛的标注数据集。不幸的是,没有这样的标记数据集可供使用。但是,有几个深度学习网络对现有解决方案做出重大改进的信息安全案例。恶意软件检测和网络入侵检测恰是两个这样的领域,深度学习已经显示出比基于规则和经典机器学习的解决方案有更显著的改进。
网络入侵检测系统通常是基于规则和签名的控件,它们部署在外围以检测已知威胁。攻击者改变恶意软件签名,就可以轻易地避开传统的网络入侵检测系统。Quamar等[1]在他们的IEEE学报论文中指出,有望采用自学的基于深度学习的系统来检测未知的网络入侵。基于深度神经网络的系统已经用来解决传统安全应用问题,例如检测恶意软件和间谍软件[2]。

与传统的机器学习方法相比,基于深度学习的技术的泛化能力更好。Jung等[3]基于深度学习的系统甚至可以检测零日恶意软件。毕业于巴塞罗那大学的Daniel已经做了大量有关CNN(Convolutional Neural Networks,卷积神经网络)和恶意软件检测的工作。他在博士论文中提及,CNNs甚至可以检测变形恶意软件。
现在,基于深度学习的神经网络正在用户和实体行为分析(User and Entity Behaviour Analytics,UEBA)中使用。传统上,UEBA采用异常检测和机器学习算法。这些算法提取安全事件以分析和基线化企业IT环境中的每一个用户和网络元素。任何偏离基线的重大偏差都会被触发为异常,进一步引发安全分析师调查警报。UEBA强化了内部威胁的检测,尽管程度有限。
现在,基于深度学习的系统被用来检测许多其他类型的异常。波兰华沙大学的Pawel Kobojek[4]使用击键动力学来验证用户是否使用LSTM网络。Capital one安全数据工程总监JasonTrost 发表了几篇博客[5],其中包含一系列有关深度学习在InfoSec应用的技术论文和演讲。
二、前馈神经网络概述
人工神经网络的灵感来自生物神经网络。神经元是生物神经系统的基本单元。每一个神经元由树突、细胞核和轴突组成。它通过树突接收信号,并通过轴突进行传递(图1)。计算在核中进行。整个网络由一系列神经元组成。
AI研究人员借用这个原理设计出人工神经网络(Artificial Neural Network,ANN)。在这样的设置下,每个神经元完成三个动作:
因此,每个神经元可以把一组输入归为一类或者其他类。当仅使用单个神经元时,这种能力会受到限制。但是,使用一组神经元足以使其成为分类和序列标记任务的强大机制。
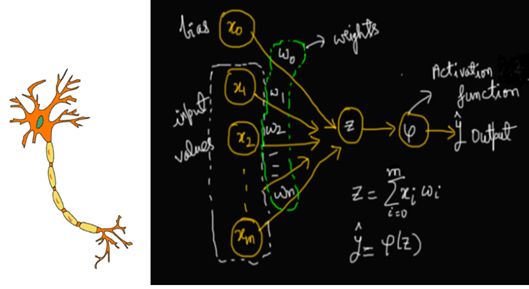
图1:我们能获得的最大灵感来自大自然——图中描绘了一个生物神经元和一个人工神经元
可以使用神经元层来构建神经网络。网络需要实现的目标不同,其架构也是不同的。常见的网络架构是前馈神经网络(Feed ForWard Neural Network,FFN)。神经元在无环的情况下线性排列,形成FFN。因为信息在网络内部向前传播,它被称为前馈。信息首先经过输入神经元层,然后经过隐藏神经元层和输出神经元层(图2)。
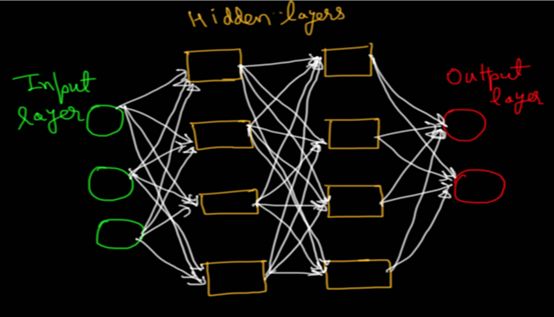
图2:具有两个隐藏层的前馈网络
与任何监督学习模型一样,FFN需要使用标记的数据进行训练。训练的形式是通过减少输出值和真值之间的误差来优化参数。要优化的一个重要参数是每个神经元赋予其每个输入信号的权重。对于单个神经元来说,使用权重可以很容易地计算出误差。
然而,在多层中调整一组神经元时,基于输出层算出的误差来优化多层中神经元的权重是具有挑战性的。反向传播算法有助于解决这个问题[6]。反向传播是一项旧技术,属于计算机代数的分支。这里,自动微分法用来计算梯度。网络中计算权重的时候需要用到梯度。
在FFN中,基于每个连接神经元的激活获得结果。误差逐层传播。基于输出与最终结果的正确性,计算误差。接着,将此误差反向传播,以修正内部神经元的误差。对于每个数据实例来说,参数是经过多次迭代优化出来的。
三、案例研究:使用深度学习检测TOR流量
网络攻击的主要目的是窃取企业用户数据、销售数据、知识产权文件、源代码和软件秘钥。攻击者使用加密流量将被盗数据混夹在常规流量中,传输到远程服务器上。
大多数经常攻击的攻击者使用匿名网络,使得安全保护人员难以跟踪流量。此外,被盗数据通常是加密的,这使得基于规则的网络入侵工具和防火墙失效。最近,匿名网络以勒索软件/恶意软件的变体形式用于C&C。例如,洋葱勒索[7]使用TOR网络和其C&C服务器进行通信。
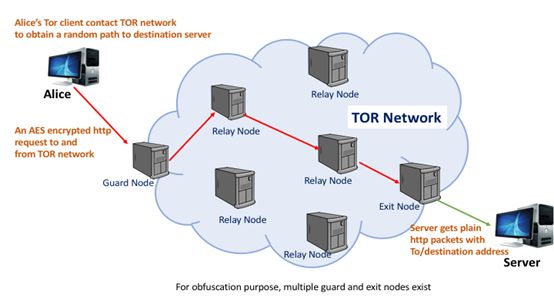
图3:Alice与目标服务器之间TOR通信的说明。通信开始于Alice向服务器请求一个地址。TOR网络给出AES加密的路径。路径的随机化发生在TOR网络内部。包的加密路径用红色显示。当到达TOR网络的出口节点时,将简单分组转发给服务器。出口节点是TOR网络的外围节点。
匿名网络/流量可以通过多种方式完成,它们大体可分为:
基于网络(TOR,I2P,Freenet)
基于自定义系统(子图操作系统,Freepto)
其中,TOR是比较流行的选择之一。TOR是一款免费软件,能够通过称为洋葱路由协议的专用路由协议在互联网上进行匿名通信[9]。该协议依赖于重定向全球范围内多个免费托管中继的互联网流量。在中继期间,就像洋葱皮的层一样,每个HTTP包使用接收器的公钥加密。
在每个接收点,使用私钥对数据包进行解密。解密后,下一个目标中继地址就会披露出来。这个过程会持续下去,直到找到TOR网络的出口节点为止。在这里数据包解密结束,一个简单的HTTP数据包会被转发到原始目标服务器。在图3中展示了Alice和服务器之间的一个示例路由方案。
启动TOR最初的目的是保护用户隐私。但是,攻击者却用它代替其他不法方式,来威逼善良的人。截至2016年,约有20%的TOR流量涉及非法活动。在企业网络中,通过不允许安装TOR客户端或者拦截保护或入口节点的IP地址来屏蔽TOR流量。
不管怎样,有许多手段可以让攻击者和恶意软件访问TOR网络以传输数据和信息。IP拦截策略不是一个合理的策略。一篇来自Distil网站[5]的自动程序情势不佳报告显示,2017年70%的自动攻击使用多个IP,20%的自动攻击使用超过100个IP。
可以通过分析流量包来检测TOR流量。这项分析可以在TOR 节点上进行,也可以在客户端和入口节点之间进行。分析是在单个数据包流上完成的。每个数据包流构成一个元组,这个元组包括源地址、源端口、目标地址和目标端口。
提取不同时间间隔的网络流,并对其进行分析。G.He等人在他们的论文“从TOR加密流量中推断应用类型信息”中提取出突发的流量和方向,以创建HMM(Hidden Markov Model,隐马尔科夫模型)来检测可能正在产生那些流量的TOR应用程序。这个领域中大部分主流工作都利用时间特征和其他特征如大小、端口信息来检测TOR流量。
我们从Habibi等人的“利用时间特征来发现TOR流量的特点”论文中得到启发,并遵循基于时间的方法提取网络流,用于本文TOR流量的检测。但是,我们的架构使用了大量可以获得的其他元信息,来对流量进行分类。这本质上是由于我们已经选择使用深度学习架构来解决这个问题。
四、数据实验-TOR流量检测
为了完成本文的数据实验,我们从纽布伦斯威克大学的Habibi Lashkari等人[11]那里获取了数据。他们的数据由从校园网络流量分析中提取的特征组成。从数据中提取的元信息如下表所示:
元信息参数 | 参数解释 |
FIAT | 前向中间达到时间,向前发送两个数据包之间的时间(平均值,最大值,最小值,标准方差) |
BIAT | 后向中间达到时间,向后发送两个数据包之间的时间(平均值,最大值,最小值,标准方差) |
FLOWIAT | 流中间达到时间,向任何一个方向发送两个数据包之间的时间(平均值,最大值,最小值,标准方差) |
ACTIVE | 时间量,在变成空闲之前的活跃时间 |
IDLE | 时间量,在变成空闲之前的活跃时间 |
FB PSEC | 每秒流字节数。每秒流量包。持续时间:数据流的持续时间。 |
表1:从[ 1 ]获得的元信息参数
除了这些参数之外,其他基于流的参数也包括在内。图4显示了一个数据集的样例。

图4:本文使用的数据集实例
请注意,源IP/端口、目标IP/端口和协议字段已经从实例中删除,因为它们会导致模型过拟合。我们使用具有N隐藏层的深度前馈神经网络来处理其他所有特征。神经网络的架构如图5所示。
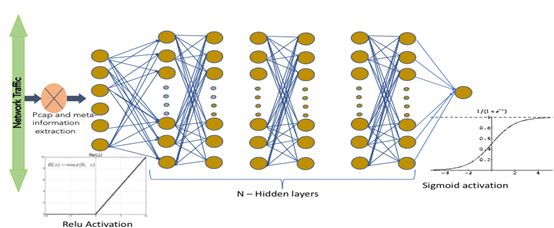
图5:用于Tor流量检测的深度学习网络表示。
隐藏层层数在2和10之间变化。当N=5时是最优的。为了激活,线性整流函数(Rectified Linear Unit, ReLU)用于所有隐藏层。隐藏层每一层实际上都是密集的,有100个维度。
Keras中的FFN的Python代码片段:
model = Sequential()
model.add(Dense(feature_dim, input_dim= feature_dim, kernel_initializer='normal', activation='relu'))
for _ in range(0, hidden_layers-1):
model.add(Dense(neurons_num, kernel_initializer='normal', activation='relu'))
model.add(Dense(1,kernel_initializer='normal', activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=["accuracy"])
输出节点由Sigmoid函数激活。这被用来输出二分类结果-TOR或非TOR。
我们在后端使用带有TensorFlow的Keras来训练深度学习模块。使用二元交叉熵损失来优化FFN。模型会被训练不同次数。图7显示,在一轮仿真训练中,随着训练次数的增加,性能也在增加,损失值也在下降。
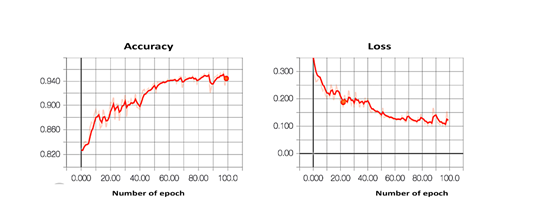
图7:网络训练过程中Tensorboard生成的静态图
我们将深度学习系统的结果与其他预测系统进行了比较。使用召回率(Recall)、精准率(Precision)和F-Score这些标准分类指标来衡量预测系统性能。我们基于深度学习的系统能够很好地检测TOR类。但是,我们更加重视非TOR类。可以看出,基于深度学习的系统可以减少非TOR类的假阳性情况。结果如下表:
Classifier used | Precision | Recall | F-Score |
Logistic Regression | 0.87 | 0.87 | 0.87 |
SVM | 0.9 | 0.9 | 0.9 |
Naïve Bayes | 0.91 | 0.6 | 0.7 |
Random Forest | 0.96 | 0.96 | 0.96 |
Deep Learning | 0.95 | 0.95 | 0.95 |
表2:用于TOR流量检测实验的深度学习和机器学习模型结果
在各种分类器中,随机森林和基于深度学习的方法比其他方法更好。所示结果基于5,500个训练实例。本实验中使用数据集的大小相对小于典型的基于深度学习的系统。随着训练数据的增加,基于深度学习的系统和随机森林分类器的性能将会进一步提升。
但是,对于大型数据集来说,基于深度学习的分类器通常优于其他分类器,并且可以针对相似类型的应用程序进行推广。例如,如果需要训练检测使用TOR的应用程序,那么只需要重新训练输出层,并且其他所有层可以保持不变。而其他机器学习分类器则需要在整个数据集上重新训练。请记住,对于大型数据集来说,重新训练模型需要耗费巨大的计算资源。
尾记
每个企业面临的匿名流量检测的挑战是存在细微差别的。攻击者使用TOR信道以匿名模式偷窃数据。当前流量检测供应商的方法依赖于拦截TOR网络的已知入口节点。这不是一个可拓展的方法,而且很容易绕过。一种通用的方法是使用基于深度学习的技术。
本文中,我们提出了一个基于深度学习的系统来检测TOR流量,具有高召回率和高精准率。请下面的评论部分告诉我们您对当前深度学习状态的看法,或者如果您有其他替代方法。
References
[1]: Quamar Niyaz, Weiqing Sun, Ahmad Y Javaid, and Mansoor Alam, “A Deep Learning Approach for Network Intrusion Detection System,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2018.
[2]: Daniel Gibert, “Convolutional Neural Networks for Malware Classification,” Thesis 2016.
[3]: Wookhyun Jung, Sangwon Kim,, Sangyong Choi, “Deep Learning for Zero-day Flash Malware Detection,” IEEE security, 2017.
[4]: Paweł Kobojek and Khalid Saeed, “Application of Recurrent Neural Networks for User
Verification based on Keystroke Dynamics,” Journal of telecommunications and information technology, 2016.
[5]:Deep Learning Security Papers, http://www.covert.io/the-definitive-security-datascience-and-machinelearning-guide/#deep-learning-and-security-papers, accessed on May 2018.
[6]: “Deep Learning,” Ian Goodfellow, Yoshua Bengio, Aaaron Courville; pp 196, MIT Press, 2016.
[7]: “The Onion Ransomware,” https://www.kaspersky.co.in/resource-center/threats/onion-ransomware-virus-threat, Retrieved on November 29, 2017.
[8]: “5 best alternative to TOR.,” https://fossbytes.com/best-alternatives-to-tor-browser-to-browse-anonymously/, Retrieved on November 29,2017.
[9]: Tor. Wikipedia., https://en.wikipedia.org/wiki/Tor_(anonymity_network), Retrieved on November 24, 2017.
[10]: He, G., Yang, M., Luo, J. and Gu, X., “ Inferring Application Type Information from Tor Encrypted Traffic,” Advanced Cloud and Big Data (CBD), 2014 Second International Conference on (pp. 220-227), Nov. 2014.
[11]: Habibi Lashkari A., Draper Gil G., Mamun M. and Ghorbani A., “Characterization of Tor Traffic using Time based Features,” Proceedings of the 3rd International Conference on Information Systems Security and Privacy – Volume 1, pages 253-262, 2017.
[13]: Juarez, M., Afroz, S., Acar, G., Diaz, C. and Greenstadt, R., “A critical evaluation of website fingerprinting attacks,” Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security (pp. 263-274), November 2014
[14]: Bai, X., Zhang, Y. and Niu, X., “Traffic identification of tor and web-mix,” Intelligent Systems Design and Applications, ISDA’08. Eighth International Conference on (Vol. 1, pp. 548-551). IEEE, November 2008
viumi
原文标题:
Using the Power of DeepLearning for Cyber Security
原文链接:
https://www.analyticsvidhya.com/blog/2018/07/using-power-deep-learning-cyber-security/
译者简介:张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无境,数据工作充满挑战。感谢数据派THU提供如此专业的平台,希望在这里能和最专业的你们共同进步!
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。









