时隔三个月,MySQL 8.0.12 有什么新内容?
今年4月份,MySQL突然直接从8.0.5跳过多个版本号到8.0.11,直接宣布8.0.11 GA,告诉大家说,这个版本已经可以到线上用了。
到今年7月底,MySQL 8.0.12版本发布,我从官方的release note里面,选取出来我认为的重点内容,在这里展开聊一下。
如果有想要看全文的人,可以直接去看官方的发布内容:
https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-12.html
filesort 算法的缓存设置优化
众所周知,MySQL 在处理 Order by 的时候,如果没有索引可以用,会采用一个名为 file sort 的算法排序,但和这个算法有一个关联的参数, sort_buffer_size,估计很多人都知道这个参数,这个参数在之前有个算是比较蛋疼的问题:如果 sql 会话中,执行 sql 需要进行file sort,那么 mysql 就会给当前回话直接分配 sort_buffer_size大小的内存出来。
这个乍一看没啥问题,但需要注意的是,在 MySQL 中,没办法像 Oracle 那样统一管理 PGA(用户线程/进程消耗的总内存大小),遇到那种恰好会话数量比较多,filesort 比较多(哪怕SQL语句单拎出来性能没啥问题),sql 查询量比较大的情况,就非常容易让 MySQL 的内存使用量超标被操作系统 OOM 了。
或者如果你有习惯设置 swap 空间,那么巨慢的 swap 会拖死整个机器,只能挥泪重启,类似这种事故,在互联网业务中,并不鲜见,也间接导致了很多人非常厌恶 file sort,哪怕多加几条索引,也要全覆盖式地处理掉所有 file sort。
但现在,这个内存分配机制总算改变了,从 8.0.12 开始,这个内存分配变成了按需分配。也就是说,对于排序量非常小的 sql(比如某个人的微博列表)这种,触发了file sort,就再也不会直接分配 sort_buffer_size(默认256KB)的大小了,而是分配很小的内存出来用,某种程度上可以避免了很多突发性流量导致的事故。
rewrite插件支持DML语句
MySQL 从 5.7 开始,新增了一个 plugin 的接口,rewrite,用于在服务器接受 SQL 语句后,执行前修改 SQL 语句,最初只是支持 select,从 8.0.12 开始,支持了 insert,update,replace 这些 DML 语句。
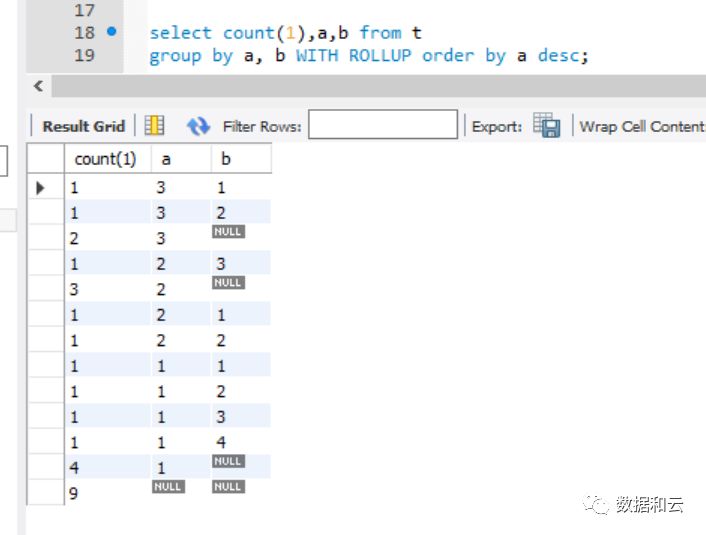
SELECT ORDER BY与GROUP BY语法变更
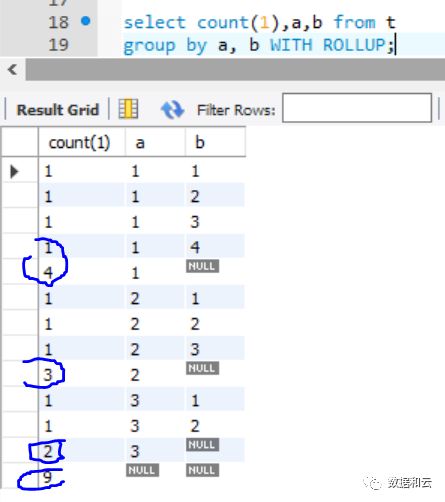
8.0.12,8.0.13(未发布版本,但文档中已经更新内容)开始,MySQL 的 Order by 支持 GROUPING函数 以及 WITH ROLLUP语法,然后,在8.0.13开始,废弃掉group gy 中的desc,asc关键字,对于 WITH ROLLUP 得到的结果集合的排序,需要使用order by 语法。
对于搞数据聚合比较多的人来说,WITH ROLLUP 与 GROUPING 应该不算陌生,这个语法变更,相当于是把 order by 的语法补全完整,更兼容 SQL 标准语法了,如果迁移程序到 8.0,需要注意这种不兼容的变更。
顺带一提,官方文档此处写的是小写的 grouping,但实际上指的是 GROUPING函数 而非普通聚合函数(普通聚合函数一直是支持的)。参考代码:
https://github.com/mysql/mysql-server/commit/d401baf535a69d6f2a945229acecbfd5863c0a48
测试表数据
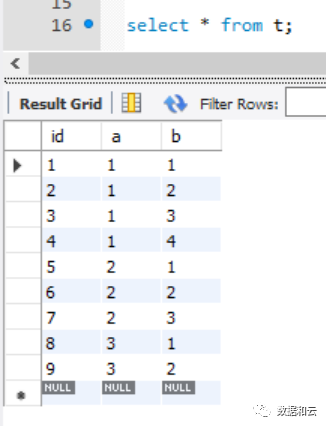
With rollup语法:
8.0.12 之前(测试版本为 5.7.22),如果想要排序,会出现语法错误:
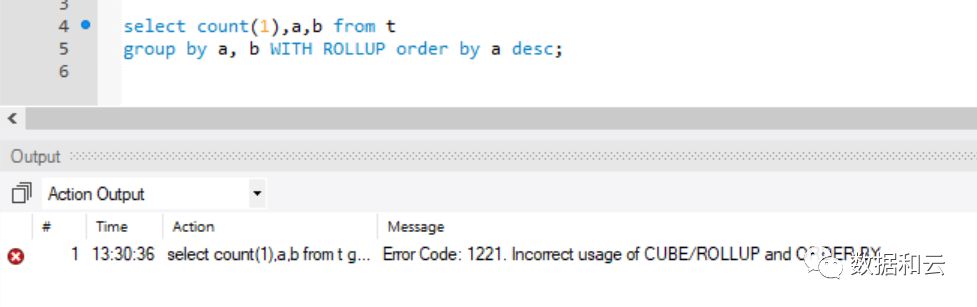
需要写为(排序关键字写到 group by 里面):
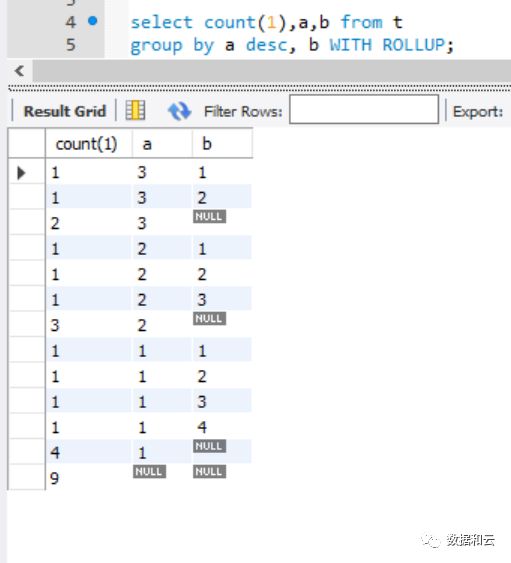
8.0.12 开始可以执行并排序(为了显著效果增加了desc 关键字):
Group Replication继续优化
新增了参数 group_replication_exit_state_action 来控制,如果一个实例发现自己属于被抛弃(网络分区发生后的少数派)的实例的情况下,这个值默认为ABORT_SERVER,也就是说,少数派会自己关闭,这个值也可以设置为 READ_ONLY,这个设置下,会以只读(设置super read only)的形式加入集群,并设置状态为 ERROR。
InnoDB Alter Table优化
这个可以说是一个源远流长的故事,简单来说,就是腾讯游戏部门的 DBA 们,为了数据库快速加列(游戏运营先天的快速变更问题),写了补丁出来用(非常早年的时候),后来这个补丁逐渐被各个第三方发行版接受,现在终于进入官方发布版,让更多的人受益。
MySQL 的 DDL一直是非常出名的问题,社区与官方都在这个问题上投入了很大的精力,从最早 percona 的 toolkit 里面带的 pt-osc(这个基于触发器实现的在线改表,由于 MySQL 早年单表只支持一个触发器,为了避免无法使用 pt-osc,有了早年一直流传到现在的 MySQL重大守则之一:不许使用触发器),到 github 发布的 gh-ost(基于 row 格式 binlog),官方也一直在搞 alter 相关的在线修改优化(比如加索引等操作,参考链接 https://dev.mysql.com/doc/refman/8.0/en/innodb-create-index-overview.html)。
alter table 的 inplace 算法,实质上解决的,是主库 DDL 不会导致读写锁表,但对于主从结构,当 SQL 传输到从库执行的时候,从库依然会有相当大的延迟出现。因此实际上,对于延迟敏感性业务,依然是前面提到那俩工具的天下。
8.0.12的优化是,新增了一个算法 ALGORITHM=INSTANT,专门处理只需要修改元数据就可以完成的变更,这个就可以相对比较方便地直接使用了,不需要担心从库延迟。
目前支持的操作是:
添加新列。已知限制条件如下:
不能与其他不支持INSTANT算法的alter子语句合并在一起。
只能添加在表列的末尾。
不能用于innodb的压缩表(ROW_FORMAT=COMPRESSED)。
目标表不能包含全文索引。
目标表不能是临时表。
目标表不能是数据字典表。
这种添加方式下,不会计算行长度是否合适,这个计算会在发生insert或者update的时候处理。
2. 添加或者删除虚拟列。
3. 添加或者去掉列的默认值。
4. 修改 enum,set 列类型的定义(题外话,有多少人知道并在用这个?)
5. 修改索引类型。
6. 重命名表名称。
binlog支持管道输入
对于大个头 binlog 的处理,由于 MySQL mysqlbinlog 程序之前是不支持管道的,只能先解压,之后再处理。从 8.0.12 开始,mysqlbinlog支持管道输入了,简单来说,就是下面这么一回事:
gzip -cd binlog-files_1.gz | ./mysqlbinlog - | ./mysql -uroot -p
当一条drop 语句里面包含了关联的父子表,则会直接删除,不在额外要求父子表顺序正确
如题,对于每次删表都需要关闭外键检查的人来说,无疑是个好消息。
MySQL 外键关联删表:
8.0,版本中,普通情况下,删除父表:
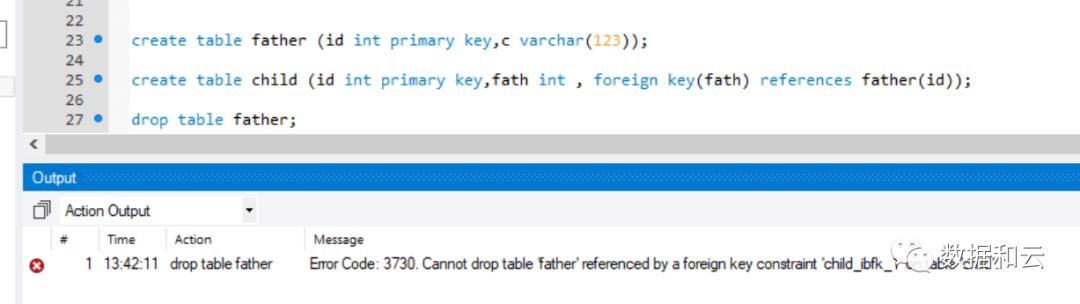
报错 3730
在更早的版本(5.7)中:
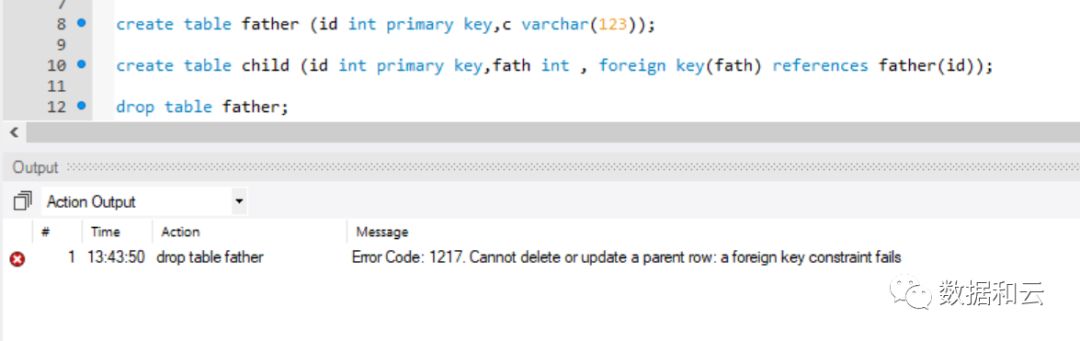
可以看出错误信息,在 8.0 开始更加详细了。
如果执行 drop table father,child:
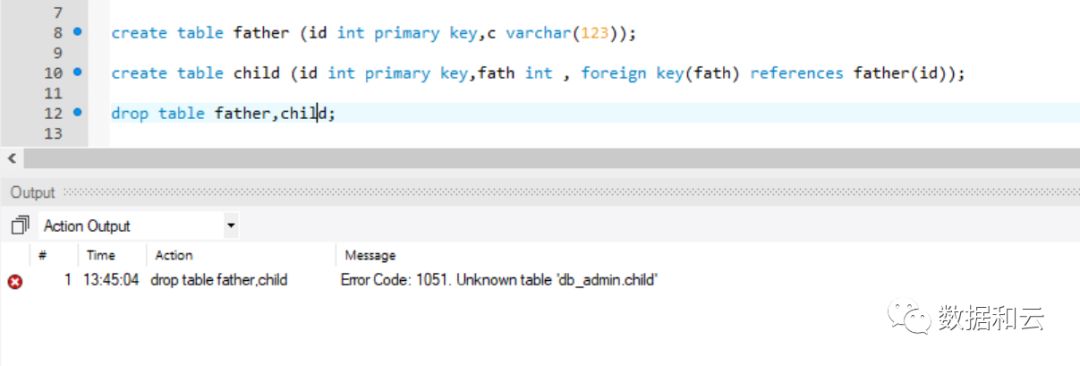
必须写成:
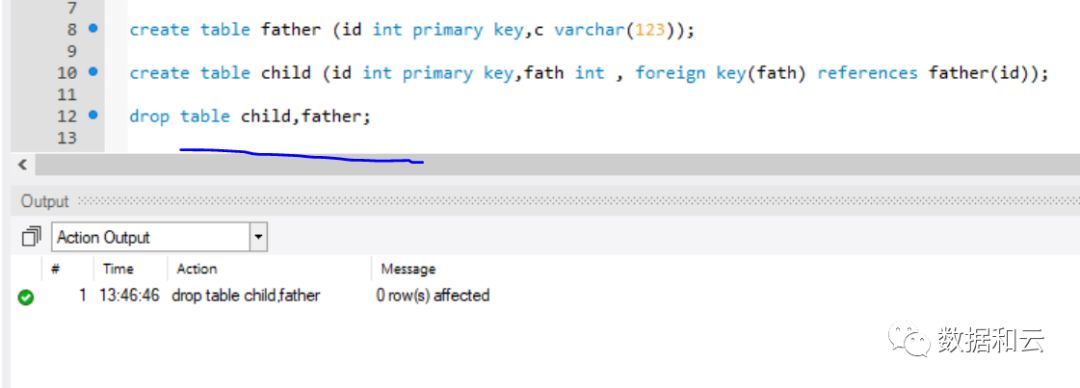
但是,在 8.0.12 开始:
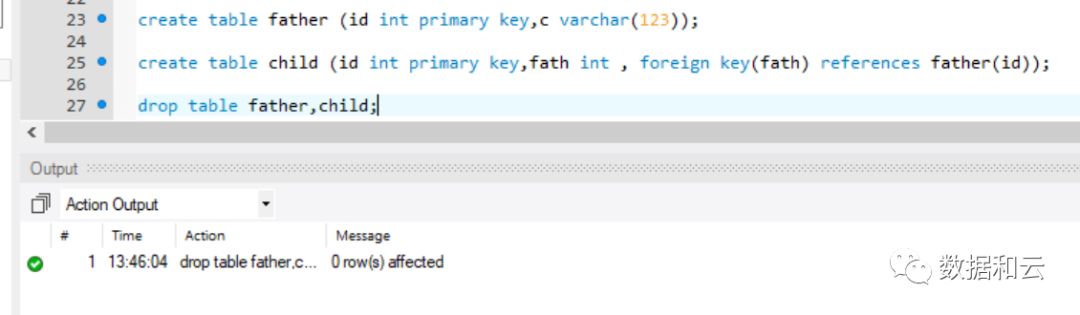
ADMIN成为关键字
以后 SQL 字段又少了一个常用的词哎=_=。
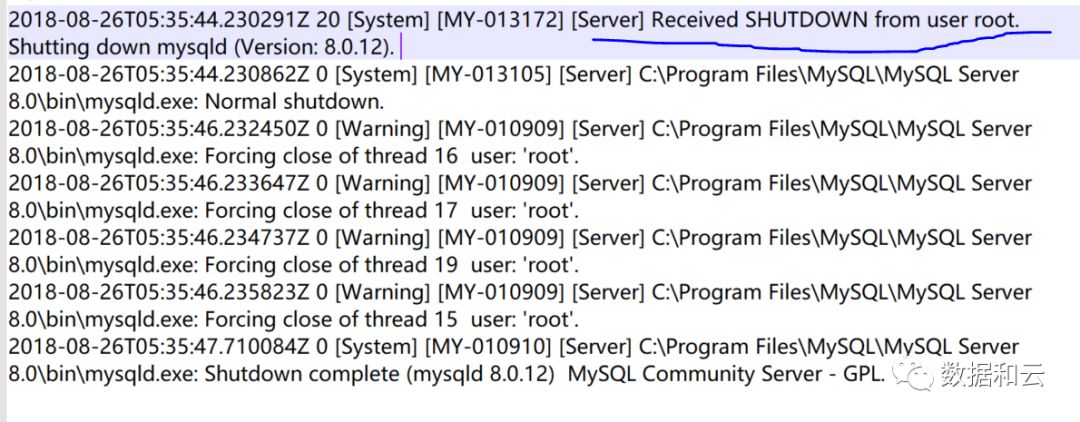
是谁关闭了数据库?
MySQL 终于会在日志里面记录,是谁发的 shutdown 命令了。
MySQL 关闭数据库:
那些或许很好玩的bug
下面是从 bugfix 记录中,找的一些好玩被修复的内容,注意——由于每个人笑点不同,如果只关注新特性修改的话,下面的内容不看就不看了。
早前宣布的新事务模型 VATS,由于其需要追踪所有等待其他事务的事务数量,为了避免死锁,目前被修改为生成出来的近似值。
gtid_purge(记录那些gtid事务已经被purge掉)的值,在Group Replication 运行期间,应该是不能被修改的,然而现在发现它是可以修改的,因此改为在 group replication 运行时候不能修改。
当 expire_logs_days 与 binlog_expire_logs_seconds 参数都设置的情况下,如果设置了 skip-log-bin ,现在开始这个信息会被写入错误日志。
当有超大事务执行(binlog 量超过 binlog_cache_size)的时候,在刷出到临时文件期间,如果遇到磁盘满导致的刷出失败,事务回滚,这个信息没有被记录在错误日志里面,并且,事务回滚后,缓存也不会被清空。
SUPER 权限的用户,没办法修改 keyring_operations 参数。
It was possible to drop the Performance Schema. 哈哈哈哈哈。
slave_rows_search_algorithms 指定了 row 格式复制时候,行匹配的的方式,指定为 INDEX_SCAN 的话,如果表上有索引,则会使用索引操作。但如果主从库的同一张表,使用了不同的列作为主键,并且从库表上还有唯一索引的情况下,bug 会导致使用 table scan(全表扫描)而非索引。
对于 MyISAM 来说,特定的 insert 与 delete 语句顺序,会导致表数据损坏。
相关阅读:
本文转载自『数据和云』公众号,作者刘伟。转载本文请联系原公众号,欢迎更多小伙伴加入投稿文章的行列,详情请戳公众号菜单「联系我们」。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号








