
作者:Eric Le Fort
翻译:蒋雨畅
校对:卢苗苗
本文约3200字,建议阅读12分钟。
本文将通过介绍两个分布模型,并运用它们到合成数据过程中,来分析合成数据在不同机器学习技术下的表现。
想法
相比于数量有限的“有机”数据,我将分析、测评合成数据是否能实现改进。
动机
我对合成数据的有效性持怀疑态度——预测模型只能与用于训练数据的数据集一样好。这种怀疑论点燃了我内心的想法,即通过客观调查来研究这些直觉。
需具备的知识
本文的读者应该处于对机器学习相关理论理解的中间水平,并且应该已经熟悉以下主题以便充分理解本文:
合成数据的背景
生成合成数据的两种常用方法是:
在这项研究中,我们将检查第一类。为了巩固这个想法,让我们从一个例子开始吧!
想象一下,在只考虑大小和体重的情况下,你试图确定一只动物是老鼠,青蛙还是鸽子。但你只有一个数据集,每种动物只有两个数据。因此不幸的是,我们无法用如此小的数据集训练出好的模型!
这个问题的答案是通过估计这些特征的分布来合成更多数据。让我们从青蛙的例子开始
参考这篇维基百科的文章:
https://en.wikipedia.org/wiki/Common_frog ,只考虑成年青蛙。
第一个特征,即它们的平均长度(7.5cm±1.5cm),可以通过从正态分布中绘制平均值为7.5且标准偏差为1.5的值来生成。类似的技术可用于预测它们的重量。然而,我们所掌握的信息并不包括其体重的典型范围,只知道平均值为22.7克。一个想法是使用10%(2.27g)的任意标准偏差。不幸的是,这只是纯粹猜测的结果,因此很可能不准确。
鉴于与其特征相关信息的可获得性,和基于这些特征来区分物种的容易程度,这可能足以培养良好的模型。但是,当您迁移到具有更多特征和区别更细微的陌生系统时,合成有用的数据变得更加困难。
数据
该分析使用与上面讨论的类比相同的想法。我们将创建一些具有10个特征的数据集。这些数据集将包含两个不同的分类类别,每个类别的样本数相同。
“有机”数据
每个类别将遵循其中每个特征的某种正态分布。例如,对于第一种特征:第一个类别样本的平均值为1500,标准差为360;第二个类别样本的平均值为1300,标准差为290。其余特征的分布如下:
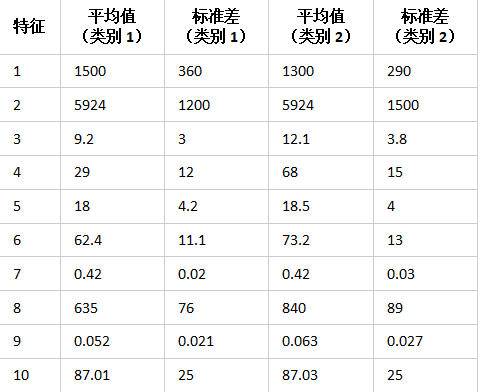
该表非常密集,但可以总结为:
创建两个这样的数据集,一个1000样本的数据集将保留为验证集,另一个1000样本的数据集可用于训练/测试。
这会创建一个数据集,使分类变得足够强大。
合成数据
现在事情开始变得有趣了!合成数据将遵循两个自定义分布中的其中一个。第一个我称之为“ Spikes Distribution”。此分布仅允许合成特征采用少数具有每个值的特定概率的离散值。例如,如果原始分布的平均值为3且标准差为1,则尖峰(spike)可能出现在2(27%),3(46%)和4(27%)。
第二个自定义分布我称之为“ Plateaus Distribution”。这种分布只是分段均匀分布。使用平台中心的正态分布概率推导出平稳点的概率。您可以使用任意数量的尖峰或平台,当添加更多时,分布将更接近正态分布。
为了清楚说明这两个分布,可以参考下图:

(注:尖峰分布图不是概率密度函数)
在这个问题中,合成数据的过程将成为一个非常重要的假设,它有利于使合成数据更接近于“有机”数据。该假设是每个特征/类别对的真实平均值和标准差是已知的。实际上,如果合成数据与这些值相差太远,则会严重影响训练模型的准确性。
好的,但为什么要使用这些分布?他们如何反映现实?
我很高兴你问这个问题!在有限的数据集中,您可能会注意到,对于某个类别,某个特征只会占用少量值。想象一下这些值是:
(50,75,54,49,24,58,49,64,43,36)
或者如果我们可以对这列进行排序:
(24,36,43,49,49,50,54,58,64,75)
为了生成此特征的数据,您可以将其拆分为三个部分,其中第一部分将是最小的20%,中间的60%将是第二部分,第三部分将是最大的20%。然后使用这三个部分,您可以计算它们的平均值和标准差:分别为(30,6.0),(50.5,4.6)和(69.5,5.5)。如果标准差相当低,比如大约为相应均值的10%或更小,则可以将该均值视为该部分的尖峰值。否则,您可以将该部分视为一个平台,其宽度是该部分标准差的两倍,并以该部分的平均值作为中心。
或者,换句话说,他们在模拟不完美的数据合成方面做得不错。
我将使用这些分布创建两个800样本数据集 - 一个使用尖峰,另一个使用平台。四个不同的数据集将用于训练模型,以便比较每个数据集的有用性:
完整 (Full) - 完整的1000个样本有机数据集(用于了解上限)
真实 (Real) - 只有20%的样本有机数据集(模拟情况而不添加合成数据)
尖峰(Spike) - “真实”数据集与尖峰数据集相结合(1000个样本)
平台(Plateaus) - “真实”数据集与平台数据集相结合(1000个样本)
现在开始令人兴奋的部分!
训练
为了测试每个数据集的强度,我将采用三种不同的机器学习技术:多层感知器(MLP),支持向量机(SVM)和决策树(Decision Trees)。为了帮助训练,由于某些特征的幅度比其他特征大得多,因此利用特征缩放来规范化数据。使用网格搜索调整各种模型的超参数,以最大化到达最好的超参数集的概率。
总之,我在8个不同的数据集上训练了24种不同的模型,以便了解合成数据对学习效果的影响。
相关代码在这里:https://github.com/EricLeFort/DataGen
结果
经过几个小时调整超参数并记录下精度测量结果后,出现了一些反直觉的结果!完整的结果集可以在下表中找到:
多层感知器(MLP)

支持向量机(SVM)

决策树(Decision Trees)

在这些表中,“Spike 9”或“Plateau 9”是指分布和使用的尖峰/平台的数量。单元格中的值是使用相应的训练/测试数据对模型进行训练/测试,并用验证集验证后的的最终精度。还要记住,“完整”(Full)类别应该是准确性的理论上限,“真实”(Rea;)类别是我们在没有合成数据的情况下可以实现的基线。
一个重要的注意事项是,(几乎)每次试验的训练/测试准确度都明显高于验证准确度。例如,尽管MLP在Spike-5上得分为97.7%,但在同一试验的训练/测试数据上分别得分为100%和99%。当在现实世界中使用时,这可能导致模型有效性的过高估计。
完整的这些测量可以在GitHub找到:
https://github.com/EricLeFort/DataGen
让我们仔细看看这些结果。
首先,让我们看一下模型间的趋势(即在所有机器学习技术类型中的合成数据集类型的影响)。似乎增加更多尖峰/平台并不一定有助于学习。你可以看到在3对 5时尖峰/平台之间的一般改善,但是当看到5对9时,则要么变平或稍微倾斜。
对我来说,这似乎是违反直觉的。随着更多尖峰/平台的增加,我预计会看到几乎持续的改善,因为这会导致分布更类似于用于合成数据的正态分布。
现在,让我们看一下模型内的趋势(即各种合成数据集对特定机器学习技术的影响)。对于MLP来说,尖峰或平台是否会带来更好的性能似乎缺少规律。对于SVM,尖峰和平台似乎表现得同样好。然而,对于决策树而言,平台是一个明显的赢家。
总的来说,在使用合成数据集时,始终能观察到明显的改进!
以后的工作
需要注意的一个重要因素是,本文的结果虽然在某些方面有用,但仍然具有相当的推测性。因此,仍需要多角度的分析以便安全地做出任何明确的结论。
这里所做的一个假设是每个类别只有一个“类型”,但在现实世界中并不总是如此。例如,杜宾犬和吉娃娃都是狗,但它们的重量分布看起来非常不同。
此外,这基本上只是一种类型的数据集。应该考虑的另一个方面是尝试类似的实验,除了具有不同维度的特征空间的数据集。这可能意味着有15个特征而不是10个或模拟图像的数据集。
我计划继续研究以扩大本研究的范围,敬请期待!
关于作者
Eric拥有软件工程学士学位和机器学习硕士学位。他目前在加拿大多伦多担任机器学习工程师。他曾使用LSTM,CNN,决策树集合,SVM等工作解决与NLP,计算机视觉和商业智能系统相关的问题!
如果您想了解更多关于他的信息,请浏览他的网站(http://ericlefort.ca/ )
原文标题:
My Thoughts on Synthetic Data
原文链接:
https://www.codementor.io/ericlefort/my-thoughts-on-synthetic-data-kq719a5ss
蒋雨畅,香港理工大学大三在读,主修地理信息,辅修计算机科学,目前在研究学习通过数据科学等方法探索城市与人类活动的关系。希望能认识更多对数据科学感兴趣的朋友,了解更多前沿知识,开拓自己的眼界。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织










