
利用 spaCy 和一点点 Cython 给 NLP 加速。
自去年发布 Python 的指代消解包(coreference resolution package)之后,很多用户开始用它来构建许多应用程序,而这些应用与我们最初的对话应用完全不同。
我们发现,尽管在处理对话时这个包的速度完全没问题,但在处理较大的问题时却非常慢。
我决定调查一下这个问题,于是就产生了
NeuralCoref v3.0(https://github.com/huggingface/neuralcoref/)这一项目,它比上一个版本快 100 倍(每秒能分析几千个单词),同时保持准确度、易用性,并且依然在 Python 库的生态系统中。
在本文中我想分享一些在这个项目中学习到的经验,具体来说包括:
• 怎样用 Python 设计高速的模块;
• 怎样利用 spaCy 的内部数据结构来有效地设计高速的 NLP 函数。
• 所以其实这里有点耍花招,虽然我们是在讨论 Python,但还要用一些 Cython的魔法。但别忘了,Cython 是 Python 的超集(http://cython.org/),所以别被它吓住了!
你现在的 Python 程序已经是 Cython 程序了。
几种情况下你可能会需要这种加速,例如:
• 用 Python 为生产环境开发 NLP 模块;
• 用 Python 在大型 NLP 数据集上计算分析结果;
为 pyTorch 或 TensorFlow 等深度学习框架预处理一个大型数据集,或者在深度学习的批次加载器中有个很复杂的处理逻辑使得训练变慢。
在我们开始前要说的最后一件事:这篇文章里的例子我都放在了Jupyter Notebook(https://github.com/huggingface/100-times-faster-nlp)上。试试看吧!
加速的第一步:性能分析
首先要明确一点,绝大部分纯 Python 的代码是没有问题的,但有几个瓶颈函数如果能够解决,就能给速度带来数量级上的提升。
因此首先应该用分析工具分析 Python 代码,找出哪里慢。一个办法是使用cProfile(https://docs.python.org/3/library/profile.html):
import cProfile
import pstats
import my_slow_module
cProfile.run(‘my_slow_module.run()’, ‘restats’)
p = pstats.Stats(‘restats’)
p.sort_stats(‘cumulative’).print_stats(30)
也许你会发现有几个循环比较慢,如果用神经网络的话,可能有几个 Numpy 数组操作会很慢(但这里我不会讨论如何加速 NumPy,已经有很多文章讨论这个问题了:
http://cython.readthedocs.io/en/latest/src/userguide/numpy_tutorial.html)。
那么,应该如何加快循环的速度?
利用 Cython 实现更快的循环
用个简单的例子来说明。假设我们一个巨大的集合里包含许多长方形,保存为 Python 对象(即 Rectangle 类的实例)的列表。模块的主要功能就是遍历该列表,数出有多少个长方形超过了某个阈值。
我们的 Python 模块非常简单,如下所示:
from random import random
class Rectangle:
def __init__(self, w, h):
self.w = w
self.h = h
def area(self):
return self.w * self.h
def check_rectangles(rectangles, threshold):
n_out = 0
for rectangle in rectangles:
if rectangle.area() > threshold:
n_out += 1
return n_out
def main():
n_rectangles = 10000000
rectangles = list(Rectangle(random(), random()) for i in range(n_rectangles))
n_out = check_rectangles(rectangles, threshold=0.25)
print(n_out)
这里 check_rectangles 函数就是瓶颈!它要遍历大量 Python 对象,而由于每次循环中 Python 解释器都要在背后进行许多工作(如在类中查找 area 方法、打包解包参数、调用 Python API 等),这段代码就会非常慢。
这里 Cython 能帮我们加快循环。
Cython 语言是 Python 的一个超集,它包含两类对象:
• Python 对象是在正常的 Python 中操作的对象,如数字、字符串、列表、类实例等。
• Cython C 对象是 C 或 C++ 对象,如 dobule、int、float、struct、vectors,这些可以被 Cython 编译成超级快的底层代码。
• 高速循环就是 Cython 程序中只访问 Cython C 对象的循环。
设计这种高速循环最直接的办法就是,定义一个 C 结构,它包含计算过程需要的一切。在这个例子中,该结构需要包含长方形的长和宽。
然后我们就可以将长方形列表保存在一个 C 数组中,传递给 check_rectangle 函数。现在该函数就需要接收一个 C 数组作为输入,因此它应该用 cdef 关键字(而不是 def)定义为 Cython 函数。(注意 cdef 也被用来定义 Cython C 对象。)
下面是 Cython 高速版本的模块:
from cymem.cymem cimport Pool
from random import random
cdef struct Rectangle:
float w
float h
cdef int check_rectangles(Rectangle* rectangles, int n_rectangles, float threshold):
cdef int n_out = 0
# C arrays contain no size information => we need to give it explicitly
for rectangle in rectangles[:n_rectangles]:
if rectangle[i].w * rectangle[i].h > threshold:
n_out += 1
return n_out
def main():
cdef:
int n_rectangles = 10000000
float threshold = 0.25
Pool mem = Pool()
Rectangle* rectangles = mem.alloc(n_rectangles, sizeof(Rectangle))
for i in range(n_rectangles):
rectangles[i].w = random()
rectangles[i].h = random()
n_out = check_rectangles(rectangles, n_rectangles, threshold)
print(n_out)
这里用了个 C 指针数组,不过你也可以用别的方式,如 vectors、pairs、queues 等 C++ 结构
(http://cython.readthedocs.io/en/latest/src/userguide/wrapping_CPlusPlus.html#standard-library)。在这段代码中,我还使用了
cymem(https://github.com/explosion/cymem)提供的方便的 Pool() 内存管理对象,这样就不用手动释放 C 数组了。在 Python 对 Pool 进行垃圾回收时,就会自动释放所有通过 Pool 分配的内存。
关于在 NLP 中使用 Cython 的指南请参考 spaCy API 的 Cython Conventions:https://spacy.io/api/cython#conventions。
试一下这段代码
有许多方法可以测试、编译并发布 Cython 代码!Cython 甚至可以像 Python 一样直接用在 Jupyter Notebook 中
(http://cython.readthedocs.io/en/latest/src/reference/compilation.html#compiling-notebook)。
首先用 pip install cython 安装 Cython:
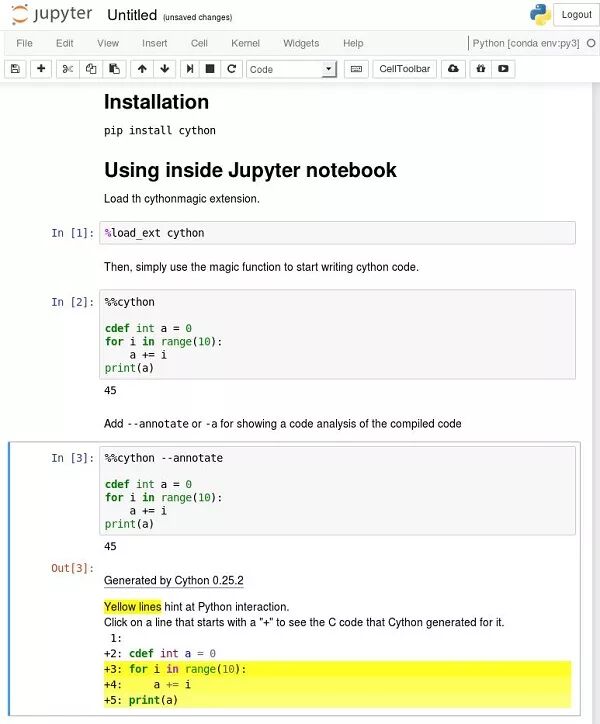
在 Jupyter 中测试
在 Jupyter notebook 中通过 %load_ext Cython 加载 Cython 扩展。
现在,只需使用魔术命令
(http://cython.readthedocs.io/en/latest/src/reference/compilation.html#compiling-with-a-jupyter-notebook)%%cython 就可以像写 Python 代码一样写 Cython 代码了。
如果在执行 Cython 单元的时候遇到编译错误,可以在 Jupyter 的终端输出上看到完整的错误信息。
一些常见的错误:如果要编译成 C++(比如使用 spaCy Cython API),需要在 %%cython 后面加入 -+ 标记;如果编译器抱怨 NumPy,需要加入 import numpy 等。
编写、使用并发布 Cython 代码
Cython 代码保存在 .pyx 文件中。这些文件会被 Cython 编译器编译成 C 或 C++ 文件,然后再被系统的 C 编译器编译成字节码。这些字节码可以直接被 Python 解释器使用。
可以在 Python 中使用 pyximport 直接加载 .pyx 文件:
>>> import pyximport; pyximport.install()
>>> import my_cython_module
也可以将Cython代码构建成Python包,并作为正常的Python包导入或发布(详细说明在此:
http://cython.readthedocs.io/en/latest/src/tutorial/cython_tutorial.html#)。
这项工作比较花费时间,主要是要处理所有平台上的兼容性问题。如果需要示例的话,spaCy 的安装脚本
(https://github.com/explosion/spaCy/blob/master/setup.py)就是个很好的例子。
在进入 NLP 之前,我们先快速讨论下 def、cdef 和 cpdef 关键字,这些是学习 Cython 时最关键的概念。
Cython 程序中包含三种函数:
• Python 函数,由关键字 def 定义。它的输入和输出都是 Python 对象。内部可以使用 Python 对象,也可以使用 C/C++ 对象,也可以调用 Cython 函数和 Python 函数。
• Cython 函数,用 cdef 关键字定义。Python 对象和 Cython 对象都可以作为它的输入、输出和内部对象使用。这些函数无法在 Python 空间(即 Python 解释器,和其他需要导入 Cython 模块的纯 Python 模块)中直接访问,但可以被其他 Cython 模块导入。
• 用 cpdef 定义的 Cython 函数,类似于用 cdef 定义的 Cython 函数,但它们还提供了 Python 封装,因此可以直接在 Python 空间中调用(用 Python 对象作为输入和输出),也可以在其他 Cython 模块中调用(用 C/C++ 或 Python 对象作为输入)。
cdef 关键字还有个用法,就是在代码中给 Cython C/C++ 对象定义类型。没有用 cdef 定义类型的对象会被当做 Python 对象处理(因此会降低访问速度)。
通过 spaCy 使用 Cython 加速 NLP
前面说的这些都很好……但这跟 NLP 还没关系呢!没有字符串操作,没有 Unicode 编码,自然语言处理中的难点都没有支持啊!
而且 Cython 的官方文档甚至还反对使用 C 语言级别的字符串
(http://cython.readthedocs.io/en/latest/src/tutorial/strings.html):
• 一般来说,除非你知道你在做什么,否则尽量不要使用 C 字符串,而应该使用 Python 字符串对象。
• 那在处理字符串时怎样才能设计高速的 Cython 循环?
这就轮到 spaCy 出场了。
spaCy 解决这个问题的办法特别聪明。
将所有字符串转换成 64 比特 hash
在 spaCy 中,所有 Unicode 字符串(token 的文本,token 的小写形式,lemma 形式,词性标注,依存关系树的标签,命名实体标签……)都保存在名为 StringStore 的单一数据结构中,字符串的索引是 64 比特 hash,也就是 C 语言层次上的 unit64_t。
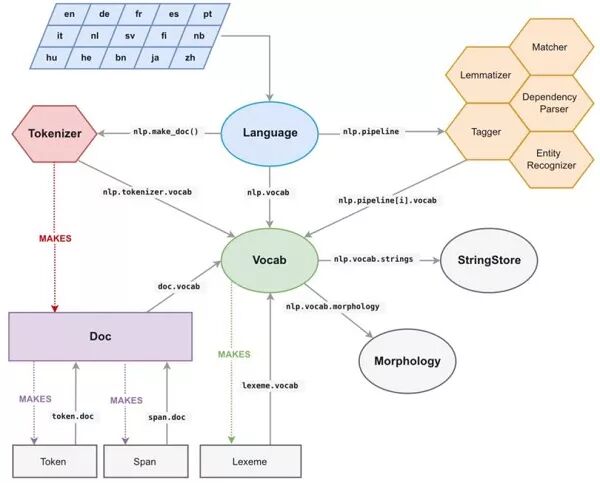
StringStore 对象实现了在 Python unicode 字符串和 64 比特 hash 之间的查找操作。
StringStore 可以从 spaCy 中的任何地方、任何对象中访问,例如可以通过 nlp.vocab.string、doc.vocab.strings 或 span.doc.vocab.string 等。
当模块需要在某些 token 上进行快速处理时,它只会使用 C 语言层次上的 64 比特 hash,而不是使用原始字符串。调用 StringStore 的查找表就会返回与该 hash 关联的 Python unicode 字符串。
但是 spaCy 还做了更多的事情,我们可以通过它访问完整的 C 语言层次上的文档和词汇表结构,因此可以使用 Cython 循环,不需要再自己构建数据结构。
spaCy 的内部数据结构
spaCy 文档的主要数据结构是 Doc 对象,它拥有被处理字符串的 token 序列(称为 words)及所有注解(annotation),这些被保存在一个 C 语言对象 doc.c 中,该对象是个 TokenC 结构的数组。
TokenC(https://github.com/explosion/spaCy/blob/master/spacy/structs.pxd)结构包含关于 token 的所有必要信息。这些信息都保存为 64 比特 hash 的形式,可以通过上面的方法重新构成 unicode 字符串。
看看 spaCy 的 Cython API 文档,就知道这些 C 结构的好处在哪里了。
我们通过一个简单例子看看它在 NLP 处理中的实际应用。
通过 spaCy 和 Cython 进行快速 NPL 处理
假设我们有个文本文档的数据集需要分析。
import urllib.request
import spacy
with urllib.request.urlopen(‘https://raw.githubusercontent.com/pytorch/examples/master/word_language_model/data/wikitext-2/valid.txt’) as response:
text = response.read()
nlp = spacy.load(‘en’)
doc_list = list(nlp(text[:800000].decode(‘utf8’)) for i in range(10))
上面的脚本建立了一个由10个spaCy解析过的文档组成的列表,每个文档大约有17万个词。也可以使用17万个文档,每个文档有10个词(比如对话的数据集),但那样创建速度就会慢很多,所以还是继续使用10个文档好了。
我们要在这个数据集上做一些NLP的处理。比如,我们需要计算“run”这个词在数据集中作为名词出现的次数(即被spaCy的词性分析(Part-Of-Speech)标记为“NN”的词)。
Python 循环的写法很直接:
def slow_loop(doc_list, word, tag):
n_out = 0
for doc in doc_list:
for tok in doc:
if tok.lower_ == word and tok.tag_ == tag:
n_out += 1
return n_out
def main_nlp_slow(doc_list):
n_out = slow_loop(doc_list, ‘run’, ‘NN’)
print(n_out)
但也非常慢!在我的笔记本上这段代码大概需要1.4秒才能得到结果。如果有100万个文档,那就要超过一天的时间。
我们可以使用多任务处理,但在Python中通常并不是个好主意
(https://youtu.be/yJR3qCUB27I?t=19m29s),
因为你得处理GIL(全局解释器锁,
https://wiki.python.org/moin/GlobalInterpreterLock)!
而且,别忘了Cython也支持多线程
(https://cython.readthedocs.io/en/latest/src/userguide/parallelism.html)!而且实际上多线程才是Cython最精彩的部分,因为GIL锁已经被释放,代码可以全速运行了。基本上,Cython会直接调用OpenMP。这里不会介绍并行,更多的细节可以参考这里
(https://cython.readthedocs.io/en/latest/src/userguide/parallelism.html)。
现在试着用 spaCy 和一点 Cython 加速 Python 代码吧。
首先需要考虑下数据结构。我们需要个C层次的数组来保存数据集,其中的指针指向每个文档的TokenC数组。还需要将测字符串(“run”和“NN”)转换成64比特hash。
下面是用spaCy编写的Cython代码:
%%cython -+
import numpy # Sometime we have a fail to import numpy compilation error if we don’t import numpy
from cymem.cymem cimport Pool
from spacy.tokens.doc cimport Doc
from spacy.typedefs cimport hash_t
from spacy.structs cimport TokenC
cdef struct DocElement:
TokenC* c
int length
cdef int fast_loop(DocElement* docs, int n_docs, hash_t word, hash_t tag):
cdef int n_out = 0
for doc in docs[:n_docs]:
for c in doc.c[:doc.length]:
if c.lex.lower == word and c.tag == tag:
n_out += 1
return n_out
def main_nlp_fast(doc_list):
cdef int i, n_out, n_docs = len(doc_list)
cdef Pool mem = Pool()
cdef DocElement* docs = mem.alloc(n_docs, sizeof(DocElement))
cdef Doc doc
for i, doc in enumerate(doc_list): # Populate our database structure
docs[i].c = doc.c
docs[i].length = (doc).length
word_hash = doc.vocab.strings.add(‘run’)
tag_hash = doc.vocab.strings.add(‘NN’)
n_out = fast_loop(docs, n_docs, word_hash, tag_hash)
print(n_out)
这段代码有点长,因为得在调用Cython函数之前,在main_nlp_fast中定义并填充C结构。(注:如果在代码中多次使用低级结构,就不要每次填充C结构,而是设计一段Python代码,利用Cython扩展类型
(http://cython.readthedocs.io/en/latest/src/userguide/extension_types.html)来封装C语言的低级结构。spaCy的绝大部分数据结构都是这么做的,能优雅地结合速度、低内存占用,以及与外部Python库和函数的接口的简单性。)
但它也快得多!在我的Jupyter notebook上,这段Cython代码只需要大约20毫秒,比纯Python循环快大约80倍。
要知道它只是Jupyter notebook单元中的一个模块,还能给其他Python模块和函数提供原生的接口,考虑到这一点,它的绝对速度也相当出色:20毫秒内扫描1700万词,意味着每秒能扫描八千万词。
这就是在 NLP 中使用 Cython 的方法,希望你能喜欢。
相关资料
Cython入门教程:
http://cython.readthedocs.io/en/latest/src/tutorial/index.html
spaCy 的 Cython 页面:https://spacy.io/api/cython
英文:100 Times Faster Natural Language Processing in Python
链接:
https://medium.com/huggingface/100-times-faster-natural-language-processing-in-python-ee32033bdced
作者:Thomas Wolf,Huggingface的机器学习,自然语言处理和深度学习科学负责人。
识别下图二维码,加“数盟社区”为好友,回复暗号“入群”,加入数盟社区交流群,群内持续有干货分享~~
本周干货:Deep Reinforcement LearningWhat’s Next in AI

媒体合作请联系:
邮箱:xiangxiaoqing@stormorai.com







